操作系统 | 输入输出系统
操作系统のI/O系统全解:从"你等我"到"各干各的"
你有没有想过,当你在键盘上敲下一个字母,CPU是怎么知道有人按了键的?当你把一份文件复制到U盘,数据是怎么从内存跑到磁盘上的?这些看似理所当然的操作背后,隐藏着一个庞大而精密的系统——输入输出系统(I/O System)。
I/O系统是操作系统中"最接地气"的部分,因为它直接和硬件打交道。从你的键盘鼠标,到显示器打印机,再到硬盘SSD,所有外设的读写都得经过它。可以说,没有I/O系统,计算机就是一个只会算数、无法和外界交流的"自闭天才"。
这篇文章,我们把操作系统I/O系统从头到尾扒个干净。准备好,我们要发车了。
本文目录
-
I/O系统概述:它到底在干啥?
-
设备与设备控制器:硬件圈的"上下级关系"
-
I/O控制方式:四代进化史
-
缓冲技术:解决"快慢矛盾"的艺术
-
设备分配:排队也得讲规矩
-
磁盘管理:硬盘里的那些弯弯绕
-
I/O软件体系:软件层的四层蛋糕
一、I/O系统概述:它到底在干啥?
1.1 六大基本功能
I/O系统的存在不是为了炫技,它要解决的是一个非常实际的问题:怎么让高速的CPU和慢速的外设和谐共处。具体来说,它承担了六大职责:
隐藏物理设备细节。 写程序的时候,你只需要说"我要读文件",而不需要关心文件到底存在磁盘的哪个柱面、哪个磁道、哪个扇区。I/O系统把这些脏活累活全包了,程序员只需要面对一个"抽象设备"就好。这就好比你点外卖不需要知道骑手走的哪条路,你只需要知道"饭会到"。
与设备的无关性(设备独立性)。 同一段代码,今天输出到显示器,明天输出到打印机,后天输出到文件,代码一行都不用改。这就是设备独立性——程序不依赖于具体的物理设备。操作系统在中间做了一层"翻译",把逻辑上的"输出"映射到具体的物理设备上。
提高处理机和IO设备的利用率。 CPU的速度是GHz级别的,而键盘每秒也就敲几个字符。如果不做优化,CPU大部分时间都在等外设,利用率低得可怜。I/O系统通过各种手段(中断、DMA、缓冲等)让CPU和外设尽可能并行工作,别互相干等。
对IO设备进行控制。 设备的启动、停止、读写操作,都需要I/O系统发出指令。它就像一个"设备管家",知道什么时候该干嘛,怎么干。
确保设备正确共享。 多个进程可能同时想用同一台打印机或同一块磁盘。I/O系统要负责协调这些请求,保证设备被正确共享,不会因为争抢而出乱子。
错误处理。 磁盘坏道、网络超时、打印机卡纸……外设是计算机里最容易出问题的部分。I/O系统需要能检测、报告并尽可能恢复这些错误,而不是让整个系统直接崩溃。
1.2 系统的层次结构
I/O系统不是一坨铁板,它有着清晰的层次结构。从上到下分为五层:
用户层软件 ——就是你写的程序,通过系统调用来请求I/O操作。设备独立性软件 ——这一层做"翻译",把逻辑设备名映射到物理设备,提供统一的接口。设备驱动程序 ——真正"懂"硬件的软件,每种设备都有自己的驱动。中断处理程序 ——当设备完成操作或出错时,通过中断通知CPU,由这一层处理。硬件 ——最底层,实际的物理设备。
这五层之间有一个核心思想:上层不需要知道下层的实现细节。你的Python代码不需要知道磁盘驱动怎么写的,驱动不需要知道你的代码在干嘛。各管各的,通过接口通信。这就是软件工程里"关注点分离"思想在操作系统中的体现。

I/O系统的五层架构:从用户程序到物理硬件
1.3 系统接口
不同层之间怎么交流?靠接口。I/O系统有三种主要的接口类型:
块设备接口 ——专门给磁盘、SSD这类"块设备"用的。块设备接口隐藏了磁盘的二维结构(柱面、磁头、扇区),对上层暴露的是"读第N个块""写第M个块"这样的抽象命令。上层只需要知道逻辑块号,接口层负责把抽象命令映射为低层的具体操作。
流设备接口 ——给键盘、鼠标、终端这类"字符设备"用的。数据像流水一样一个字符一个字符地传输,没有"块"的概念。操作包括读一个字符、写一个字符、设置终端属性等。
网络通信接口 ——给网卡用的,处理网络数据的收发。Socket就是最典型的网络通信接口。
1.4 I/O软件的设计目标
写I/O软件的时候,有四个核心设计目标:
设备独立性 ——程序不依赖具体设备,换个设备代码不用改。
统一命名与统一接口 ——所有设备都用统一的命名方式(比如Linux里的/dev/sda)和统一的操作接口(read/write/open/close)。
高效性 ——通过异步I/O、缓冲、DMA等手段提高吞吐量。
错误处理 ——错误应该先在驱动层处理(驱动最懂硬件),处理不了的再上报给OS。
二、设备与设备控制器:硬件圈的"上下级关系"
2.1 设备的四种分类方式
计算机外设五花八门,但我们可以从不同维度把它们归归类:
按使用特性 分,设备分成 存储设备(磁盘、SSD、光盘)和 IO设备(键盘、显示器、打印机)两大类。前者主要负责数据存储,后者主要负责人机交互。
按传输速率 分,有 低速设备(键盘、鼠标,每秒几十字符)、中速设备(打印机,每秒几千字符)、高速设备(磁盘、SSD,每秒数百万字符以上)。这个分类直接影响了我们要用什么I/O控制方式来伺候它。
按信息交换单位 分,有 块设备(以"块"为单位传输,可随机寻址,如磁盘)和 字符设备(以字符为单位,不可寻址,如键盘)。块设备就像图书馆,你可以直接说"我要第37本书";字符设备就像自来水龙头,只能一个水珠一个水珠地流。
按共享属性 分,有 独占设备(一段时间只能给一个进程用,如打印机)、共享设备(多个进程可以交替使用,如磁盘)和 虚拟设备(通过SPOOLing技术把独占设备模拟成共享设备)。
2.2 设备与控制器之间的接口
设备和设备控制器之间靠三类信号线通信:数据信号线 传输实际数据,控制信号线 传递控制命令(如启动、停止),状态信号线 反馈设备当前状态(如"忙""就绪""出错")。这三种信号线就像两个人打电话时的"说话""指令""反馈"——你得知道对方在不在、能不能说话、说完了没有。
2.3 设备控制器
设备控制器是CPU和设备之间的"中间人"。CPU不直接操作设备,而是给控制器下命令,控制器再去操作设备。一个控制器可以管一个或多个设备。
控制器的六大基本功能
接受和识别命令 ——控制器有个命令寄存器,CPU把命令写进去,控制器就开始干活。
数据交换 ——控制器有数据寄存器,负责在CPU和设备之间搬运数据。
标识和报告设备状态 ——控制器通过状态寄存器告诉CPU设备现在是忙还是闲、有没有出错。
地址识别 ——在多设备环境下,控制器需要知道自己管的是哪个设备。
数据缓冲区 ——控制器内部有缓冲区,暂时存放正在传输的数据,协调速度差异。
差错控制 ——控制器能做基本的错误检测,比如奇偶校验、CRC校验。
控制器的组成
控制器有三个主要部分:
与处理机的接口 ——连接CPU那一侧,接收CPU的命令和数据。
与设备的接口 ——连接外设那一侧,控制实际设备。
IO逻辑(寄存器组) ——控制器内部的"大脑",由一组寄存器组成,负责解释命令、控制操作流程。
IO端口编址方式
CPU怎么找到控制器的寄存器?
有两种编址方式:
内存映像IO(统一编址) ——把IO端口映射到内存地址空间,用访问内存的指令(如MOV)就能操作IO端口。优点是编程方便,缺点是占用了内存地址空间。
独立编址(IO指令方式) ——IO端口有自己独立的地址空间,需要用专门的IN/OUT指令来访问。优点是不占用内存地址,缺点是需要额外的指令。
三、I/O控制方式:四代进化史
I/O控制方式的发展史,本质上就是一部 "CPU如何从苦逼的搬运工变成甩手掌柜" 的进化史。从最初的全程参与,到最后几乎不用管,一共经历了四个阶段。
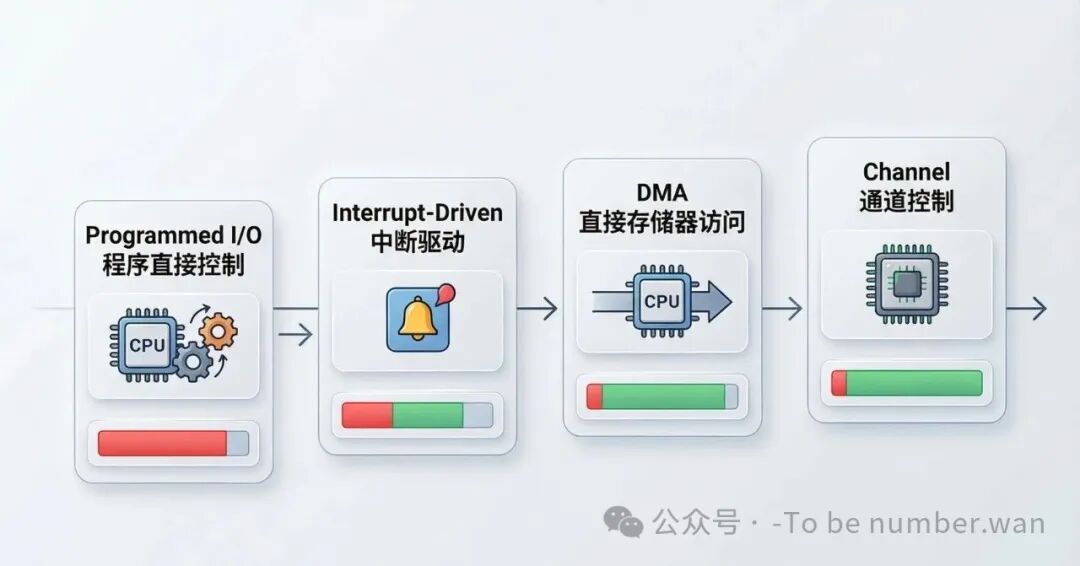
四种I/O控制方式:CPU参与度从高到低的进化
3.1 程序直接控制方式——最原始的"你等我"
最早的方式简单粗暴:CPU直接向IO设备发出命令,然后不停地检查设备的状态(轮询),等设备干完活了CPU才能继续干别的。
这种方式最大的问题就是 忙等待(busy waiting)。CPU就像在等外卖的小哥,一直不停地刷手机看"骑手到哪了",啥也干不了。CPU利用率极低,因为绝大部分时间都在空转等待。这种方式只适用于极低速设备,在现代操作系统中基本已经被淘汰了。
3.2 中断驱动方式——"到了叫我"
改进思路很自然:既然设备忙的时候CPU在干等,那不如让CPU先去干别的事,等设备完成了再通知CPU。
具体做法是:CPU发出IO命令后就去执行其他进程,IO设备完成数据传输后向CPU发一个 中断信号。CPU收到中断后暂停当前工作,转去处理IO结果,处理完再回来继续之前的工作。
这种方式让CPU和IO设备可以 并行工作,CPU不再干等了。但问题是,数据传输是以 字符/字为单位 的,每传一个字符就要中断一次CPU。对于大量数据传输,中断太频繁了,CPU被中断搞得焦头烂额,开销依然很大。
中断机构和中断处理
中断机制有几个核心概念:
中断源识别 ——多个设备可能同时发中断,CPU需要知道是谁发的。
中断优先级 ——不同设备的中断有不同优先级,紧急的先处理。
中断屏蔽 ——可以暂时屏蔽某些中断,防止在处理一个中断时被另一个中断打断。
中断响应过程 ——CPU收到中断后的一系列动作。
中断处理的标准流程是四步:
保存被中断进程的现场(把当前CPU寄存器的值存起来)→ 分析中断原因(谁发的?什么类型的中断?)→ 执行中断处理程序(干该干的活)→ 恢复被中断进程的现场(把之前存的寄存器值恢复回来,继续之前的工作)。
3.3 DMA方式——"搬大块的你来"
DMA(Direct Memory Access,直接存储器访问)的核心思想是:对于大量数据的传输,让一个专门的硬件——DMA控制器(DMAC) 来代替CPU搬运数据。数据直接在设备和内存之间传送,不经过CPU。
DMA以 数据块为单位 传输,而不是一个字符一个字符地传。CPU只需要在开始时告诉DMAC"从哪搬到哪、搬多少",然后就可以去做别的事了。DMAC接管总线,把数据搬完,最后发一个中断告诉CPU"搬完了"。整个过程CPU只在 开始和结束时介入。
DMA控制器的组成
DMAC内部有四个关键寄存器:
内存地址寄存器(MAR) ——存放数据在内存中的目标地址。
数据计数器(DC) ——记录还需要传送的数据量。
数据缓冲寄存器(DBR) ——临时存放正在传送的数据。
控制/状态寄存器 ——控制传送方向、传送方向等。
DMA工作过程
四步走:
①CPU初始化DMA控制器 ——设置源地址、目标地址、传输长度等。
②DMA控制器接管总线 ——CPU让出总线控制权。
③数据块直接传送 ——DMAC一个一个地把数据从设备搬到内存(或反过来)。
④传送完成发中断 ——全部搬完后DMAC发中断通知CPU。
中断方式 vs DMA方式的关键区别: 中断方式以字符为单位,每传一个字符都要中断CPU一次;DMA以块为单位,只有整块传完才中断CPU一次。这就好比收快递——中断方式是每收到一个包裹就去叫你一次,DMA方式是把所有包裹都搬进屋了才叫你签收。
3.4 通道控制方式——"雇个管家"
通道(Channel)本质上是一个 独立的IO处理器,比DMA更"高级"。DMA一次只管一个设备的一次传输,而通道可以同时管理多个设备,自己执行一段 通道程序(由通道指令组成),完成复杂的IO操作序列。
CPU只需要发一条IO指令启动通道,通道就独立执行通道程序完成全部IO操作,最后向CPU发中断报告完成情况。CPU的参与度降到最低——"雇了个管家,啥都不用操心了"。
三种通道类型
字节多路通道 ——连接多台低速字符设备(键盘、打印机等),以分时方式为各设备服务。就像餐厅服务员,给这桌上完菜马上跑去那桌。
数组选择通道 ——连接多台高速块设备(磁盘等),独占方式工作:选中一个设备后一直服务到传完,再换下一个。像出租车,载了一个乘客直到目的地。
数组多路通道 ——也连接多台高速块设备,但支持交叉传送:一个设备在寻道的时候,通道可以去服务另一个设备,提高了效率。像网约车,你等车的时候司机可以先顺路送个外卖。
瓶颈问题
通道硬件很贵(本质上是另一个处理器),所以数量通常很少。
这就可能出现 瓶颈 ——多个设备抢同一个通道,排队等半天,系统吞吐量反而下降。
解决办法是 增加通道与设备之间的通路,让一个设备可以通过多条路径到达多个通道。
CPU与通道的关系
三句话总结:CPU发出IO指令启动通道("管家,帮我搞定这件事")→ 通道独立执行通道程序(管家自己干活去了)→ 通道完成后向CPU发中断("老板,搞定了")。
3.5 四种方式对比
|
控制方式 |
CPU参与度 |
传输单位 |
适用场景 |
效率 |
|---|---|---|---|---|
|
程序直接控制 |
全程参与(忙等) |
字符/字 |
极低速设备 |
最低 |
|
中断驱动 |
参与较少(被中断) |
字符/字 |
低速设备 |
一般 |
|
DMA |
仅首尾介入 |
数据块 |
块设备/批量传输 |
高 |
|
通道 |
几乎不参与 |
数据块 |
大批量/多设备 |
最高 |
四、缓冲技术:解决"快慢矛盾"的艺术
4.1 为什么要搞缓冲?
缓冲技术解决的核心矛盾很简单:CPU太快了,外设太慢了。
CPU处理一个数据可能只要几纳秒,而磁盘读一个数据可能要几毫秒,差了百万倍。如果CPU直接等外设,大部分时间都在发呆。缓冲就是在CPU和外设之间放一个"中间仓库"(缓冲区),外设把数据先堆到缓冲区里,CPU有空了再来取;反过来也一样,CPU把要写的数据丢到缓冲区,外设按自己的节奏慢慢写。
引入缓冲有三个好处:
缓和速度不匹配(这是最主要的目的)、减少中断次数(攒够一批再中断,而不是每次都中断)、提高并行性(CPU处理当前缓冲区数据时,外设可以同时往另一个缓冲区写数据)。
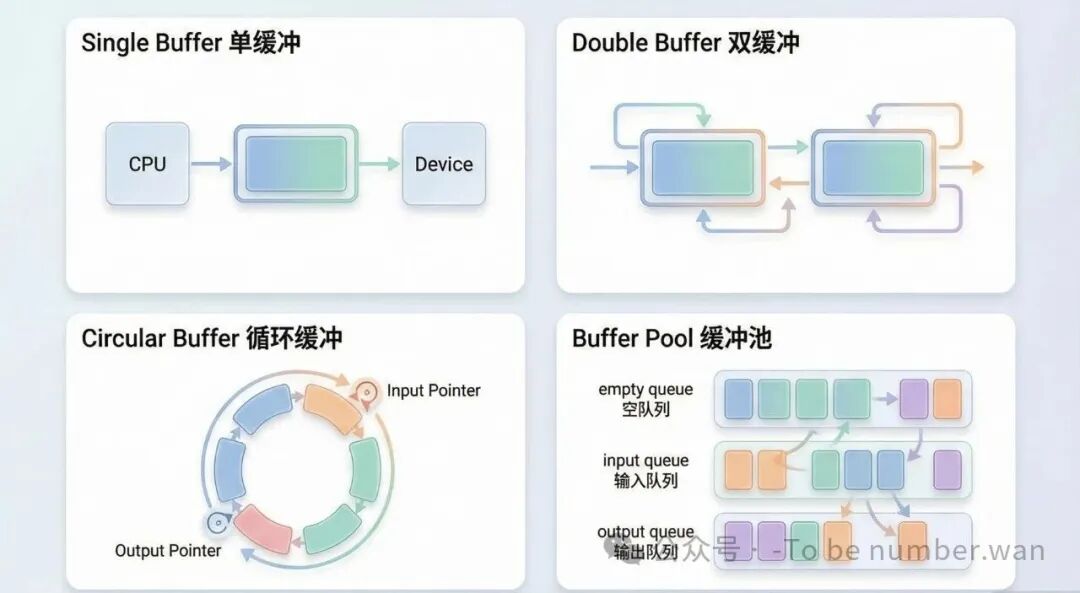
四种缓冲技术对比:从单缓冲到缓冲池
4.2 单缓冲
最简单的方案:只设 一块缓冲区。外设把数据写入缓冲区,CPU从缓冲区读取处理。问题在于,当CPU在处理缓冲区数据时,外设不能往里面写新数据(不然就覆盖了),反之亦然。
处理一块数据的总时间 T = C+ T_transfer,其中 C 是CPU处理时间,T_transfer 是数据传送到缓冲区的时间。说白了就是——谁慢就等谁。
4.3 双缓冲(乒乓缓冲)
两块缓冲区交替使用,就像打乒乓球。外设往缓冲区1写数据时,CPU从缓冲区0读数据;然后反过来。这样CPU和外设可以最大限度地并行工作。
当 CPU处理时间 ≤ 传输时间(C ≤ T_transfer)时,
总时间 T = max(C, T_transfer),相当于没有等待时间。双缓冲特别适合 连续数据流 的场景,比如视频播放、音频流。
4.4 循环缓冲
如果两块还不够,那就搞 多个缓冲区组成一个环形。环中有些缓冲区是空的(等待被填充),有些是满的(等待被读取)。系统维护输入指针和输出指针在环上移动。
当缓冲区数量足够多时,CPU和IO设备可以 完全并行,互不等待。这就是循环缓冲的优势——缓冲区越多,越不容易"追尾"。
4.5 缓冲池
缓冲池是最灵活的方案:多个缓冲区统一管理,根据需要使用。
缓冲池维护三种队列:
空缓冲队列(emq) ——空闲的缓冲区排队等着被用。
装满输入数据的缓冲队列(inq) ——已经从输入设备装好数据的缓冲区。
装满输出数据的缓冲队列(outq) ——已经装好要输出数据的缓冲区。
同时有四种工作缓冲区:
收容输入工作缓冲区(hin) ——输入设备正在往里写数据。
提取输入工作缓冲区(sin) ——CPU正在从里面读数据。
收容输出工作缓冲区(hout) ——CPU正在往里写要输出的数据。
提取输出工作缓冲区(sout) ——输出设备正在从里面取数据。
一个缓冲区可以在这些状态之间流转:空的 → 被选中做hin → 装满后进入inq → 被CPU取走做sin → 取完后回到emq。就像一个"缓冲区生命周期"。
4.6 SPOOLing技术(假脱机)
SPOOLing(Simultaneous Peripheral Operations Online)是个很巧妙的技术:它利用 磁盘来模拟独占设备,让独占设备看起来像共享设备。
最经典的例子就是打印机。打印机是独占设备,一次只能给一个进程打印。但有了SPOOLing之后,每个进程想打印时,先把打印数据写到磁盘的 输出井 里,然后就"以为"自己已经打印完了,可以继续干别的事。系统在后台有个 输出进程,按顺序把输出井里的数据取出来发给打印机。
SPOOLing系统的组成:
输入井和输出井 ——磁盘上的两个区域,分别存放输入数据和输出数据。
输入缓冲区和输出缓冲区 ——内存中的缓冲区。
输入进程和输出进程 ——后台负责实际IO操作的进程。
本质上,SPOOLing是一种 虚拟设备技术。它把一台物理打印机变成了多台"虚拟打印机",每个用户觉得自己独享一台打印机,其实大家都在排队等同一台。就像餐厅的排号系统——你以为你预约了一桌,其实你只是在排队。
五、设备分配:排队也得讲规矩
5.1 四大数据结构
当进程请求使用设备时,操作系统需要通过一套数据结构来管理设备的分配。这套结构分四层,层层递进:
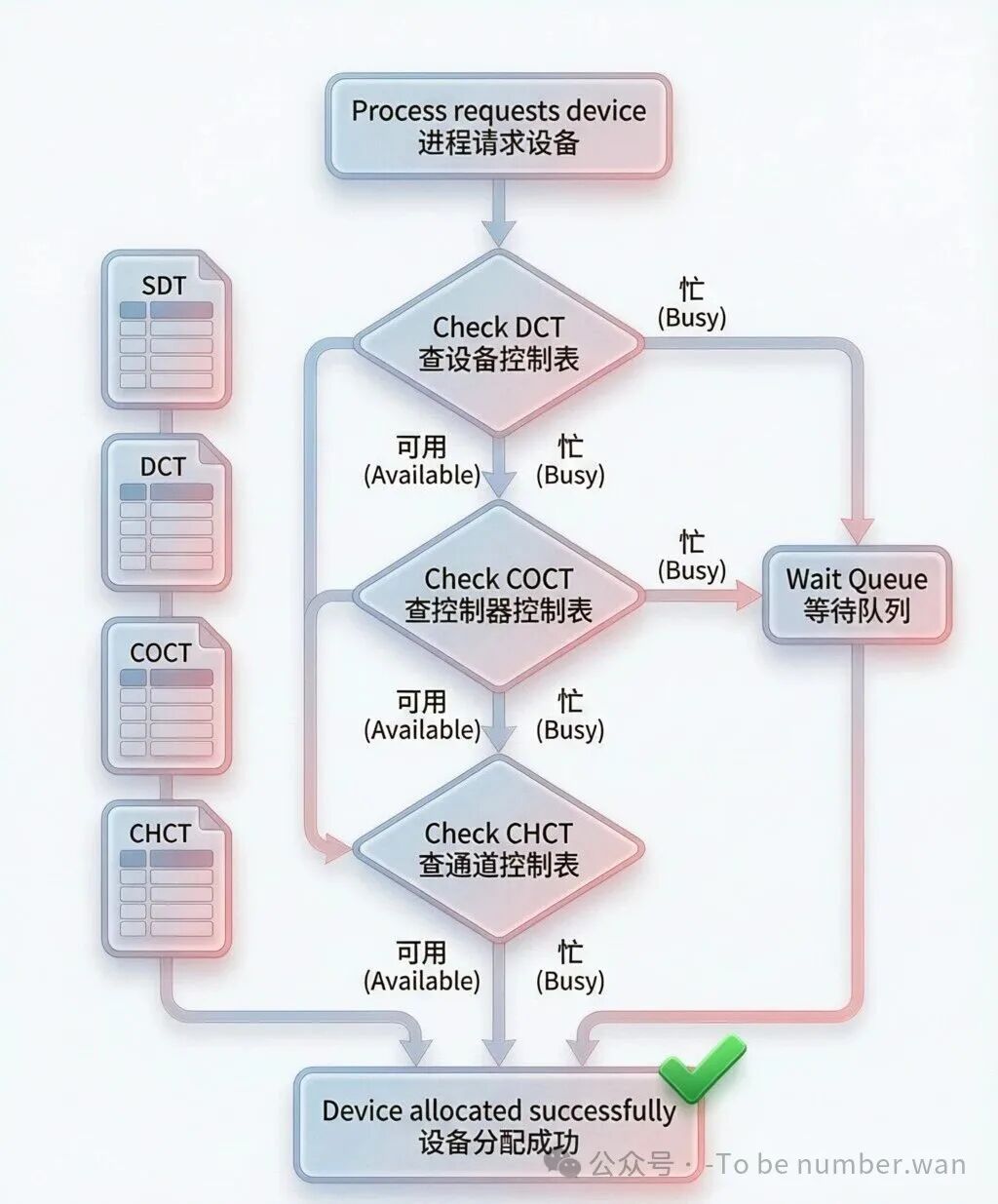
设备分配流程:从SDT到CHCT的层层检查
系统设备表(SDT) ——全系统就一张,记录了所有设备的基本信息(设备类型、标识符、状态等)。这是设备管理的"总台账"。
设备控制表(DCT) ——每台设备一张。记录了设备的类型、标识、当前状态、指向其控制器的COCT的指针,以及等待使用该设备的进程队列。设备忙的时候,想用的进程就得排队。
控制器控制表(COCT) ——每个设备控制器一张。记录控制器的状态和指向其通道的CHCT的指针。一个控制器可以管多个设备。
通道控制表(CHCT) ——每个通道一张。记录通道的状态和等待使用该通道的进程队列。一个通道可以连多个控制器。
这四层关系就像一个"公司组织架构":SDT是公司花名册,DCT是每个员工的档案,COCT是部门经理的档案,CHCT是高管的档案。你要找某个人干活,得一层一层地往上查,看谁有空。
5.2 设备分配策略
当多个进程同时请求设备时,怎么决定先给谁?
有两种基本策略:
先请求先服务(FCFS) ——谁先来谁先用,公平但可能导致某些短作业等太久。
优先级高者优先 ——紧急的进程先用,但可能导致低优先级进程"饿死"。
分配过程中还要考虑 安全性 ——避免死锁。就像借东西,A借了B的笔,B借了C的书,C又想借A的尺子,三个人互相等着,谁也干不了活。
5.3 设备分配过程
当进程请求一个设备时,系统需要按顺序检查三层:
第一步,查DCT ——设备忙不忙?忙就入等待队列。
第二步,查COCT ——设备对应的控制器忙不忙?忙也入等待队列。
第三步,查CHCT ——控制器对应的通道忙不忙?忙还是入等待队列。
只有三层都"空闲",设备才能真正分配给进程。任一环节不可用,进程就得排队。这就好比你要用打印机,不仅打印机得空着,连打印机的控制器、通道都得有空,才能开始打印。
5.4 逻辑设备名到物理设备名的映射
用户程序中使用的是 逻辑设备名(如"打印机"),而实际要操作的是 物理设备名(如"/dev/lp0")。这个映射关系维护在 逻辑设备表(LUT) 中。
LUT是实现设备独立性的关键——程序只关心逻辑名,具体用哪台物理设备由操作系统决定。如果一台打印机坏了,系统可以自动切换到另一台,程序完全无感。
六、磁盘管理:硬盘里的那些弯弯绕
6.1 磁盘的物理结构
磁盘是计算机中最重要的块设备。理解磁盘调度,得先搞清楚它的物理结构。
一个磁盘由若干 盘面(盘片) 叠在一起,每个盘面有一个 磁头 负责读写。盘面上划分为一圈一圈的同心圆,叫 磁道。所有盘面上相同位置的磁道组成一个 柱面。每个磁道又分成若干个 扇区,扇区是磁盘最小的读写单位。
要定位磁盘上的某个数据块,需要三个坐标:柱面号(在哪个柱面上)、磁头号(用哪个磁头/盘面)、扇区号(在磁道的哪个扇区)。这就是磁盘的物理地址。
6.2 磁盘访问时间
读写一个磁盘块需要的时间由三部分组成:
寻道时间 ——磁头从当前位置移动到目标磁道的时间。这是 最耗时的部分,因为涉及机械运动(磁头物理移动),通常在几毫秒量级。
旋转延迟 ——磁头到位了,但目标扇区可能还没转到磁头下面。需要等盘片转一转,平均旋转延迟 = 1/(2 × 转速)。一个7200转的硬盘,平均旋转延迟约4.17毫秒。
传输时间 ——扇区转到磁头下面后,实际读写数据的时间。这通常很短。
总访问时间 = 寻道时间 + 旋转延迟 + 传输时间。
由于寻道时间占比最大,所以 磁盘调度算法的核心目标就是减少寻道时间。
6.3 磁盘调度算法
假设有多个读写请求在排队,先服务哪个?不同的策略就是不同的调度算法。
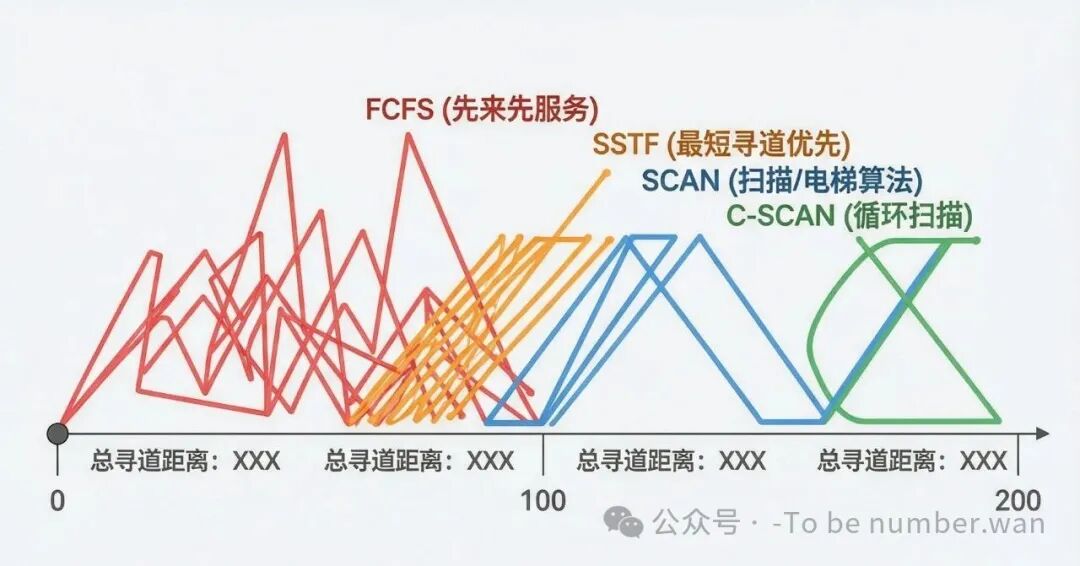
磁盘调度算法对比:不同策略的磁头移动轨迹
先来先服务(FCFS) ——最公平,谁先排队谁先来。但效率最低,因为完全不考虑磁头当前位置,磁头可能在磁盘上来回乱跑,寻道距离很长。
最短寻道时间优先(SSTF) ——每次选离当前磁头位置最近的请求。效率比FCFS高很多,但有一个致命缺陷:可能饥饿。远处的请求可能一直等不到,因为总有更近的新请求插队。
扫描算法(SCAN / 电梯算法) ——磁头像电梯一样,单方向一路扫过去(服务沿途所有请求),扫到头了再掉头往回扫。避免了饥饿问题,因为每个请求最多等一个完整的来回。但缺点是 两侧服务密度不均匀 ——靠近端点的请求等待时间更长。
循环扫描(C-SCAN) ——磁头只在一个方向上服务请求,到了一端后 直接跳回起点(回程不服务),然后重新开始。好处是等待时间更均匀,坏处是回跳那一段浪费了时间。
LOOK算法 ——SCAN的改良版。磁头不一定要扫到磁盘最末端,如果在当前方向上已经没有更多请求了,就 立即反向。减少了不必要的空跑。
C-LOOK算法 ——C-SCAN的LOOK版。单方向扫描,没有请求了就跳回最远端的请求位置继续。
N步SCAN ——把请求队列按时间分为N段子队列,每个子队列内部用SCAN算法。正在服务的子队列中新加入的请求放到下一个子队列里,防止"磁臂粘着"(某个进程不断发请求霸占磁头)。
6.4 磁盘格式化
一块新硬盘不能直接存文件,需要三级格式化:
低级格式化(物理格式化) ——在磁盘上划分磁道和扇区,写入扇区头(标识信息)、数据区和校验码(ECC)。这一步由硬盘厂商在出厂时完成。分区 ——把磁盘分成若干个逻辑分区。写入主引导记录(MBR)和分区表,告诉系统"这块磁盘有几个区,每个区从哪到哪"。
高级格式化(逻辑格式化) ——在分区上创建文件系统,写入引导块、超级块、inode表等元数据结构。这一步之后,操作系统才能在这个分区上创建和管理文件。
6.5 磁盘高速缓存
和CPU缓存类似的思路:用内存来缓存最近访问过的磁盘数据。因为内存速度远快于磁盘,如果后续访问的数据在缓存中(命中),就不需要再访问磁盘了。
缓存满了怎么办?需要置换策略:
最近最少使用(LRU) ——淘汰最久没被访问的数据。
最少使用(LFU) ——淘汰访问次数最少的数据。
同时还需要 周期写盘 ——定期把缓存中修改过的数据刷到磁盘上,防止断电丢失。
6.6 提高磁盘IO速度的其他方法
除了调度算法和缓存,还有几种常用手段:
提前读(预读) ——顺序访问时,把后面可能要读的数据提前读到缓存中。
延迟写 ——写操作不立即写磁盘,先写到缓存,攒一批再统一写。
优化文件物理块分布 ——让同一个文件的块尽量在磁盘上连续存放,减少寻道。
减少磁头移动 ——通过合理分配和调度减少不必要的寻道。
6.7 RAID——廉价冗余磁盘阵列
RAID(Redundant Array of Independent Disks)用多块磁盘组合来提高性能和/或可靠性。不同组合方式形成不同的RAID级别:
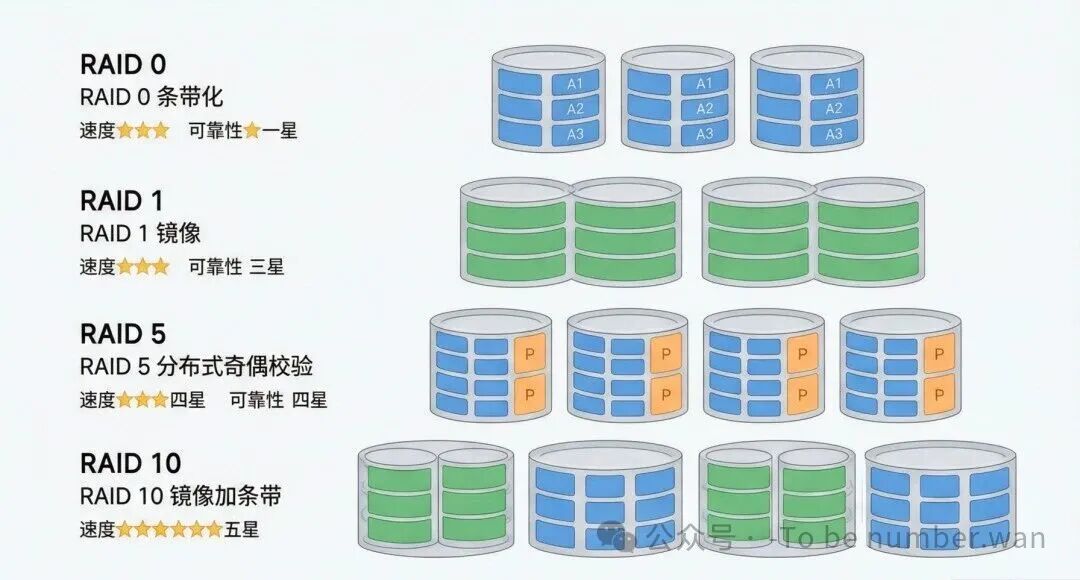
RAID各级别对比:速度、可靠性与成本的权衡
RAID 0(条带化) ——数据被切分成块,交替分布到多块磁盘上。读写可以并行进行,速度成倍提升。但 没有任何冗余,任何一块盘坏了,所有数据全完。就像把一份文件撕成几页分给几个人保管,一个人丢了就全没了。
RAID 1(镜像) ——每块盘都有一个完整的镜像盘,数据同时写到两块盘上。可靠性极高(一块盘坏了还有另一块),但 成本翻倍(实际可用容量只有总容量的一半)。
RAID 2(位级条带 + 海明码) ——数据按位分散到多盘,额外用海明码做校验。实际中很少使用,了解即可。
RAID 3(字节级条带 + 专用校验盘) ——数据按字节分散,有一块专门的盘存放奇偶校验信息。每次读写都涉及所有盘,适合大文件顺序读写。
RAID 4(块级条带 + 专用校验盘) ——和RAID 3类似,但以块为单位分散。校验盘成为写入瓶颈(每次写都要更新校验盘)。
RAID 5(分布式奇偶校验) ——和RAID 4类似,但校验信息 分散存储在所有盘上,而不是集中在一块盘上。解决了RAID 4的校验盘瓶颈问题。允许一块盘故障而不丢数据。这是最常用的RAID级别,兼顾了性能、可靠性和成本。
RAID 6(双重奇偶校验) ——使用两套校验信息,允许 两块盘同时故障。可靠性更高,但写入性能更低。
RAID 10(1+0) ——先做镜像(RAID 1),再做条带化(RAID 0)。高性能 + 高可靠,但成本也最高(至少需要4块盘,可用容量只有50%)。
RAID 01(0+1) ——先做条带化(RAID 0),再做镜像(RAID 1)。看起来和RAID 10差不多,但可靠性更差——条带组中任何一块盘坏,整个条带组都不可用。
七、I/O软件体系:软件层的四层蛋糕
7.1 设计原则
I/O软件的设计遵循三个核心原则:
设备独立性 ——程序不依赖具体的物理设备。
统一性 ——不同类型的设备提供统一的操作接口(不管是磁盘还是键盘,都用read/write/open/close)。
高效性 ——尽可能减少CPU在IO操作中的等待时间。
7.2 用户层I/O软件
最上层,离用户最近。包含三个部分:
系统调用接口 ——如open()、read()、write()、close()等,是应用程序请求IO操作的入口。
库函数 ——如C语言的stdio库(printf、scanf、fopen等),在系统调用基础上封装了更方便的接口。
假脱机系统 ——如打印守护进程(lpd),在后台管理打印队列。
7.3 设备独立性软件
这一层承上启下,做很多"翻译"和"管理"工作:
设备命名 ——在Unix/Linux中,每个设备对应一个 设备特殊文件,放在/dev目录下。比如/dev/sda是第一块SCSI磁盘,/dev/tty是终端。
设备保护 ——检查进程是否有权限访问某个设备(就像文件权限一样)。
缓冲管理 ——决定什么时候读缓冲、什么时候刷缓冲。
设备分配 ——在独占设备场景下,管理设备的分配和回收。
逻辑设备名→物理设备名映射 ——通过LUT把程序使用的逻辑名映射到实际的物理设备。
提供统一设备接口 ——向上层屏蔽不同设备的差异。
7.4 设备驱动程序
驱动程序是I/O软件中最"底层"的部分,与硬件密切相关。每种设备(甚至同种设备的不同型号)都有自己的驱动程序。
驱动程序的职责包括:
接收设备独立性软件的请求(上层说"读第100块")
检查请求合法性(参数对不对?设备状态正不正常?)
将抽象请求转换为设备特定操作(把"读第100块"翻译成"寻道到第N柱面第M磁道第K扇区")
启动设备执行IO操作(向设备控制器发出具体命令)。
驱动程序由两部分组成:
设备启动例程 ——负责启动IO操作。
中断处理例程 ——处理设备完成或出错时的中断。
7.5 中断处理程序
最底层(软件层面),负责处理硬件中断。当中断发生时,中断处理程序:唤醒阻塞的驱动进程(IO完成了,之前等待的进程可以起来了)→ 将IO结果传递给驱动(成功还是失败?传了多少数据?)。
中断处理主要有两种时机:IO完成中断(正常结束)和 IO出错中断(发生错误)。
总结
操作系统的I/O系统是一个"承上启下"的核心模块——对上为应用程序提供方便的设备访问接口,对下管理和协调各种外设的操作。从最底层的硬件设备、设备控制器、通道,到中间层的驱动程序、中断处理、缓冲管理,再到最上层的系统调用和用户接口,每一层都在解决特定的问题。
回顾整个I/O系统的发展脉络,核心矛盾就是 **"快的等慢的"**。为了解决这个矛盾,人们想出了各种办法:中断让CPU不用傻等,DMA让CPU不用亲手搬数据,通道让CPU几乎不用管IO的事;缓冲缩小了速度差,SPOOLing让独占设备变共享;磁盘调度减少寻道时间,RAID用多盘并行提速。
这些机制看似复杂,但背后的思想很朴素:能并行的就并行,能异步的就异步,能少麻烦CPU的就少麻烦CPU。毕竟,CPU是计算机里最贵的"打工人",让它去干搬运工的活,实在太浪费了。

openEuler 是由开放原子开源基金会孵化的全场景开源操作系统项目,面向数字基础设施四大核心场景(服务器、云计算、边缘计算、嵌入式),全面支持 ARM、x86、RISC-V、loongArch、PowerPC、SW-64 等多样性计算架构
更多推荐
 0
0 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)