操作系统 | 存储器管理
存储器管理:你的电脑到底是怎么"记东西"的?
你有没有想过,你双击打开一个程序的那一瞬间,电脑内部到底发生了什么?代码不可能凭空出现在CPU面前,就像你不可能在图书馆闭着眼睛找到一本书——你得知道书在哪层楼、哪个书架、第几本。
存储器管理,就是操作系统里那个负责"安排座位"的超级管家。它要解决的核心问题只有一个:怎么把程序和它需要的数据,又快又省地塞进内存里,并且保证它们能正确找到自己的位置。
今天这篇文章,我们就把存储器管理从头到尾讲透。内容有点多,但别慌,咱们一层一层剥洋葱。
一、存储器的层次结构:一座金字塔
在聊管理之前,得先搞清楚——电脑里到底有哪些"记忆场所"?
答案是:一座金字塔。
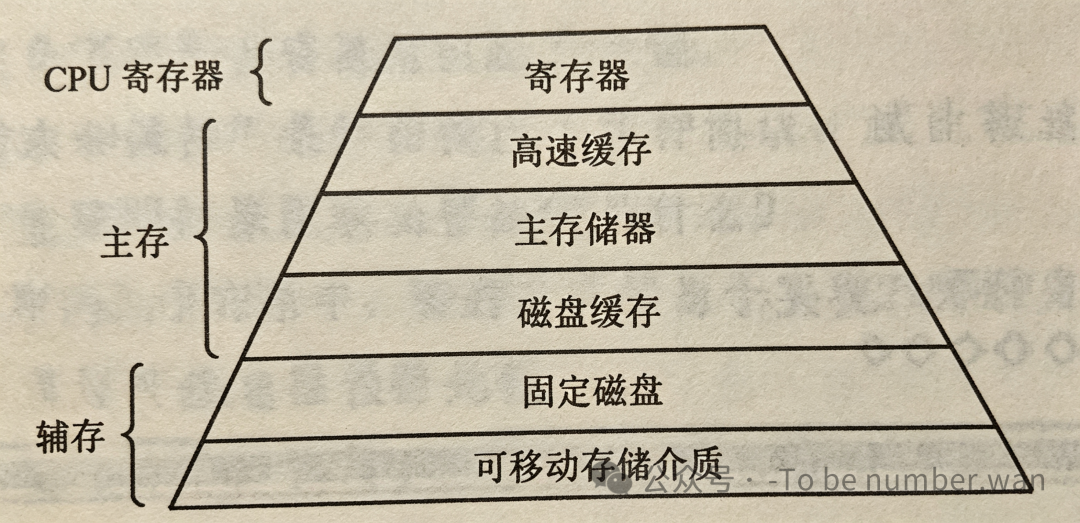
从上到下依次是:
CPU寄存器 → 高速缓存(Cache) → 主存(内存) → 磁盘缓存 → 固定磁盘(内置硬盘/SSD) → 可移动存储介质(U盘、光盘) → 磁带
这可不是随便排列的,每一层的存在都有它的道理。
CPU寄存器是最顶级的存在,它就住在CPU"家里",速度快到飞起,但容量极其有限——就那么几十个,每个也就存一个机器字长。你可以把它理解为CPU的"随身口袋",只能放最紧急的东西。
主存,也就是我们常说的内存条,是真正干活的地方。所有正在运行的程序和数据,最终都得被加载到主存里才能被CPU执行。寄存器和主存被统称为可执行存储器——因为程序真正"跑起来"的时候,只跟这两位打交道。
那问题来了:CPU的运算速度是纳秒级的,而主存的访问速度……也是纳秒级的,但CPU比主存快了不止一个量级。这就好比一个超级学霸做算术题的速度是普通人的100倍,但他每次都得走到教室另一头去拿草稿纸——速度差太大了。
高速缓存就是为了缓和CPU与主存之间的速度矛盾而诞生的。它藏在CPU芯片内部或附近,速度极快,容量比寄存器大但比内存小。CPU要取数据时先看缓存里有没有,有就直接拿走(缓存命中),没有才去主存里找,同时把这块数据顺便搬到缓存里——下次可能还用得着。
你可能会好奇:高速缓存真的存在吗?
答案是——对程序员来说,它在硬件层面自动工作,你在写代码时几乎感知不到它的存在。它"并不实际存在"于你的编程视角中,但它确确实实在硬件里高速运转着。
再往下,磁盘存储(硬盘、SSD)的容量巨大但速度慢得多——大概是主存的十万到百万倍的速度差。为了缓和磁盘与主存之间的速度矛盾,操作系统又搞了一个磁盘缓存,把最近用过的磁盘数据暂时缓存在主存里。
整个金字塔的核心思想就是:速度越快的存储越贵、容量越小;速度越慢的存储越便宜、容量越大。每一层缓存都是为了弥合上下层之间的速度鸿沟。
二、程序的装入与链接:代码是怎么"搬进"内存的?
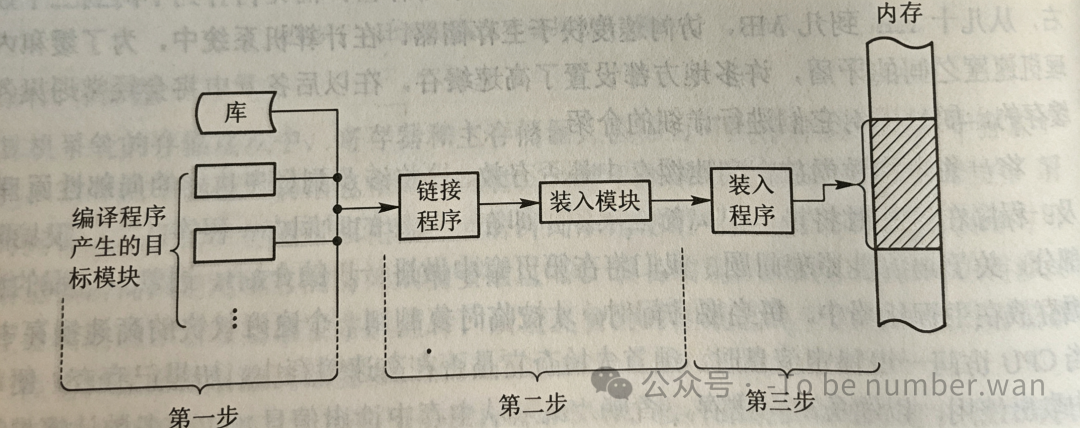
你写了一段C++代码,编译之后变成了目标文件。但目标文件还不能直接运行,它得被"装入"内存,才能被CPU执行。这个过程,就涉及到装入方式和链接方式两个问题。
2.1 三种装入方式
绝对装入方式,是最原始的方法。在计算机还很小、只能运行单道程序的年代,程序员清楚地知道自己的程序会被放在内存的哪个位置——因为他就是唯一的住户,整个内存都是他的"别墅"。编译的时候就把物理地址写死了,装入时直接往那个地址放就行。
但到了多道程序的时代,好几道程序要同时住在内存里,谁住哪事先根本不知道。这时候就需要可重定位装入方式了。
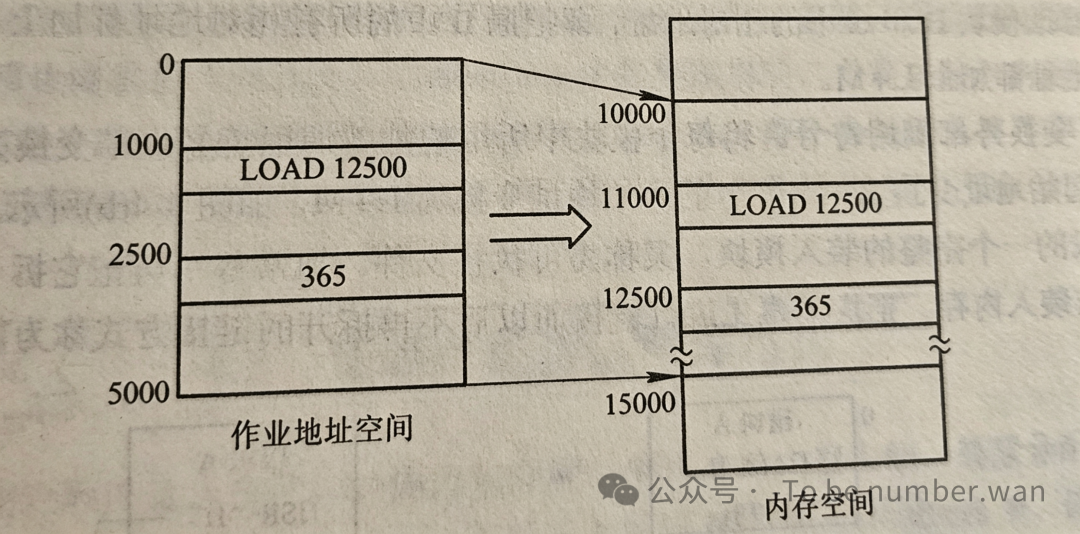
程序在编译时使用的是逻辑地址(也叫相对地址),装入内存时,由装入程序根据内存的实际情况,把逻辑地址转换成物理地址。这就像你买了一张电影票写着"第5排第3座",但到底是哪个影厅的5排3座,得等你到了电影院才知道。
第三种是动态运行时的装入方式。这种方式更激进——装入内存的时候先不做地址转换,地址仍然是逻辑地址,一直到程序真正运行、需要访问某个地址的时候,才由硬件的地址变换机构实时完成转换。这样做的好处是,程序在内存里的位置可以随时变动,给操作系统的调度带来了极大的灵活性。
2.2 三种链接方式
程序往往不是一个单独的模块,而是由多个目标模块组合而成的。比如你写了一个主程序,还调用了标准库里的函数——这些模块怎么组合到一起呢?
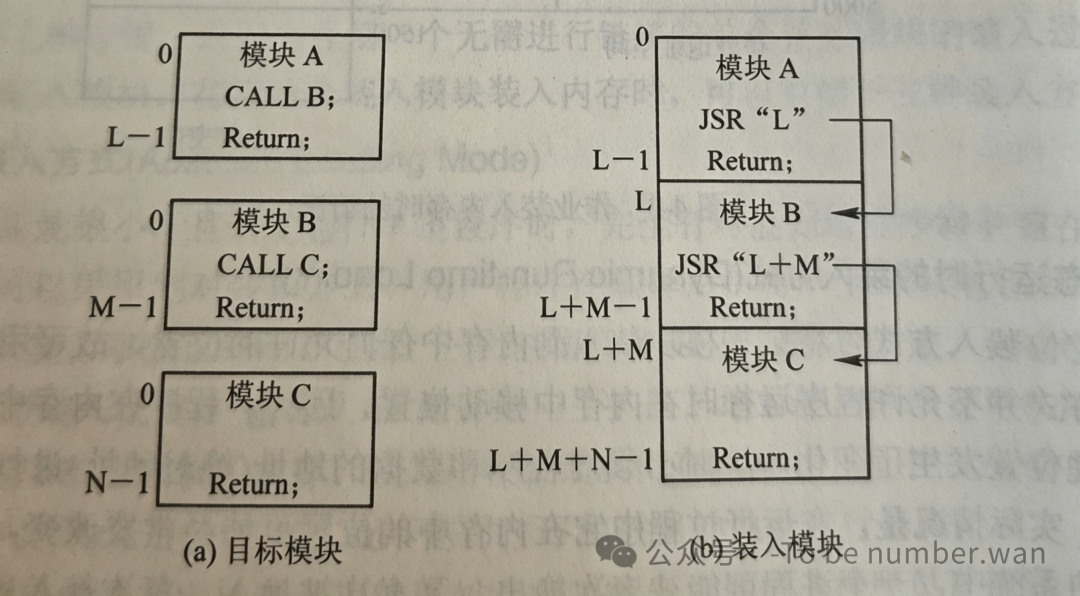
静态链接方式:在程序运行之前,一次性把所有目标模块链接成一个完整的可执行文件,以后再也不会拆开。简单粗暴,但缺点也明显——每次更新一个模块,整个程序都要重新链接。
装入时动态链接方式:一边装入内存一边链接。好处是便于修改和更新(只需要替换某个模块),也便于实现目标模块的共享(多个程序可以共用同一个库模块)。你可以把它理解为"现场组装家具",零件到了就组装,没到的先放着。
运行时动态链接方式:把某些模块的链接推迟到程序真正执行到、需要用到那个模块的时候才进行。这样做可以节省大量内存空间——如果某个功能这次压根没用到,那对应的模块就根本不会被加载进来。我们日常用的操作系统里大量的动态链接库(.dll或.so),就是这种思想的体现。
三、连续分配存储管理:最早的"分房"方案
好,现在我们知道程序要装入内存了。但内存是有限的,怎么给不同的程序分配内存空间呢?
最直觉的方案就是:连续分配——给每个程序一块连续的内存,就像给每户人家分一栋联排别墅。
3.1 单一连续分配
最早期的操作系统,内存里只能放一道程序,整个用户区全归它。简单,但浪费严重——一道程序可能只需要100KB,但你给了它1MB,剩下的900KB就只能闲着。
3.2 固定分区分配
后来人们想到,把内存提前划分成若干个固定大小的区域(分区),每个分区放一道程序。
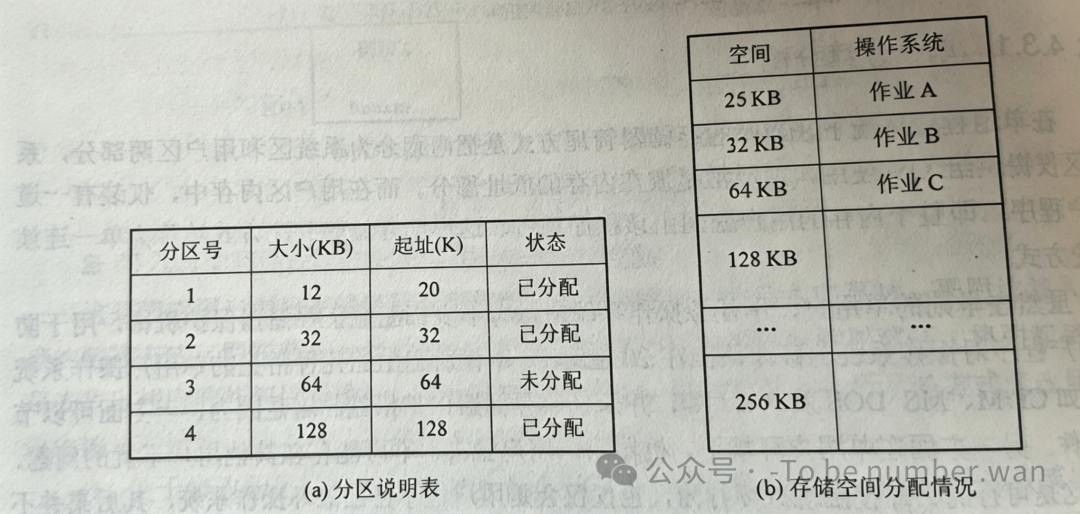
分区划分有两种方法:
分区大小相等——所有分区一样大,简单但死板,程序太小浪费空间,太大又放不进去;
分区大小不等——有大区有小区,灵活性增加了,但仍然无法应对所有情况。
为了管理分区,操作系统需要维护两张表:分区使用表记录每个分区的状态(已分配还是空闲),空闲分区表记录所有空闲分区的情况。空闲分区还会被组织成一条空闲分区链,用指针把空闲分区串起来,方便分配和回收。
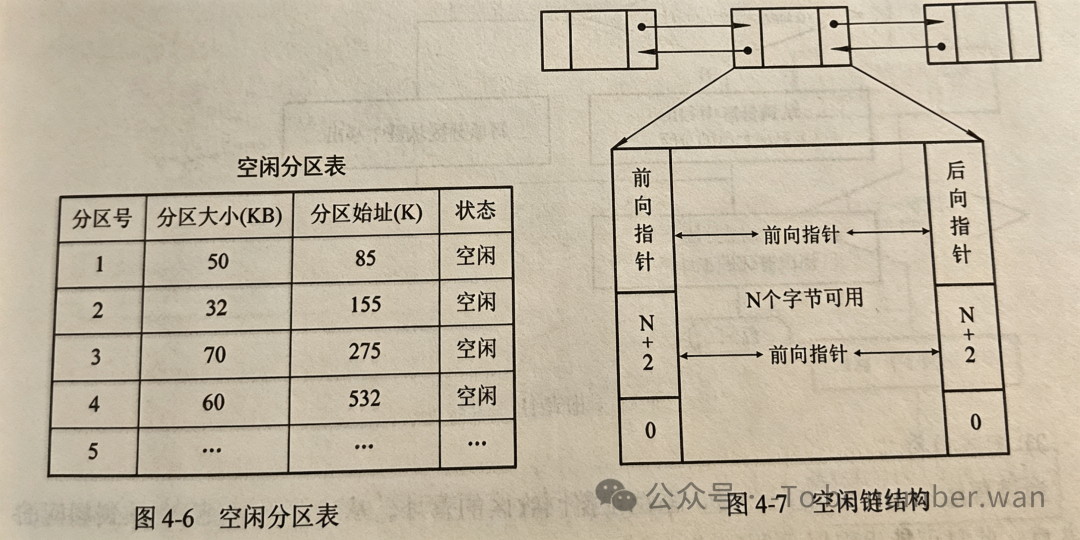
3.3 动态分区分配
固定分区的"死板"催生了动态分区分配:不事先划分分区,而是在程序需要装入时,根据程序的大小动态地切出一块刚好合适的内存。这就像不再预先建好固定户型的房子,而是来了几个人就盖多大的房子。
听起来很美,但随之而来的问题是:用什么策略来选一块空闲内存给新来的程序? 这就引出了好几种经典的分区分配算法。
首次适应算法(First Fit):把所有的空闲分区按照地址从低到高排列成一条链。每次分配时从链头开始顺序查找,找到第一个够大的空闲分区就停下来分配。
优点是简单,倾向于优先利用低地址空间,保留了高地址的大空闲区。
缺点是低地址部分被不断切割,产生大量碎片,而且每次查找都要从低地址开始扫描,增加了查找开销。
循环首次适应算法(Next Fit):在首次适应的基础上做了个小改进——不是每次都从头开始找,而是从上次分配结束的位置继续往下找。为此需要设置一个"起始查询指针"。
好处是使空闲分区的使用更加均匀,减少了查找开销。
缺点是不再刻意保留高地址的大空闲区。
最佳适应算法(Best Fit):把所有空闲分区按容量从小到大排序。分配时找第一个能满足要求的(也就是最小的那个足够大的分区)。直觉上"最合适",但实际上会造成大量难以利用的碎片——因为每次切剩下的边角料都太小了,小到几乎没有程序能用上。
最坏适应算法(Worst Fit):反过来,按容量从大到小排序,总是挑最大的空闲区来切。这样每次剩下的碎片仍然足够大,可以被其他程序利用,对中小型作业比较友好。但缺点是大的空闲区被快速消耗,真正需要大块内存的程序反而可能找不到位置。
查找效率倒是很高,因为只要第一个分区够大就行。
快速适应算法(Quick Fit):将空闲分区按容量大小分成若干类,每一类设一个独立的空闲分区链。同时在内存中建立一张管理索引表,索引每一项指向对应大小的空闲分区链。分配时,根据作业长度在索引表中找到最小匹配的空闲链,直接取链中第一块分配,无需遍历。
缺点是分配与回收的算法复杂度较高,系统开销大,而且一个分区只属于一个进程也可能造成浪费。
伙伴系统(Buddy System):这是一个非常优雅的方案。它要求所有已分配和空闲的分区大小都是2的k次幂(比如1KB、2KB、4KB、8KB……)。对于具有相同大小的所有空闲分区,单独设立一个双向链表。分配一个大小为n的分区时,先找到满足 2^i ≤ n < 2^(i+1) 的i值,然后去大小为2^i的空闲链表中找。如果有,直接分配;如果没有,就去更大的链表中找一块,拆成两个"伙伴"——一个分配,另一个放入对应大小的链表中。
回收时则检查被回收分区的"伙伴"是否也空闲,如果是就合并成更大的块。伙伴系统利用了哈希快速查找的优势,构建一张以空闲区大小为关键字的哈希表来加速定位。
3.4 分配内存操作
算法选好了,但真正给程序分配内存时,具体是怎么操作的呢?
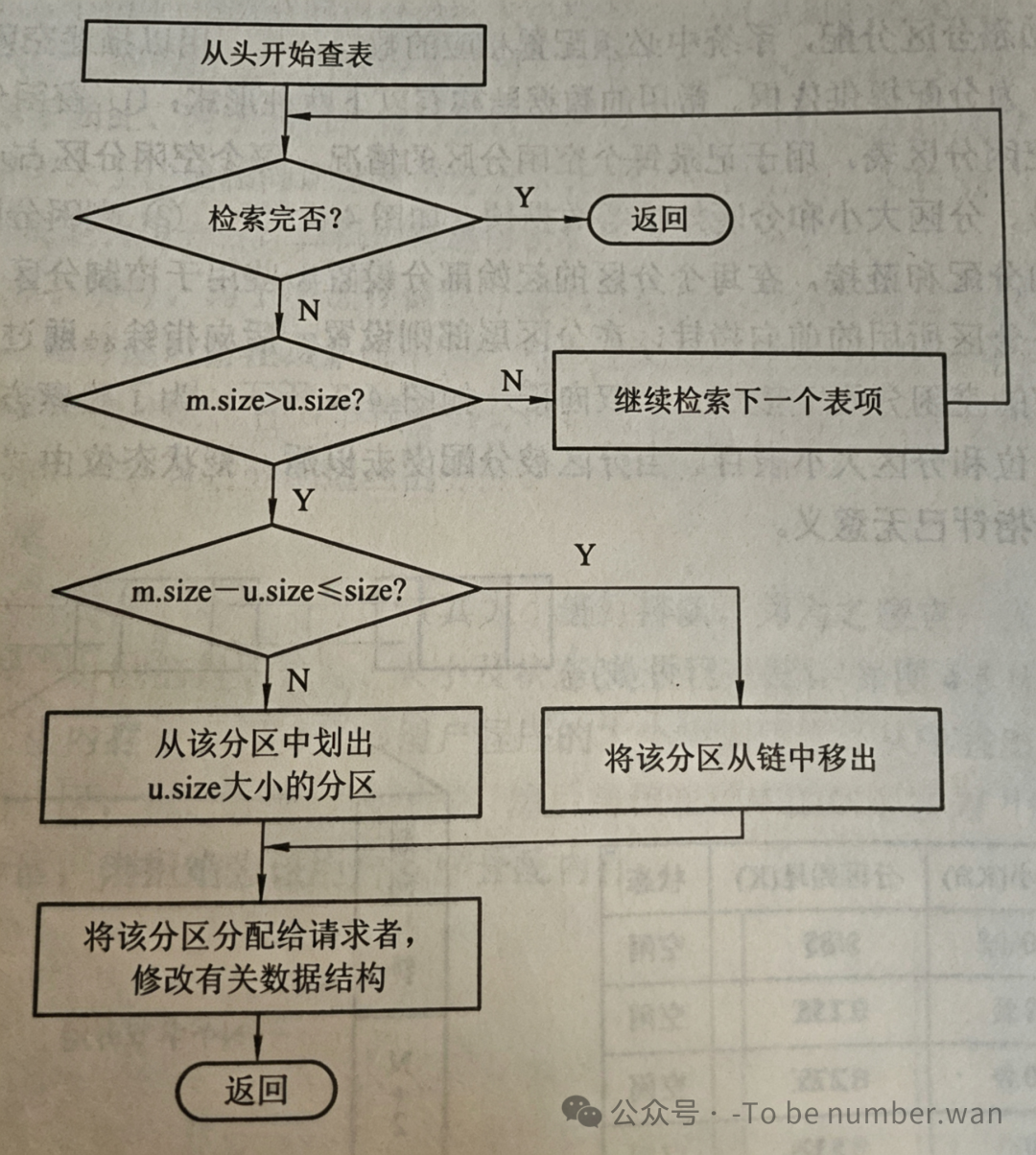
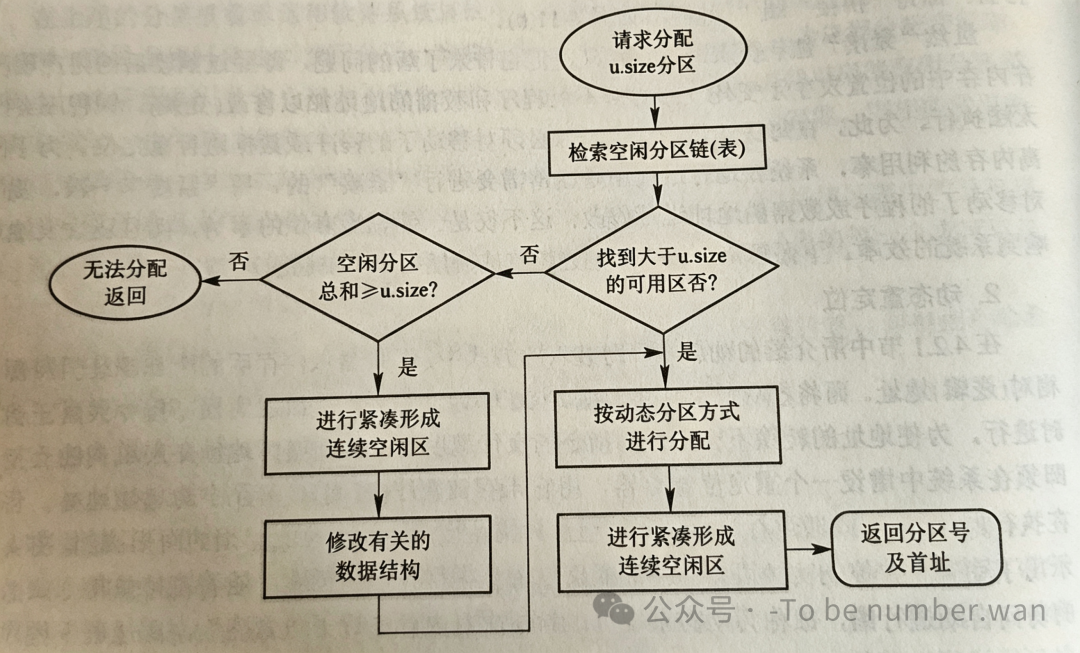
当一个进程请求一块大小为u的内存时,操作系统首先按照选定的分配算法(首次适应、最佳适应等),在空闲分区表或空闲分区链中查找,找到一个大小不小于u的空闲分区。假设找到的空闲分区大小为m。
接下来要做一个判断:这个分区需不需要"切开"?
如果 m - u 的值很小(小于一个最小阈值,比如不足以放下任何有意义的程序),那就不切了,整个分区全部给这个进程——虽然浪费了一点点,但至少不会产生一个毫无用处的"微型碎片"。
如果 m - u 足够大,那就在该分区中划出一块大小为u的区域分配给进程,剩下的部分仍然保留为空闲分区,更新空闲分区表或链表中对应表项的起始地址和大小。
以首次适应算法为例,完整的分配流程是这样的:从空闲分区链的链头开始扫描,逐个检查每个空闲分区的大小是否 ≥ u。一旦找到满足条件的分区,就停下来;如果整个链都扫完了还没找到,说明当前没有足够大的连续空闲区,分配失败。找到之后,再从空闲分区表中删除该表项,修改分区使用表(记录新分配出去的分区信息),最后将分好的分区分配给进程。
3.5 回收内存操作
程序运行结束后,它占用的内存要归还给系统。回收可不是简单地把内存标记为"空闲"就完事了——关键问题在于:归还的这块内存,和它左右相邻的区域是不是也是空闲的?
回收一块已分配的内存时,存在以下四种情况:
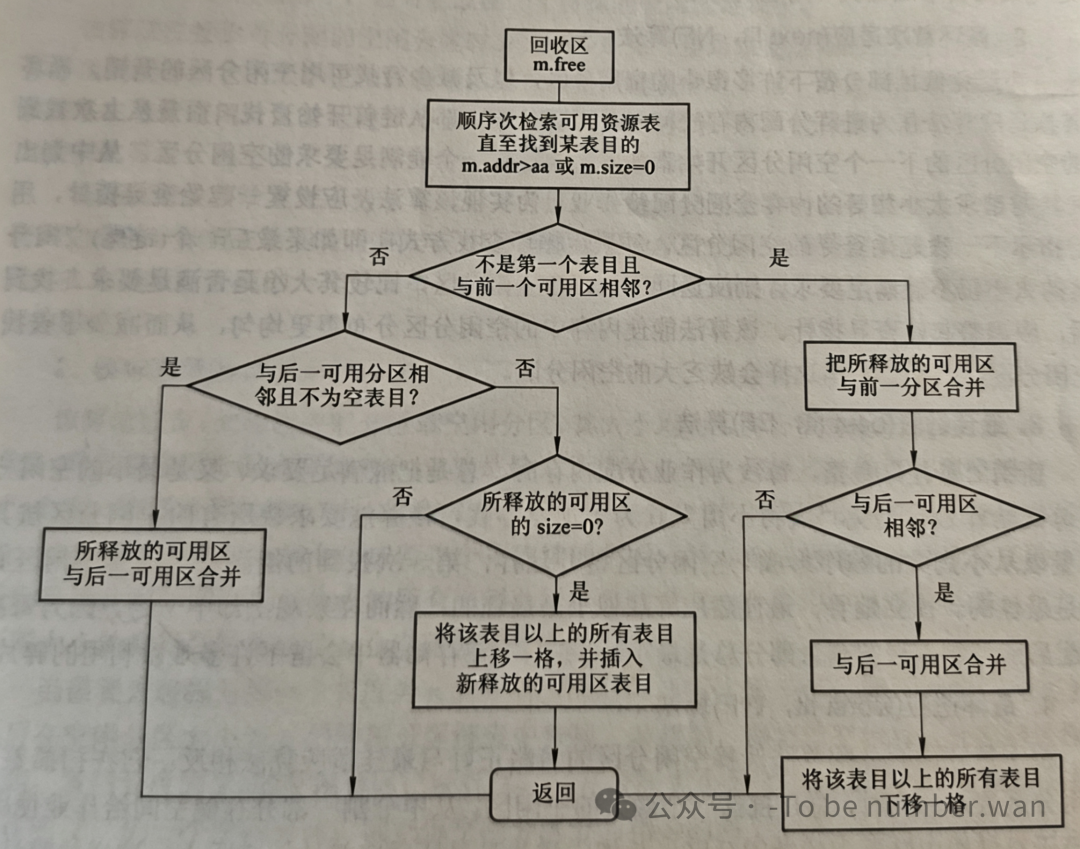
情况一:回收区与上邻空闲区合并。 回收区的"上面"(低地址方向)紧挨着一个空闲分区。这时候把回收区与上方的空闲区合并成一个更大的空闲分区,更新空闲分区表中该表项的大小即可。
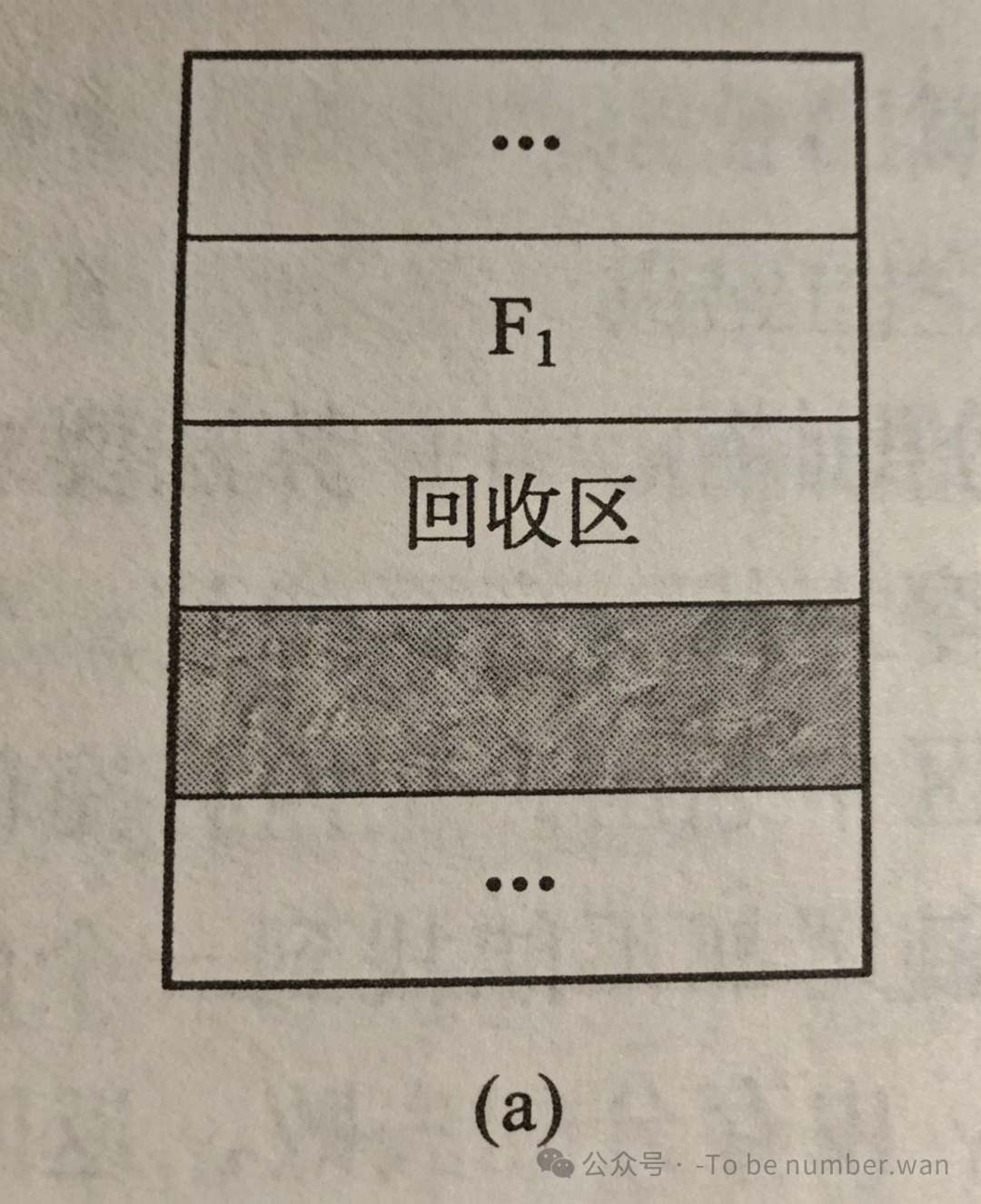
情况二:回收区与下邻空闲区合并。 回收区的"下面"(高地址方向)紧挨着一个空闲分区。类似地,将两者合并,回收区的起始地址不变,大小加上原下方空闲分区的大小。
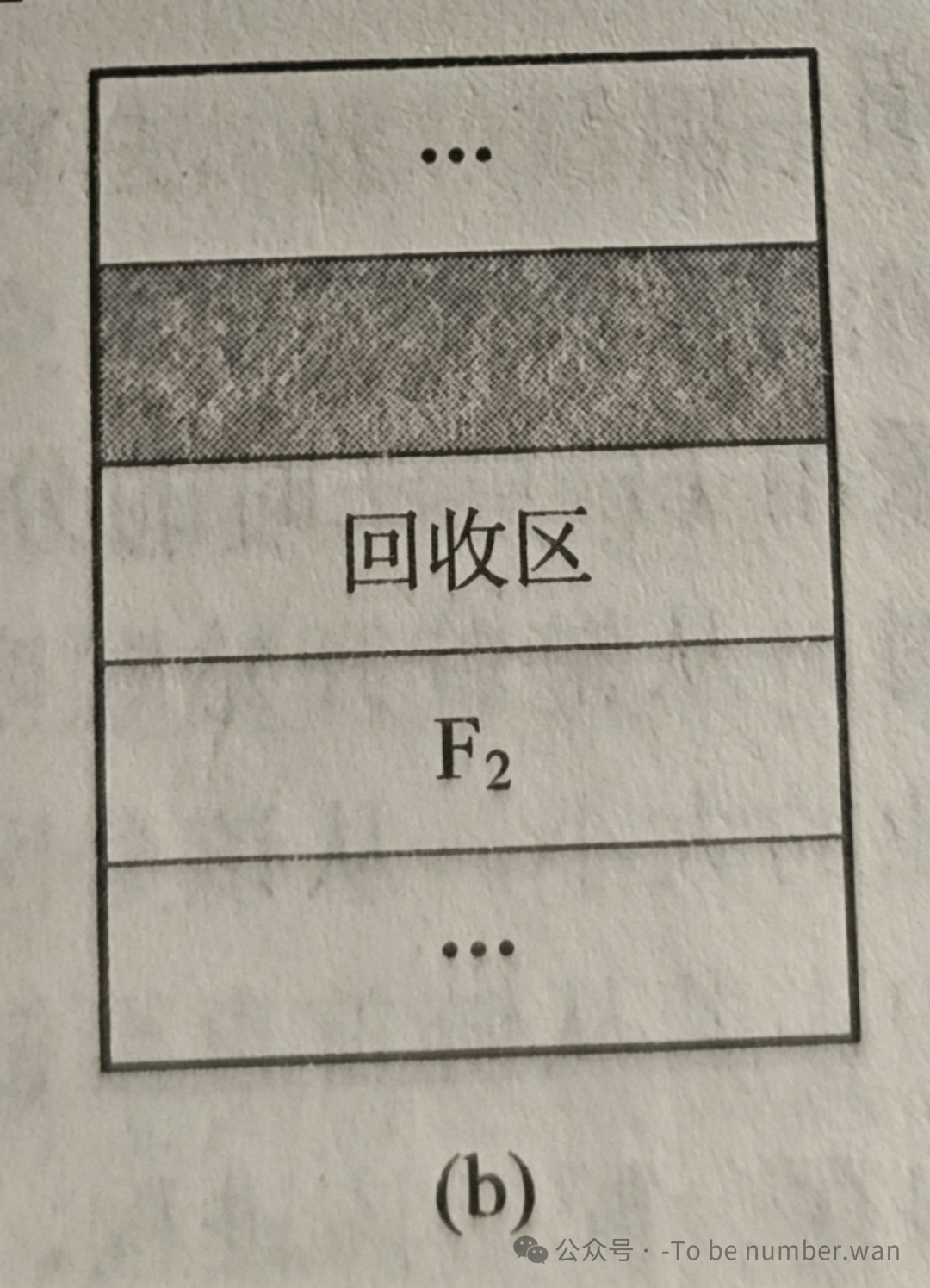
情况三:回收区同时与上邻和下邻空闲区合并。 回收区的上下两个方向都是空闲分区——这是最"幸运"的情况,三个空闲区合并成一个大的,减少碎片。操作上,以上邻空闲区为基础,大小扩展为三者之和,同时删除下邻空闲区的表项,并调整空闲分区链。
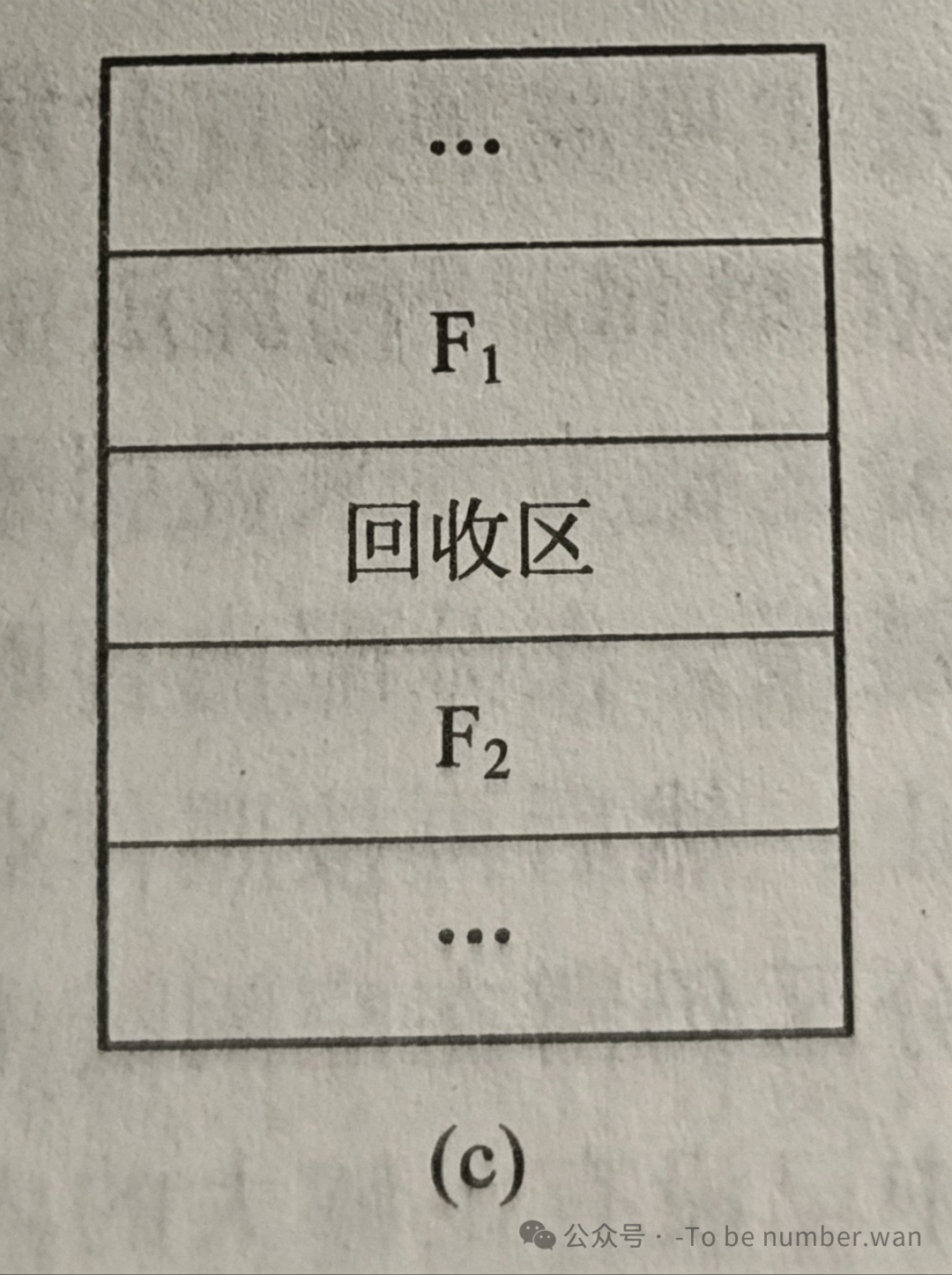
情况四:回收区不与任何空闲区相邻。 回收区的上下都是已分配的分区。这时直接将回收区作为一个新的空闲分区插入到空闲分区表中,并按照地址顺序插入到空闲分区链中的合适位置。
不管哪种情况,回收操作的核心思想就是:能合并就合并,尽量保持大的连续空闲区,避免碎片越碎越小。这也是为什么空闲分区链要按地址有序排列——只有有序,才能快速判断回收区与邻居是否相邻。
3.6 紧凑与动态重定位
无论哪种算法,动态分区都逃不过一个问题——碎片。用久了,内存中散落着大量大小不一的空闲块,虽然总量足够,但没有一块连续的能放下一个大程序。
解决方案就是紧凑(Compaction):把内存中所有的作业都"搬一搬",全部挤到一端,另一端自然就腾出了一大块连续空闲区。
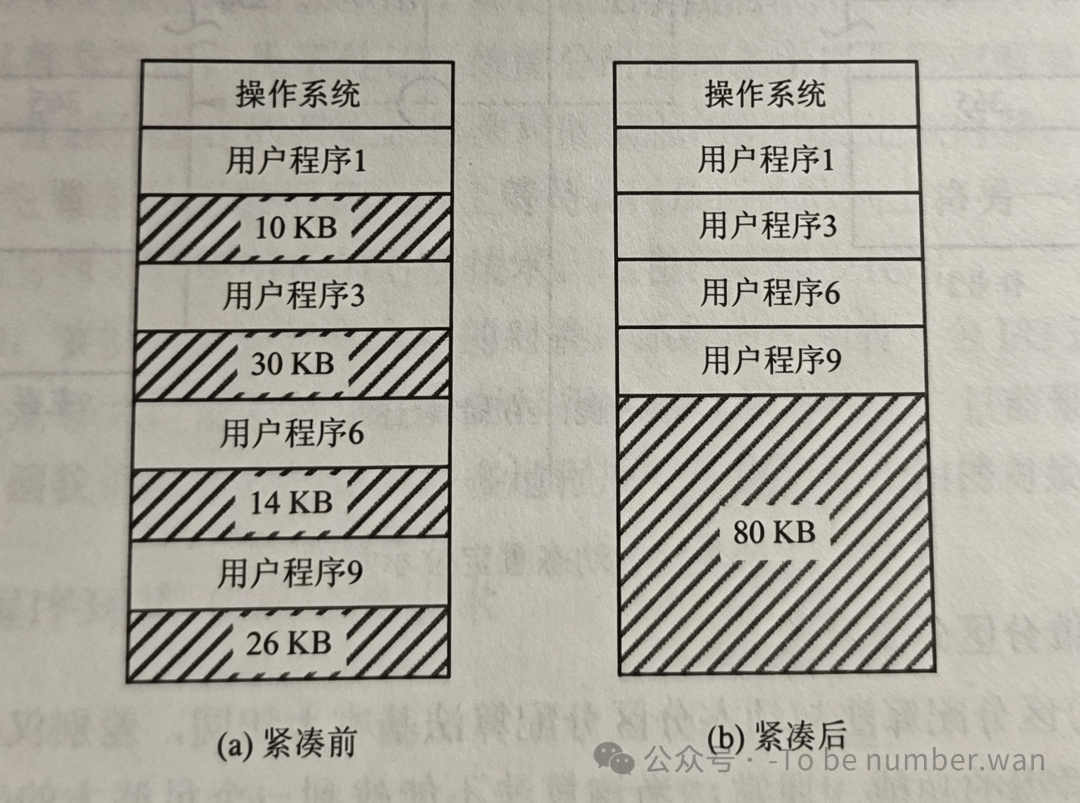
听起来简单,但"搬家"的时候必须对所有移动过的程序和数据做重定位——更新它们所有的地址引用,否则程序就跑飞了。
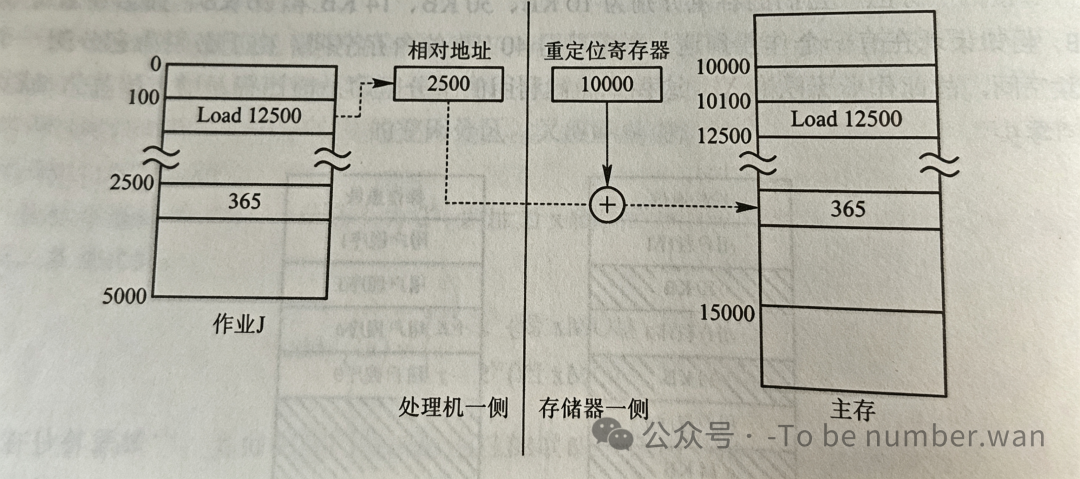
这就引出了动态重定位的概念:在程序运行时,通过硬件的重定位寄存器,把每条指令中的逻辑地址自动加上一个偏移量,变成物理地址。这样程序可以在内存中随意移动,只要更新重定位寄存器中的值就行了。想象一下:你搬家了,但你不用通知所有朋友新地址,只需要在快递站留一个"转寄地址"就行。
动态重定位分区分配算法与动态分区分配的算法基本上相同
四、对换技术:内存不够?先搬出去!
当内存实在不够用的时候,操作系统还有一招——对换(Swapping)。简单说就是把暂时不运行的进程整个搬到磁盘上去(换出),等需要的时候再搬回来(换入)。就像你家客厅太小,客人多了坐不下,就让暂时不聊天的朋友先去阳台待一会儿,需要的时候再叫回来。
对换技术最早出现在多道程序环境下,伴随着处理机的中级调度而产生。对换分为两种类型:整体对换(以进程为单位整个换出换入)和页面对换(以页面为单位进行换出换入,这是后面分页系统的内容了)。
4.1 对换空间的管理
磁盘上要专门划出一块区域作为对换空间(在Linux里叫swap分区,Windows里叫页面文件)。对文件区管理的目标是提高文件存储空间的利用率,而对换空间管理的目标则是提高对换速度——毕竟换出换入越快,系统响应越流畅。
操作系统需要维护一张对换空间的使用情况表,记录哪些块已分配、哪些块空闲。对换空间的分配与回收与内存分配类似,通常也采用空闲链表的方式管理。
4.2 进程的换出与换入
换出时,操作系统需要选择哪个进程被换出去。通常优先选择处于阻塞状态且优先级较低的进程——反正它现在也用不到CPU,让它去磁盘上"休息"最合适。
换出的过程是:
先将进程的状态信息保存到磁盘上,然后把该进程占用的内存空间全部写入对换区,最后修改进程状态为"挂起"。
换入的过程相反:
在对换区中找到该进程的映像,在内存中为它分配空间,读入数据,更新PCB(进程控制块),恢复进程状态。
五、分页存储管理:把内存切成一样大的"格子"
连续分配最大的痛点就是碎片问题。分页存储管理用了一种很聪明的办法彻底解决了它——既然连续分配要求"一整块",那我就把内存切成大小相同的物理块(页框),把程序也切成同样大小的页面,然后像拼拼图一样把页面离散地放进不同的物理块里。
5.1 基本概念
页面和物理块:程序的逻辑地址空间被划分成若干个大小相等的页面(Page),内存空间也被划分成同样大小的物理块(Frame/页框)。比如页面大小定为4KB,那么一个20KB的程序就有5个页面,而内存里也按4KB一个格子来分配。
页面大小的选取很有讲究:太小了页表太长、管理开销大;太大了内部碎片多(最后一页可能浪费掉将近一页的空间)。通常取几百字节到几KB。
地址结构:分页之后,每个逻辑地址被分成两部分——页号(高位)和页内位

移量(低位)。页号告诉你这是第几页,位移量告诉你在这页里面的具体偏移。就像一本书,"第3章第25页"——3是章号,25是页码。
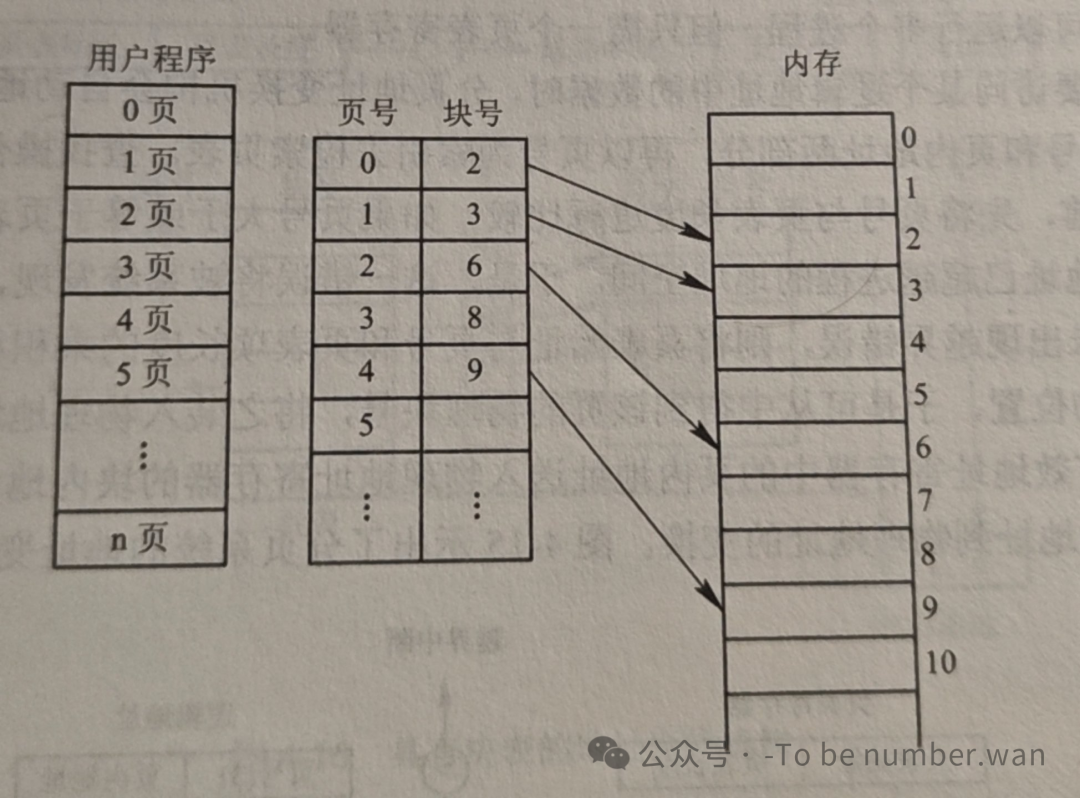
页表:这是分页管理的核心数据结构。每个进程有一张页表,页表的每一项记录了该进程的某个页面在内存中对应的物理块号。换句话说,页表实现了从页号到物理块号的地址映射。程序的第0页可能在物理块第5块,第1页可能在第12块,第2页可能在第3块……离散分配,互不干扰。
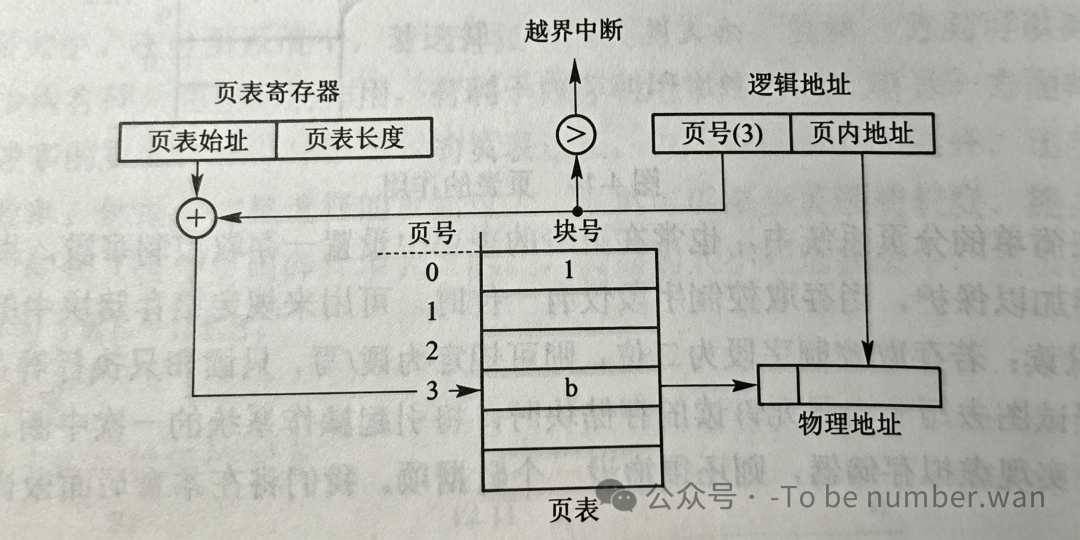
5.2 基本的地址变换机构
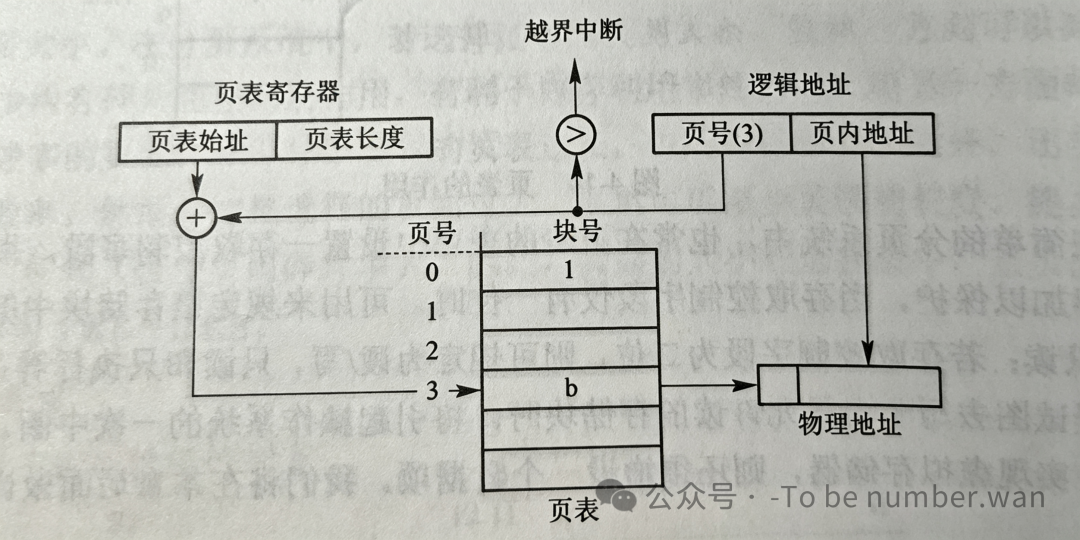
程序运行时,CPU给出的地址是逻辑地址(页号+页内偏移)。分页地址变换机构会自动地将逻辑地址拆分为页号和页内地址。然后以页号为索引,通过页表寄存器去查页表,找到对应的物理块号,再用"物理块号 × 页面大小 + 页内偏移"得到最终的物理地址。
如果页号大于页表长度,说明访问越界了,硬件会立即产生一个越界中断——你想访问的页面根本不存在,这可不是小事。
5.3 快表(TLB):给地址变换加速
每次地址变换都要查页表,而页表是存在内存里的——也就是说,你访问一次数据要先访问一次内存查页表,再访问一次内存取数据,相当于访问时间翻倍了。
为了解决这个问题,人们在CPU内部设了一个快表,也叫TLB(Translation Lookaside Buffer)。快表本质上就是页表的高速缓存,容量很小(通常几十到几百项),但访问速度极快(和Cache同级)。它存放的是最近最常被访问的那些页表项。
地址变换时先查快表:如果命中,直接拿到物理块号,速度飞快;如果未命中,再去内存里查完整的页表,同时把查到的这一项写入快表,供以后快速访问。
访问内存的有效时间在有无快表的情况下差别很大。基本的分页管理方式下,每次内存访问需要两次访存(一次查页表,一次取数据)。
引入快表后,如果快表命中率为α,快表访问时间为t,内存访问时间为m,则有效访问时间大约为:α×(t+m) + (1-α)×(t+m+m)。因为α通常很高(90%以上),所以实际性能提升非常明显。
5.4 多级页表
页表本身也要占内存。对于32位地址空间、4KB页面的系统,页表有 2^20 = 1048576 个表项。如果每个表项4字节,光页表就要4MB内存。如果系统中有几十个进程,页表占用的内存量相当可观。
更糟的是,大多数进程的地址空间中有很多页面其实是不用的(比如中间大段的空白区域),但这些不用的页面对应的页表项仍然要占空间——这很不合理。
多级页表的思路是:为这些离散分配的页表项再建立一张页表,形成页表的页表。以两级页表为例,逻辑地址被拆成三部分:外层页号 + 内层页号 + 页内偏移。
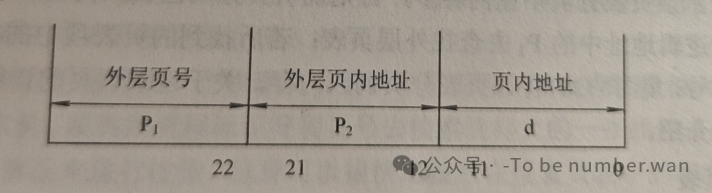
先查外层页表找到内层页表的物理位置,再查内层页表找到实际物理块号。那些完全为空的区域,外层页表项直接标记为"不存在",对应的内层页表根本不需要分配内存。
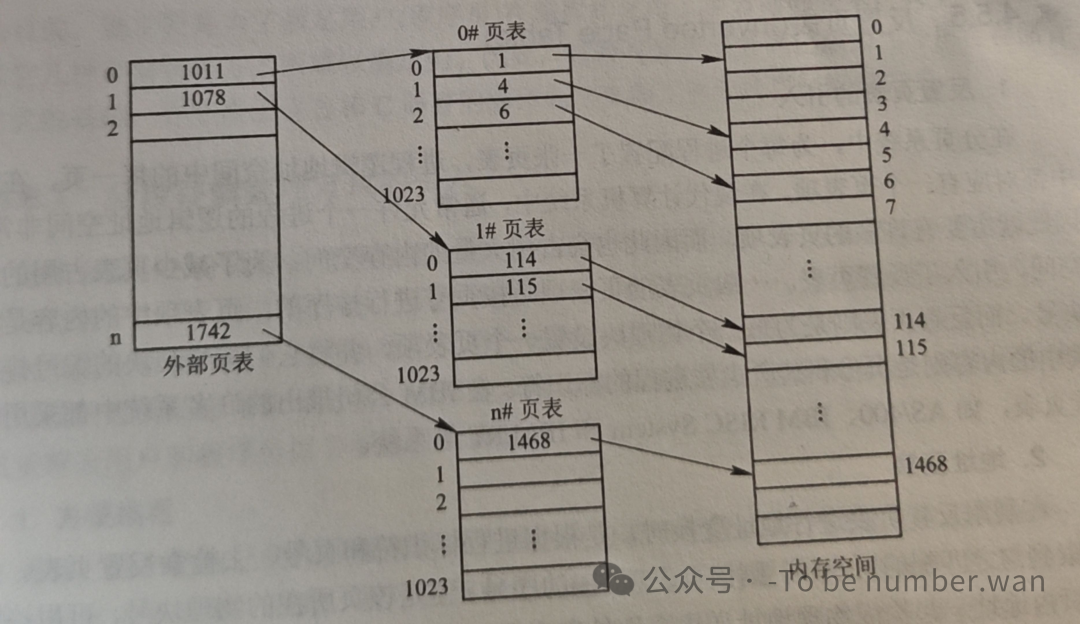
级数可以进一步扩展到三级、四级(x86-64就用了四级页表),但级数越多,查表次数越多,地址变换越慢。所以通常会配合快表来弥补这个开销。
5.5 反置页表
多级页表解决的是"页表太大"的问题,而反置页表换了个角度:既然物理块的数量是固定的,那我就为每一个物理块设一个页表项(而不是为每一个页面设一个),这样页表的大小就只和物理内存的大小有关,跟进程的地址空间大小无关了。
在反置页表中,每个表项记录的是"这个物理块目前被哪个进程的哪个页面占用着"。地址变换时需要根据进程标识符和页号来检索反置页表。
为了加快检索速度,通常会借助哈希技术。反置页表的缺点是查找效率下降,但占用内存确实大大减少了。
六、分段存储管理:按"意义"来分
分页虽然解决了碎片问题,但它是从物理管理的角度出发的——页的划分纯粹是按大小来的,跟程序的逻辑结构毫无关系。这带来了一些不便:程序员想共享某个函数?那个函数可能横跨两个页面。
想对某段代码做保护?你得把整个页面设为受保护,可能误伤同页的其他代码。
分段存储管理换了个思路:按照程序的逻辑结构来划分。一个程序被分成若干个段,每个段有自己的名字(段号),有明确的含义——比如"代码段""数据段""栈段""堆段"。
6.1 分段管理方式的引入
分段带来的好处是多方面的。
方便编程:程序员不用操心物理地址,只需要按"段名+段内偏移"来写程序,符合人类思维。
信息共享变得自然——想共享一个库函数?把它单独放一个段,多个进程指向同一段即可。
信息保护也更灵活——你可以把只读代码段设为"只读"保护,数据段设为"可读写"。
动态增长:某些段(比如数据段)在运行过程中可能变大,分段管理允许段动态扩展而不影响其他段。
动态链接:段的链接可以推迟到运行时,某个段需要时才装入,进一步节省内存。
6.2 分段系统的基本原理
在分段系统中,作业的地址空间被分为若干段,每个段在内存中占用一块连续的存储空间,但各段之间是离散分布的——段A可能在低地址区,段B可能在高地址区,它们不需要挨在一起。
逻辑地址的结构变成了二维的:段号 + 段内地址。这与分页的一维结构(页号+页内偏移)形成了鲜明对比。

段表是分段的灵魂。每个进程有一张段表,段表的每一项包含:段号、段长(该段占多少字节)、段在内存中的起始地址。段表实现了从逻辑段到物理内存区的映射。
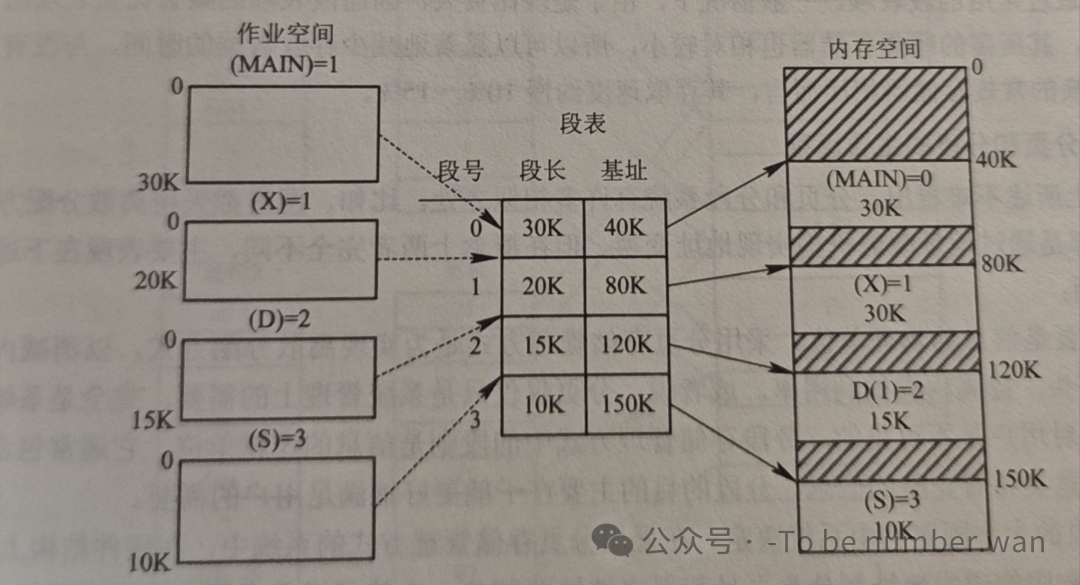
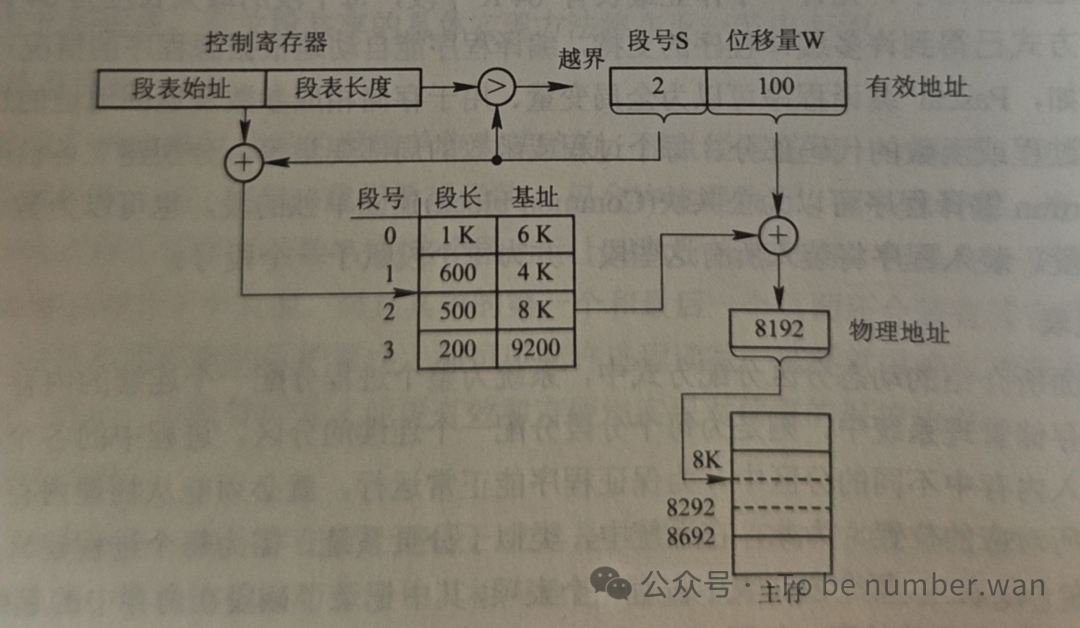
6.3 地址变换机构
地址变换过程如下:CPU给出逻辑地址(段号S,段内偏移d)。系统通过段表寄存器获取段表的起始地址和段表长度。
首先检查段号S是否越界(S是否大于段表长度),越界则产生中断。未越界的话,找到段表中第S项,取出该段的起始地址和段长。再检查段内偏移d是否超过段长,超过则产生越界中断。一切正常的话,用"段起始地址 + 段内偏移d"得到物理地址。
6.4 分页与分段的区别
这是操作系统课程中的经典对比,也是很多人容易混淆的地方:
从性质上看:页是信息的物理单位,分页是出于系统管理上的需要,用户完全感知不到页面的存在。而段是信息的逻辑单位,分段是为了满足用户在编程、共享、保护等方面的需求,用户是能感知到"段"的。
从大小上看:页的大小是固定的,由系统决定(比如4KB、8KB)。段的大小不固定,由程序员或编译器根据逻辑含义来决定——一个函数可以是200字节,一个数组可以是20KB。
从地址空间看:分页的用户程序地址空间是一维的(只有一个线性地址,系统自动拆成页号+偏移)。分段的地址空间是二维的(段号+段内地址,两个维度独立编址)。
6.5 段页式存储管理
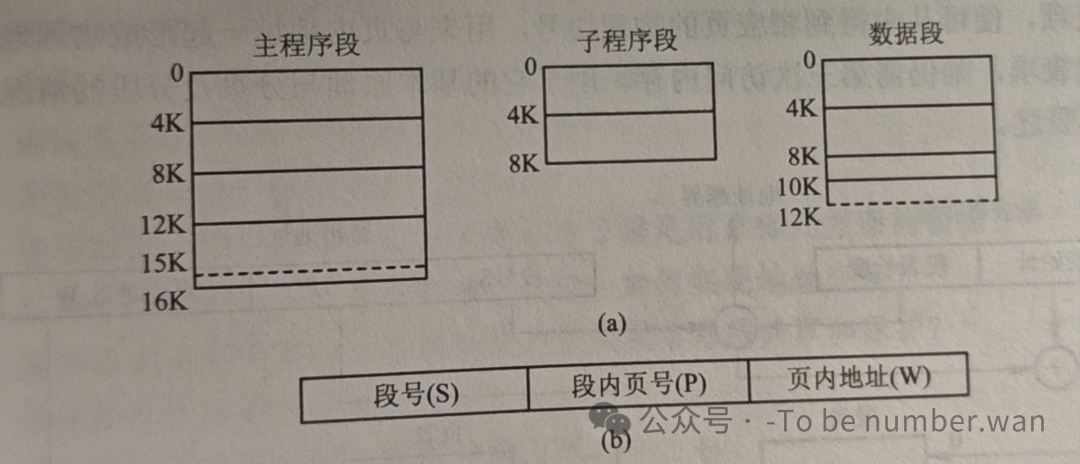
既然分页和分段各有优缺点,为什么不把两者结合起来呢?这就是段页式存储管理。
基本原理是:先将程序分成若干段(按逻辑),再把每个段分成若干页(按大小)。系统同时配置段表和页表:段表记录每个段对应的页表位置,页表记录每页对应的物理块号。
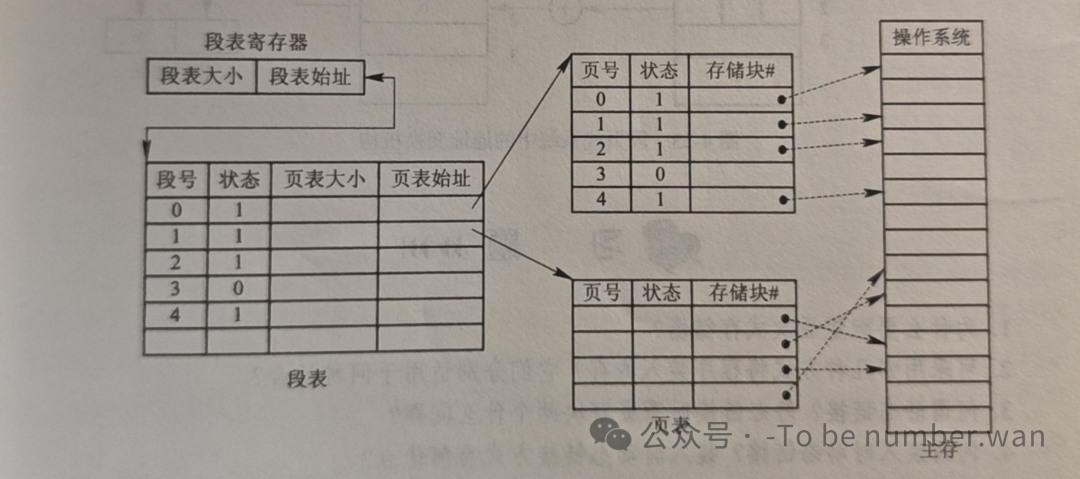
地址变换过程需要进行三次内存访问:
第一次查段表,得到该段页表的起始地址;
第二次查页表,得到物理块号;
第三次才是真正访问目标数据。
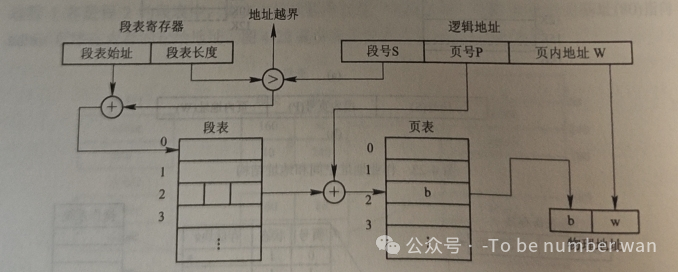
为了加速这个过程,段页式系统同样会设置高速缓冲器(快表)来缓存最近使用的段表和页表项。
段页式综合了两者的优点:既有分段的逻辑清晰、便于共享和保护,又有分页的离散分配、消除碎片。
代价是地址变换更复杂、硬件开销更大。
七、写在最后
从存储器层次结构的金字塔,到程序装入链接的三种方式;从连续分配的六种经典算法,到对换技术的"搬进搬出";从分页的"格子化管理",到分段的"意义化管理",再到段页式的"两手都要抓"——存储器管理这条路,操作系统走了几十年,每一步都是在解决前一步留下的痛点。
没有哪种方案是完美的。连续分配简单但有碎片,分页消除碎片但不够"人性化",分段逻辑清晰但管理复杂,段页式集大成但开销更大。工程世界的魅力就在于此——永远在权衡取舍中找最优解。
下次当你打开一个App、切换一个标签页的时候,想想背后那个默默搬运数据的存储器管家——它可比你自己整理桌面勤快多了。
觉得有用的话,别忘了点赞、在看、转发三连~ 有问题欢迎在评论区讨论!

openEuler 是由开放原子开源基金会孵化的全场景开源操作系统项目,面向数字基础设施四大核心场景(服务器、云计算、边缘计算、嵌入式),全面支持 ARM、x86、RISC-V、loongArch、PowerPC、SW-64 等多样性计算架构
更多推荐
 3
3 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)