数据包在网络中的历程
第一步:解析 URL
所以长长的 URL 实际上是请求服务器里的文件资源,浏览器就能确定web服务器和文件名了
url
协议:通常有http,https,这个请求遵循的规范,比如:在中国买卖东西,你肯定是用国家规范的货币(人民币),用国外货币,买家不认可啊
web服务器:通常是域名,在本地访问时就是localhost:127.0.01,这一部分要进行DNS,解析出服务器对应的IP地址
蓝色部分:
你要去访问服务器下的哪一个资源,如果没有呢?那么请求的就是根目录下事先设置的默认文件,也就是 /index.html 或者 /default.html
DNS解析
干了什么事?
就是查询服务器域名对应的IP地址
域名
比如:www.server.com,用.分隔开,体现层级关系,越靠后的位置表示其层级越高
域名是给人类看的"门牌号名字",而 IP 地址是网络设备(路由器、交换机)能看懂的"经纬度坐标"
类似于:XX 街道 XX 区 XX 市 XX 省,但是层级是相反的
根域的 DNS 服务器信息保存在互联网中所有的 DNS 服务器中。
这样一来,任何 DNS 服务器就都可以找到并访问根域 DNS 服务器了。
低一级的DNS服务器信息保存在高一级的DNS服务器中,
因此,客户端只要能够找到任意一台 DNS 服务器,就可以通过它找到根域 DNS 服务器,然后再一路顺藤摸瓜找到位于下层的某台目标 DNS 服务器
DNS就像一个电话簿,你要给别人打电话(发送HTTP请求),你需要对方的手机号(IP),不知道怎么办呢?从电话簿(DNS)找到对应的手机号就可以了
域名解析流程
- 客户端首先会发出一个 DNS 请求,问 www.server.com 的 IP 是啥,并发给本地 DNS 服务器(也就是客户端的 TCP/IP 设置中填写的 DNS 服务器地址)。
- 本地域名服务器收到客户端的请求后,如果缓存里能找到 www.server.com,则它直接返回 IP 地址。如果没有,本地 DNS 会去问它的根域名服务器:
- 根域名服务器:它存放着管理名单,那个DNS服务器管理着.com,.net等等顶级域名的名单,“根服务器”,但实际上全球有 13 组 根域名服务器,本地 DNS 会随机选择其中一组(通常是延迟最低的一组)去询问
.com的地址。 - 然后询问根域名服务器"老大, 能告诉我 www.server.com 的 IP 地址吗?" 根服务器会把域名从右往左看,锁定顶级域:它只关注最右边的
**.com**。 - 根 DNS 收到来自本地 DNS 的请求后,发现后置是 .com,说:“www.server.com 这个域名归 .com 区域管理”,我给你 .com 顶级域名服务器地址给你,你去问问它吧。"
- 顶级域名服务器(.com)管理所有以
.com结尾的二级域名的名单,比如:它知道server.com的权威 DNS 是谁,知道google.com的权威 DNS 是谁,知道baidu.com的权威 DNS 是谁, - 本地 DNS 收到顶级域名服务器的地址后,发起请求问"老二, 你能告诉我 www.server.com 的 IP 地址吗?"
- 顶级域名服务器说:“我给你负责 www.server.com 区域的权威 DNS 服务器的地址,你去问它应该能问到”。
- 权威域名服务器 (server.com):管理
server.com及其所有子域名的具体记录。它确切地知道www.server.com对应哪个 IP,mail.server.com对应哪个 IP。 - 本地 DNS 于是转向问权威 DNS 服务器:“老三,www.server.com对应的IP是啥呀?” server.com 的权威 DNS 服务器,它是域名解析结果的原出处。为啥叫权威呢?就是我的域名我做主。
- 权威 DNS 服务器查询后将对应的 IP 地址 X.X.X.X 告诉本地 DNS。
- 本地 DNS 再将 IP 地址返回客户端,客户端和目标建立连接。
问题
为什么要用域名?
- 可读性。域名比IP好记和传播
- 域名提供了逻辑名称与物理地址的解耦。动态调整:后端服务器IP可能会因为调整,故障转移等等原因改变IP,使用域名,只需要在DNS处修改记录即可;负载均衡:一个域名可以对应多个IP,对接多个服务器,将数据分流发到不同服务器,单靠IP无法灵活实现,通过域名 + DNS 轮询方式实现负载均衡
既然有域名了?为什么不通过域名直接发送,还要找到IP,通过IP来确定传输
域名是给人类看的"门牌号名字",而 IP 地址是网络设备(路由器、交换机)能看懂的"经纬度坐标"。
互联网是由多个路由器连接而成,让路由器决策这个数据包要发送给谁?
如果直接存放域名,那么数据量太大,大到无法存储,而且域名是字符串,查找肯定没有IP数字速度快
并且协议头部源地址和目的地址字段被严格定义为固定长度的二进制数字,无法存放字符串域名
DNS服务器中存放的信息是怎样的?
DNS 服务器本质上是一个分布式的数据库,但它存储的数据结构非常特殊,主要是一系列的资源记录(Resource Records, 简称 RR)。
每一条记录通常包含以下五个核心字段:[域名] [TTL] [类] [类型] [数据]
1. 核心数据结构:资源记录 (RR)
DNS 服务器里存的不是简单的"域名-IP"对照表,而是不同类型的记录,每种记录解决不同的问题:
- A 记录 (Address Record)
- 作用:将域名映射到 IPv4 地址。
- 例子:
www.server.com->192.0.2.1 - 这是你最常接触的记录。
- AAAA 记录 (Quad-A Record)
- 作用:将域名映射到 IPv6 地址。
- 例子:
www.server.com->2001:db8::1
- CNAME 记录 (Canonical Name Record)
- 作用:别名记录。将一个域名指向另一个域名,而不是直接指向 IP。
- 例子:
blog.server.com->www.server.com - 场景:当你想让多个域名指向同一个网站,或者使用 CDN 服务时常用。DNS 服务器查到 CNAME 后,会再去查那个目标域名的 A 记录。
- NS 记录 (Name Server Record)
- 作用:指定谁来管理这个域名。它告诉上级域名服务器:“关于
server.com的问题,请去问这台服务器(权威 DNS)”。 - 例子:
server.com->ns1.provider.com - 这就是你描述流程中,根域名和顶级域名返回给本地 DNS 的关键信息。
- 作用:指定谁来管理这个域名。它告诉上级域名服务器:“关于
- MX 记录 (Mail Exchange Record)
- 作用:邮件交换记录。告诉发送邮件的服务器,该域名的邮件应该投递到哪台服务器。
- 例子:
server.com->mail.server.com(优先级 10)
- SOA 记录 (Start of Authority)
- 作用:起始授权记录。每个区域文件的第一条记录,包含该域名的主权威服务器信息、管理员邮箱、序列号(用于同步)、刷新时间等。它是域区的"元数据"。
- TXT 记录 (Text Record)
- 作用:存放文本信息。常用于域名所有权验证、SPF(反垃圾邮件策略)等。
2. DNS 服务器的两种主要数据形态
根据你在流程中提到的角色,DNS 服务器里存的数据形态有所不同:
- 权威 DNS 服务器 (Authoritative Server)
- 存储内容:存储区域文件 (Zone File)。
- 特点:这是数据的"源头"。管理员在这里手动配置或通过 API 写入上述的 A、CNAME、MX 等记录。
- 示例 (简化版 Zone File):
$TTL 86400
@ IN SOA ns1.server.com. admin.server.com. (
2026031801 ; Serial
3600 ; Refresh
...
)
@ IN NS ns1.server.com.
@ IN A 192.0.2.1
www IN A 192.0.2.1
mail IN MX 10 mail.server.com.
- 递归/本地 DNS 服务器 (Recursive/Local Resolver)
- 存储内容:主要存储缓存 (Cache)。
- 特点:它通常不保存原始的 Zone File(除非它同时也兼作某个域名的权威服务器)。它保存的是之前帮用户查询过的结果。
- 缓存机制:每条记录都有一个 TTL (Time To Live) 值(单位:秒)。
- 当本地 DNS 从权威服务器拿到
www.server.com->1.2.3.4时,它会连同 TTL(比如 3600 秒)一起存下来。 - 在 3600 秒内,如果有其他用户问同样的问题,它直接返回缓存,不再去问根服务器。
- 一旦 TTL 过期,这条缓存失效,下次请求时必须重新发起完整的查询流程。
- 当本地 DNS 从权威服务器拿到
3. 数据的组织形式:树状结构
DNS 数据库在逻辑上是倒置的树状结构:
- 根 (.):存放所有顶级域 (.com, .cn, .org 等) 的 NS 记录。
- 顶级域 (.com):存放所有注册在该后缀下的二级域名 (server.com, google.com) 的 NS 记录。
- 二级域 (server.com):存放具体的主机记录 (www, mail, ftp 等) 的 A/CNAME 记录。
这种分层结构使得没有任何一台服务器需要存储全世界的域名信息,实现了负载分担和分布式管理。
第二步:生产HTTP请求信息
这些都是在代码中定义包装好
第三步:传输
协议栈
http的传输工作就需要依靠协议栈了
上面的部分会向下面的部分委托工作,下面的部分收到委托的工作并执行。
应用程序(浏览器)通过调用 Socket 库,来委托协议栈工作。
传输层、网络层、数据链路层:通常由操作系统内核(即我们常说的"协议栈"核心部分)实现。例如 Linux 内核中的 TCP/IP 协议栈,负责处理 TCP/UDP 包头、IP 路由、以太网帧封装等。
协议栈,负责收发数据的 TCP 和 UDP 协议,它们会接受应用层的委托执行收集数据的操作,用 IP 协议控制网络包收发操作。
协议栈的工作
传输层(TCP):接收应用数据,添加 TCP 头部(源/目的端口、序列号、确认号、窗口大小等)。如果数据太大,TCP 会根据 MSS(最大报文段长度) 将数据切分成适合传输的段(Segment)。
网络层(IP):接收 TCP 段,添加 IP 头部(源/目的 IP 地址、TTL、协议号等)。这里负责逻辑寻址和路由。
数据链路层:接收 IP 数据包,添加 以太网帧头(源/目的 MAC 地址)和 帧尾(FCS 校验)。
帧封装是软硬结合的。逻辑寻址(MAC)多由软件协议栈处理,物理成帧(FCS、前导码)多由网卡硬件处理。
IP 下面的网卡驱动程序负责控制网卡硬件,而最下面的网卡则负责完成实际的收发操作,也就是对网线中的信号执行发送和接收操作。
也就是封装好的以太网帧被传给 网卡驱动程序。
驱动程序通过 DMA(直接内存访问) 将数据拷贝到网卡硬件的缓冲区。
**物理层:**网卡硬件将数字信号转换为电信号/光信号发送到物理介质。
第四步:出口
经过协议栈,数据已经封装好了,归根结底都是一堆0和1,要想把这些数据传输给目的地,还需要网卡把这些转换为电信号传输出去
网卡
负责执行这一操作的是网卡,要控制网卡还需要靠网卡驱动程序。
驱动程序在系统内存中先加好MAC 报头,然后连同数据一起 DMA 复制到网卡缓冲区;网卡硬件在发送时,会自动加上前导码、SFD 和 FCS。
起始帧分界符是一个用来表示包起始位置的标记末尾的
FCS(帧校验序列)用来检查包传输过程是否有损坏
第五步:交换机
数据通过网卡转换为电信号传输到交换机上,交换机将数据原样转发到目的地。
那么交换机怎么知道转发到哪里呢?目的地在哪儿?
这时需要交换机把电信号转换为数字信号,通过交换机根据 MAC 地址表查找 MAC 地址,然后将信号发送到相应的端口,并正确转发传输
交换机只处理数据中的MAC地址,数据链路层,不去理解应用层,网络层有什么东西,体现了分层结构
交换机的自学习机制
交换机的工作
- 交换机将数据的电信号转换为数字信号
- 通过末尾的FCS校验错误,没问题就将包存入缓冲区后,接下来需要在MAC地址表中查询一下这个包的接收方 MAC 地址
- 在交换机中维护着一个MAC地址表:交换机的 MAC 地址表主要包含两个信息:一个是设备的 MAC 地址,另一个是该设备连接在交换机的哪个端口上
- 如果该包的MAC地址在表中存在,那么交换机会将数据转发到对应的端口
- 如果地址表中找不到指定的 MAC 地址。这可能是因为具有该地址的设备还没有向交换机发送过包,或者这个设备一段时间没有工作导致地址被从地址表中删除了。
- 这种情况下,交换机无法判断应该把包转发到哪个端口,只能将包转发到除了源端口之外的所有端口上,无论该设备连接在哪个端口上都能收到这个包。这样做不会产生什么问题,因为以太网的设计本来就是将包发送到整个网络的,然后只有相应的接收者才接收包,而其他设备则会忽略这个包
问题
这样做会发送多余的包,会不会造成网络拥塞呢?
在实际的以太网设计和现代交换机的工作机制中,这种情况通常不会造成严重的网络拥塞。
主要原因:
- 过程:当交换机收到一个目的 MAC 未知的包时,它确实会泛洪(发给所有端口)。
- 结果:真正的目标设备收到这个包后,通常会进行回复(例如 TCP 的 SYN-ACK,或者 ARP 响应)。
- 学习:当目标设备回复时,交换机会立刻从回复包的源地址中学习到该设备的 MAC 地址和对应的端口,并写入地址表。
- 结论:后续的通信就不再是泛洪了,而是精准的单播。因此,泛洪只发生在连接建立的第一个瞬间,对于持续的数据传输,开销几乎为零。
其次现代局域网(千兆、万兆以太网)的带宽通常远大于实际业务需求。偶尔的几个泛洪包占用的带宽微乎其微,就像高速公路上偶尔有一辆车走错路绕了一圈,不会导致堵车。
第六步:路由器
网络包经过交换机之后,现在到达了路由器,并在此被转发到下一个路由器或目标设备。
家用"无线路由器"其实是一个三合一设备。
它内部包含了:路由器模块:负责拨号、NAT、连接互联网。交换机模块:负责背后的 4 个 LAN 口,连接电脑、电视。无线 AP 模块:负责发射 WiFi,连接手机。
路由器的工作
接收和校验
将网线中的电信号转换为数字信号,通过包末尾的 FCS 进行错误校验。如果没问题则检查 MAC 头部中的接收方 MAC 地址,看看是不是发给自己的包,如果是就放到接收缓冲区中,否则就丢弃这个包。
关键点:路由器端口有自己的MAC地址,它像一个普通的网络设备一样接收数据
解封装
去掉数据链路层头部(以太网帧 + 帧尾),保留网络层数据包
因为路由器只能看懂IP,且MAC地址只在当前网段有效
这个时候就要去路由表中查找目的网络的IP对应的出口是哪个?
路由表查找
路由表中每一个条记录包含:
| 字段 | 说明 | 示例 | 形象化 |
|---|---|---|---|
| 目标网络 | 目的地的网段地址 | 192.168.1.0 |
地址(朝阳区建国路100号) |
| 子网掩码 | 界定网络范围 | 255.255.255.0 |
地址的范围(朝阳区) |
| 下一跳IP | 下一个路由器的地址 | 10.0.0.2 |
下一个引路人(老王) |
| 出接口 | 从哪个端口发出去 | eth0 |
从哪个门出去找下一个引路人 |
| 路由来源 | 怎么学到这条路的 | 直连/静态/动态 | |
| 管理距离 | 信任优先级(值越小越优先) | 直连=0, 静态=1 | |
| 度量值 | 路径成本(跳数、带宽等) | 跳数=3 |
**怎么查?**路由匹配的"最长前缀匹配"原则
就像,你要去朝阳区建国路100号(IP可以类比成地址)
路由表里的记录:(目的IP地址,在哪里,那条路线能找到该IP的指引)
- 记录1: 中国 → 走A门
- 记录2: 上海市 → 走B门 不匹配
- 记录3: 北京市朝阳区 → 走C门 最精确
- 记录4: 全国默认 → 走D门
匹配结果:
- "朝阳区建国路"在"中国"范围内吗? 在
- "朝阳区建国路"在"上海市"范围内吗?不在
- "朝阳区建国路"在"北京市朝阳区"范围内吗? 在
- "朝阳区建国路"在"全国"范围内吗?在
三个匹配,选最精确的 → 记录3(北京市朝阳区)
匹配后,得到了:原来我要去朝阳区建国路100号,我应该走C门,去找下一个路由器(找老王问话,让它继续带路)
路由匹配的"最长前缀匹配"原则
- 提取数据包中的目标IP地址
- 逐条与路由表记录进行按位与运算
- 选择子网掩码最长(最精确)的匹配项
ARP解析(找下一站的MAC地址)
这个时候路由器只知道"老王"的名字(IP),不知道"老王"在哪儿啊?(MAC地址),怎么办?
全网喊话,"老王"你在哪儿?(ARP请求),这时"老王"回复给当前路由器(ARP回应):我的MAC地址是xxxx
这个时候,路由器就知道应该把数据包转发给"老王",让它继续传输下去,找到目的地
ARP只在同一局域网内有效!
场景1:下一跳路由器在同一局域网 → 可以直接ARP查询
场景2:下一跳路由器不在同一局域网 → 这种情况不会出现(路由表保证下一跳都是直连的)
封装发送
数据包从头到尾:
源IP:始终不变(最开始发送数据包的设备)
目标IP:始终不变(最终的目的地)
源MAC:每跳都变(当前路由器)
目标MAC:每跳都变(下一跳路由器)← 这是"老王"
数据包封装,发送给下一跳路由器,下一跳路由器重复上述过程,直到找到目的地
举例
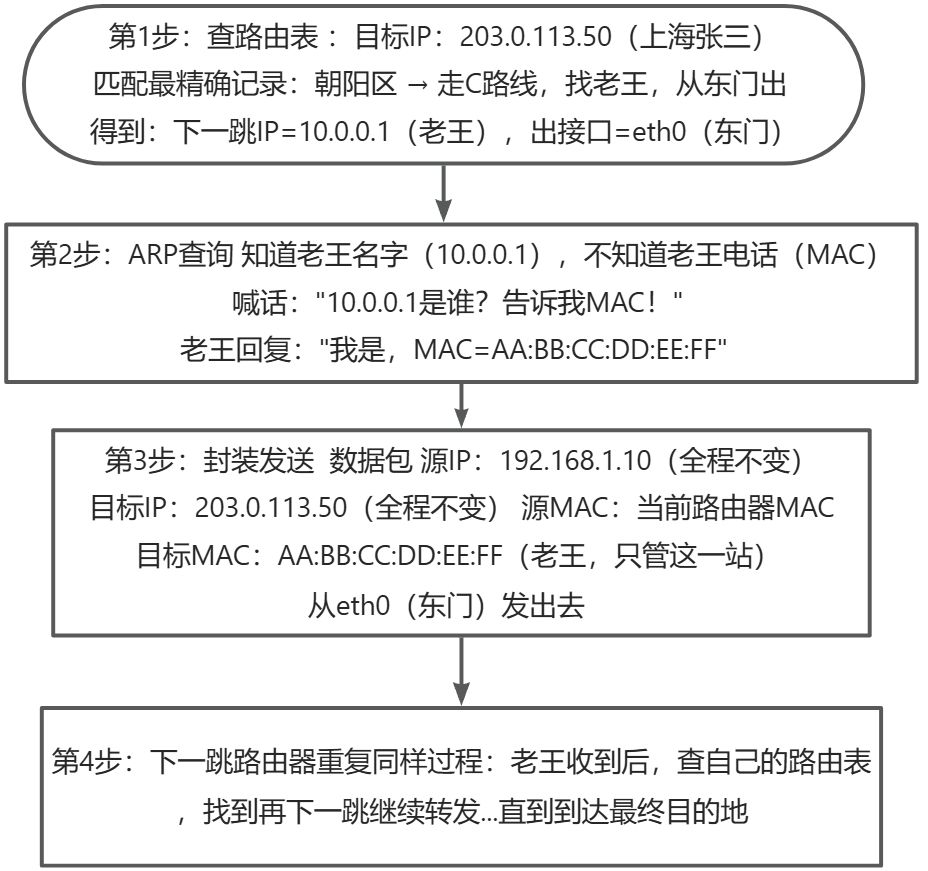
有了交换机,能把数据从一个设备传输到另一个设备,为什么还需要路由器?
交换机负责"把家里的设备连起来",路由器负责"把家连到外面的世界"
原因一:隔离与连接(局域网 vs 广域网)
- 交换机的局限:交换机把所有连在上面的设备看作"一家人"。如果只有交换机,
- 所有设备都在同一个"大房间"里,只能自娱自乐,无法触摸到互联网
- 如果这个房间里有1000台设备,任何一台设备发出的广播(比如"谁是192.168.1.1?"),其他999台都能听到,网络会瞬间卡死(广播风暴)。
- 路由器的作用:路由器是边界。它把你家的局域网(私有网络)和外面的互联网(公共网络)隔开。
- 它阻止了互联网的混乱广播进入你家。
- 它也防止你家的广播泛滥到互联网上。
原因二:地址转换 (NAT) —— 最关键的功能
问题:互联网上的公网 IP 地址非常宝贵且有限,运营商通常只给你家分配1个公网 IP。但你家有手机、电脑、电视等10个设备,每个设备都需要上网,它们都需要 IP 地址。
解决:
- 交换机做不到这点,它只会原封不动地转发。
- 路由器拥有 NAT (网络地址转换) 功能。
- 家里的设备使用私有 IP(如
192.168.1.x),这些地址在互联网上是无效的。 - 当访问百度时,路由器会把你的"私有 IP"替换成运营商给的"公网 IP",然后把数据发出去。
- 当百度回复数据时,路由器再根据记录,把数据转回给具体设备。
- 家里的设备使用私有 IP(如
- 结论:没有路由器做 NAT,家里除了那一台直接连光猫的设备,其他所有设备都上不了网。
原因三:路径选择 (Routing)
- 交换机:只知道"目标 MAC 在哪个端口",它没有全局地图。
- 路由器:拥有一张路由表(地图)。互联网由成千上万个网络组成,数据从你家传到美国服务器,中间要经过几十个路由器。每个路由器都要判断:"要去美国,下一跳应该发给谁?"这种复杂的寻路功能,交换机完全不具备。
路由器和交换机的区别?
路由器是基于 IP 设计的,俗称三层网络设备,路由器的各个端口都具有 MAC 地址和 IP 地址;
而交换机是基于以太网设计的,俗称二层网络设备,交换机的端口不具有 MAC 地址
交换机 (Switch):工作在数据链路层 (第2层)。
- 认人方式:它只看 MAC 地址(物理地址,如
00:1A:2B:3C:4D:5E)。 - 作用范围:只能在同一个局域网 (LAN) 内部传输数据。它不知道什么是"互联网",也不知道什么是"IP地址"。
- 比喻:就像公司内部的前台/总机。你知道同事的分机号(MAC地址),前台能帮你把电话转接给同事。但前台没法帮你打外线电话去联系其他公司。
路由器 (Router):工作在网络层 (第3层)。
- 认人方式:它看 IP 地址(逻辑地址,如
192.168.1.5)。 - 作用范围:连接不同的网络(比如你的家庭局域网 vs 互联网)。它负责在不同网络之间"指路"和转发数据。
- 比喻:就像邮局分拣中心。它不看具体的门牌号(MAC),而是看城市和街道(IP网段)。它决定你的信是发往"北京"还是"上海",并选择最佳路线发送出去。
第七步:服务器和客户端
流程
- 数据包抵达服务器后,服务器会先扒开数据包的 MAC 头部,查看是否和服务器自己的 MAC 地址符合,符合就将包收起来。不匹配,直接丢弃!
- 接着继续扒开数据包的 IP 头,发现 IP 地址符合,根据 IP 头中协议项,知道自己上层是 TCP 协议。于是,扒开 TCP 的头,里面有序列号,需要看一看这个序列包是不是我想要的,如果是就放入缓存中然后返回一个 ACK;如果是乱序到达(后面的包先到),那么缓存起来等待 + 返回ACK(告知已收到的最高序列号);如果是重复的包,丢弃并返回ACK(我已经收到了);如果是旧的包,直接丢弃;TCP头部里面还有端口号, 通过端口号找到对应的应用进程
- 于是,服务器自然就知道是 监听该端口的这个HTTP 进程想要这个包,于是就将包发给这个HTTP 进程。
- 服务器的 HTTP 进程看到,原来这个请求是要访问一个页面,于是就把这个网页封装在 HTTP 响应报文里。HTTP 响应报文也需要穿上 TCP、IP、MAC 头部,不过这次是源地址是服务器 IP 地址,目的地址是客户端 IP 地址。
- 穿好头部衣服后,从网卡出去,和上述的传输流程一样,交由交换机转发到路由器,路由器就把响应数据包发到了下一个路由器,就这样跳啊跳。
- 最后跳到了客户端的路由器,路由器扒开 IP 头部发现是要找城内的人,于是把包发给了城内的交换机,再由交换机转发到客户端。客户端就这样收到了服务器的响应数据包!
- 于是,客户端开始扒皮,把收到的数据包解封装成HTTP 响应报文后,交给浏览器去渲染页面
- 最后,客户端要离开了,向服务器发起了 TCP 四次挥手,至此双方的连接就断开了。
HTTP 进程。 - 服务器的 HTTP 进程看到,原来这个请求是要访问一个页面,于是就把这个网页封装在 HTTP 响应报文里。HTTP 响应报文也需要穿上 TCP、IP、MAC 头部,不过这次是源地址是服务器 IP 地址,目的地址是客户端 IP 地址。
- 穿好头部衣服后,从网卡出去,和上述的传输流程一样,交由交换机转发到路由器,路由器就把响应数据包发到了下一个路由器,就这样跳啊跳。
- 最后跳到了客户端的路由器,路由器扒开 IP 头部发现是要找城内的人,于是把包发给了城内的交换机,再由交换机转发到客户端。客户端就这样收到了服务器的响应数据包!
- 于是,客户端开始扒皮,把收到的数据包解封装成HTTP 响应报文后,交给浏览器去渲染页面
- 最后,客户端要离开了,向服务器发起了 TCP 四次挥手,至此双方的连接就断开了。

openEuler 是由开放原子开源基金会孵化的全场景开源操作系统项目,面向数字基础设施四大核心场景(服务器、云计算、边缘计算、嵌入式),全面支持 ARM、x86、RISC-V、loongArch、PowerPC、SW-64 等多样性计算架构
更多推荐

 14
14 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)