大模型学习8下-高性能推理引擎vLLM学习笔记
核心概念
1.1 背景与问题
1.1.1 LLM推理的挑战
LLM正加速从云端走向边缘与本地部署,背后的驱动力主要来自更低的推理延迟、更强的隐私保护,以及更可控的部署成本。与此同时,随着模型参数规模和上下文长度不断增长,传统推理方案的瓶颈也越来越明显:显存利用率低、GPU算力利用率低、并发能力不足,并且请求量一旦增加,响应延迟就会迅速恶化。
这类问题在LLM工程落地中非常常见。模型在单用户或低并发环境下通常表现正常,但一旦进入真实生产场景,面对十几个甚至几十个并发请求,往往就会出现首Token延迟飙升、显存耗尽、吞吐量下降等现象,而GPU利用率却始终不高。
根本原因在于LLM的自回归生成机制。LLM需要逐Token生成结果,并持续维护KVCache来保存历史上下文。KVCache的显存占用会随着上下文长度线性增长,而生成长度在推理前又无法准确预知,这就使得资源分配高度动态,传统优化手段很难奏效。
传统推理方案,例如直接使用Hugging Face Transformers的model.generate()方法,通常采用预先分配策略,为每个请求预先分配一整块连续显存空间,即便该空间大部分未被使用。这种预留机制造成显存浪费和严重碎片化,GPU计算单元频繁等待显存数据访问,最终导致吞吐量下降、延迟升高和算力成本上升。
vLLM是加州大学伯克利分校团队在2023年开源的高性能推理框架,核心目标是提升LLM推理的吞吐量、显存利用率,并降低推理延迟。它已经成为Mistral、Qwen、Llama、DeepSeek等主流模型常用的推理后端之一,也常被视为面向服务器级GPU的主流LLM推理方案。
它的核心性能优势主要来自两项关键技术:
-
PagedAttention:借鉴操作系统的分页内存管理思想,将KVCache切分为固定大小的块,统一调度和复用,使不同请求能够复用非连续的显存资源,从而显著降低碎片率。在实际生产中,这种机制通常能减少大量显存浪费。
-
Continuous Batching:从调度层面提升GPU利用率。传统推理往往要等一个批次中的所有请求都结束后才能进入下一轮计算,而vLLM允许新请求持续加入正在执行的批次,各请求独立推进、独立结束,不必同步等待。这样一来,在相同硬件条件下通常可以带来数倍吞吐提升。
除性能优化外,vLLM在工程可用性方面也很突出。它原生兼容Hugging Face模型格式,并提供OpenAI风格的API接口。开发者只需少量代码或一条vllm serve命令,就能快速部署支持流式输出、高并发请求和批处理的推理服务。
关于vLLM的定位与适用场景,有两点需要明确:
-
vLLM是高性能推理引擎,不是完整的模型服务平台。监控、日志、自动扩缩容、安全认证、模型版本管理等能力,需要由外部系统补齐。vLLM专注于推理优化,不涉及模型训练。在轻量级或纯CPU离线推理场景中,
llama.cpp等方案往往更具性价比。 -
vLLM更适合实时对话系统、多租户模型服务、高并发生成任务,以及需要长上下文和流式输出的在线推理服务。
在LLM落地实践中,模型本身的能力固然重要,但承载业务流量的推理系统架构,才是LLM工程化落地的核心底座。相关工程问题与解决方案可参考:vLLM核心原理与生产实践。
1.1.2 KVCache原理与局限
原理
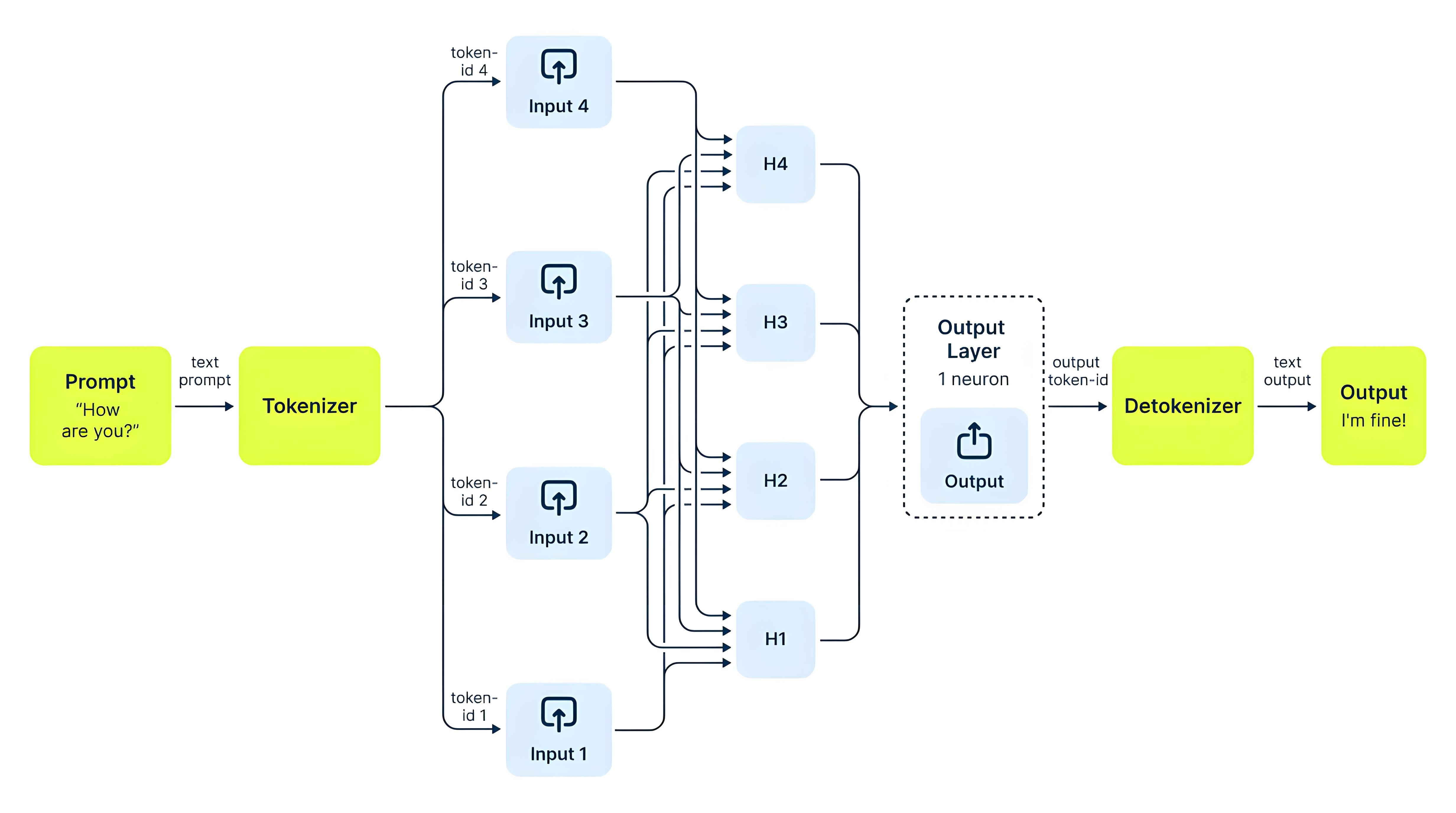
LLM以自回归方式生成文本,也就是逐个Token依次输出。当模型准备生成第N个Token时,必须参考此前N-1个Token所包含的全部信息,这一能力由注意力机制承担。
注意力计算可视为一种查询匹配过程:当前待生成的token发出一组Query(查询向量),意在询问此前内容中哪些部分与当下最相关;已存在的每个token均提供一组Key(索引标签)与Value(实际内容)。以Query与各个Key的匹配程度作为权重,对所有Value进行加权求和,所得结果即为当前token应当重点关注的上下文信息。
以翻译“The cat sat on the mat”为例。模型已经生成了两个中文词:“那只”、“猫”。现在模型要决定第三个中文词是什么。
第三个中文词在生成之前,先有一个“空位”代表它。这个空位被称为“当前待生成的Token”。模型为这个空位计算出一个Query向量,用来询问之前的内容。
具体计算:这个空位有自己的位置编码和初始向量,乘以权重矩阵W_Query,得到Query = [0.2, 0.8]。这个Query的含义相当于“猫做了什么动作”。
每个已存在的英文单词(The、cat、sat、on、the、mat)都有各自的Key和Value(2维向量):
| 单词 | Key | Value |
|---|---|---|
| cat | [0.8, 0.1] | [0.9, 0.2] |
| sat | [0.2, 0.9] | [0.1, 0.9] |
| 其他 | 忽略 | 忽略 |
匹配度计算(点积:q·k = q1×k1 + q2×k2):
- Query与cat的Key:0.2×0.8 + 0.8×0.1 = 0.24
- Query与sat的Key:0.2×0.2 + 0.8×0.9 = 0.76
加权求和(Value × 匹配度,再相加):
- cat贡献:[0.9×0.24, 0.2×0.24] = [0.216, 0.048]
- sat贡献:[0.1×0.76, 0.9×0.76] = [0.076, 0.684]
- 结果:[0.292, 0.732]
这个结果向量被送回空位所在的层。输出层根据这个向量判断概率最高的词是“坐”。于是空位被填充为“坐”。
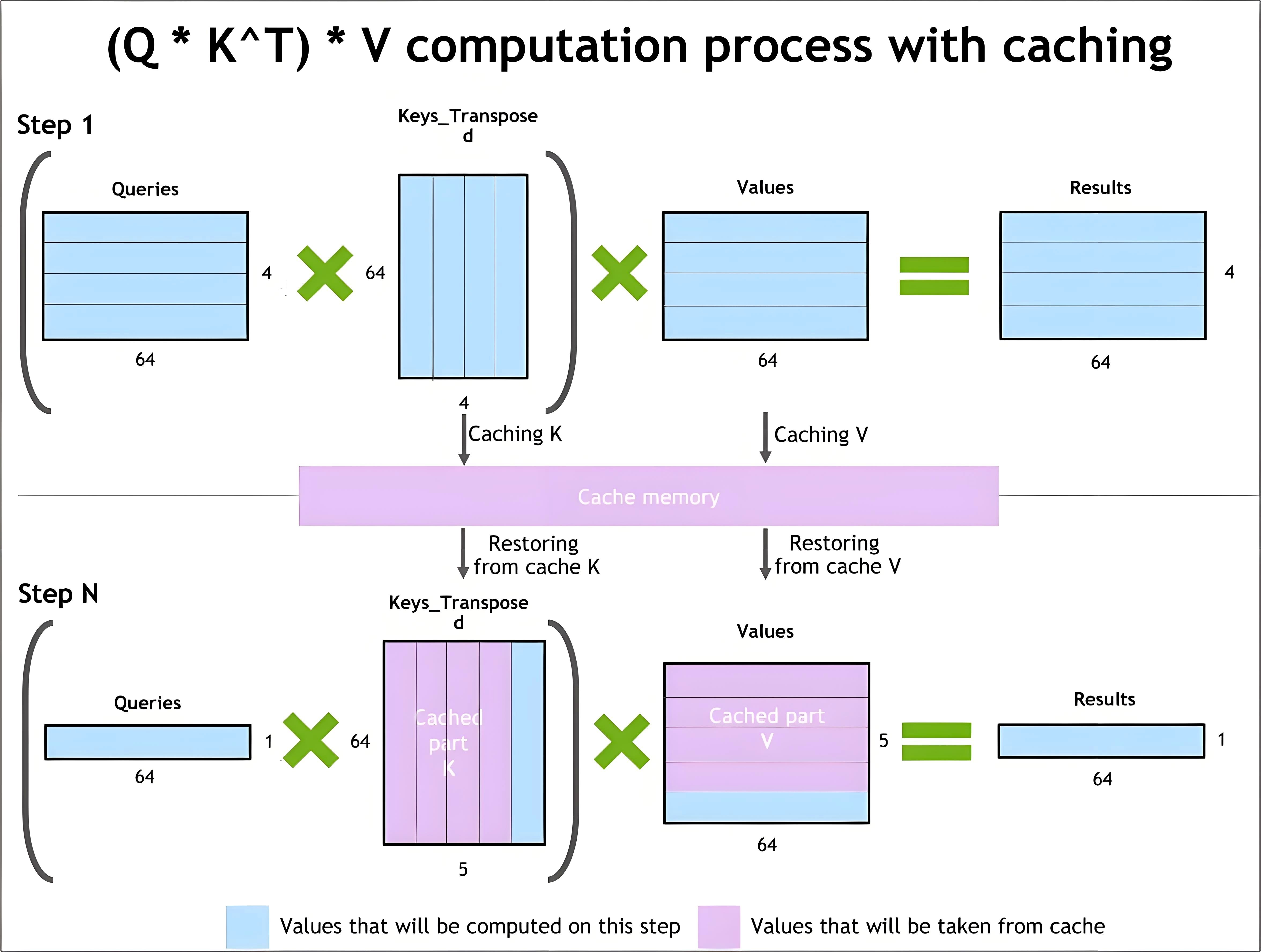
在多层Transformer结构中,每一层都会为每个Token分别计算Key和Value。如果每生成一个新Token都重新计算一次全部历史Token的Key和Value,计算量会随着序列长度快速膨胀,接近平方级增长。为避免这种重复计算,vLLM会将每个Token在每一层产生的Key和Value保存下来,在后续生成过程中直接复用这些结果。这部分用于存储历史Key和Value的数据结构,就是KVCache,通常驻留在GPU显存中。
生成过程因此可以拆成两个阶段:
- 预填充(Prefill)阶段:将整个提示词一次性输入模型,并行计算所有Token对应的Key和Value,写入KVCache,然后生成首个回复Token。
- 解码(Decode)阶段:之后每生成一个新Token,只需为新Token计算Query、Key和Value,并将新的Key和Value追加到KVCache末尾,再基于Query与更新后的缓存计算注意力,生成下一个Token。
到这里,解码阶段的单步计算已经显著降低,但新的问题也随之出现。
局限
随着对话序列长度增长,KVCache的显存占用会持续升高。以70B规模模型为例,在处理3.2万Token长上下文时,单条请求的KVCache可能占用几十GB显存,具体数值会受到精度、层数、头数等配置影响。一块NVIDIA H100显卡的总显存约80GB,这意味着一条长序列请求几乎可以独占整张卡。
传统框架通常为每条请求预先分配一整块连续显存来容纳KVCache,这会引发两个明显问题:
- 空间浪费与显存溢出并存:若按最大长度预分配,大部分空间在多数时间内处于空闲状态;若按平均长度分配,一旦实际输出长度超出预期,便会因显存耗尽而触发显存溢出崩溃。
- 显存碎片化:每条请求各自占据一块连续显存,不同请求的长度和结束时间都不同。当部分请求完成并释放显存后,留下的是大小不一、彼此分散的空闲区域。即使剩余显存总量足够,新请求也可能因为缺乏足够长度的连续空间而无法启动。
这就像一家旅馆按照每位客人可能住的最长天数,一次性锁死整层楼的房间。结果大多数客人只住几天,大量房间在大部分时间里白白空着;偶尔遇到长住客,整层楼倒是刚好能被占满。更麻烦的是,当一位长住客退房后,留下的房间散落在不同楼层,彼此不连续。而新来的团队需要的恰恰是一整层连续楼层。于是就会出现一种尴尬的局面:总空房间不少,但因为不连续,怎么也塞不进一个需要整层楼的团队。
1.2 vLLM关键技术
1.2.1 PagedAttention
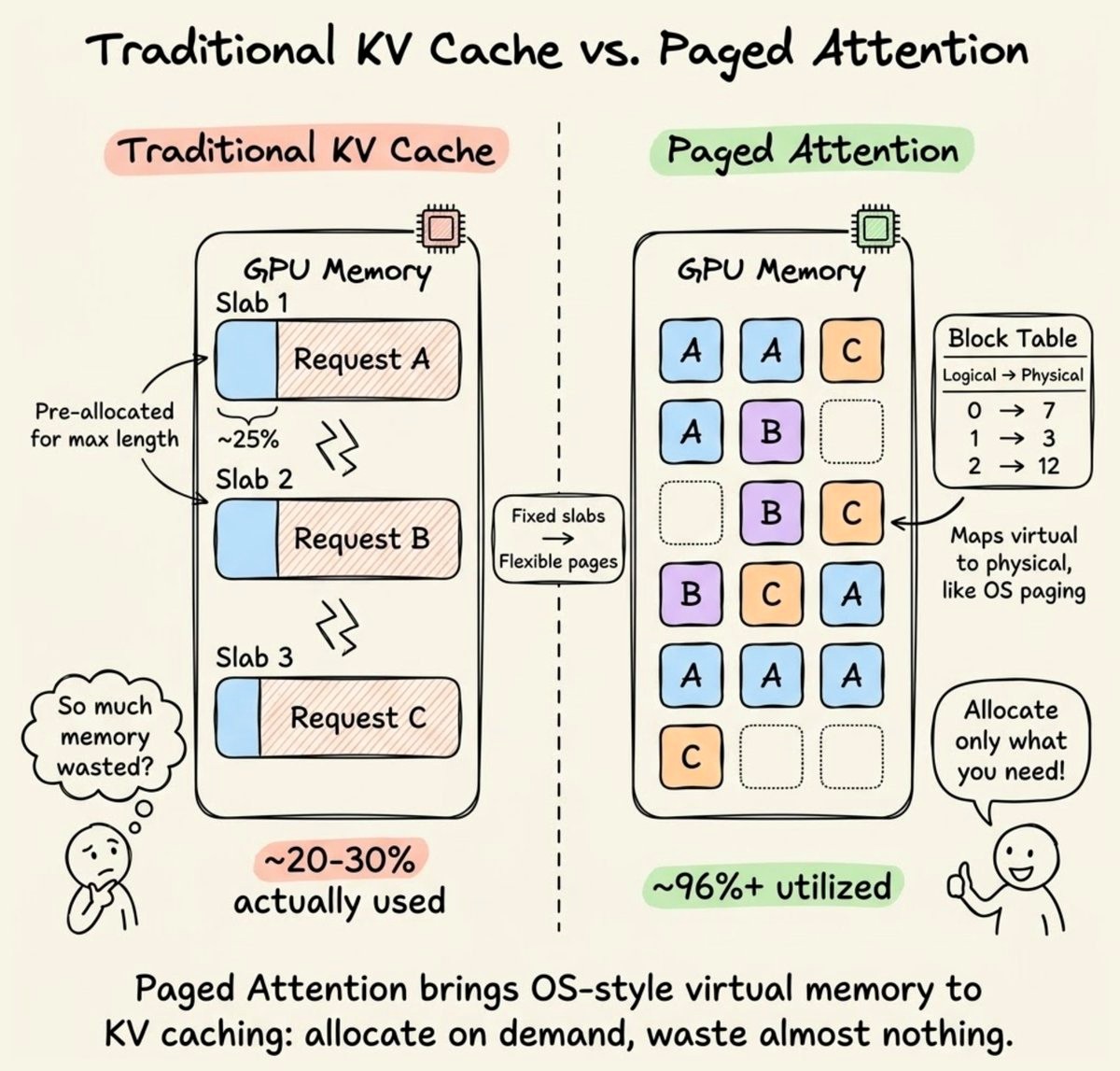
在LLM中,注意力机制需要缓存Key和Value(KVCache),显存占用很大。如果直接连续分配,容易产生碎片,浪费空间,并降低性能。vLLM的PagedAttention借鉴了操作系统的虚拟内存与分页机制,有效解决了这个问题。
操作系统管理内存的基本流程如下,可以把操作系统的内存管理想象成书架:
-
分块存储
内存被切成固定大小的页(Page),就像书架分成统一格子。 -
按需分配,不要求连续
程序只分配需要的页,这些页在物理内存中可以散落,不必连续。 -
映射关系维护
系统维护页表,记录逻辑页与物理页的对应关系。程序看到的是连续空间,但底层可能分散。 -
统一回收消除碎片
程序结束后,占用的页会被回收放回空闲池。因为分配和回收都是固定大小的页,从而避免碎片产生。
PagedAttention将这一思想平移到KVCache管理中,核心设计包括:
-
固定大小的块(Block)
将显存切成大小相同的块,每块可存固定数量Token的KV数据。 -
按需分配,物理块可分散
序列开始时只分配少量块,随着Token生成再动态追加。这些块在显存中不必连续。 -
块表(Block Table)映射
每条序列维护一张块表,记录逻辑块与物理块的对应关系。注意力计算时通过查表即可找到真实位置。 -
即时回收+全局空闲池
序列结束或暂停时,其占用的块会立即回收并放入全局空闲池,供其他请求复用。 -
写时复制(Copy-on-Write)实现前缀共享
多条序列若拥有相同前缀,可先共享同一组物理块;只有当某条序列需要修改数据时,才复制出专属的新块,从而避免重复占用显存。
凭借这套机制,KVCache的显存利用率显著提升,分配与回收都变成了轻量级的块操作,系统吞吐能力也随之大幅提高。该技术的详细原理与实现可参考:Deploy LLMs at Scale with vLLM。
1.2.2 Continuous Batching
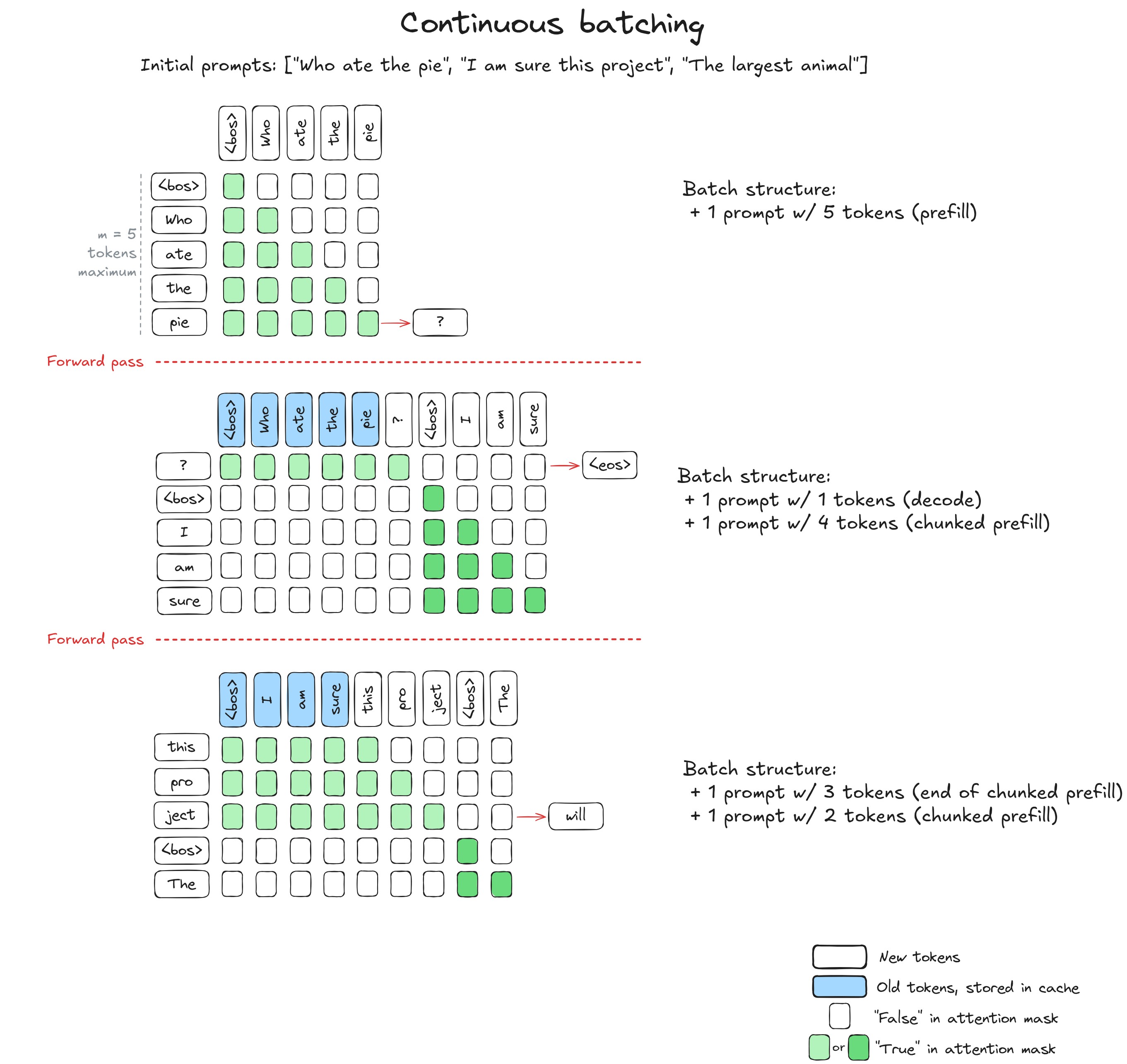
解决显存瓶颈后,vLLM进一步把重点放在计算效率上。传统静态批处理通常是先凑齐一批请求,统一完成预填充,再逐Token生成,并且必须等批次内所有请求都结束后才能进入下一轮。这意味着短请求经常要等待长请求,GPU也会因为批次内某些序列结束而被动浪费算力。
vLLM的连续批处理(Continuous Batching)更像一个动态拼车系统:
- GPU持续运行一个生成循环,每一步只为当前批次中仍然活跃的序列生成一个Token。
- 某条序列完成后,立即从批次中移除,并归还它占用的KVCache块。
- 同一步调度中,系统会从等待队列里拉入新的请求,直接插入当前批次。
- 下一步生成会在新旧混合批次上继续执行,GPU始终保持较高利用率。
在这种情况下,短请求不必等待长请求结束,完成后也能立刻释放资源。配合PagedAttention灵活的块分配机制,新请求可以随时进入执行流程,不会因为KVCache无法连续分配而被阻塞。最终,vLLM的吞吐量往往能达到传统方法的数倍,在线服务成本也会明显下降。高并发调度优化细节可参考:vLLM高并发推理优化详解。
1.2.3 其他优化措施
除了上述两大核心设计,vLLM还集成了多项在生产环境中很实用的优化能力:
- 自动前缀缓存(Prefix Caching):自动识别多个请求中的相同前缀,例如System Prompt、工具说明或少样本示例,并复用对应的KVCache,减少重复计算。
- 分块预填充(Chunked Prefill):将超长提示文本拆成多个小块,穿插在解码阶段交替执行,避免长输入一次性占满GPU计算资源。
- FlashAttention-3:使用高效注意力内核,减少显存读写开销,加速Attention计算。
- PagedAttention专用CUDA内核:直接在GPU侧读取块表,减少CPU参与调度的开销。
- 多LoRA批量服务:在同一批次中并行服务多个不同LoRA适配器的请求,适合多任务、多租户场景。
- 投机解码(Speculative Decoding):先用小模型快速生成候选Token,再由大模型验证,以提升生成速度。
- 张量并行与流水线并行:通过一行参数即可将模型切分到多张GPU上运行,便于扩展到多卡甚至多节点环境。
- 智能调度与抢占:系统高负载时优先处理短交互式请求,并对长序列请求进行适度抢占与恢复,以维持整体体验。
这些技术协同起来,使vLLM不只是一个跑得快的推理工具,而是一套更适合生产环境的高效推理引擎。vLLM核心技术与实战落地详解可参考:vLLM Tutorial for Beginners。
2 快速上手
2.1 安装说明
版本兼容
vLLM本质上是一个GPU-first推理框架,底层高度依赖CUDA Runtime、Triton Kernel、FlashAttention以及PyTorch CUDA等关键组件,因此它与NVIDIA GPU生态绑定很深。由于Windows在CUDA工具链、C++扩展编译链以及部分底层依赖上的兼容性不如Linux成熟,部署时更容易出现依赖缺失、编译失败或运行不稳定等问题。
在标准Linux + NVIDIA GPU环境下,只要完成CUDA和PyTorch等基础依赖安装,vLLM通常就能比较顺利地部署。官方一般已经提供集成主要CUDA扩展和推理内核的预编译wheel,大多数Linux发行版可以直接通过pip安装,无需额外编译。
相比之下,纯CPU环境难以发挥vLLM的核心优势。PagedAttention主要面向GPU显存带宽和高并发吞吐优化,在CPU上很难获得同等级别收益,而这一差距在Windows + CPU环境中通常会更明显。不过,CPU环境仍然可以安装vLLM,只是过程更复杂。由于预编译wheel支持有限,很多情况下需要从源码编译C++和Python扩展模块,涉及GCC、CMake、Ninja以及PyTorch等多重依赖约束,部分GPU相关算子也会被禁用或降级。
在无GPU的CPU推理场景中,更适合选择专门面向CPU优化的推理框架,例如:
- llama.cpp:针对AVX2/AVX512等SIMD指令集优化,支持GGUF量化格式,在低资源环境下具备更高效率与更低延迟
- Ollama:基于llama.cpp封装,提供更友好的模型管理与开箱即用体验
- Hugging Face Optimum:面向Intel生态的系统级CPU推理优化方案,可提供更高效的推理加速
安装
在Linux+CUDA环境下安装vLLM时,需要重点关注PyTorch、vLLM与CUDA之间的版本兼容关系。vLLM依赖其支持范围内的PyTorch与CUDA组合运行,并基于PyTorch提供GPU计算能力和算子体系进行推理加速。因此,一旦PyTorch版本变化,底层CUDA相关接口和二进制兼容性也可能变化,进而导致vLLM编译失败或运行时无法正常加载。
很多表面上的安装问题,本质上通常来自PyTorch与CUDA或相关依赖版本不匹配。不同版本的vLLM会限定其支持的PyTorch版本范围,而PyTorch本身又与CUDA版本强绑定,并进一步影响驱动版本兼容性。在这种链式依赖关系下,直接执行:
pip install vllm
该命令会默认安装最新版本的vLLM。如果当前环境中的PyTorch版本不匹配,pip在解析依赖时可能会自动调整或升级PyTorch,但新版本PyTorch未必与当前CUDA环境完全兼容,从而导致运行错误。
在安装前应重点核对vLLM与PyTorch的兼容关系,可以参考vLLM GitHub Releases来确认具体版本对应关系。如果当前PyTorch版本较低,通常需要选择较旧的vLLM版本进行匹配。如果需使用较新的vLLM版本,则往往需要同步升级PyTorch与CUDA环境,以保证整体兼容。例如,PyTorch 2.5.1通常与vLLM 0.7.3版本适配,可以这样安装:
pip install vllm==0.7.3
对于生产环境,更推荐直接使用官方Docker镜像或经过验证的版本组合,以降低编译与兼容性风险。如果需要从源码构建vLLM,应明确指定release tag,并确保当前PyTorch与CUDA组合在官方支持范围内。
2.2 模型加载与调用
在vLLM中,从模型到服务的完整流程通常分为三步:模型获取→服务启动→API调用验证。详细内容可参考,vLLM快速部署与实战教程。
1. 模型获取
vLLM支持直接加载Hugging Face或ModelScope上的模型,也支持从本地路径加载已经下载好的模型。如果指定在线模型,启动服务时会自动下载。生产环境中更推荐提前将模型下载到本地。国内环境常用ModelScope下载,示例如下:
pip install modelscope
modelscope download --model Qwen/Qwen3-0.6B --local_dir ./Qwen3-0.6B
2. 服务启动
无论是本地模型还是在线模型,vLLM的启动方式是统一的,只需要指定不同的路径。
本地模型启动:
vllm serve ./Qwen3-0.6B --served-model-name Qwen3-0.6B
在线模型启动,例如直接使用Hugging Face模型时,会自动从远程拉取:
vllm serve Qwen/Qwen3-0.6B --served-model-name Qwen3-0.6B
--served-model-name用于指定模型在API中的暴露名称,方便后续调用。
服务启动后,vLLM通常会执行以下操作:
- 自动加载tokenizer和模型权重
- 初始化GPU显存分配,基于PagedAttention机制
- 启动OpenAI兼容API服务,默认端口为8000
- 捕获CUDA Graph形状,用虚拟数据预先打包一组GPU操作快照,后续直接重放
启动后,可先查询可用模型列表:
curl http://localhost:8000/v1/models
openEuler 是由开放原子开源基金会孵化的全场景开源操作系统项目,面向数字基础设施四大核心场景(服务器、云计算、边缘计算、嵌入式),全面支持 ARM、x86、RISC-V、loongArch、PowerPC、SW-64 等多样性计算架构
更多推荐
 1
1 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)