HDFS的读写流程
HDFS(分布式文件管理系统)
什么是文件管理系统
1 文件系统: 文件系统是一种存储和组织计算机数据的方法,它使得对其访问和查找变得容易。
2 文件名 : 在文件系统中,文件名是用于定位存储位置。
3 元数据(Metadata):保存文件属性的数据,如文件名,文件长度,文件所属用户组,文件存储位置等。
4 数据块(Block):存储文件的最小单元。对存储介质划分了固定的区域,使用时按这些区域分配使用。
HDFS产生背景
随着数据量的增加,在一个操作系统存不下所有的数据,那么久分配到更多的操作系统管理的磁盘中,但
将数据分散的存储在不同的操作系统中,不便于管理和维护,迫切需要一种系统来管理多台机器上的文
件,这就是分布式文件管理系统。HDFS只是分布式文件管理系统中的一种
HDFS 优缺点
优点:
高容错性:认为硬件总是不可靠的(提供副本机制,默认副本数是3)
高吞吐量:为大量数据访问的应用提供高吞吐量支持
大文件存储:支持存储TB-PB级别的数据
缺点:
低时间延迟数据访问的应用,例如几十毫秒范围
原因:HDFS是为高数据吞吐量应用优化的,这样就会造成以高时间延迟为代价
大量小文件
原因:NameNode启动时,将文件系统的元数据加载到内存,因此文件系统所能存储的文件总数受限于NameNode内存容量,那么需要的内存空间将是非常大的。
HDFS架构
HDFS架构包含三个部分NameNode: 名称节点NameNode是HDFS中最重要的进程,它负责管理文件系统的命名空间、数据块映射以及数据块的位置信息。每个HDFS集 群只有一个活动的NameNode进程,多个备份节点用于提高可用性。DataNode: 数据节点DataNode是存储实际数据的进程,它将文件划分为数据块,并负责存储和检索这些数据块。每台机器上都会运行一个 DataNode进程,它们与NameNode进行通信以更新块列表和报告状态secondarynamenode:第二名称节点SecondaryNameNode并不是NameNode的备份节点,它主要负责定期合并NameNode的编辑日志(EditLog)和镜像文 件(FsImage),以减少NameNode故障时的恢复时间。
一、HDFS 写数据流程(上传文件)
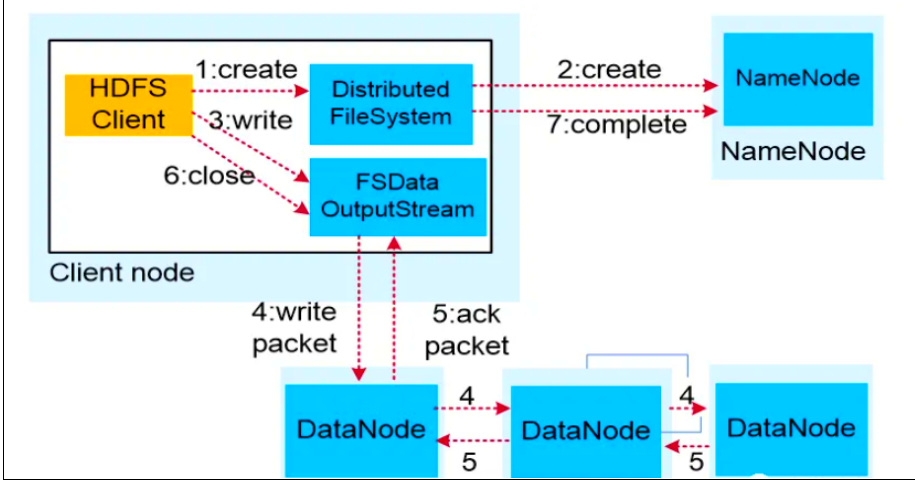
1.业务应用调用HDFS Client提供的API,请求写入文件。2.HDFS Client(客户端)联系NameNode,NameNode在元数据中创建文件节点。3.业务应用调用write API写入文件。4.HDFS Client收到业务数据后,从NameNode获取到数据块编号、位置信息后,联系DataNode,并将需要写入数据的5.DataNode建立起流水线。完成后,客户端再通过自有协议写入数据到DataNode1,再由DataNode1复制到DataNode2, DataNode3。6.写完的数据,将返回确认信息给HDFS Client。7.所有数据确认完成后,业务调用HDFS Client关闭文件。8.业务调用close, flush后HDFSClient联系NameNode,确认数据写完成,NameNode持久化元数据。
假设客户端执行命令:hdfs dfs -put local.txt /input/
详细步骤:
-
创建文件请求
-
Client向NameNode发起创建文件请求(
create)。 -
NameNode检查目标路径是否存在、客户端是否有写权限等。若通过,NameNode在元数据中记录新文件信息(此时文件块列表为空)。
-
-
建立数据流管道(Pipeline)
-
Client向NameNode询问:“文件第一个块(Block)应该存放在哪些DataNode上?”
-
NameNode根据机架感知策略(Rack Awareness)返回一组DataNode地址(默认3个副本)。
-
策略:第1个副本放在本地节点(若客户端在集群内)或随机节点;第2个副本放在不同机架的节点;第3个副本放在与第2个副本同机架的不同节点。
-
-
Client与最近的DataNode(DN1)建立TCP连接,DN1与DN2建立连接,DN2与DN3建立连接,形成一条流水线(Pipeline)。
-
-
数据分块与写入
-
Client将文件切分为多个数据包(Packet,默认64KB)。
-
Client将第一个Packet发送给DN1。
-
DN1收到后,立即缓存并转发给DN2;DN2同样缓存并转发给DN3。这个过程是流式并行的。
-
-
确认机制(ACK)
-
每个DataNode在成功写入一个Packet后,会向上游发送一个ACK确认包。
-
当Packet经过整个Pipeline回到Client时,Client才认为该Packet写入成功。
-
如果某个DataNode写入失败,Pipeline会被关闭,NameNode会重新分配新的DataNode,继续写入,保证副本数。
-
-
关闭文件与元数据更新
-
当一个Block写满(默认128MB),Client会请求NameNode分配下一个Block的DataNode列表,重复步骤2-4。
-
所有数据块写完后,Client调用
close()方法。 -
NameNode将文件的块列表、副本位置等元数据持久化到FsImage中,完成文件创建。
-
Client -> NameNode (请求创建文件)
Client -> DN1 -> DN2 -> DN3 (建立Pipeline)
Client -> DN1 [Packet1] -> DN2 [Packet1] -> DN3 [Packet1]
<- ACK1 <- ACK1 <- ACK1 (确认)
... (循环直到Block写完)
Client -> NameNode (更新元数据)
二、HDFS 读数据流程(下载文件)
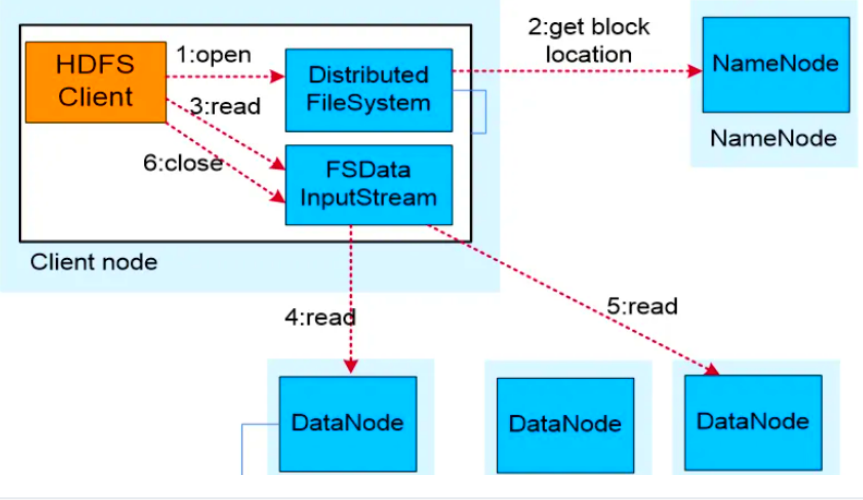
1.业务应用调用HDFS Client提供的API打开文件。2.HDFS Client联系NameNode,获取到文件信息(数据块、DataNode位置信息)。3.业务应用调用read API读取文件。4.HDFS Client根据从NameNode获取到的信息,联系DataNode,获取相应的数据块。(Client采用就近原则读取数据)。5.HDFS Client会与多个DataNode通讯获取数据块。6.数据读取完成后,业务调用close关闭连接。
假设客户端执行命令:hdfs dfs -get /input/file.txt ./
详细步骤:
-
文件定位请求
-
Client向NameNode发起打开文件请求(
open)。 -
NameNode返回文件的块列表及每个块的位置信息(即存放该块的DataNode地址)。
-
注意:NameNode只返回有该块副本的DataNode列表,按距离Client的远近排序(本地 > 同机架 > 不同机架)。
-
-
选择DataNode读取
-
Client根据返回的列表,选择最近的一个DataNode(网络拓扑距离最短)建立连接,开始读取数据。
-
读取单位是Packet,Client会校验数据的完整性(通过校验和)。
-
-
跨块读取
-
读完一个Block后,Client关闭与当前DataNode的连接。
-
向NameNode询问下一个Block的位置,连接到新的DataNode继续读取。
-
这个过程对Client是透明的,看起来像在读一个连续的文件流。
-
-
异常处理
如果读取某个DataNode失败(如节点宕机),Client会尝试从其他存有该副本的DataNode读取,并通知NameNode该节点异常。
Client -> NameNode (请求文件块位置)
NameNode -> Client (返回Block1: DN1,DN2,DN3; Block2: DN2,DN4...)
Client -> DN1 (读取Block1)
Client -> DN2 (读取Block2)
... (直至读完所有块)
常用指令:
1. 文件/目录增删改查
# 1. 查看目录内容
hdfs dfs -ls /input
hdfs dfs -ls -R /input # 递归查看(查看子目录)# 2. 创建目录
hdfs dfs -mkdir /test
hdfs dfs -mkdir -p /data/log/2024 # 递归创建多级目录# 3. 上传文件(本地 → HDFS)
hdfs dfs -put local.txt /input/
hdfs dfs -copyFromLocal local.txt /input/ # 同上,正式环境常用
hdfs dfs -moveFromLocal local.txt /input/ # 上传后删除本地文件# 4. 下载文件(HDFS → 本地)
hdfs dfs -get /input/file.txt ./local/
hdfs dfs -copyToLocal /input/file.txt ./local/# 5. 查看文件内容
hdfs dfs -cat /input/file.txt
hdfs dfs -text /input/file.txt.gz # 自动识别压缩格式(如gz、seq)
hdfs dfs -tail /input/file.txt # 查看文件尾部(常用于看日志)# 6. 删除文件/目录
hdfs dfs -rm /input/test.txt
hdfs dfs -rm -r /input/tmp # 递归删除目录(慎用!)
hdfs dfs -rm -skipTrash /input/tmp # 直接删除,不经过回收站# 7. 复制/移动(HDFS内部)
hdfs dfs -cp /input/a.txt /output/
hdfs dfs -mv /input/a.txt /output/b.txt# 8. 统计文件大小
hdfs dfs -du -h /input # 人性化显示大小
hdfs dfs -df -h / # 查看HDFS总磁盘使用情况
2. 权限与属性管理
# 修改权限(类似Linux chmod)
hdfs dfs -chmod 755 /input
hdfs dfs -chmod -R 777 /test # 递归修改# 修改属主/属组
hdfs dfs -chown user1:group1 /input/file.txt
hdfs dfs -chgrp group1 /input/file.txt# 修改副本数(针对已有文件)
hdfs dfs -setrep -w 2 /input/file.txt # 修改为2个副本,-w等待完成
hdfs dfs -setrep -R 3 /data # 递归修改目录下所有文件

openEuler 是由开放原子开源基金会孵化的全场景开源操作系统项目,面向数字基础设施四大核心场景(服务器、云计算、边缘计算、嵌入式),全面支持 ARM、x86、RISC-V、loongArch、PowerPC、SW-64 等多样性计算架构
更多推荐

 4
4 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)