操作系统 | 磁盘存储器的管理
操作系统の磁盘存储器管理全解:让"最慢的家伙"跑得快一点
你有没有想过,为什么你的电脑有时候会"卡"一下?尤其是打开一个大文件或者启动一个大型游戏的时候,明明CPU在GHz级别狂跑,却还是要等上好几秒?答案很简单——CPU在等磁盘。在计算机的所有部件中,磁盘是那个"拖后腿的",速度比内存慢几百万倍。怎么让这个"最慢的家伙"尽量跑得快一点,就是磁盘存储器管理要解决的核心问题。
这篇文章,我们把操作系统中关于磁盘管理的知识从头到尾扒个干净——从磁盘长啥样、读写一次要多久、到怎么调度请求、怎么分配空间、怎么格式化、怎么提速、怎么搞RAID,一个都不落。坐稳了,发车。
本文目录
-
磁盘存储器概述:存储界的"阶级划分"
-
磁盘的物理结构与访问时间:一次读写到底要多久?
-
磁盘调度算法:排队也得讲策略
-
外存分配方式:文件在磁盘上怎么摆?
-
磁盘空间管理:谁占着地,谁空着?
-
磁盘格式化:新硬盘到手,怎么从"白板"变"可用"?
-
磁盘高速缓存:用内存帮磁盘"打辅助"
-
提高磁盘I/O速度的方法:各种加速骚操作
-
RAID:多块盘组队,又快又稳
一、磁盘存储器概述:存储界的"阶级划分"
1.1 存储层次
计算机的存储不是扁平的,它是一个清晰的金字塔结构。从上到下依次为:寄存器 → 高速缓存(Cache) → 主存(内存/RAM) → 磁盘(HDD/SSD) → 磁带/光盘。
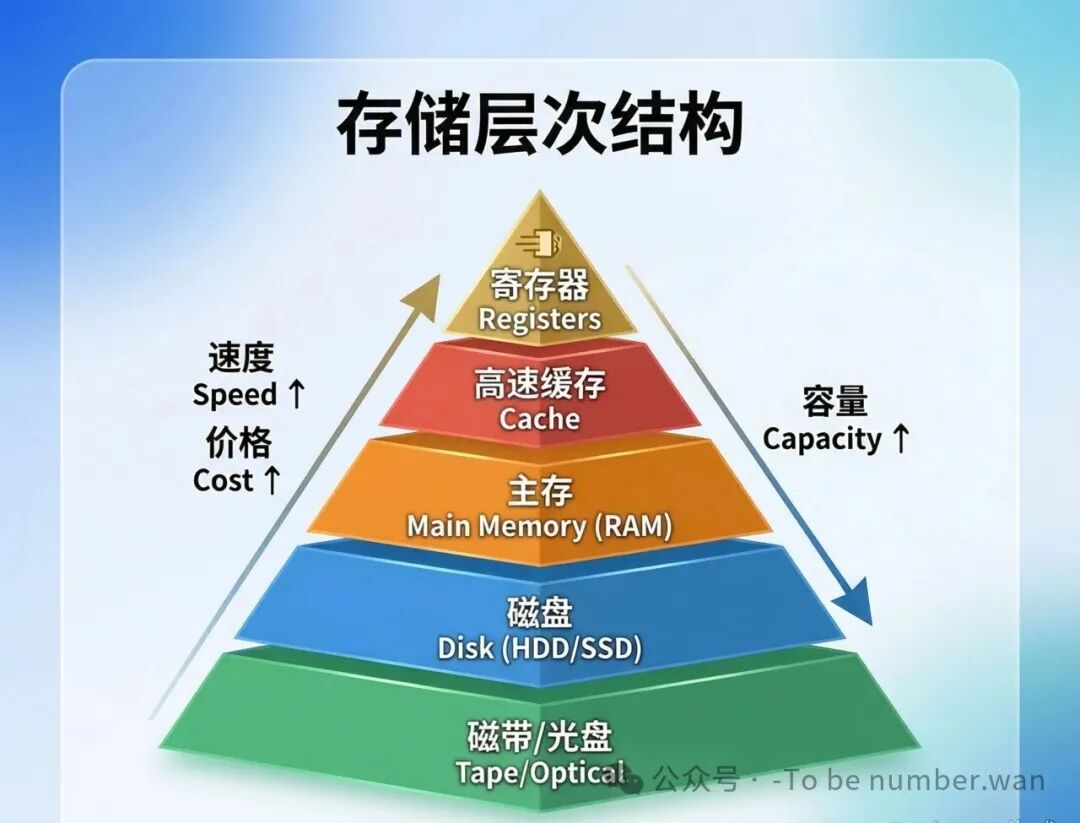
存储层次结构:速度、容量与价格的权衡
越往上,速度越快、容量越小、价格越贵。寄存器在CPU内部,访问速度是皮秒级;Cache也是芯片级的,纳秒级;主存(内存条)也是纳秒级但比Cache慢几倍;磁盘是毫秒级——比内存慢了几百万倍。磁带和光盘更慢,但胜在容量极大、价格极低,主要用来做归档和备份。
磁盘属于辅助存储器(外存)——CPU不能直接访问外存中的数据,必须先把数据读到内存里,CPU才能处理。所以磁盘和内存之间的数据搬运效率,直接决定了整个系统的"体感速度"。
1.2 磁盘的分类
硬盘驱动器(HDD) ——传统的机械硬盘,也叫温切斯特磁盘(Winchester Disk)。内部有盘片在旋转、磁头在寻道,是纯机械结构。优点是容量大、价格低;缺点是速度慢(毫秒级)、怕震动。
固态硬盘(SSD) ——基于闪存(Flash Memory),没有机械部件。随机访问速度远快于HDD(微秒级),抗震性好。缺点是写入有寿命限制(闪存有擦写次数上限,一般几千到几万次),价格较高但在持续下降。
磁带 ——顺序存取设备,不能随机访问。容量极大(单盘可达数十TB),价格极低。主要用于企业级归档和冷数据备份。你不会在日常使用中直接接触磁带,但很多大公司的数据中心里堆满了磁带柜。
光盘 ——包括CD(700MB)、DVD(4.7~17GB)、蓝光(25~100GB)。有只读型(ROM)、一次写入型(R)和可重写型(RW)三种。现在用得越来越少了,但在软件分发和影音领域还有一席之地。
1.3 磁盘设备的特点
磁盘(不管是HDD还是SSD)有几个共同特点:
它是块设备——以块(扇区)为单位进行读写,不是像键盘那样一个字符一个字符地传。
它可随机访问——可以直接跳到任意块,不需要从头开始。
它是共享设备——多个进程可以交替使用同一块磁盘。
最关键的是,它速度远慢于主存——毫秒 vs 纳秒,差了六个数量级。
二、磁盘的物理结构与访问时间:一次读写到底要多久?
2.1 磁盘的物理结构
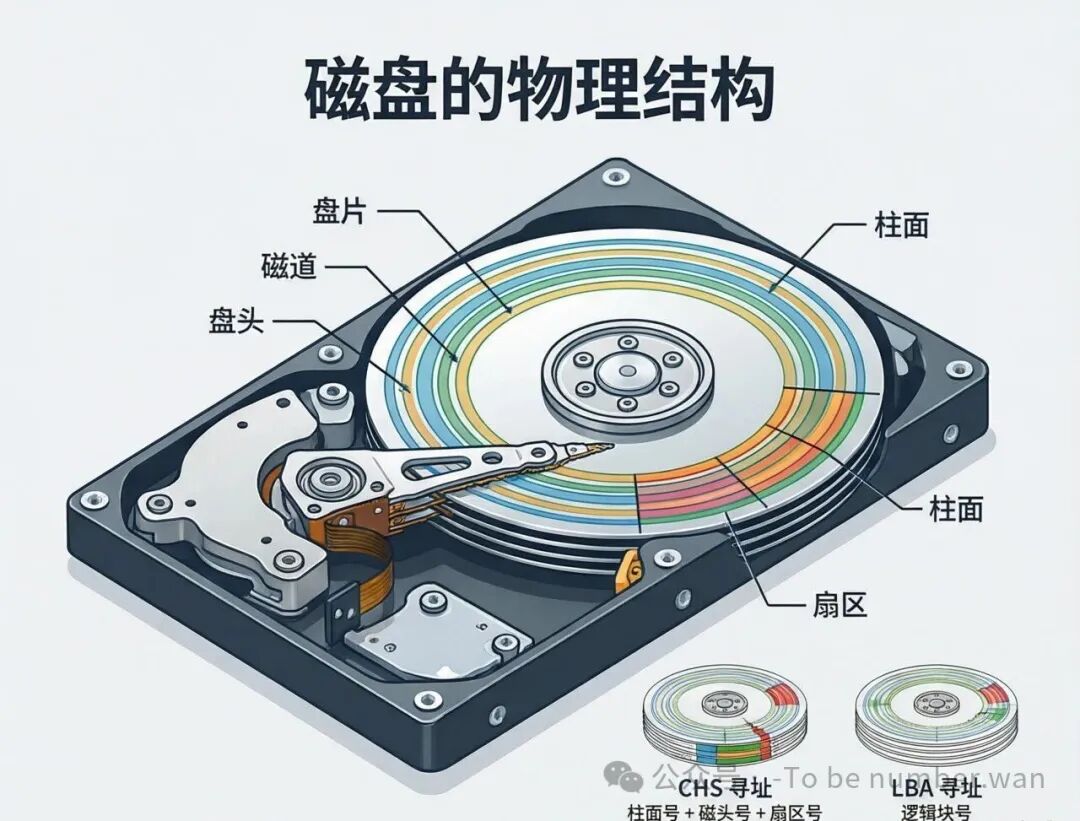
磁盘的物理结构:盘面、磁道、柱面与扇区
传统机械硬盘(HDD)的物理结构可以用几个关键词来概括:
盘面(Platter) ——磁盘由多个盘片叠在一起,每个盘片有上下两个面,每个面都能存数据。每个盘面配有一个磁头(Head),负责读写数据。所有磁头安装在一个共同的臂上,同时移动——也就是说,所有磁头永远在同一个柱面上。
磁道(Track) ——盘面上划了一圈一圈的同心圆,每一圈就是一个磁道。外圈的磁道比内圈长,在现代磁盘中,外圈磁道可能有更多的扇区。
柱面(Cylinder) ——所有盘面上相同位置的磁道组成一个柱面。柱面数 = 每面的磁道数。寻道的时候,磁头一起移动到一个柱面,然后选择对应的磁头来读写。
扇区(Sector) ——每个磁道被分成若干段,每段就是一个扇区。扇区是磁盘最小的读写单位。传统扇区大小是512字节,现代磁盘采用高级格式化(Advanced Format),扇区大小为4KB。
要定位磁盘上的某一块数据,需要三个坐标:柱面号 + 磁头号 + 扇区号,这叫CHS寻址(Cylinder-Head-Sector)。现代磁盘更多使用LBA(逻辑块寻址)——把所有扇区编成连续的线性地址(0, 1, 2, 3...),由磁盘控制器内部负责LBA到CHS的转换。
2.2 磁盘访问时间
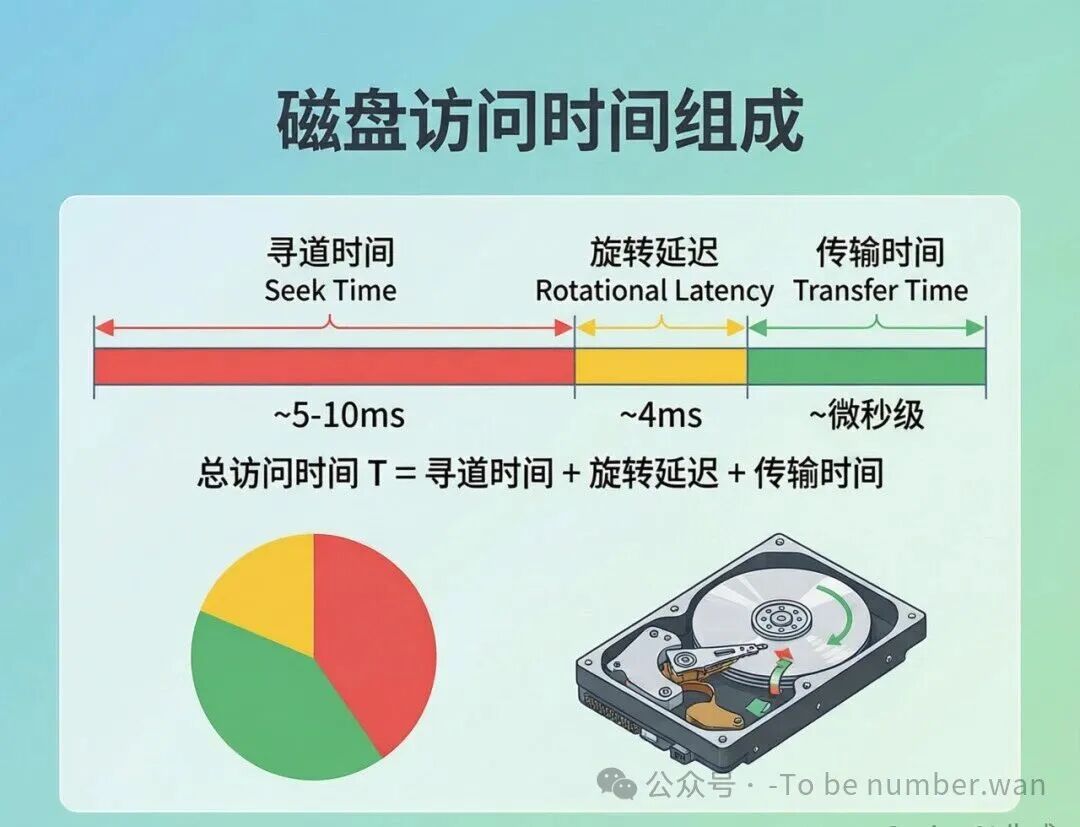
磁盘访问时间的三个组成部分
读写一个磁盘块,需要的时间由三部分组成:
寻道时间(Seek Time) ——磁头从当前磁道移动到目标磁道的时间。这是最耗时的部分,因为涉及机械运动(磁头物理移动)。寻道时间 = 启动时间 + 移动时间 + 减速时间。典型硬盘的平均寻道时间在5~10毫秒。
旋转延迟(Rotational Latency) ——磁头到达目标磁道了,但目标扇区可能还没转到磁头下面。需要等盘片转一转。平均旋转延迟 = 1/(2 × 转速)。7200转/分的硬盘,转一圈约8.33毫秒,平均旋转延迟约4.17毫秒。15000转的企业级硬盘,平均旋转延迟约2毫秒。
传输时间(Transfer Time) ——扇区转到磁头下面后,实际读写数据的时间。通常很短,在微秒级别。
总访问时间 T = 寻道时间 + 旋转延迟 + 传输时间。由于寻道时间占比最大,所以磁盘调度算法的核心目标就是减少寻道时间——让磁头尽量少跑、跑短路。
2.3 磁盘的I/O请求
进程发出的磁盘I/O请求通常包含以下信息:进程标识(谁发的)、操作类型(读还是写)、数据在内存中的起始地址(数据搬到内存哪/从内存哪搬来)、数据在磁盘上的起始位置(柱面号、磁头号、扇区号)、传输的数据量(要读写多少个扇区)。
多个I/O请求会排队等待服务,形成一个请求队列。磁盘调度算法就是决定"先服务队列中的哪个请求"的策略。
三、磁盘调度算法:排队也得讲策略
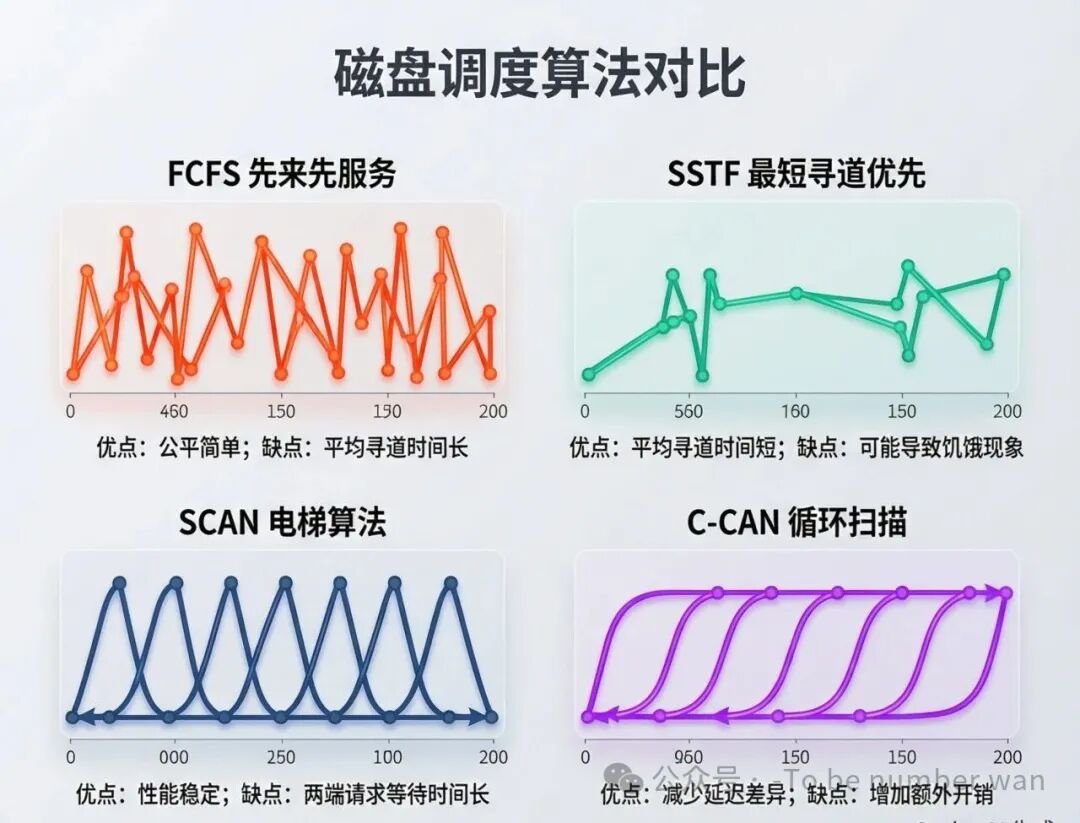
磁盘调度算法对比:不同策略的磁头移动轨迹
假设有多个读写请求在排队,先服务哪个?不同的策略就是不同的调度算法。调度的目标有三个:减少平均寻道时间、提高I/O吞吐量、保证公平性(避免饥饿)。
3.1 FCFS(先来先服务)
最简单的策略:谁先来谁先被服务。优点是完全公平,不会有饥饿问题。缺点是完全不考虑磁头当前位置,磁头可能在磁盘上来回乱跑,寻道距离很长。平均寻道时间是所有算法中最长的。就像餐厅叫号完全按顺序来,不管你坐在哪个位置,服务员得满场跑。
3.2 SSTF(最短寻道时间优先)
每次选离当前磁头位置最近的请求。效率比FCFS高很多——磁头尽量就近服务,减少了大量不必要的移动。
但有一个致命缺陷:可能导致饥饿。远处的请求可能一直等不到,因为总有更近的新请求插队。这就像一个贪心算法——每一步都选当前最优,但不保证全局最优。
3.3 SCAN(扫描算法/电梯算法)
磁头像电梯一样工作:单方向一路扫过去,沿途服务所有请求,扫到磁盘一端后反向继续扫。就像电梯从1楼上到顶楼,再从顶楼下到1楼。
优点:无饥饿——每个请求最多等一个完整的来回(电梯总会扫到你那一层)。缺点是两端服务密度不均匀——靠近端点的请求等待时间更长,因为磁头要到端点才掉头。另外,磁头刚扫过的方向上,新来的请求要等整个回程才能被服务。
3.4 C-SCAN(循环扫描)
磁头只在一个方向上服务请求(比如从左到右),到达一端后直接跳回起点(回程不服务任何请求),然后重新开始。
好处是等待时间更均匀——每个请求最多等一个完整的单向扫描周期。坏处是回跳那一段浪费了时间(空跑)。适合请求分布比较均匀的场景。
3.5 LOOK算法
SCAN的改良版。磁头不需要扫到磁盘最末端——如果在当前方向上已经没有更多请求了,就立即反向。减少了不必要的空跑。就像电梯不会非要到顶楼才掉头,如果最高只到15楼有人按了按钮,到了15楼就掉头往下。
3.6 C-LOOK算法
C-SCAN的LOOK版。单方向扫描,当前方向没有请求了就跳回最远端的请求位置继续。等待时间均匀且减少了空跑。
3.7 N步SCAN
把请求队列按时间分为N段子队列,每个子队列内部用SCAN算法。正在服务的子队列中新加入的请求放到下一个子队列里。这样做的目的是防止磁臂粘着——某个进程不断发请求霸占磁头,导致其他进程饿死。
3.8 FSCAN(两队列扫描)
N步SCAN的简化版(N=全部当前请求)。维护两个队列:当前服务队列和新请求队列。当前队列服务期间,新来的请求都进入新请求队列。当前队列服务完后,两个队列交换。效果与N步SCAN类似。
3.9 算法对比总结
|
算法 |
公平性 |
平均寻道 |
饥饿 |
特点 |
|---|---|---|---|---|
|
FCFS |
最公平 |
最长 |
无 |
简单但效率最低 |
|
SSTF |
不公平 |
较短 |
可能 |
贪心策略,可能饥饿 |
|
SCAN |
较公平 |
中等 |
无 |
电梯算法,两端不均 |
|
C-SCAN |
较公平 |
中等 |
无 |
等待更均匀 |
|
LOOK |
较公平 |
较短 |
无 |
SCAN的优化版 |
|
C-LOOK |
较公平 |
较短 |
无 |
C-SCAN的优化版 |
|
N步SCAN |
公平 |
中等 |
无 |
防磁臂粘着 |
|
FSCAN |
公平 |
中等 |
无 |
N步SCAN简化版 |
四、外存分配方式:文件在磁盘上怎么摆?
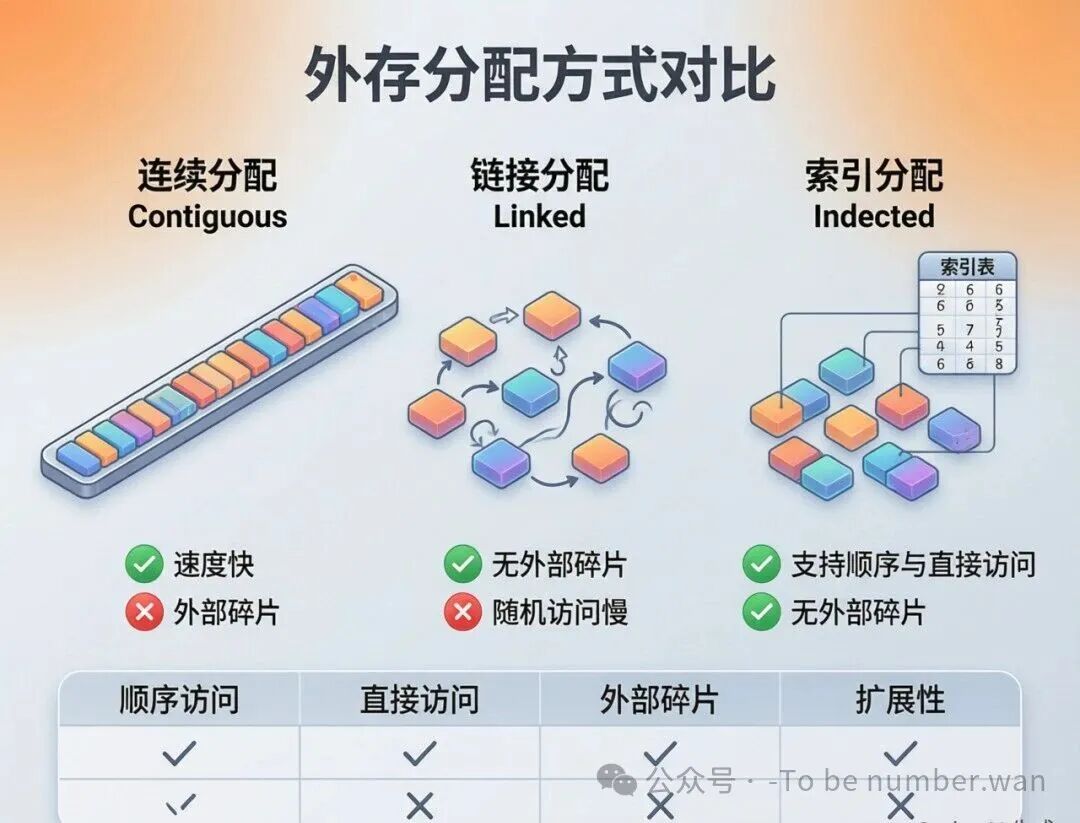
外存分配方式对比:连续、链接与索引
文件的各个数据块在磁盘上怎么存放?不同的方式有不同的优缺点。
4.1 连续分配
文件的各个部分占据连续的物理块。目录项中只需要记录起始块号 + 块数,就能定位文件的所有数据。
优点是顺序访问速度极快(磁头不用跑来跑去),也支持直接访问(第N块 = 起始块号 + N,直接算)。缺点是产生外部碎片(删除文件后留下的空隙可能太小,放不下新的大文件),而且文件不易动态增长(后面的位置可能已经被其他文件占了)。需要提前知道文件大小,或者预分配过多空间造成浪费。
4.2 链接分配
文件不需要占据连续的物理块,而是通过指针链接在一起。
隐式链接 ——每个物理块的末尾存一个指向下一个块的指针。目录项只记录起始块号。优点是无外部碎片,文件容易扩展。缺点是只适合顺序访问(想找第100块?得从第1块跟着指针一步步走),而且可靠性差——中间某个块的指针坏了,链子就断了。
显式链接(FAT) ——把链接指针从数据块中抽出来,集中存放在内存里的一张文件分配表(FAT) 中。想找下一个块?查FAT表就行。这样既支持直接访问,又提高了检索速度。缺点是FAT表本身要占内存,磁盘越大表越大。FAT16/FAT32/exFAT都用这种方式。
4.3 索引分配
为每个文件建一张索引表,记录文件各部分对应的物理块号。目录项记录索引表的地址。想找第N块?查索引表直接跳到对应物理块。优点是支持直接访问,无外部碎片。缺点是索引表本身也占空间。
大文件的处理方案:链接索引——多个索引块用指针链接起来。多级索引——一级索引指向数据块,二级索引指向一级索引块,三级索引指向二级索引块。混合索引(Unix inode方式) ——inode中直接存放一部分数据块号(如10个直接地址),然后有一次间接、二次间接、三次间接。小文件走直接地址,大文件走间接地址,灵活高效。
4.4 分配方式对比
|
分配方式 |
顺序访问 |
直接访问 |
外部碎片 |
文件扩展 |
额外开销 |
|---|---|---|---|---|---|
|
连续分配 |
快 |
支持 |
有 |
困难 |
无 |
|
隐式链接 |
快 |
不支持 |
无 |
容易 |
指针空间 |
|
显式链接(FAT) |
快 |
支持 |
无 |
容易 |
FAT表占内存 |
|
索引分配 |
快 |
支持 |
无 |
容易 |
索引表空间 |
五、磁盘空间管理:谁占着地,谁空着?
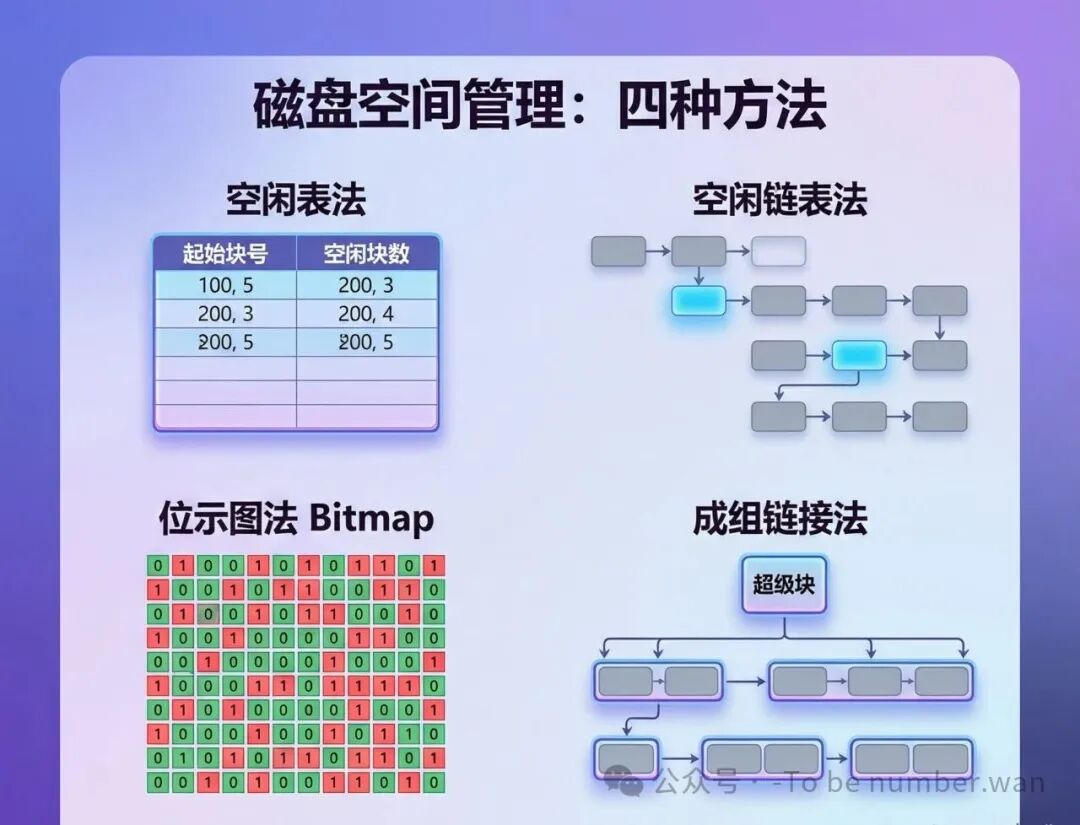
磁盘空间管理:四种方法对比
磁盘空间是有限的。文件系统需要知道哪些块是空闲的、哪些已经被占了。有四种经典的管理方法:
5.1 空闲表法
最直观的方式:用一张表记录所有空闲区的起始块号和空闲块数。比如"从第100块开始有5块空闲""从第200块开始有10块空闲"。分配时查表找合适的空闲区,回收时把归还的块登记回表,并合并相邻的空闲区。
优点是简单直观,适合连续分配。缺点是空闲区太多时表会很大——磁盘碎片化严重的话,可能有成千上万个小空闲区。
5.2 空闲链表法
把空闲块用指针链接成链表。有两种变体:空闲块链——每个空闲块单独链接,一个接一个。空闲盘区链——把连续的空闲区作为一个整体来链接(每个结点记录起始块号 + 块数 + 指针),减少链表长度。
优点是分配和回收方便——从链头取块就是分配,把块插回链中就是回收。缺点是链接指针本身也占空间。
5.3 位示图法(Bitmap)
用一个二进制位数组表示每个磁盘块的状态:0=空闲,1=已分配。1000块的磁盘,位示图只需要125字节(1000 ÷ 8)。
优点非常明显:占用空间极小、容易找到连续空闲块(找连续的0就行了)、整个位图可以常驻内存。广泛用于各种现代文件系统。
5.4 成组链接法
Unix/Linux的经典方式。核心思想:空闲块分组,每组最多N块(如50块)。每组的第一块存放下一组的块数和块号。超级块保存当前组的空闲块列表。
分配时从当前组取一块。当前组取完了,加载下一组信息到超级块。回收时把块放回当前组。当前组满了,形成新组。当前组空了,加载下一组。大多数操作只需要读写超级块,不需要遍历整个磁盘,所以很快。
六、磁盘格式化:新硬盘到手,怎么从"白板"变"可用"?
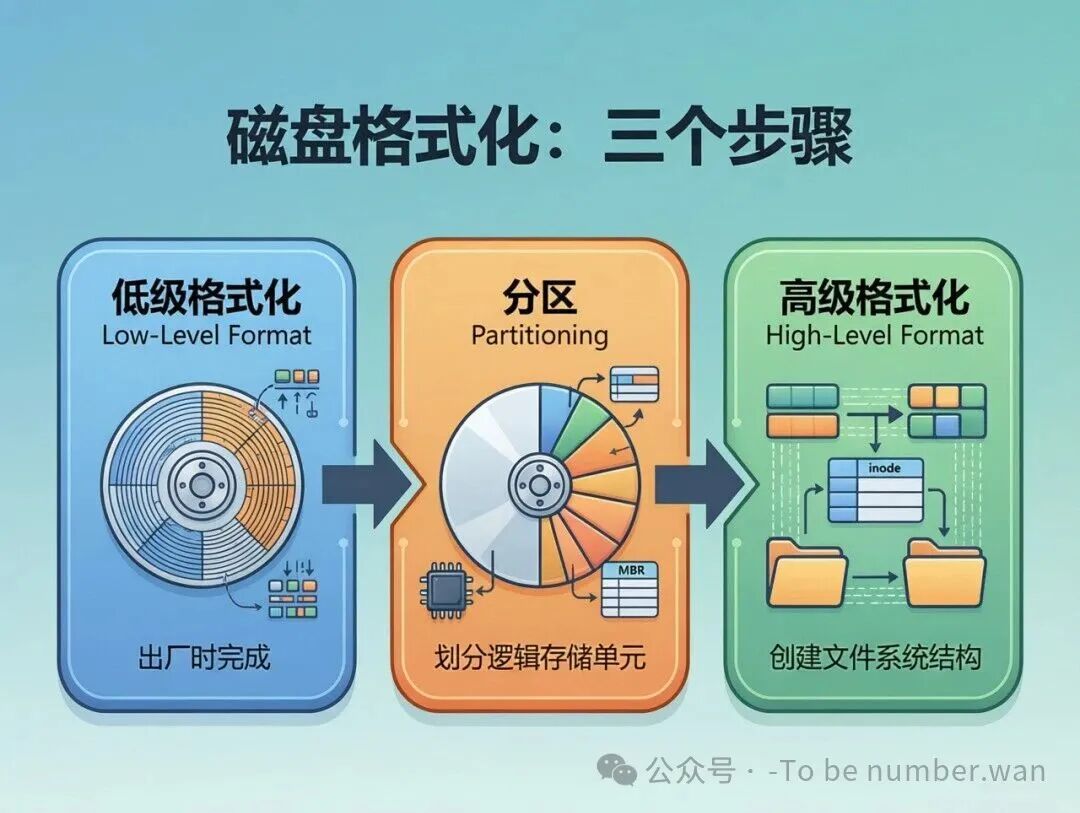
磁盘格式化:从物理格式化到逻辑格式化的三个步骤
一块全新的硬盘不能直接存文件,需要经历三个步骤才能被操作系统使用:
6.1 低级格式化(物理格式化)
在磁盘上划分磁道和扇区,写入扇区头信息(标识磁道号和扇区号)、数据区和校验码(ECC)。同时标记坏扇区(缺陷列表),让系统知道这些位置不能用。
这一步由硬盘厂商在出厂时完成——你买到的硬盘已经低级格式化好了。用户一般不需要(也不应该)自己做低级格式化。
6.2 分区
把磁盘划分为若干逻辑分区。每个分区可以独立管理,使用不同的文件系统。分区过程中会写入主引导记录(MBR)和分区表,告诉系统"这块磁盘有几个区,每个区从哪到哪"。
传统MBR分区方式有局限(最多4个主分区,最大支持2TB磁盘)。现代系统使用GPT(GUID分区表)作为替代方案:支持更大磁盘(>2TB)、更多分区、分区表有备份更可靠。
6.3 高级格式化(逻辑格式化)
在分区上创建文件系统。具体包括:写入引导块(Boot Block,用于系统启动)、写入超级块(Superblock,记录文件系统整体信息)、创建inode表(索引节点表)、创建根目录、初始化空闲空间管理结构(位图或成组链接等)。
这一步完成后,操作系统才能在这个分区上创建和管理文件。你在Windows上右键"格式化"U盘,做的就是这一步。
七、磁盘高速缓存:用内存帮磁盘"打辅助"
7.1 缓存原理
和CPU缓存的思路完全一样:用快速的内存来缓存最近访问过的磁盘数据。因为内存比磁盘快百万倍,如果后续访问的数据在缓存中(命中),就不需要再访问磁盘了。这利用了局部性原理——时间局部性(最近访问的数据很可能再次被访问)和空间局部性(访问了某块数据后,很可能接着访问相邻的块)。
7.2 缓冲区的三种状态
缓存中的缓冲区分为三种:
自由缓冲(Free) ——还没被使用,随时可以被分配。
清洁缓冲(Clean) ——已缓存磁盘数据,且内容和磁盘一致(没被修改过)。
脏缓冲(Dirty) ——内容被修改过,和磁盘不一致,需要找机会写回磁盘。
7.3 置换策略
缓存满了怎么办?需要淘汰一些缓冲区。
常用策略:
LRU(最近最少使用) ——淘汰最久没被访问的。
LFU(最少使用) ——淘汰访问次数最少的。
FIFO(先进先出) ——最早进入缓存的先淘汰。
Clock算法(时钟算法) ——LRU的近似实现,用一个循环链表和引用位来模拟。
7.4 写策略
写操作有三种策略:
写穿(Write-through) ——每次写缓存的同时也写磁盘。数据安全但写性能差(每次写都要等磁盘)。
写回(Write-back) ——只写缓存,标记为脏。缓冲区被置换出时才写回磁盘。性能好,但有断电丢数据的风险。
周期写盘 ——定期(比如每隔几秒)把所有脏缓冲写回磁盘。这是折中方案:兼顾性能和安全性。Linux的 sync 命令和内核的 flush 线程就是干这个的。
7.5 统一缓冲池
现代操作系统将磁盘缓存和文件系统的缓冲区统一管理,形成统一的缓冲池。Linux的 Page Cache 就是这种实现——所有磁盘数据(文件数据、目录数据、inode数据)都通过Page Cache来缓存和管理。
八、提高磁盘I/O速度的方法:各种加速骚操作
磁盘是系统中最慢的部件之一,操作系统绞尽脑汁想出了各种加速手段:
8.1 提前读(Read-ahead)
当系统检测到你在顺序读取一个文件时,它会"猜到"你接下来可能要读后面的数据,于是提前把后续的数据读到缓存中。这样你真正要读的时候,数据已经在缓存里了(命中),不用等磁盘。
提前读对顺序访问效果非常好(看视频、读大文件),但对随机访问基本没用。Linux的预读窗口大小是自适应的——连续命中时窗口越来越大,频繁不命中时窗口缩小。
8.2 延迟写(Delayed Write)
写操作不立即写磁盘,而是先写到缓存中标记为脏,然后在适当的时候统一写回。好处是可以合并多次小写为一次大写——比如你连续修改一个文件10次,如果每次都写磁盘就要写10次;有了延迟写,可能只需要写1次。
Linux中有专门的pdflush/flush线程定期把脏页写回磁盘。但风险是断电可能丢数据——还没写回的脏页会丢失。所以重要的程序会用 fsync() 系统调用强制立即写盘。
8.3 优化文件物理块分布
让同一个文件的各个块尽量在磁盘上连续存放,减少寻道次数。ext4的区段(extent)分配就是这个思路——用"起始块号+连续块数"来表示一段连续的数据块,而不是逐块记录。
预分配——创建文件时预先分配一定的连续空间,避免后续频繁扩展导致文件块分散。
8.4 减少磁头移动
通过合理的磁盘调度算法(SCAN、C-SCAN等),将同一柱面的请求集中处理,减少不必要的寻道。在多磁盘环境下,还可以将I/O负载分散到多块磁盘上。
8.5 NCQ(原生命令队列)
这是SATA硬盘的一个硬件特性。操作系统只管往硬盘发I/O请求,硬盘内部自己会对请求重新排序,优化磁头的移动路径。相当于把调度算法从操作系统层下沉到了硬件层。操作系统只需要发出请求,硬盘自己决定执行顺序。
8.6 Linux的I/O调度器
Linux内核提供了几种I/O调度器:CFQ(完全公平队列) ——为每个进程分配独立的I/O时间片,保证公平。Deadline(截止时间调度) ——为每个请求设定截止时间,防止饥饿。NOOP(无操作/直通) ——不做任何调度,直接按FIFO顺序执行。BFQ(预算公平队列) ——CFQ的改进版,按"预算"分配I/O资源。
SSD通常使用NOOP或Deadline——因为SSD没有机械寻道,不需要像HDD那样优化磁头移动路径,调度器的开销反而可能成为瓶颈。
九、RAID:多块盘组队,又快又稳
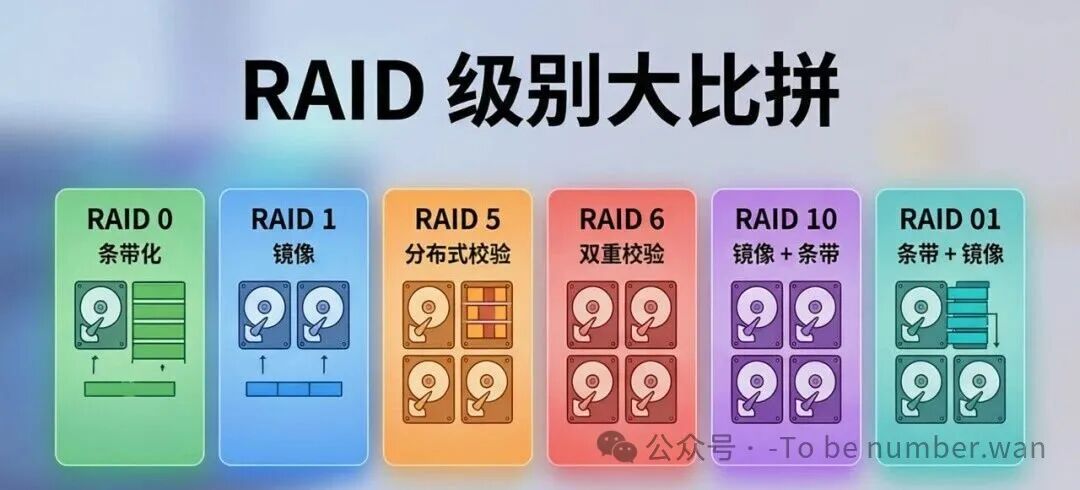
RAID级别大比拼:速度、可靠性与成本的权衡
RAID(Redundant Array of Independent Disks,廉价冗余磁盘阵列)用多块磁盘组合成一个逻辑磁盘,目的是提高性能和/或可靠性。两个核心概念:数据条带化(Striping) ——数据分散到多盘,并行读写提速。冗余(Redundancy) ——额外存储校验信息,某块盘坏了数据还在。
9.1 RAID 0(条带化)
数据被切成块,交替分布到多块磁盘上。读写可以并行进行,速度成倍提升。但没有任何冗余——任何一块盘坏了,所有数据全完。就像把一份文件撕成几页分给几个人保管,一个人丢了就全没了。至少需要2块盘。适用场景:追求极致速度,数据丢了也无所谓。
9.2 RAID 1(镜像)
每块盘都有一个完整的镜像盘,数据同时写到两块盘上。可靠性极高(一块盘坏了还有另一块),读性能可以提升(可以从两块盘同时读)。但可用容量只有50%——两块1TB的盘组RAID 1,你只能用到1TB。适用场景:数据安全要求极高。
9.3 RAID 2(位级条带 + 海明码)
数据按位分散到多盘,额外用海明码做校验。需要很多盘(数据盘+校验盘),实际中很少使用,了解即可。
9.4 RAID 3(字节级条带 + 专用校验盘)
数据按字节分散到多盘,有一块专门的盘存放奇偶校验信息。每次读写都涉及所有盘,适合大文件顺序读写。但校验盘可能成为瓶颈。
9.5 RAID 4(块级条带 + 专用校验盘)
和RAID 3类似,但以块为单位分散。校验盘成为写入瓶颈——每次写操作都要更新校验盘,而校验盘只有一块。
9.6 RAID 5(分布式奇偶校验)
和RAID 4类似,但校验信息分散存储在所有盘上,而不是集中在一块盘上。解决了RAID 4的校验盘瓶颈问题。允许一块盘故障而不丢数据。至少需要3块盘。
RAID 5是最常用的RAID级别,兼顾了性能、可靠性和成本。适合文件服务器、NAS等场景。
9.7 RAID 6(双重奇偶校验)
使用两套校验信息,允许两块盘同时故障。可靠性更高,但写入性能更低(每次写都要计算和更新两套校验)。至少需要4块盘。适合对可靠性要求极高的企业存储。
9.8 RAID 10(1+0)
先做镜像(RAID 1),再做条带化(RAID 0)。高性能 + 高可靠,但成本也最高——至少需要4块盘,可用容量只有50%。适用场景:高性能数据库服务器、核心业务系统。
9.9 RAID 01(0+1)
先做条带化(RAID 0),再做镜像(RAID 1)。看起来和RAID 10差不多,但可靠性不如RAID 10——条带组中任何一块盘坏,整个条带组都不可用,只剩镜像组在撑。
9.10 RAID选择建议
|
RAID级别 |
最少盘数 |
可用容量 |
容错能力 |
读性能 |
写性能 |
适用场景 |
|---|---|---|---|---|---|---|
|
RAID 0 |
2 |
100% |
无 |
极高 |
极高 |
追求速度,数据不重要 |
|
RAID 1 |
2 |
50% |
1块盘 |
高 |
一般 |
数据安全要求高 |
|
RAID 5 |
3 |
(n-1)/n |
1块盘 |
高 |
中等 |
通用存储/NAS |
|
RAID 6 |
4 |
(n-2)/n |
2块盘 |
高 |
较低 |
企业存储 |
|
RAID 10 |
4 |
50% |
1块/组 |
极高 |
高 |
高性能数据库 |
|
RAID 01 |
4 |
50% |
1组 |
极高 |
高 |
不推荐 |
总结
磁盘存储器管理的核心矛盾就一句话:CPU太快了,磁盘太慢了。为了解决这个矛盾,操作系统想出了一整套方案:
调度算法让磁头尽量少跑、跑短路——FCFS公平但慢,SSTF快但可能饿死人,SCAN像电梯一样均衡,C-SCAN更均匀,LOOK系列是它们的优化版。
分配方式决定文件在磁盘上怎么摆——连续分配简单快速但有碎片,链接分配无碎片但随机访问差,索引分配综合最优。
空间管理追踪磁盘上的"空地"——空闲表法简单直观,位示图法空间最省,成组链接法效率最高。
格式化让新硬盘从"白板"变"可用"——低级格式化划磁道扇区,分区切蛋糕,高级格式化建文件系统。
缓存用内存帮磁盘"打辅助"——Page Cache让热数据不用每次都读磁盘。
各种加速手段进一步压榨性能——提前读、延迟写、优化块分布、NCQ、I/O调度器……
RAID让多块盘组队——条带化提速,镜像保安全,RAID 5是性价比之王。
一句话总结:磁盘存储器管理的全部目标,就是让"最慢的家伙"尽可能不拖慢整个系统。

openEuler 是由开放原子开源基金会孵化的全场景开源操作系统项目,面向数字基础设施四大核心场景(服务器、云计算、边缘计算、嵌入式),全面支持 ARM、x86、RISC-V、loongArch、PowerPC、SW-64 等多样性计算架构
更多推荐
 6
6 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)