Prompt Injection 与 Agent Security 论文盘点:从“提示词越狱”到权限化 Agent 架构
Prompt Injection 与 Agent Security 论文盘点:从“提示词越狱”到权限化 Agent 架构

系列:AI 论文盘点 / 技术趋势
日期:2026-06-26
适合读者:研究生、LLM 应用研究者、安全工程师、Agent/RAG 系统开发者
检索日期:2026-06-26
摘要
Prompt Injection 最早像是一个“提示词工程”问题:用户在输入里写一句“忽略上文”,模型就可能偏离开发者意图。到 2025-2026 年,这个问题已经演化成 Agent Security 的核心议题:LLM 不再只是生成文本,而是在浏览器、邮件、代码仓库、MCP 工具、数据库和长期记忆之间调度权限。真正危险的不是模型“说错话”,而是未受信任的网页、邮件或工具描述影响了带权限的动作参数,比如收件人、转账账户、命令行、文件路径、API endpoint。
近一年研究的主线很清晰:攻击从直接注入转向间接注入、工具投毒、记忆投毒和多步状态污染;评测从静态 prompt 集合转向真实任务环境、浏览器代理和利益相关方视角;防御从“过滤恶意文本”转向指令层级、结构化通道、能力沙箱、来源追踪、最小权限和运行时授权。工程上最重要的启发是:不要把 LLM 当作安全边界,安全边界应该在工具、数据流、权限和可审计执行层。
目录
- 研究背景:为什么 Agent 放大了注入风险
- 近一年路线图
- 代表论文分组解读
- 方法对比表
- 关键技术趋势
- 工程落地启发
- 局限与争议
- 接下来值得关注的问题
- 参考资料
研究背景:从 prompt 混淆到权限混淆
Prompt Injection 的根因是“指令”和“数据”共享同一个自然语言上下文。传统 Web 安全里,SQL 注入危险是因为数据被解释成代码;LLM 应用里,外部文本被解释成更高优先级的任务指令。Simon Willison 在 2022 年将这一类问题命名为 prompt injection;Greshake 等人在 2023 年的 indirect prompt injection 论文进一步指出,攻击者不必直接向模型输入恶意 prompt,只要把指令藏在网页、邮件、文档或检索结果里,应用在读取外部数据时就可能被劫持。
Agent 让问题升级。普通聊天机器人最多输出错误文本;Agent 可以读取邮箱、发请求、写文件、调用支付或部署接口。此时安全问题不再只是“模型是否拒答”,而是“谁有权让哪个参数进入哪个工具调用”。OWASP 2025 将 Prompt Injection 放在 LLM 应用风险首位,并把 Excessive Agency、敏感信息泄露、供应链和工具调用风险一并纳入治理视角;MCP 官方安全实践也强调用户同意、least privilege、confused deputy 和 token passthrough 风险。NCSC 更早提醒过:Prompt Injection 可能是 LLM 技术的内生问题,不能只靠更强提示词完全消除。
近一年路线图
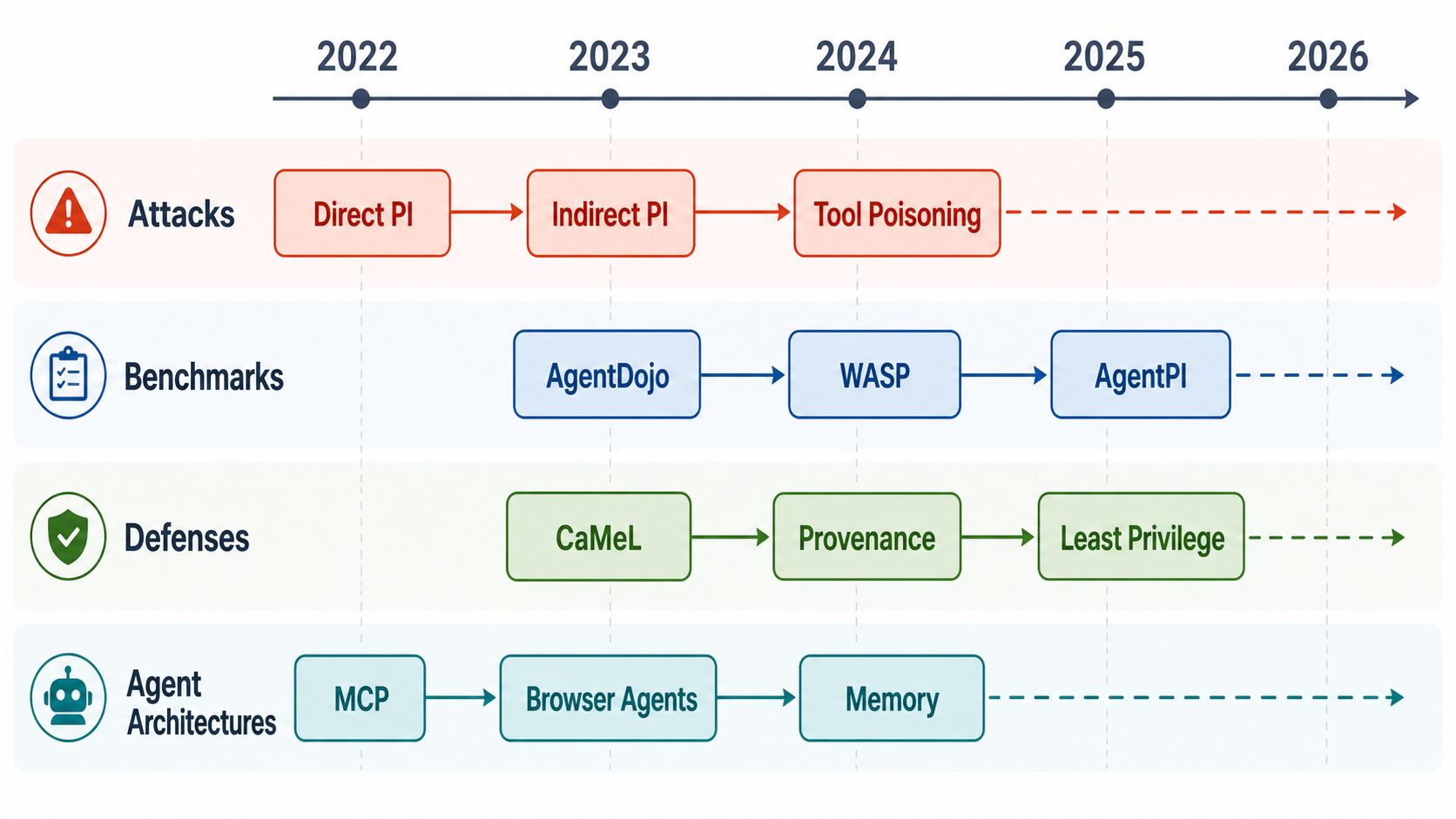
2024 年的重点是定义问题和建立环境:Instruction Hierarchy 把系统、开发者、用户、工具/第三方内容区分成不同权限层级;StruQ 用结构化查询训练模型只服从 prompt 区域的指令;AgentDojo 把邮件、银行、旅行等工具任务放进可扩展环境,评估 agent 在未受信任数据下的攻击与防御。
2025 年,研究明显转向“真实 agent 场景”。WASP 聚焦 Web Agent,把攻击者能力限制在更贴近网页内容操纵的条件下;CaMeL 把可信用户请求解析成控制流和数据流,再用 capability 限制未受信任数据影响程序流程;MCP Safety Audit 则把 MCP 生态作为新攻击面,讨论恶意工具、工具描述投毒、凭据窃取和远程执行风险。
2026 年上半年出现了更细粒度的系统化研究:AgentPI 这类 SoK/benchmark 强调 context-dependent task,即真实 agent 必须读取环境上下文才能完成任务,简单隔离外部内容会损害 utility;PACT、AuthGraph、SafeAgent、SecureClaw 等预印本把重点放到参数级 provenance、授权图、运行时控制器和读写双边界。它们还需要更多独立复现,但方向很值得关注:安全不只是输入分类器,而是执行轨迹上的权限约束。
代表论文分组解读
1. 攻击:从直接注入到状态污染
直接注入攻击通常来自用户输入,目标是覆盖系统或开发者指令;间接注入攻击来自外部数据,威胁更接近真实部署。Indirect prompt injection 的经典结论是:只要应用把网页、邮件或检索文档放进同一上下文,攻击者就可能让模型执行“用户没有授权但 agent 有能力做”的动作。
近一年攻击面继续扩张。Web agent 需要解析页面视觉元素、隐藏文本、表单和导航状态;MCP agent 需要信任第三方 server 暴露的 tool descriptions;带长期记忆的助手可能把恶意规则写入未来会话。ASB 把系统 prompt、用户 prompt、工具调用和记忆检索都纳入攻击阶段,说明 agent 安全必须看完整生命周期,而不能只在入口做一次过滤。
2. Benchmark:从静态集合到任务环境
Prompt Injection 早期 benchmark 往往像分类题:给一段文本,判断模型是否被诱导。AgentDojo 的贡献是把任务、工具和攻击组合成动态环境,并区分 task utility 与 security。论文公开摘要中列出 97 个现实任务和 629 个安全测试用例,这使研究者能比较“能否完成正常任务”和“能否抵抗攻击”之间的张力。
WASP 更进一步关注浏览器代理。其摘要报告了一个有意思的现象:一些 agent 会在 16%-86% 的情况下开始执行恶意指令,但真正端到端达成攻击目标的比例只有 0%-17%。这不是安全性的胜利,而是提醒我们:当前 agent 能力不足会“偶然降低攻击完成率”;一旦基础能力提升,同样的安全设计可能迅速失效。
2026 年的 StakeBench/AgentPI 类工作把评测焦点从攻击成功率扩展到受害方和上下文依赖。一个注入可以同时伤害用户、卖家、平台或第三方;而防御如果粗暴屏蔽环境上下文,又会让 agent 无法完成授权任务。未来 benchmark 应该同时报告任务成功、攻击成功、误拒率、延迟、权限越界类型和可审计性。
3. 防御:三条路线正在成形
第一条路线是模型侧指令优先级。Instruction Hierarchy 通过训练让模型识别高低优先级冲突;StruQ 则用结构化通道把“指令区域”和“数据区域”分开。它们适合作为基础能力,但不能单独承担系统安全边界。2025 年关于 fine-tuning 防御的白盒攻击预印本显示,结构化或对齐式防御在强攻击者下仍可能被突破,具体结论需结合后续复现核验。
第二条路线是架构侧隔离。CaMeL 的核心思想是:可信请求决定控制流,未受信任数据只能作为数据参与,不应改变程序流程;capability 用来限制数据外流。这类工作对工程师最有价值,因为它把问题从“让模型更听话”改写为“让模型没有权限犯关键错误”。
第三条路线是运行时 provenance 与授权。PACT、AuthGraph、SecureClaw 等 2026 预印本把关注点放到工具参数来源:例如邮件正文可以影响摘要内容,但不应决定转账账号或外发邮箱地址。这个方向更接近传统信息流控制、taint tracking 和 policy enforcement,可能成为 agent 平台的基础设施。
方法对比表
| 类别 | 代表工作 | 主要对象 | 优点 | 风险与待验证点 |
|---|---|---|---|---|
| 指令层级训练 | Instruction Hierarchy | 模型行为 | 让模型理解权限冲突 | 不能替代工具授权 |
| 结构化通道 | StruQ | prompt/data 分离 | 思路清楚,易解释 | 白盒攻击鲁棒性仍需核验 |
| 动态评测环境 | AgentDojo, ASB | Agent 工具任务 | 能同时测 utility 与 security | 不同任务生态可迁移性有限 |
| Web Agent 评测 | WASP, WAInjectBench, StakeBench | 浏览器代理 | 更贴近真实网页攻击 | 页面复杂度和模型版本变化快 |
| 能力沙箱 | CaMeL | 控制流、数据流、capability | 把安全边界移出模型 | 工程成本和任务覆盖率是挑战 |
| 来源/授权图 | PACT, AuthGraph, SecureClaw | 工具参数与读写边界 | 贴近权限系统,可审计 | 多为 2026 预印本,待独立复现 |
| 协议/生态审计 | MCP Safety Audit, MCP-38 | MCP server 与 tool | 覆盖新兴工具生态 | 实际 MCP 部署差异大 |
关键技术趋势
第一,Prompt Injection 正在从“输入安全”变成“执行安全”。把一句外部文本判定为恶意并不够,因为同一段网页内容在摘要任务里是数据,在转账任务里可能变成危险参数。安全策略要绑定任务、工具、参数和来源。
第二,Agent Security 正在吸收传统安全范式:least privilege、confused deputy、capability、taint tracking、policy-as-code、审计日志和人类确认。LLM 负责语义理解,但权限系统必须由确定性组件执行。
第三,MCP 和工具生态会成为高价值研究对象。MCP 降低了工具接入成本,也让工具描述、server 身份、授权 scope、token 传递和多 server 组合成为新边界。工具描述不应被默认当作可信事实,安装、更新、授权和调用都需要供应链治理。
第四,评测会从“攻击是否成功”转向“谁受损、怎么受损、能否追责”。真实平台关心的不只是 ASR,还包括 benign task completion、误拦截成本、用户确认负担、泄露路径、恢复能力和事后取证。
工程落地启发
- 把所有外部内容标成 untrusted。网页、邮件、PDF、RAG chunk、工具返回、MCP tool description、长期记忆都不应自动提升为指令。
- 对工具调用做参数级授权。允许 agent 总结邮件,不等于允许邮件正文决定收件人、附件、转账目标或 shell 命令。
- 采用最小权限和分阶段提交。高风险动作使用 PREVIEW -> USER_APPROVE -> COMMIT;commit 阶段由可信 executor 执行规范化请求。
- 记录 provenance。每个关键参数应能追溯到用户输入、系统配置、外部数据或模型生成;审计日志要覆盖读取、推理、工具调用和最终输出。
- 对 MCP/server 做供应链治理。固定 server 版本、校验发布者、限制 scope、禁止无提示扩权,避免把工具描述当作天然可信。
- 不把“系统提示词写得更严”当成主要防线。提示词可以降低误操作,但不能提供强安全保证。
- 评测要包含真实失败模式。至少覆盖直接注入、间接注入、工具投毒、记忆污染、数据泄露、越权写操作和 benign utility。
局限与争议
当前研究还有三个明显缺口。第一,很多论文在不同模型、任务和工具生态上评测,结果很难横向比较;同一个 defense 在邮件 agent 上有效,不代表在代码 agent 或浏览器 agent 上有效。第二,2026 年不少系统架构论文仍是预印本,报告的 0% ASR 或高 utility 数字需要独立复现、开源实现和更强 adaptive attack。第三,安全与可用性的矛盾尚未解决:完全隔离外部数据会让 agent 无法完成上下文依赖任务;过度信任上下文又会带来权限混淆。
因此,本文不把任何单一方案视为最终答案。更现实的部署形态可能是组合式:模型侧指令层级作为基础,工具层最小权限作为硬边界,运行时 provenance/authorization 作为审计和拦截层,高风险动作交给人类确认。
接下来值得关注的问题
- 是否会出现面向 Agent 的通用信息流控制框架,像 Web 安全里的 CSP/权限模型一样成为平台默认能力?
- MCP 生态是否会形成可验证的工具身份、权限声明、签名更新和安全审计规范?
- 长期记忆如何做可撤销、可解释、可隔离的安全治理?
- Web agent 的视觉注入、隐藏文本和跨页面状态污染如何被系统化评测?
- 评测指标能否从 ASR 扩展到 stakeholder harm、误拒成本和恢复能力?
总结
Prompt Injection 的研究重心已经从“模型会不会听攻击者的话”转向“agent 的权限是否被未受信任数据间接控制”。近一年最重要的趋势不是某个 detector 分数更高,而是安全边界正在外移:从 prompt 到结构化上下文,从模型到工具运行时,从文本分类到参数来源和授权关系。对工程团队来说,最稳妥的路线是承认 LLM 不是安全边界,把 agent 看成一套有权限、有状态、有供应链的软件系统来设计。
参考资料
检索日期:2026-06-26。
- Simon Willison, “Prompt injection attacks against GPT-3”, 2022. https://simonwillison.net/2022/Sep/12/prompt-injection/
- Kai Greshake et al., “Not what you’ve signed up for: Compromising Real-World LLM-Integrated Applications with Indirect Prompt Injection”, arXiv, 2023. https://arxiv.org/abs/2302.12173
- Eric Wallace et al., “The Instruction Hierarchy: Training LLMs to Prioritize Privileged Instructions”, arXiv, 2024. https://arxiv.org/abs/2404.13208
- Sizhe Chen et al., “StruQ: Defending Against Prompt Injection with Structured Queries”, arXiv / USENIX Security 2025. https://arxiv.org/abs/2402.06363
- Edoardo Debenedetti et al., “AgentDojo: A Dynamic Environment to Evaluate Prompt Injection Attacks and Defenses for LLM Agents”, arXiv, 2024. https://arxiv.org/abs/2406.13352
- Hanrong Zhang et al., “Agent Security Bench (ASB): Formalizing and Benchmarking Attacks and Defenses in LLM-based Agents”, arXiv, 2024. https://arxiv.org/abs/2410.02644
- Ivan Evtimov et al., “WASP: Benchmarking Web Agent Security Against Prompt Injection Attacks”, arXiv, 2025. https://arxiv.org/abs/2504.18575
- Edoardo Debenedetti et al., “Defeating Prompt Injections by Design”, arXiv, 2025. https://arxiv.org/abs/2503.18813
- Brandon Radosevich and John Halloran, “MCP Safety Audit: LLMs with the Model Context Protocol Allow Major Security Exploits”, arXiv, 2025. https://arxiv.org/abs/2504.03767
- Yinuo Liu et al., “WAInjectBench: Benchmarking Prompt Injection Detections for Web Agents”, arXiv, 2025. https://arxiv.org/abs/2510.01354
- Peiran Wang et al., “The Landscape of Prompt Injection Threats in LLM Agents: From Taxonomy to Analysis”, arXiv, 2026. https://arxiv.org/abs/2602.10453
- Zihao Wang et al., “Who Pays the Price? Stakeholder-Centric Prompt Injection Benchmarking for Real-world Web Agents”, arXiv, 2026. https://arxiv.org/abs/2606.13385
- Linfeng Fan et al., “The Granularity Mismatch in Agent Security: Argument-Level Provenance Solves Enforcement and Isolates the LLM Reasoning Bottleneck”, arXiv, 2026. https://arxiv.org/abs/2605.11039
- Peiran Wang et al., “Aligning Provenance with Authorization: A Dual-Graph Defense for LLM Agents”, arXiv, 2026. https://arxiv.org/abs/2605.26497
- Hailin Liu et al., “SafeAgent: A Runtime Protection Architecture for Agentic Systems”, arXiv, 2026. https://arxiv.org/abs/2604.17562
- Yuhan Ma and Stefan Schmid, “SecureClaw: Clawing Back Control of LLM Agents”, arXiv, 2026. https://arxiv.org/abs/2606.09549
- Yi Ting Shen et al., “MCP-38: A Comprehensive Threat Taxonomy for Model Context Protocol Systems”, arXiv, 2026. https://arxiv.org/abs/2603.18063
- OWASP, “LLM01: Prompt Injection”, OWASP Top 10 for LLM Applications 2025. https://genai.owasp.org/llmrisk/llm01-prompt-injection/
- OWASP Cheat Sheet Series, “LLM Prompt Injection Prevention Cheat Sheet”. https://cheatsheetseries.owasp.org/cheatsheets/LLM_Prompt_Injection_Prevention_Cheat_Sheet.html
- Model Context Protocol, “Security Best Practices”, specification version 2025-06-18. https://modelcontextprotocol.io/specification/2025-06-18/basic/security_best_practices/
- NIST, “Artificial Intelligence Risk Management Framework: Generative Artificial Intelligence Profile”, NIST AI 600-1, July 2024. https://doi.org/10.6028/NIST.AI.600-1
- UK NCSC, “Exercise caution when building off LLMs”, 2023. https://www.ncsc.gov.uk/blog-post/exercise-caution-building-off-llms

openEuler 是由开放原子开源基金会孵化的全场景开源操作系统项目,面向数字基础设施四大核心场景(服务器、云计算、边缘计算、嵌入式),全面支持 ARM、x86、RISC-V、loongArch、PowerPC、SW-64 等多样性计算架构
更多推荐
 3
3 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)