操作系统 | 文件管理
操作系统の文件系统全解:从"按名存取"到"万物皆可文件"
你有没有想过,当你在电脑上双击打开一个文件,背后到底发生了什么?你以为你是在打开"毕业论文.docx",但对计算机来说,它根本不知道什么叫"毕业论文"——它只知道磁盘上某个位置的一堆0和1。把"文件名"翻译成"磁盘上的数据",这中间的桥梁,就是文件系统。
文件系统是操作系统中最"日常"的部分。你创建文件、删除文件、建文件夹、改权限,每一次操作的背后,都有文件系统在默默干活。可以说,没有文件系统,你的硬盘就是一堆无序的磁信号,跟你家仓库堆了一地杂物没什么区别。
这篇文章,我们把操作系统的文件系统从里到外、从头到脚扒个干净。坐稳了,内容很多,但绝对值得一读。
本文目录
-
文件系统概述:它到底在干啥?
-
文件:一切皆文件的"文件"到底是什么?
-
文件结构:数据怎么存,大有讲究
-
目录管理:文件的"通讯录"
-
文件存储空间管理:磁盘上的"房产管理"
-
文件共享与保护:既能合着用,又不能乱来
-
文件系统实现:VFS与底层的那些事
-
文件操作与系统调用:程序员怎么和文件打交道
-
文件系统性能优化:让读写飞起来
-
常见文件系统:FAT、NTFS、ext4……到底怎么选?
一、文件系统概述:它到底在干啥?
1.1 六大核心功能
文件系统的存在,归根结底是为了解决一个问题:怎么把磁盘上的一堆乱七八糟的数据,变成用户能理解、能操作的"文件"。具体来说,它承担了六大职责:
按名存取。 这是文件系统最基本的功能。用户只需要说"打开 report.docx",文件系统就会自动找到这个文件在磁盘上的具体位置,你不需要关心它到底在第几个柱面、第几个扇区。就像你点外卖只需要说"黄焖鸡",不需要知道后厨在哪个灶台炒的一样。
提供文件的逻辑组织。 用户看到的文件是有结构的——文本文件是一行一行的字,数据库文件是一条一条的记录。文件系统帮助用户把数据组织成需要的逻辑形式,而不是让他们面对裸磁盘块。
实现文件的物理存储。 文件最终要落到磁盘上。文件系统负责决定文件存在磁盘的哪个位置、怎么分配空间、怎么回收空间。这就是"物理存储"的含义——把逻辑上的文件变成物理上的磁盘块。
文件共享。 多个用户或多个进程可能需要同时访问同一个文件。文件系统要支持这种共享,同时保证数据一致性——不能让两个人同时写同一个文件,写出来的结果变成一锅粥。
文件保护。 不是所有人都能看所有文件。老板的财务报表不能让实习生随便改,系统配置文件不能让用户随便删。文件系统要控制"谁能对哪个文件做什么操作"。
提高存取效率。 磁盘是机械运动(HDD)或电信号传输(SSD),速度比内存慢几个数量级。文件系统需要通过索引、缓存、预读等手段,尽可能让文件访问又快又高效。
1.2 文件系统模型:三层结构
文件系统不是一个扁平的模块,它有着清晰的三层模型:
用户调用接口层 ——最顶层,离用户最近。提供文件操作API(open、read、write、close等)和目录操作API(mkdir、rmdir、opendir等)。程序员通过这些接口与文件系统交互,就像你在餐厅通过菜单点菜,不需要知道后厨怎么做的。
文件目录系统层(逻辑文件系统) ——中间层,做"翻译"工作。它管理文件目录,把逻辑文件名映射到物理文件,还负责文件存取控制。就像餐厅的服务员把你说的"宫保鸡丁"翻译成后厨能理解的"3号灶台,鸡丁200g,花生50g"。
存取控制验证层 ——最底层,负责权限检查和用户身份验证。你说要读某个文件,这一层会先检查"你有权限吗?"就像保安在你进大楼之前先看你的工牌。
1.3 文件系统的六层体系
如果再把三层模型细化,文件系统的层次可以展开为六层(从上到下):
用户接口 ——系统调用与命令(ls、cat、cp等)。
目录系统 ——目录管理与查找。
逻辑文件系统 ——文件名到文件的映射。
基本I/O管理 ——块到文件的映射。
基本文件系统 ——物理块的读写。
I/O控制层 ——底层磁盘读写,直接与硬件打交道。
这六层的核心思想与I/O系统一样:上层不需要知道下层的实现细节。你写 fopen("data.txt", "r") 的时候,不需要知道data.txt到底是用连续分配还是索引分配存在磁盘上的。

文件系统的六层架构:从用户接口到硬件控制
二、文件:一切皆文件的"文件"到底是什么?
2.1 文件的定义
教科书上的定义是:具有符号名的、在逻辑上具有完整意义的信息集合。翻译成人话就是——文件就是一堆有意义的数据,给它起了个名字,方便找到它。
更精确地说,文件 = 文件体 + 文件属性。文件体是实际的数据内容,文件属性是描述这个文件的"元信息"(名字多大、在哪放着、谁有权限看)。文件属性存在一个叫文件控制块(FCB) 的数据结构里。
2.2 文件控制块(FCB)
FCB是操作系统为每个文件设置的"身份证"。它包含四类信息:
基本信息 ——文件名、文件类型(文本还是二进制?普通文件还是目录?)、文件的组织形式。
存取控制信息 ——文件主是谁、谁有读写执行权限。
使用信息 ——创建时间、最后修改时间、最后访问时间、当前有多少进程在使用它。
位置信息 ——文件在磁盘上的起始位置、文件大小(占了多少块)。
把所有FCB有序地放在一起,就构成了文件目录。每一个FCB就是一个目录项(目录条目)。当你在命令行敲 ls -l 的时候,看到的那些信息,本质上就是在读FCB。
2.3 文件属性
一个文件的属性通常包括七个方面:
名称(name) ——用户可见的标识符。
类型(type) ——普通文件、目录文件、设备文件等。
位置(location) ——在存储设备上的地址。
大小(size) ——文件占用的字节数或块数。
保护信息(protection) ——读/写/执行权限。
时间信息 ——创建时间、修改时间、访问时间。
所有者(owner) ——文件属于哪个用户。
2.4 文件类型:不只是"文本"和"图片"
按用途分,文件分为三大类:
普通文件 ——包括文本文件(你能读懂的)和二进制文件(机器能读懂的)。
目录文件 ——专门用来组织其他文件的结构,本质上是"文件的容器"。
特殊文件 ——设备文件(块设备如磁盘、字符设备如键盘)、管道文件(进程间通信用的)、链接文件(快捷方式)。
按数据形式分 更简单:
文本文件 ——由字符序列组成,你打开能看懂的。
二进制文件 ——由字节序列组成,打开是一堆乱码但机器能执行。
在Unix/Linux世界里,文件类型更加丰富。用 ls -l 看文件权限的第一个字符就能分辨:- 代表普通文件,d 代表目录文件,b 代表块设备文件,c 代表字符设备文件,p 代表管道文件,l 代表符号链接文件,s 代表套接字文件。七种类型,涵盖了操作系统中几乎所有的"东西"。
Linux哲学名言:"一切皆文件"。 键盘是文件(/dev/input/),显示器是文件(/dev/fb0),进程信息也是文件(/proc/)。这种设计让所有IO操作都可以用统一的接口(read/write)来完成。
2.5 文件访问方式
用户怎么读文件里的数据?
有三种方式:
顺序访问 ——从头到尾依次读写,像听磁带一样,不能跳。
直接访问(随机访问) ——想读哪块就读哪块,像CD一样可以直接跳到第N首。
索引访问 ——通过索引键快速定位,适合数据库这类有结构的文件。
三、文件结构:数据怎么存,大有讲究
3.1 文件的逻辑结构
逻辑结构是用户"看到"的文件组织方式,分为两种:
流式文件(无结构文件) ——文件被看作一串字符/字节的序列,没有任何内部结构。用户自己决定怎么划分内容(按行、按词、按字段随便来)。Unix/Linux采用的就是这种方式——对系统来说,一个文本文件和一个二进制文件没有本质区别,都是一串字节流。
记录式文件(有结构文件) ——文件由若干逻辑记录组成。记录可以是定长的(每条记录等长,像数据库表的行),也可以是变长的(每条记录不等长,像日志文件)。记录的排列方式可以是顺序的、按键值排序的、或者按键值建立索引的。
3.2 文件的物理结构(分配方式)
物理结构是文件在磁盘上的实际存放方式——这才是操作系统真正操心的事情。主要有三种分配方式:
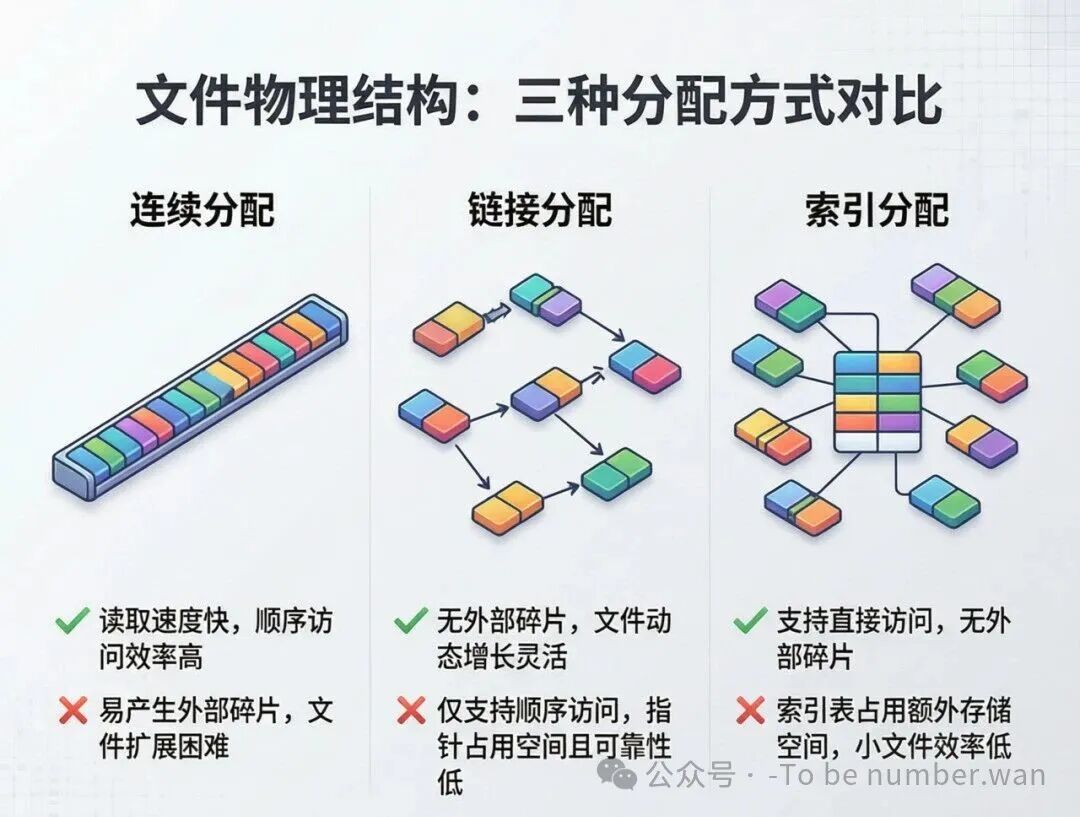
文件物理结构:连续分配、链接分配、索引分配对比
连续分配(顺序结构)
文件的各个部分占据连续的物理块。就像你在图书馆占了一排连续的座位放你的书。只要知道起始块号和文件长度,就能定位任何位置。
优点是顺序存取速度极快(磁头不用跑来跑去),也支持直接访问(第N块 = 起始块 + N,直接算出来)。
缺点是产生外部碎片(文件之间留下不连续的小空隙,太小放不下新文件),而且文件不易扩展(后面的位置可能已经被别人占了)。
链接分配
文件不需要占据连续的物理块,而是通过指针链接在一起。有两种实现方式:
隐式链接 ——每个物理块的末尾存一个指向下一个块的指针,像一条锁链。优点是没有外部碎片,文件容易扩展(随便找个空闲块接上就行)。缺点是只适合顺序访问(想找第100块?得从第1块开始一个一个跟着指针走),而且可靠性差——中间某个块的指针坏了,后面的全丢了,链子断了。
显式链接(FAT文件分配表) ——把链接指针从数据块中抽出来,集中存放在内存里的一张表(FAT表)中。想找下一个块?查FAT表就行,不需要读磁盘。这样既支持直接访问,又提高了检索速度。缺点是FAT表本身要占内存空间,磁盘越大表越大。FAT16、FAT32、exFAT都是采用这种方式。
索引分配
为每个文件建一张索引表,表里记录文件各部分对应的物理块号。索引表本身存在磁盘上的"索引块"中。想找第N块?查索引表直接跳到对应物理块。优点是支持直接访问,无外部碎片。缺点是索引表本身也要占空间——小文件也得有一张索引表。
大文件怎么办?索引表放不下了,有三种方案:
链接方案 ——多个索引块用指针链接起来。
多级索引 ——一级索引指向数据块,二级索引指向一级索引块,三级索引指向二级索引块,层层套娃。
混合索引 ——Unix inode的经典方式:inode中直接存放一部分数据块号(比如10个直接地址),然后有一次间接(指向一个索引块)、二次间接(指向二级索引块)、三次间接(指向三级索引块)。小文件走直接地址,大文件走间接地址,灵活高效。
3.3 三种分配方式对比
|
分配方式 |
顺序访问 |
直接访问 |
外部碎片 |
文件扩展 |
额外开销 |
|---|---|---|---|---|---|
|
连续分配 |
快 |
支持 |
有 |
困难 |
无 |
|
隐式链接 |
快 |
不支持 |
无 |
容易 |
指针空间 |
|
显式链接(FAT) |
快 |
支持 |
无 |
容易 |
FAT表占内存 |
|
索引分配 |
快 |
支持 |
无 |
容易 |
索引块空间 |
四、目录管理:文件的"通讯录"
4.1 目录的功能
目录就是文件的"通讯录"——你知道文件名,通过目录就能找到它在哪。
目录有四大功能:
实现按名存取 ——通过文件名找到文件的物理位置。
提高检索速度 ——好的目录结构能快速定位文件。
支持文件共享 ——多个用户可以通过目录共享同一个文件。
允许文件重名 ——不同目录下可以有同名文件(张三和李四都可以有一个叫"report.docx"的文件)。
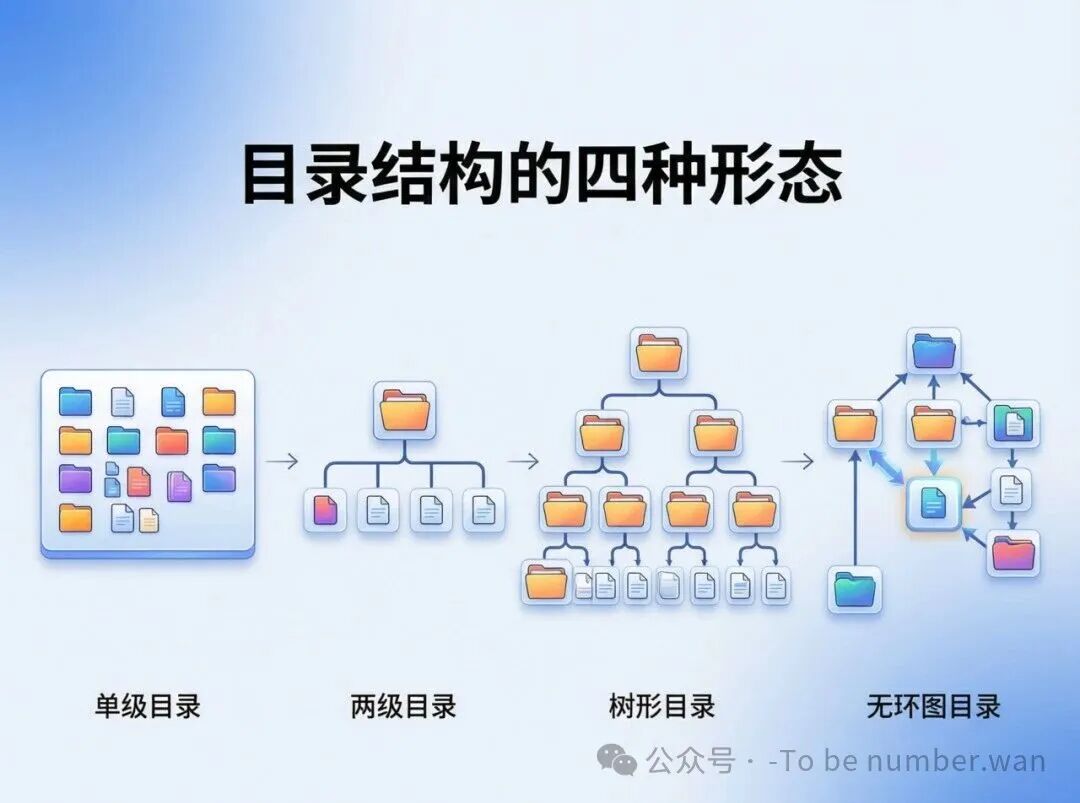
4.2 目录结构类型:从扁平到树形
目录结构的四种形态:从单级到无环图
单级目录
最简单粗暴——全系统就一个目录,所有文件都放在里面。缺点很明显:不允许文件重名(全世界只能有一个report.docx),而且检索慢(文件越多,找起来越费劲)。现代操作系统早已不用这种方式了。
两级目录
为了解决重名问题,引入了两级结构:主文件目录(MFD) 记录每个用户的信息,每个用户有一个用户文件目录(UFD) 存放自己的文件。这样张三和李四可以各自拥有一个叫report.docx的文件,互不干扰。缺点是只能有两层,结构不够灵活。
树形目录(多级目录)
这是目前最主流的方式。从根目录出发,可以有无限层级的子目录,形成一棵倒置的"树"。优点很多:允许重名(不同目录下可以同名)、结构清晰(像公司的组织架构)、便于分类管理。缺点是需要逐层检索,路径太深的时候查找效率会降低。
树形目录引出了路径的概念:绝对路径 从根目录开始写起(如 /home/zhangsan/report.docx),相对路径 从当前工作目录开始(如 ../data/input.csv)。你当前所在的目录叫当前目录(工作目录),用 pwd 命令可以查看。
无环图目录(带共享的目录)
树形目录有个限制:每个文件只能有一个父目录。如果张三和李四都想在自己的目录里直接访问同一个文件怎么办?无环图目录允许文件有多个父目录(共享),形成有向无环图(DAG)。但要注意两个问题:一是避免形成环(A指向B,B又指向A,就死循环了),二是删除时要处理多个链接(不能删了一个链接就把文件也删了,别人还在用呢)。
4.3 目录操作
操作系统提供了一组标准的目录操作:
创建目录(mkdir) ——建一个新的文件夹。
删除目录(rmdir) ——删除一个空目录。
打开目录(opendir) ——准备读取目录内容。
关闭目录(closedir) ——读完收工。
读目录(readdir) ——遍历目录中的条目。
改名(rename) ——给目录换个名字。
查找文件 ——在目录树中搜索特定文件。
4.4 路径解析
当你写 /home/zhangsan/data.txt 的时候,系统怎么找到这个文件?
答案是逐级解析:先查根目录 / 找到 home,再在 /home 下找 zhangsan,最后在 /home/zhangsan 下找 data.txt。每一步都是在目录中查找一个目录项。
为了提高路径解析的速度,系统会使用目录缓存/目录项缓存——把最近访问过的目录信息缓存在内存中。下次再访问同一个目录就不用查磁盘了。
五、文件存储空间管理:磁盘上的"房产管理"
磁盘空间是有限的,就像城市的土地一样。文件系统需要知道哪些"地块"(磁盘块)是空的、哪些已经被占了、怎么高效地分配和回收。这就是文件存储空间管理要解决的问题。
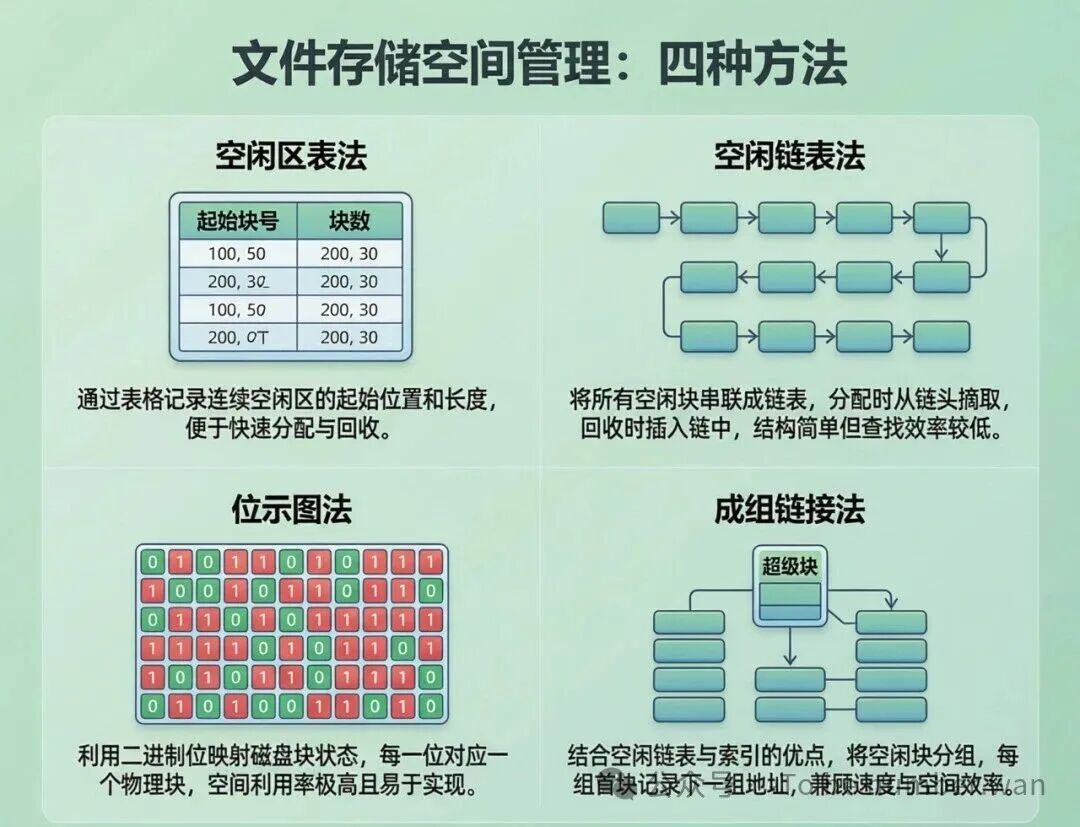
文件存储空间管理:四种方法对比
5.1 空闲区表法
最直观的方式:用一张表记录所有空闲区的起始块号和空闲块数。比如"从第100块开始有5块空闲""从第200块开始有10块空闲"。分配时从表中找一段合适的空闲区,回收时把归还的空闲区登记回表中。
这种方式简单直观,适合连续分配。缺点是空闲区太多时表会很大——磁盘碎片化严重的话,可能有成千上万个小空闲区,表就爆炸了。
5.2 空闲链表法
把空闲块用指针链接起来,形成链表。有两种变体:
空闲块链 ——每个空闲块单独链接,一个接一个。
空闲盘区链 ——把连续的空闲区作为一个整体来链接(减少链表长度)。
优点是分配和回收都很方便——分配就从链头取块,回收就把块插回链中。缺点是链接指针本身也占空间,而且空闲块多的时候链表很长,遍历效率低。
5.3 位示图法(Bitmap)
用一个二进制位数组来表示每个磁盘块的使用状态:0 表示空闲,1 表示已分配。比如一个有1000块的磁盘,位示图只需要125字节(1000 ÷ 8)。
优点非常明显:占用空间极小(1TB磁盘用4KB块,位示图也才32MB),而且容易找到连续的空闲块——在位图中找连续的0就行了。位示图广泛用于各种现代文件系统(ext系列、NTFS等都用到类似思想)。
5.4 成组链接法
这是Unix/Linux的经典方式,设计很巧妙。核心思想是:把空闲块分组,每组最多N个(比如50个)。每组的第一块存放下一组的块数和块号。系统的超级块保存当前组的空闲块信息。
分配的时候,从当前组取一块。如果当前组取完了,就把下一组的信息加载到超级块中。回收的时候,把块放回当前组。如果当前组满了(超过N个),就把满的这一组写到刚回收的那个块里,然后开一个新组。
这种方式的好处是分配和回收都很快——大多数情况下只需要操作超级块中的信息,不需要遍历整个磁盘。坏处是实现稍复杂,不太直观。
六、文件共享与保护:既能合着用,又不能乱来
6.1 文件共享方式
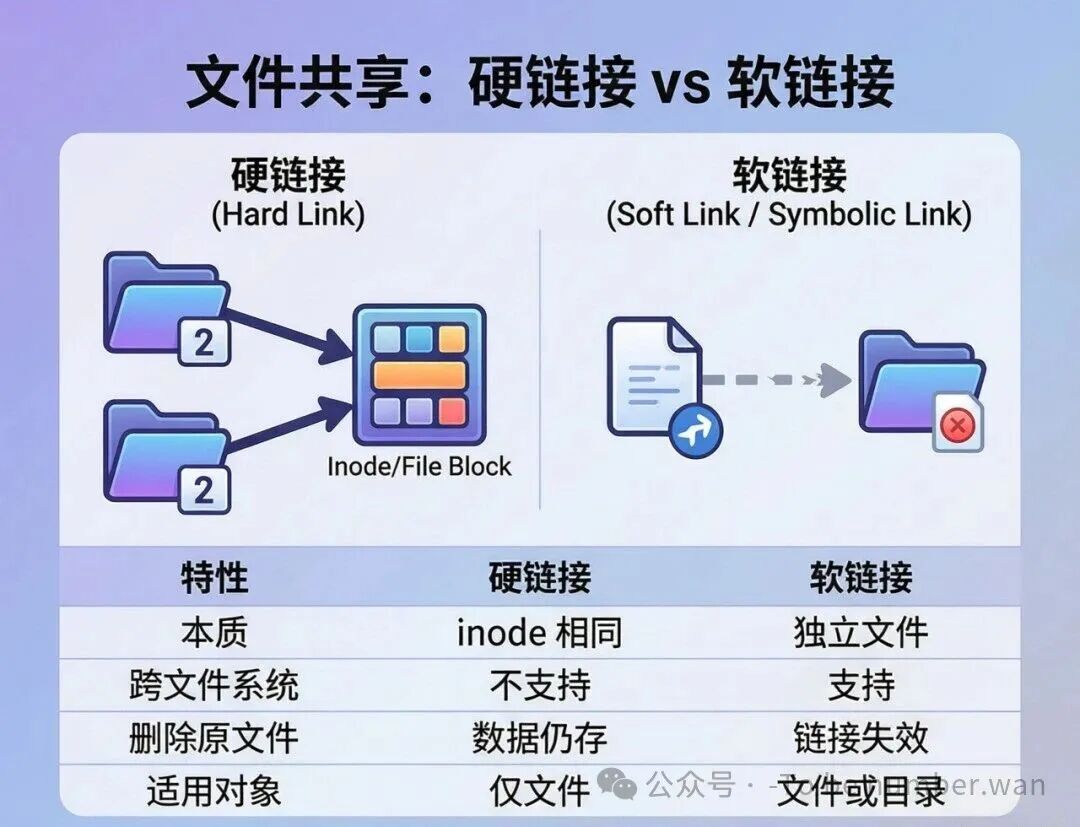
文件共享:硬链接与软链接的区别
基于索引节点的共享(硬链接)
多个目录项指向同一个inode(索引节点)。就像同一套房子有多个门牌号,不管你从哪个门牌号进去,到的都是同一个房子。inode中有一个链接计数(link count),记录有多少个目录项指向它。
删除一个硬链接,只是把链接计数减1,文件不会被真正删除。只有当链接计数变为0(没有任何目录项指向它了),文件的数据块和inode才会被释放。这就是为什么Linux下 rm 命令删除文件时,如果还有其他硬链接存在,文件数据不会丢失。
利用符号链(软链接/快捷方式)
创建一个特殊的LINK类型文件,里面只存一个东西——目标文件的路径名。就像你在桌面上建了一个快捷方式,它本身不是那个程序,只是告诉你"那个程序在C:\Program Files\xxx"。
软链接不影响原文件的链接计数(因为它是独立的文件)。但如果原文件被删除了,软链接就变成了悬空链接(dangling link)——指向一个不存在的地方,就像快捷方式指向的程序被卸载了,双击就报错了。
绕道法
共享文件通过其所在的完整路径间接访问。效率较低,现代系统中很少使用。
6.2 文件保护:四种控制手段
文件系统必须控制"谁能对什么文件做什么"。有四种主要方式:
存取控制矩阵 ——一个二维矩阵,行是用户,列是文件,每个格子里放着权限集合{r, w, x}。概念上最清晰,但实际中矩阵太稀疏(大部分用户对大部分文件没权限),存起来太浪费空间,所以不直接使用。
存取控制表(ACL) ——矩阵按列分割。每个文件有一张ACL,列出"谁对这个文件有什么权限"。Windows NTFS采用的就是ACL方式,可以精确到每个用户。
用户权限表 ——矩阵按行分割。每个用户有一张权限表,列出"我能访问哪些文件,各有什么权限"。
密码(口令) ——最简单粗暴的方式:访问文件时需要提供密码。安全性完全取决于密码强度和管理。
6.3 Unix文件权限模型
Unix/Linux的权限模型非常经典,把用户分成三类:
文件主(owner/user) ——文件的创建者。
同组用户(group) ——和文件主在同一个用户组的人。
其他用户(others) ——剩下的所有人。
每类用户有三种权限:
读(r) ——可读文件内容。
写(w) ——可修改文件内容。
执行(x) ——可执行该文件(如果是目录,表示可以进入该目录)。
用 ls -l 看到的 -rwxr-xr-- 就是这个模型:文件主可以读写执行(rwx),同组用户可以读和执行(r-x),其他人只能读(r--)。用数字表示就是754(rwx=7, r-x=5, r--=4)。chmod 777 就是给所有人所有权限——千万别在生产环境这么干。
七、文件系统实现:VFS与底层的那些事
7.1 虚拟文件系统(VFS)
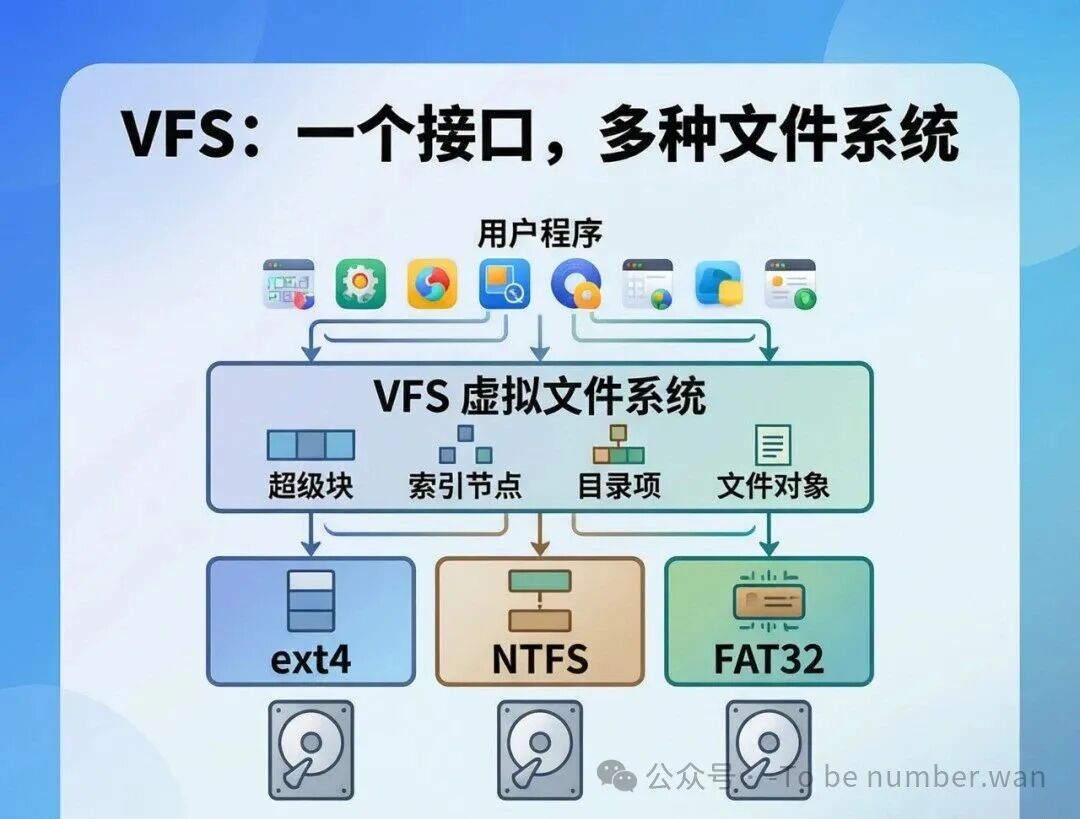
VFS:一个接口,多种文件系统
Linux支持几十种不同的文件系统(ext4、XFS、Btrfs、FAT32、NTFS……),但用户操作文件时用的是同一套命令(ls、cat、cp)。这是怎么做到的?
答案是VFS(Virtual File System,虚拟文件系统)。
VFS的核心思想是:在多种文件系统之上提供一个统一的抽象接口。它屏蔽了底层文件系统的差异,让上层软件不需要关心你用的是ext4还是NTFS。就像Java的"Write Once, Run Anywhere"——VFS让你"写一次代码,跑在任何文件系统上"。
VFS有三大作用:屏蔽底层文件系统差异、提供统一的文件操作接口、支持多种文件系统共存。
Linux VFS定义了四大核心对象:
超级块对象(superblock) ——描述文件系统的整体信息(总块数、空闲块数、块大小等)。
索引节点对象(inode) ——描述单个文件的元信息(大小、权限、时间、数据块位置)。
目录项对象(dentry) ——描述目录层次关系(父目录、子目录、文件名)。
文件对象(file) ——描述一个被打开的文件与某个进程之间的关系(当前读写位置、访问模式)。
当用户调用 read() 时,VFS层先把请求转发给具体文件系统的read实现。就像你打10086投诉,客服(VFS)把你的投诉转给对应的地方营业厅(具体文件系统)去处理。
7.2 文件系统挂载
一个新磁盘(或U盘)插上电脑后,需要挂载(mount) 到目录树的某个节点上,才能被访问。挂载就是"把文件系统连接到目录树的一个位置"。
Linux用 mount 命令完成挂载。挂载点就是目录树中的连接位置——比如把U盘挂载到 /mnt/usb,之后访问 /mnt/usb 就是在访问U盘的内容。系统启动时挂载的第一个文件系统叫根文件系统,挂载在 /(根目录)。
7.3 文件一致性
系统突然断电、崩溃、强制关机的时候,文件系统可能处于不一致状态——比如一个文件的inode说它有100个数据块,但位示图中只标记了98个,有2个块"失踪"了。
传统的解决方式是一致性检查:Unix/Linux用 fsck 命令,Windows用 chkdsk 命令。系统启动时通常会自动运行这些检查工具,发现不一致就修复。但问题是:磁盘越大,检查越慢,有时候开机要等半天。
更优雅的解决方案是日志文件系统(Journaling):在修改文件系统之前,先把"我要做什么"记录到一个日志区域。如果中途崩溃了,重启后根据日志就能恢复到一致状态——要么把操作做完(redo),要么把操作撤销(undo)。典型的日志文件系统包括ext3/ext4、NTFS、ZFS等。
7.4 文件备份
不管文件系统多可靠,备份永远是必须的(硬盘会坏、人会手误删文件)。有三种经典备份策略:
完全备份 ——每次把所有数据都备份一遍。最安全但最耗时耗空间。
增量备份 ——只备份上次备份以来变化的数据。省空间但恢复时需要从完全备份开始逐步叠加。
差异备份 ——备份上次完全备份以来变化的数据。折中方案。Unix/Linux中常用的备份工具是 dump 和 restore。
八、文件操作与系统调用:程序员怎么和文件打交道
8.1 文件基本操作

文件操作的生命周期:从创建到删除
操作系统提供了一组标准的文件操作(系统调用),程序员通过这些接口与文件系统交互:
创建(create) ——在磁盘上分配空间,建立FCB/目录项,登记文件属性。
删除(delete) ——释放磁盘空间,删除目录项。
打开(open) ——把文件的FCB信息读入内存的"打开文件表"中,返回一个文件描述符(一个非负整数)。之后所有对这个文件的操作都通过这个描述符进行,不需要每次都去查磁盘——这就是open的意义,减少磁盘访问次数。
关闭(close) ——把内存中修改过的文件信息写回磁盘,释放内存中的打开文件表项。如果不close就断电,数据可能丢失。
读(read) ——从文件的当前位置读取数据到内存缓冲区。
写(write) ——把内存缓冲区的数据写到文件的当前位置。
定位(seek/lseek) ——移动文件的读写位置指针(不实际读写数据)。
截断(truncate) ——把文件内容清空(大小变为0),但保留文件本身和它的属性。
获取属性(stat) ——读取文件的元信息(大小、权限、时间等)。
修改属性(chmod/chown) ——改权限或改所有者。
重命名(rename) ——给文件换个名字。
8.2 打开文件表
打开文件表分为两级:
系统打开文件表 ——全系统共享一张表,记录每个被打开文件的磁盘信息(inode位置、引用计数等)。共享计数记录有多少个进程打开了这个文件。当共享计数变为0,系统才会真正"关闭"这个文件。
用户打开文件表(进程级) ——每个进程维护自己的一张表,记录文件当前的读写位置指针和访问模式。通过文件描述符(一个非负整数)来索引这张表。前三个描述符是固定的:0 = 标准输入(stdin),1 = 标准输出(stdout),2 = 标准错误(stderr)。所以新打开的文件描述符从3开始。
这种两级设计的好处是:多个进程打开同一个文件时,各自维护自己的读写位置,互不干扰。系统级表则保证文件的物理信息只加载一份,节省内存。
8.3 内存映射文件
这是一种"骚操作":把文件直接映射到进程的虚拟地址空间,然后就可以像操作内存一样操作文件——用指针读写,不需要调用read/write。
Linux中通过 mmap 系统调用实现。好处是:对于大文件的随机访问非常高效(省去了用户空间和内核空间之间的数据拷贝),而且可以用于进程间通信——两个进程映射同一个文件,就能通过这个"共享内存区域"交换数据。
九、文件系统性能优化:让读写飞起来
磁盘是计算机中最慢的部件之一(比CPU慢百万倍)。文件系统必须通过各种优化手段,尽可能缩小这个速度鸿沟。
9.1 磁盘高速缓存(Page Cache)
和CPU缓存的思路一样:用内存缓存最近访问过的磁盘数据。Linux的Page Cache机制把从磁盘读出的数据页缓存在内存中,下次再读同样的数据就不用访问磁盘了——命中时速度快几个数量级。
缓存中的缓冲区有三种状态:
自由缓冲(free) ——还没被使用,随时可以被分配。
清洁缓冲(clean) ——已经缓存了磁盘数据,且内容没有被修改过,和磁盘上的一致。
脏缓冲(dirty) ——内容被修改过,和磁盘上的不一致,需要找机会写回磁盘。
缓存满了怎么办?需要置换策略:
LRU(最近最少使用) ——淘汰最久没被访问的数据。
LFU(最少使用) ——淘汰访问次数最少的数据。
9.2 延迟写(Delayed Write)
写操作不立即写磁盘,而是先写到缓存中标记为"脏",然后在适当的时候统一写回。这样做的好处是可以合并多次小写为一次大写——比如你连续对一个文件做了10次修改,如果没有延迟写,每次都要写磁盘;有了延迟写,可能只需要写一次。
Linux中有专门的pdflush/flush线程定期把脏页写回磁盘。但这种方案有一个风险:断电可能丢失数据——还没来得及写回的脏页会丢失。所以重要的程序会用 fsync() 强制立即写盘。
9.3 提前读(Read-ahead)
当系统在顺序读取一个文件时,它会"猜到"你接下来可能要读后面的数据,于是提前把后续的数据读到缓存中。这样当你真的需要读的时候,数据已经在缓存里了(命中),不用等磁盘。
提前读对顺序访问的效果非常好(比如看视频、读大文件),但对随机访问没什么用。Linux的预读窗口大小是自适应的——如果连续命中,窗口会越来越大;如果频繁不命中,窗口会缩小。
9.4 磁盘碎片整理
随着文件的不断创建和删除,磁盘上会出现碎片。外部碎片是连续分配留下的——文件之间的空隙太小,放不下新的大文件。文件碎片是文件的各个块分散在磁盘的不同位置——读一个文件时磁头要来回跳动,严重降低性能。
碎片整理就是把文件块移动重排,使它们尽量连续存放。Windows有内置的磁盘碎片整理工具。但请注意:SSD不需要碎片整理——SSD没有机械寻道的开销,随机读和顺序读速度差不多,碎片整理对SSD没有性能提升,反而会消耗写入寿命。
9.5 文件块优化
文件系统的"块大小"是一个重要的参数。块太大 ——每个文件浪费的空间多(内部碎片增加,一个1字节的文件也要占一整块),但寻址开销小。块太小 ——内部碎片少,但管理开销大(索引表变大),寻址效率低。需要在两者之间找到平衡点,常见块大小为4KB。
其他优化手段还包括:连续分配优化 ——尽量让文件的块连续存放以减少寻道。预分配 ——创建文件时预先分配一定的空间,避免后续频繁扩展。
十、常见文件系统:FAT、NTFS、ext4……到底怎么选?
10.1 FAT系列——老当益壮的"活化石"
FAT(File Allocation Table)是最古老的文件系统之一,采用显式链接分配。它的家族有四代:
FAT12 ——用于早期软盘,FAT项12位,最大支持几MB的磁盘。现在只能在博物馆见到。
FAT16 ——DOS和Windows 95时代的主力,最大支持2GB分区。当年买个2GB的硬盘都觉得是"海量存储"。
FAT32 ——Windows 95 OSR2引入,最大支持2TB分区,但单个文件最大只能4GB——想存个蓝光电影?对不起,放不下。这也是很多人吐槽FAT32的地方。
exFAT ——专为闪存设备(U盘、SD卡)优化,突破了4GB文件限制,兼容性也好(Windows和macOS都支持)。
FAT系列的共同特点是:简单、兼容性好(几乎所有操作系统都能读写),但没有权限管理、没有日志、可靠性差。U盘默认就是FAT32或exFAT格式。
10.2 NTFS——Windows的"亲儿子"
NTFS(New Technology File System)是从Windows NT开始引入的文件系统,也是Windows XP/7/10/11的默认文件系统。它的核心数据结构是主文件表(MFT)——一张记录所有文件元信息的大表。
NTFS的功能非常丰富:支持ACL权限管理(精确到每个用户的权限)、支持文件加密(EFS)、支持文件压缩、有日志功能(提高可靠性)、支持硬链接和符号链接。基本上你能想到的现代文件系统该有的功能,NTFS都有。
缺点是在非Windows平台上兼容性不好——macOS默认只能读不能写NTFS,Linux需要额外安装ntfs-3g驱动。
10.3 ext系列——Linux的中流砥柱
ext(Extended File System)是Linux世界最经典的文件系统家族:
ext2 ——第二代扩展文件系统,没有日志功能。性能不错但可靠性差——突然断电后需要完整的fsck检查,大磁盘上要跑很久。
ext3 ——在ext2基础上增加了日志功能,崩溃恢复速度大幅提升。但性能因为日志开销略有下降。
ext4 ——目前Linux的主流文件系统,在ext3基础上大幅改进:支持大文件(最大16TB)、引入区段(extent)分配(连续块用一个区间表示,减少碎片和索引开销)、延迟分配(写数据时先不分配块,等到必须写盘时才分配,可以做出更优的分配决策)、多块分配(一次分配多个块)、快速fsck(只检查有问题的部分)。
10.4 其他值得关注的文件系统
XFS ——SGI开发的高性能文件系统,特别适合处理大文件和大吞吐量场景。CentOS 7的默认文件系统就是XFS。支持在线扩容但不支持缩容。
Btrfs(B-tree File System)——被寄予厚望的"下一代Linux文件系统"。四大杀手锏:写时复制(CoW) ——修改数据时不覆盖原数据,而是写到新位置(保证数据完整性)、快照 ——瞬间创建文件系统的完整副本(因为CoW,几乎不占空间)、校验和 ——检测数据静默损坏(bit rot)、内置RAID支持。但由于性能和稳定性问题,目前还没完全取代ext4。
ZFS ——Sun Microsystems开发的企业级文件系统,号称"最后一个文件系统"。它是128位文件系统(理论容量大到不可思议),集成了数据校验、快照与克隆、内置RAID等功能。在服务器和NAS领域非常流行。
APFS(Apple File System)——macOS和iOS的默认文件系统,取代了老旧的HFS+。支持写时复制、快照、克隆、加密等现代特性。专为SSD优化。
HFS+ ——macOS的旧默认文件系统,从Mac OS 8.1用到macOS Sierra,已经被APFS取代。
ISO 9660 ——CD/DVD光盘的标准文件系统。如果你刻录过光盘,用的就是它。
ReFS(Resilient File System)——微软为Windows Server开发的新一代文件系统,主打数据弹性和自动修复能力。目前还在发展中。
总结
文件系统是操作系统中最"日常"却最"庞大"的子系统。从你双击一个图标打开文件的那一刻起,背后就经历了一连串的操作:路径解析(在目录树中查找)→ 权限验证(你有没有权限打开)→ 查找inode(找到文件的物理位置)→ 分配缓冲区 → 读数据块 → 返回给用户程序。这整个过程在毫秒级别完成,你几乎感觉不到。
回顾整个文件系统的知识体系,核心矛盾是"逻辑与物理的映射"——用户看到的是"文件",系统操作的是"磁盘块"。文件系统的所有机制,本质上都在解决这个映射问题:FCB记录文件属性,目录组织文件结构,分配方式决定物理存储,空闲管理追踪可用空间,VFS统一多种文件系统的接口,缓存和预读缩小速度鸿沟。
一句话总结:文件系统就是让"一堆磁信号"变成"用户能理解的文件"的全部魔法。

openEuler 是由开放原子开源基金会孵化的全场景开源操作系统项目,面向数字基础设施四大核心场景(服务器、云计算、边缘计算、嵌入式),全面支持 ARM、x86、RISC-V、loongArch、PowerPC、SW-64 等多样性计算架构
更多推荐
 6
6 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)