决定 AI Agent 生死的,不是模型,是 Harness 和 Loop
去年秋天,OpenAI 一个三人小组做了一件有点“反常”的事。
他们打开一个空仓库,接着就没再手写一行代码。三个人只做一件事——调整 Agent 的运行环境、约束条件和反馈策略。半年后,这个仓库长到了一百多万行代码。
差不多同一时间,Anthropic 的工程师在内部做了个实验:让一个 AI Agent 从零搭建一款 2D 复古游戏引擎。起初只用单独一个 Agent,产出的东西“技术上能跑起来,但基本是废的”。后来他们把 Agent 拆成三个——Planner 定方案,Generator 写代码,Evaluator 独立验证——同样任务、同样模型,结果从“勉强跑通”跳到了“功能完整且附带单独 Agent 从未尝试过的特性”。
然后,2026 年春天,两家公司各自发了一篇工程博客。OpenAI 那篇叫“Harness Engineering: Leveraging Codex in an Agent-First World”。Anthropic 那篇叫“Effective Harnesses for Long-Running Agents”。发布时间差不超过七天。Martin Fowler 随后也跟进写了一篇分析。
这不是一次巧合。这是一条正在成型的共识。
当 AI 从“回答问题”变成“做事”,决定最终产出的,早已不是模型本身。而是模型运行在其中的那套控制系统。
这套系统有两个维度,缺一不可。一个叫 Harness Engineering,管的是 Agent 的运行时环境和治理架构。一个叫 Loop Engineering,管的是 Agent 怎么在迭代中观察结果、修正方向、闭合反馈。
这篇文章把两个概念拆开讲清楚。
1
先说 Harness.
这个词在英文里是“挽具”——套在马身上、让骑手能驾驭那副力量的东西。用这个比喻来理解 AI 系统非常到位:模型是智力引擎,Harness 是决定这台引擎能做什么、不能做什么、每一步怎么走的软件层。
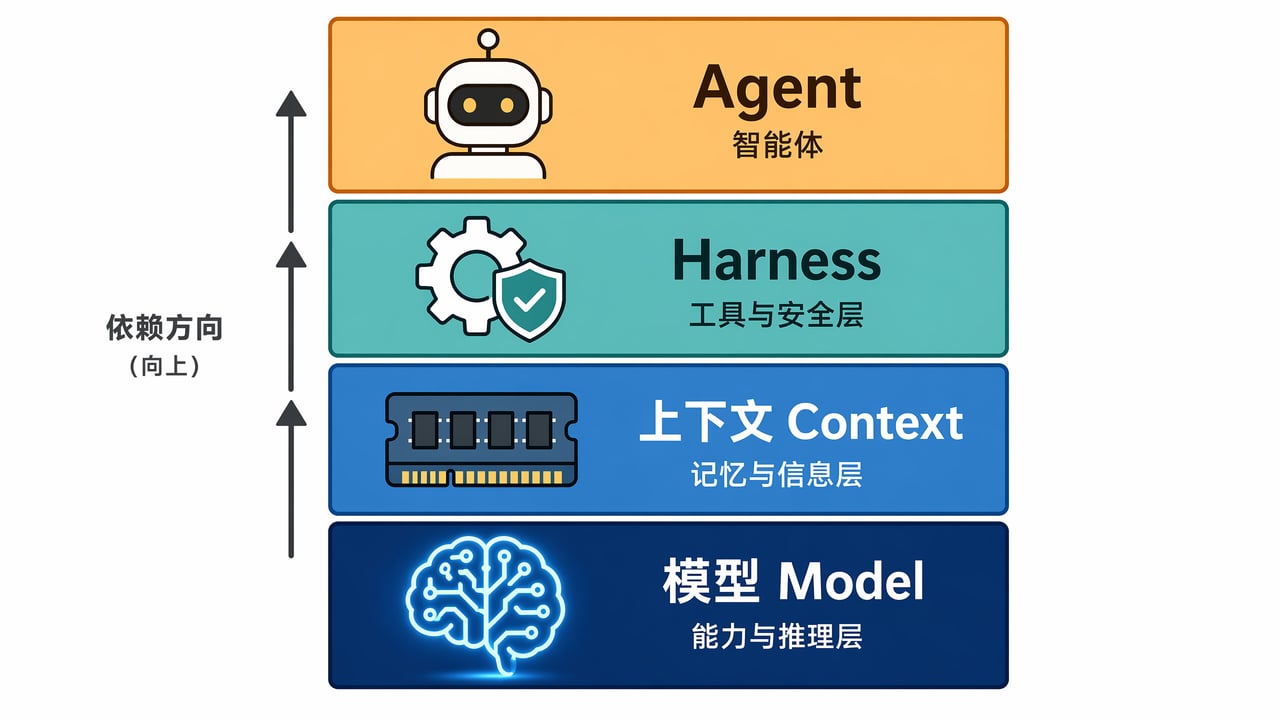
Cobus Greyling 今年 3 月给了一个很干净的四层架构图:
-
模型:原始处理能力。它是“大脑”。
-
上下文窗口:有限的工作内存。它是“短期记忆”。
-
Harness:操作系统。它管工具调度、安全检查、状态持久化、错误恢复。
-
Agent:应用程序。它跑在 Harness 之上。
这个分工画了一条很重要的边界:模型负责“想”,Harness 负责“管”。混在一起,两个都做不好。
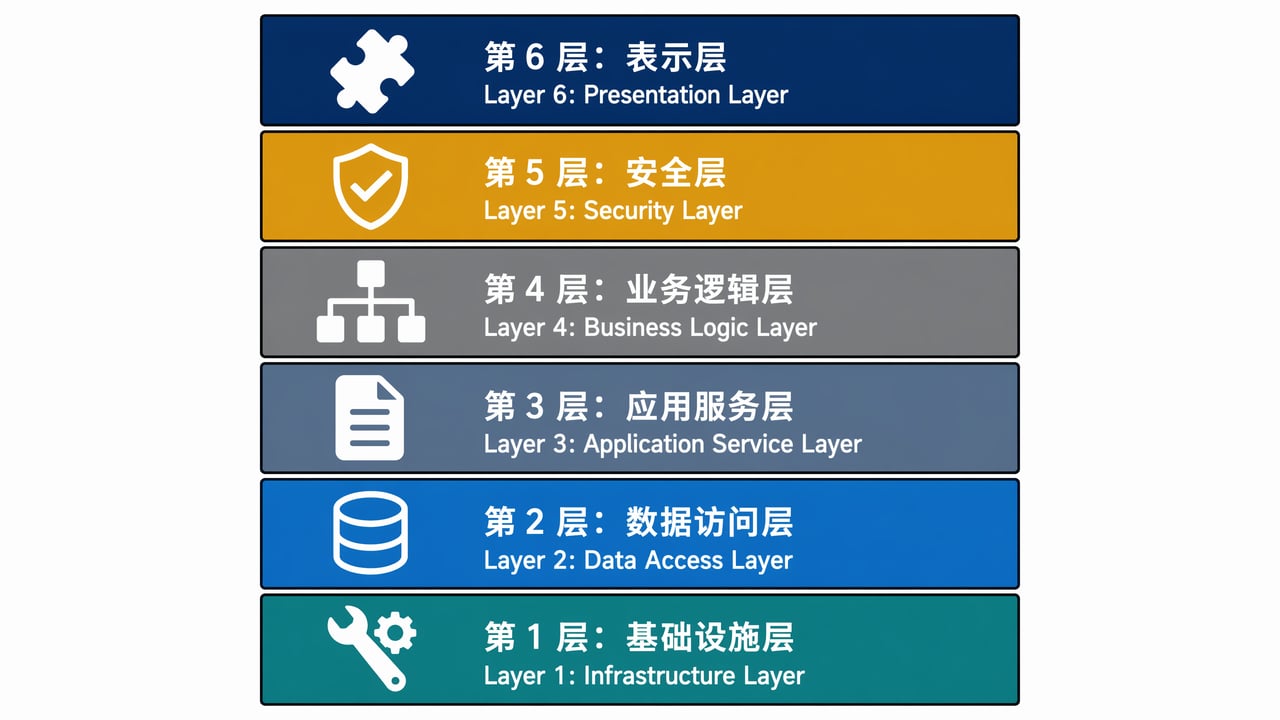
今年 4 月 arXiv 上的一篇综述文章对当时主流的 Agent 项目做了系统分析,识别出五个反复出现的设计维度:子 Agent 架构、上下文管理、工具系统、安全机制、编排逻辑。从产业实践往回看,一个生产级 Harness 目前公认有六个组件层:
第一层:工具集成。 Harness 通过 MCP 协议或直接 API 把模型连接到外部世界——文件系统、Shell、浏览器、数据库、代码执行环境。每个工具的注册表定义了权限边界、速率限制和失败语义。没有“万能权限”这回事。
第二层:内存与状态管理。 单次模型调用是无状态的,但 Agent 任务可能跑好几个小时。Harness 负责在多轮调用之间保持连续性——git 快照、JSON 进度文件、结构化的 Handoff Artifact。这块做不好,Agent 就会“失忆”。
第三层:上下文工程。 不是静态 prompt 模板。是根据当前任务状态,动态决定哪些信息需要进入模型的注意力窗口。遇到新错误?Harness 判断是把尝试历史压缩摘要、引入新源码文件、还是刷新项目约定。
第四层:规划与分解。 模型提方向,Harness 拆成可执行步骤。一步失败,触发重新规划而不是硬推。
第五层:验证与护栏。 自动化测试、格式校验、安全策略过滤。Agent 跑偏了不是人的问题,是 Harness 没拦住。
第六层:模块化。 工具、内存策略、验证逻辑都是可替换的独立组件。不会因为一个护栏升级就得重写整个 Harness。
OpenAI 那个百万行代码的仓库是这么运作的:Agent 卡住了,团队不碰代码,改的是 Harness 配置——上下文策略收了什么文件、架构约束严到什么程度、多久跑一次清理 Agent。Anthropic 的三 Agent Harness 也是同一个思路:Evaluator 拥有浏览器自动化和运行时测试能力,独立核查 Generator 的产出。用的模型没变,变的是“模型怎么被管”。
2
如果说 Harness 是操作系统,Loop Engineering 就是 Agent 的工作方法。
Loop Engineering 的命题很简单:Agent 做了一件事,怎么让它看到结果、理解结果、基于结果改进下一步?
听起来容易,做到很难。
Loop Engineering 的学术根基是 2022 年普林斯顿和 Google 提出的 ReAct 模式——Reason + Act,推理和行动交替。但 Loop Engineering 把“交替”扩展成了完整的闭环。kilo.ai 的定义比较精确:五个阶段构成一个回合,多个回合构成一个任务。
这五个阶段是:意图 → 上下文获取 → 执行动作 → 观察结果 → 调整计划。
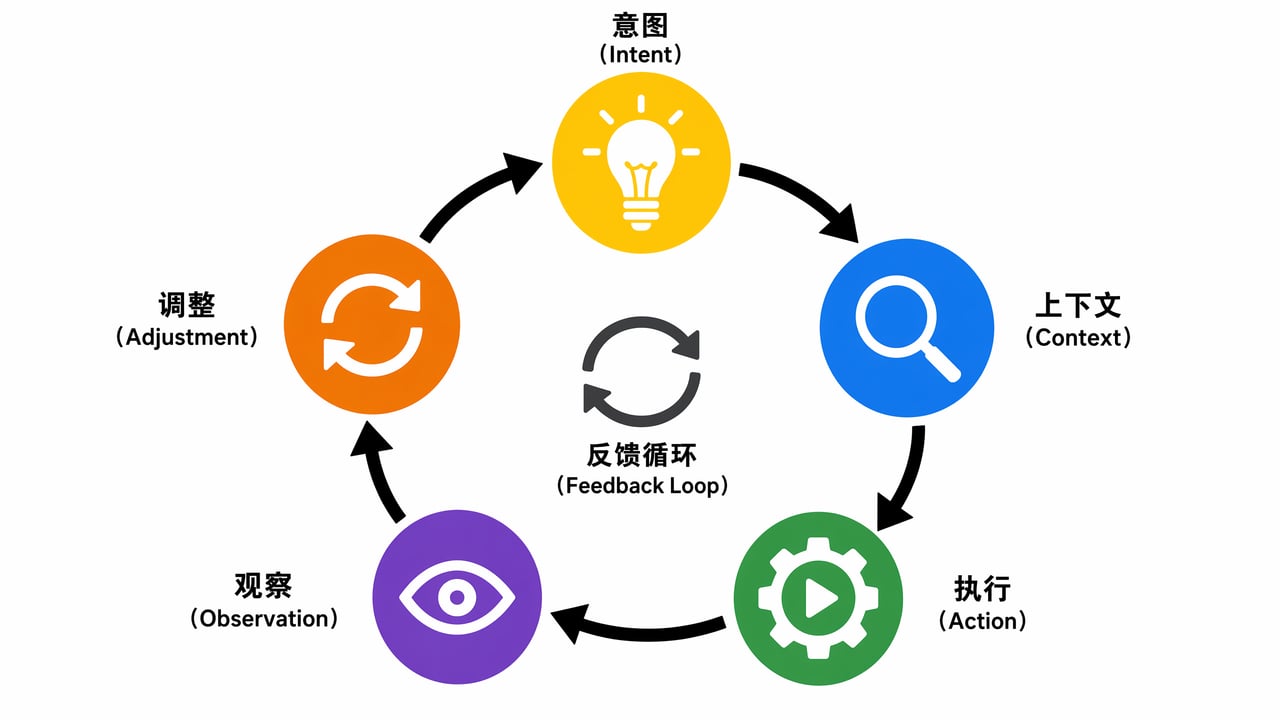
第五步是整个循环的试金石。一个差劲的循环在失败后原样重试,一模一样的方法,期待不同结果。一个好的循环会分析失败信号,改策略,换工具,缩小范围,然后再试。
MindStudio 的分析文章里举了一个例子,很能说明差距。
任务:“修 Bug——保存账单设置时公司名带撇号会失败。”
弱循环怎么做?它猜一个 SQL 转义问题,直接去打补丁。强循环怎么做?先找表单、API 路由、校验 schema、数据库更新路径。复现失败。观察错误到底出在前端校验、后端校验、序列化还是 SQL 层。然后只改最小相关的代码路径,跑一次定向回归测试。
同样的模型。差十倍的效率。差距全在循环设计。
Loop 和 Prompt 的分工很清晰。Prompt Engineering 优化模型的第一版输出。Loop Engineering 优化最终的交付结果。 前者的反馈源主要是人的评估,后者的反馈源是测试结果、编译器报错、diff 对比、日志、review 评论、再加上人的判断。
一个能出漂亮答案的模型,第一版输出可能就让人满意。但在生产级代码里,真正重要的信号往往在第一次行动之后才会出现——类型检查挂了、import 缺了一个、测试崩溃了、UI 截图暴露了布局问题、reviewer 指出了一个边缘 case。Loop Engineering 把这些信号纳入了工作流本身,而不是当作事后收拾。
常见的 Loop 模式有四种:
-
Retry Loop:原子任务,有清晰的 pass/fail 标准。每次失败换策略。
-
Plan-Execute-Verify Loop:多步任务,步骤顺序敏感。先定计划,执行一步、验证一步,发现计划错了就改计划。
-
Explore-Narrow Loop:调试未知错误、探索不熟悉的 API。多条路径并行探索,快速剪枝收敛。
-
Human-in-the-Loop:需求无法事前写死,或错误代价太高。Agent 跑到关键决策点,暂停,等人说“继续”或“换方向”。
循环设计最常出问题的不是模型质量,而是终止条件。没有成功出口——“所有测试通过且无 lint 错误”——Agent 会无休止地打磨。没有失败出口——“10 次迭代无进展则升级到人”——Agent 会原地空转,烧 token,没有产出。
3
Harness 和 Loop 是什么关系?
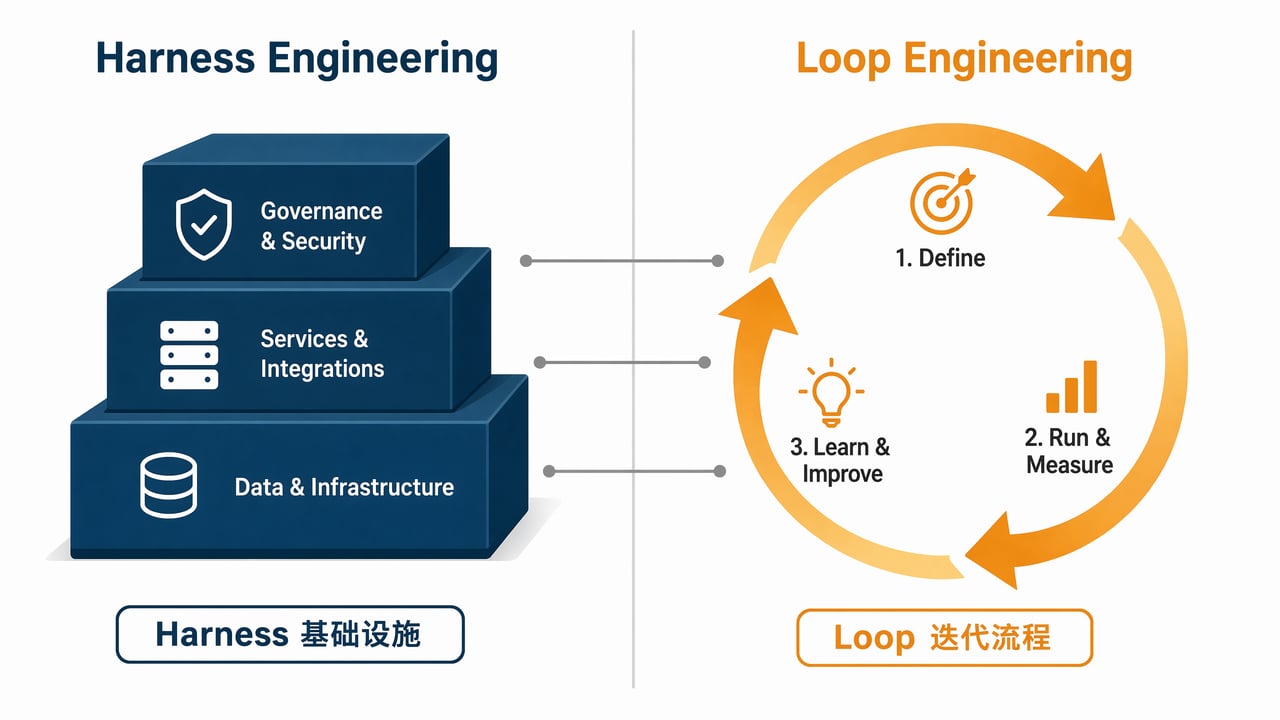
Loop Engineering 是工艺流程。Harness Engineering 是生产线。
或者换个更好懂的类比:Loop 是建筑工法——砌一层、检查垂直度、修正、再砌一层。Harness 是脚手架、安全带、物料通道和监理制度。没有人会只用其中一个盖房子。
在实践中,两者交叠很深。Loop 的每一次迭代都需要 Harness 来管理工具调用、上下文更新、安全检查。如果 Harness 的工具调用超时没人管、上下文窗口溢出了、安全检查太宽松放过了危险操作——那设计再好的 Loop 也跑不满一轮。
arXiv 上一篇关于终端 AI 编码 Agent 的论文揭示了一个很少被谈的实现细节:不同 LLM 提供者的工具调用机制完全不同——Anthropic 用 tool_use content blocks 加 extended thinking,OpenAI 用 function calling 加 structured output。这意味着同一套 Harness 必须在 Prompt 渲染层写互斥的条件分支,按运行时 provider 动态替换系统 prompt 的结构。
这个细节说出了一个更大的事实:Harness 和 Loop 的工程难度并不主要来自模型的能力天花板,而是来自模型接口的碎片化、工具行为的不确定性,以及真实环境中那些不可预测的失败方式。
4
概念讲完了,说点真的。
今年 4 月,Anthropic 发了一份 Claude Code 质量报告,坦率得少见。起因是一次质量下降,追溯下来,原因是三个 Harness 层面的改动:默认推理强度下调,一个缓存优化 Bug 持续丢弃思考历史,以及一个过于激进的 verbosity 限制 system prompt。
三个改动,没有一个碰过模型权重。但合在一起的效应足以触发用户投诉。
这件事同时说明了两面:Harness 层面有巨大的杠杆效应——它可以直接、显著地改变 Agent 的行为质量。但当前的可观测性和回滚机制还不够成熟——你改了一个“不涉及模型”的配置,三周后才发现产出质量降了。
OpenAI 和 Anthropic 在 4 月的博客里还共同描述了一个趋势:框架层的消解。
过去开发者用框架管理 Agent 定义、消息路由、任务生命周期、依赖调度。但现在模型原生的编排能力已经覆盖了其中大约八成。剩下的两成——持久化、确定性重放、成本控制、可观测性、错误恢复——正是 Harness 要接管的。
Cobus Greyling 的总结很准:框架层不是在消失,而是在分裂。智能部分回归模型,基础设施部分下沉到 Harness。
Loop Engineering 这一侧同样有硬的边界。
哈佛和 Google DeepMind 的研究者在今年 3 月的 HITL 综述中说得直白:人类反馈的可扩展性是这个范式最根本的瓶颈。任务越复杂,需要的人类判断就越频繁,但人类的时间、注意力和判断一致性并不会随任务规模线性增长。
RLTHF 这类工作尝试了一个思路:用 AI 标注替代九成以上的人类标注,只对最难判的那 6-7% 样本引入人工纠偏。结果在 HHH-RLHF 和 TL;DR 数据集上达到了全人工标注级别的对齐效果。但这是训练阶段的改进,不直接解决运行时 Loop 中的人类介入瓶颈——你不可能只靠更好标注来让 Agent 在运行时不问人。
Loop Engineering 最常见的几个失效模式,多个来源反复提到:无休止的重复循环(换了策略但换汤不换药)、过早终止(做了六成就停了,因为“看起来差不多了”)、上下文膨胀(多分支探索时 token 窗口爆炸)、错误归因(把失败归给最后一步操作,而真正的问题出在初始计划)。这四个都不是模型问题,是循环设计问题。
5
有几个争议和未解的问题值得摆出来。
第一个是自主性程度的“安全甜蜜点”在哪。
Harness 的护栏设太严,Agent 什么都不敢做。设太松,出事了才后悔。OWASP 在 2025 年专门新增了 LLM06 风险项“Excessive Agency”——Agent 权限过度授予。但具体怎么审计?除了“遵循最小权限原则”这种谁都同意却没法直接落地的大纲之外,可操作的安全 checklist 还在成形过程中。
第二个是人的角色变了,但没人在教人怎么变。
当 Agent 能自主完成多文件重构、测试修复和部署脚本时,开发者的工作重心从“写代码”转向“审查 Agent 的决策”。但决策审查对理解深度的要求比直接编码更高——你不光要知道代码应该做什么,还要能在脑子里跑 Agent 为什么选了方案 A 而不是方案 B。
MindStudio 的实践建议是“自动化证据收集和机械性修复,保留架构和产品决策给人类”。这句话在理论上没毛病,但在真实项目里,证据收集和架构决策之间的那条线经常模糊得一塌糊涂。
第三个是评估标准的缺失。
那篇 2026 年 arXiv 的综述直接点破了一个尴尬:研究者缺少一套共享词汇来描述和比较不同 Harness 的架构。没有共享词汇,就没法系统地验证“语言决定架构”或“能力增长自然带来治理成熟度”这类常见假设。这意味着今天绝大多数的 Harness 设计决策是经验性的,没有经过严格的比较验证。Anthropic 的三 Agent 对照实验是少数例外,但一个实验远远撑不起一个学科的知识体系。
第四个是 Harness 本身会不会变成新的技术债务。
OpenAI 和 Anthropic 的 SDK 正在以惊人的速度把 Harness 的原语——工具注册、多 Agent 编排、护栏层、持久化——变成平台默认功能。2024 到 2025 年间开发者手写的定制化 Harness 代码,相当一部分已经被 SDK 以更稳健的方式取代了。
但平台接管底层基础设施的另一面,是差异化从何而来的问题。当所有人的 Harness 基础能力趋同,能拉开差距的地方只剩多 Agent 编排的巧思、领域专属护栏的精度,以及真正长周期工作流的设计——这些都还需要“真正的设计”。
最后
Harness Engineering 和 Loop Engineering 这两个概念的共同指向,其实很简单:把 AI Agent 的工程焦点从“模型有多强”拉回到“我们怎么用模型”。
在模型能力持续爬升、基础能力趋同的当下,这件事比“你用的是哪个模型”重要太多了。
OpenAI 和 Anthropic 在 2026 年春天不约而同说出同一句话,不是因为他们互相看了对方的博客。
是因为他们都从生产环境里得到了同一个教训。

openEuler 是由开放原子开源基金会孵化的全场景开源操作系统项目,面向数字基础设施四大核心场景(服务器、云计算、边缘计算、嵌入式),全面支持 ARM、x86、RISC-V、loongArch、PowerPC、SW-64 等多样性计算架构
更多推荐
 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)