时序数据库国产化深水区:从 DolphinDB 首批通过安全可靠测评看选型与迁移

摘要
安可替代走到今天,操作系统、关系型数据库、中间件基本都换过了,但工业场景里那一层"看不见的时序数据底座"一直卡着。2026 年 5 月,DolphinDB 成为首批通过国家安全可靠测评的时序数据库——这块拼图才算补上。这篇不写营销稿,从一个具体问题出发:当一个团队拿到"时序数据库国产化"的任务单,到底该怎么选、怎么迁。
过去几年里,国产化替代在各行各业推进得很快。如果你参与过这类项目,大概率会有一个感受:操作系统和 OLTP 数据库的替代方案已经很成熟,真正让人头疼的,是工业和金融场景里那一层时序数据基础设施。
这层基础设施的尴尬之处在于,它不像 OLTP 数据库那样有明确的"对标杆",也不像操作系统那样标准化程度高。它散落在电网监控、车联网、产线质检、金融行情、地震监测这些场景里,每个场景的写入量、查询模式、实时性要求都不一样。更麻烦的是,很多团队一开始根本没把它当作"国产化清单"上的独立一项——它要么被塞进 MySQL,要么被拼装成"InfluxDB + Flink + Spark"的组合,直到数据量涨上来、性能撑不住,才意识到这是一个需要专门对待的品类。
2026 年 5 月 26 日,中国信息安全测评中心、国家保密科技测评中心发布的《安全可靠测评结果公告(2026 年第 2 号)》里,DolphinDB 数据库软件成为首批通过安全可靠测评的时序数据库。这件事的价值,与其说是一款产品拿了证书,不如说是时序数据库这个品类第一次有了国家级的"准入背书"。
下面就从选型和迁移的工程视角,拆解一下这件事对实际项目的意义。

一、时序数据库为什么是国产化里最难啃的一层
先说清楚问题本身。时序数据库的国产化难,不是难在"有没有国产产品"——国产时序库这几年冒出来不少。真正难的是三点。
1.1 性能要求极端,不是"能跑"就行
时序场景的写入压力,往往远超普通业务系统。一座大型水电站有 200 多万个传感器测点,每天产生数百亿行数据;某新能源车企的车联网平台,单车测点接近 7000 个,每秒要持续写入 1.8 亿个测点;地震台网中心每 10 毫秒就要采一条监测记录。
这些数字背后是一个硬约束:数据库不能因为写入高峰而把查询拖垮,也不能因为复杂分析而让写入阻塞。很多国产时序库在 demo 环境跑得很漂亮,一到这种持续高并发写入的真实场景,写入延迟开始抖动、查询响应陡然上升——而工业场景里,抖动往往就意味着告警丢失、故障漏报。
1.2 场景碎片,一套方案很难通用
同样是时序数据,金融行情看重的是低延迟查询和复杂因子计算,电网监控看重的是实时异常检测,产线质检看重的是和历史数据的关联分析。一个产品要在这些场景里都站得住,靠的不只是存储能力,还得有足够的计算和分析能力——而这恰恰是很多"纯存储型"时序库的短板。
1.3 迁移风险高,没人敢轻易动核心系统
这是最现实的一点。时序数据库往往承接的是核心业务(电网调度、核工业监控、金融风控),一旦迁移出问题,代价不是"应用慢一点",而是安全事故。所以很多团队的国产化清单里,时序数据库是被放到最后处理的——不是不想换,是不敢换。
这次 DolphinDB 首批通过安全可靠测评,等于给这种"不敢换"提供了一份外部背书:至少有一款时序库,在核心技术自主性、安全保障、持续发展能力、关键行业应用这四个维度上,被国家权威机构验过了。对采购决策来说,这降低了"选错产品"的风险——很多国产化项目里,选型者最大的压力不是技术判断,而是"出了事谁担责",一份国家测评背书,能极大缓解这种压力。
二、安全可靠测评对选型决策的实际价值
上面对测评的解读偏感性,这里说点务实的:对一线选型者,这份测评到底意味着什么。
第一,它是国产化采购的"通行证"。在很多关键行业的采购流程里,产品是否在安全可靠测评清单上,是能否进入招标的前提条件。时序数据库此前一直是清单上的空白,这意味着很多项目要么用国外产品(合规风险),要么用未通过测评的国产产品(审计风险)。现在有了通过测评的时序库,这个矛盾才算真正解开。
第二,它筛掉了"包装壳"产品。安全可靠测评对核心代码自主性、关键技术指标有硬要求——核心代码是否自主可控、关键指标是否达到国际同类水平,都要被审查。这相当于帮选型者做了一轮前置筛选,至少不用担心选到套壳的开源项目。
第三,它强制要求真实的大规模落地。测评的"关键行业应用能力"这一项,要求产品在金融、能源、电力等关键行业有真实的大规模运行记录。这一条比任何白皮书都管用——白皮书上的性能数字可以优化,但核心系统里的长期运行记录没法伪造。
需要说明的是,通过测评不等于"完美无缺",它解决的是"准入和背书"问题,选型时仍要结合自己的场景做技术验证。但有一份国家测评打底,选型者的决策风险确实降了一个量级。

三、选型时容易被忽略的几个硬指标
下面这部分更偏技术。如果你正在做时序数据库选型,有几个指标比"标称的写入吞吐"更值得盯,它们往往决定了系统上线后能不能撑住。
3.1 写入吞吐的真实天花板,而不是峰值
很多时序库宣传的写入吞吐是"峰值"——在短时间内、资源充裕时的瞬时能力。但工业场景要的是持续稳定的高写入。DolphinDB 在那个 1.8 亿点/秒的车联网场景里,资源利用率稳定在 40% 左右,这说明它还有很大余量;而有些产品跑满 CPU 才能达到标称值,真实部署时一旦有查询压力,写入就会掉速。选型时一定要问的是"持续写入能力"和"写入时的资源占用",而不是峰值。
3.2 数据量增长后的查询衰减曲线
时序数据的特点是只增不减,数据量会持续膨胀。一个常见的坑是:系统上线时查询毫秒级,数据量翻几倍后查询变成秒级甚至更慢。这背后是存储引擎和索引设计的差异。DolphinDB 在单表百亿、千亿级数据量下仍能保持毫秒级查询(核工业案例里,单表百亿级实现了毫秒级查询响应),这种"衰减曲线平缓"的能力,远比上线初期的漂亮数字重要。选型时最好用自己业务预期的数据规模做长期压测,而不是用小数据量 demo。
3.3 流批一致性,而非"支持流计算"
很多时序库宣称支持流计算,但选型者真正要关心的不是"有没有流计算模块",而是流计算结果和离线批处理结果是否一致。传统拼装方案里,实时用 Flink、离线用 Spark,两套代码两套逻辑,结果对不上时排查成本极高——这在金融风控、设备预警里是致命的。DolphinDB 的做法是用同一套脚本同时做流式和批量计算,并保证结果完全一致。这个能力在 demo 里看不出来,只有真正做过实时+离线双系统的人才知道它省了多少事。
3.4 事务能力:时序库里的稀缺品
这一点经常被低估。时序库支持 ACID 事务的产品在行业里并不多,但它在工业场景里的价值很实在:海量传感器数据并发写入的同时,业务系统在做复杂查询——没有事务保障,读到的可能是"半写半未写"的中间状态,分析结果就不可信。DolphinDB 是少数提供完整事务机制、保证 ACID 特性和快照级隔离的时序库之一。如果你的场景里"读取的数据必须可信",这是一个硬指标。
四、迁移落地:从 MySQL/InfluxDB 到 DolphinDB 的现实考量
选型之后是迁移,这才是真正考验工程能力的地方。结合公开案例,迁移路径上有几个现实问题值得提前想清楚。
4.1 为什么"直接套 MySQL"会崩
很多团队的时序数据最初是存在 MySQL 里的——毕竟关系型数据库最熟悉。但 MySQL 的设计目标根本不是高频时序写入。以中核集团某研究院为例,它原来的工业组态监控体系就基于 MySQL 搭建,随着测点增多和采样频率提升,MySQL 在并发写入和毫秒级查询上都撑不住了。迁移到 DolphinDB 后,用 PKEY 引擎保证从 MySQL CDC 同步过来的关系型数据完整性,用 TSDB 引擎处理海量时序数据,单表百亿级数据下实现了毫秒级查询响应,完成了对 MySQL 的平滑替代。
这个案例的启示是:不要等到 MySQL 崩了才考虑迁移。时序数据一旦规模上来,关系型数据库的短板会快速暴露,提前规划专用时序库的迁移路径,比事后救火成本低得多。
4.2 为什么"拼装方案"维护成本高
另一种常见做法是"拼装"——用 InfluxDB 之类的时序库做存储,用 Flink 做实时流处理,用 Spark 做离线分析,用 Python 做机器学习。这套方案功能上能凑齐,但维护成本极高:多个系统要分别部署、监控、扩容,数据在系统间反复搬运,每一次搬运都是潜在的故障点和性能损耗。
DolphinDB 的思路是把这些能力收拢到一个平台——存算一体架构让计算直接下推到存储节点,流批一体让实时和离线用同一套代码,2000 多个内置函数加上库内机器学习推理(支持 libTorch、XGBoost 等插件),让复杂分析在数据库内闭环完成。某智能制造企业仅用 3 台 4 核 32GB 服务器就满足了 32.4 万点/秒的实时写入,在百亿数据量级下实现毫秒级即席查询——这种资源效率,是"拼装方案"很难达到的。
4.3 迁移路径:数据接入与脚本复用
迁移中最担心的两件事是"历史数据怎么办"和"现有代码要不要重写"。这两点 DolphinDB 的设计是照顾到了的:
-
数据接入:原生支持 MQTT、OPC UA/DA、Modbus、IEC 104 等主流工业协议,可通过插件从 Kafka、MySQL、Oracle、MongoDB、HDFS 导入存量数据。某海关电子口岸就把原本分散在 MongoDB、Oracle、MySQL 里的 TB 级数据,融合到了统一实时数据仓库,复杂计算响应从分钟级降到秒级。
-
脚本复用:DolphinDB 支持流批一体,研发阶段基于历史数据写的分析脚本,可以直接复用到生产环境的实时数据流。这意味着迁移不只是"搬数据",分析逻辑也能平滑过渡。

再加上它完成了龙芯、鲲鹏、飞腾、海光、兆芯等国产 CPU 和统信 UOS、银河麒麟等国产操作系统的全栈适配,在信创环境下的部署也不需要额外做适配工作。
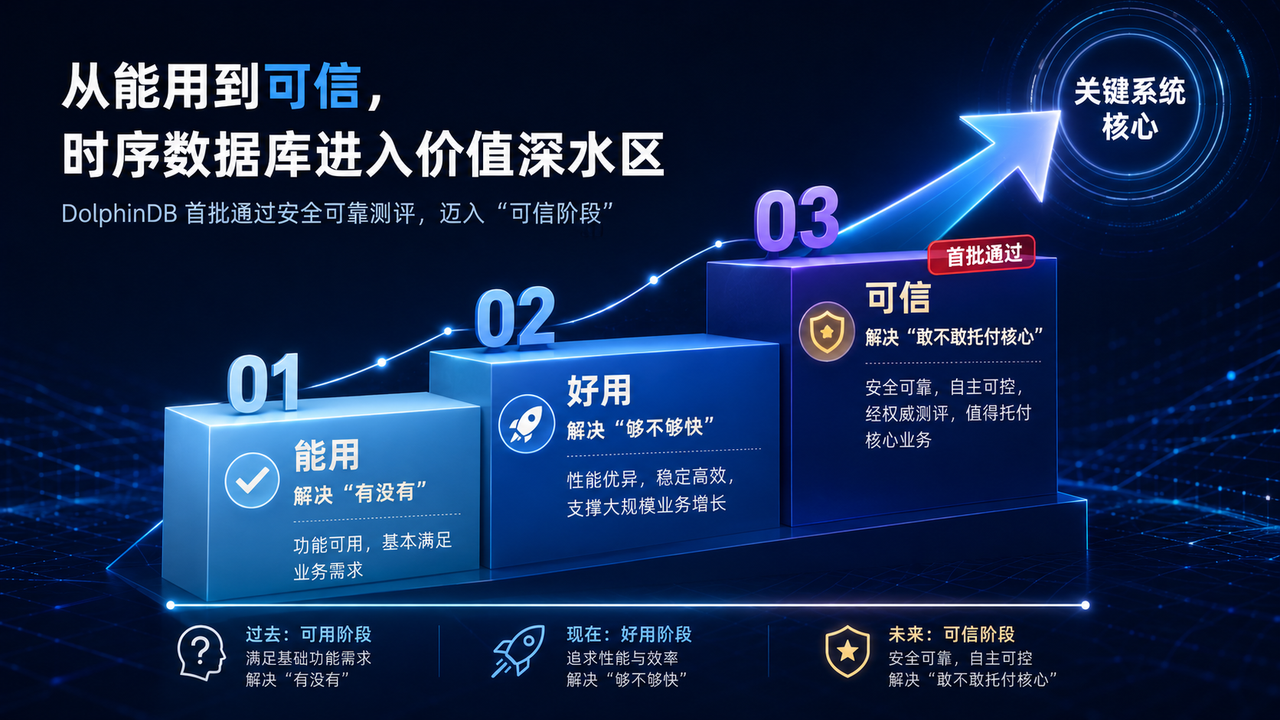
五、写在最后:从"可用"到"可信"的距离
回到开头那个问题:当一个团队拿到"时序数据库国产化"的任务单,该怎么选、怎么迁。
DolphinDB 首批通过国家安全可靠测评这件事,给出的不是"你应该选哪个产品"的答案,而是重新定义了时序数据库国产化的评判标准——从"有没有国产产品可选",升级到"哪款国产产品能被信任地放进核心系统"。
过去国产时序库行业解决的是"能用"的问题,后来是"好用"的问题。但"能用""好用"都不足以让金融、核工业、电网这些场景敢于把核心系统托付出去——这些场景真正在意的,是自主可控、安全保障、长期稳定、真实落地,而这些恰恰是安全可靠测评在考核的东西。
所以这次首批通过的象征意义,大于产品意义:它意味着时序数据库这个品类,正式进入了"可信"阶段。当一份国家级测评背书、几个关键行业的长期运行记录、一套自主可控的技术体系叠加在一起,"不敢换"的那个理由,正在被一点点拆解。
当然,国产时序数据库替代不可能一蹴而就。每个团队的场景、数据规模、现有架构都不同,选型和迁移都需要结合自身情况做扎实的技术验证。但至少从今天起,做这件事的人手里,多了一份可以参考的坐标系——而不是只能在"国外产品"和"不踏实的国产产品"之间二选一。
这,或许才是这次测评通过最实在的价值。
参考与延伸阅读
-
中国信息安全测评中心《安全可靠测评结果公告(2026 年第 2 号)》
-
中国信通院分布式时序数据库稳定性专项评测、性能专项评测、基础能力专项评测

openEuler 是由开放原子开源基金会孵化的全场景开源操作系统项目,面向数字基础设施四大核心场景(服务器、云计算、边缘计算、嵌入式),全面支持 ARM、x86、RISC-V、loongArch、PowerPC、SW-64 等多样性计算架构
更多推荐

 4
4 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)