操作系统 第四章 时间的协调 处理器调度原理与设计
指令流是什么?
指令流:
独立执行的指令序列,执行指令流可以完成程序的功能
指令流的组成:
计算期和IO期
指令流的分工:
可以按功能分工,一些负责IO,一些负责计算。
可以按对象分工,处理不同的数据和对象。‘
指令流的执行:
顺序执行
优势:简单
劣势:不能被打断
有问题:需要打断怎么办?
什么时候会被打断:
优先级:更紧急的事发生
IO执行期:IO很慢,CPU等着没事干
资源超限:超时或恶意占用
恶意程序
需要通信:某些指令流依赖其他指令流传递数据
怎么办?
合作执行
拆成几段,每一段顺序执行,主动放弃CPU占用权
特点:
自愿放弃:只有指令流主动放弃CPU或执行完毕才是交还CPU试使用权的方式
顺序确定:可以指定也可以随机
有问题:缺乏强制性,恶意程序可以长期占用
并发执行/抢占执行
允许指令流任何时刻被打断,插入新的指令流。
特点:
虽然每个任务(指令流)都觉得自己独占了一个CPU在跑,但实际上系统会在它们之间快速切换,而且你无法预知下一个轮到谁。
问题:切换时如何保留信息(上下文、状态)
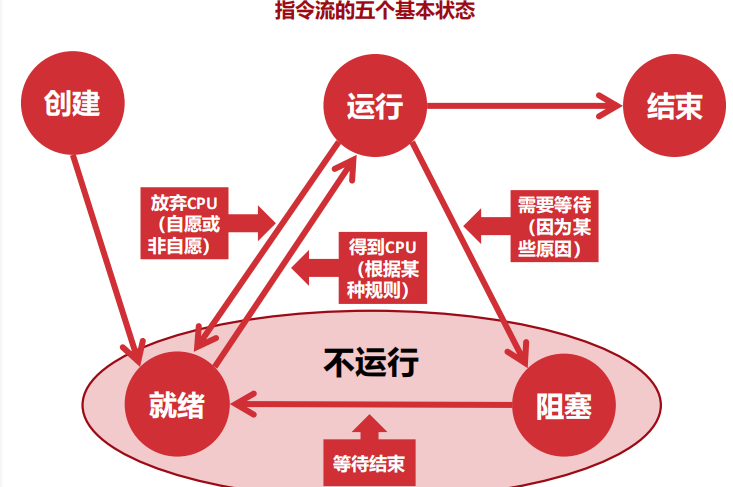
指令流的描述
上下文:能够使其恢复被打断时的状态的寄存器组、执行栈
状态:运行、不运行(就绪、阻塞)
处理器时间分配
指令流与时间:操作系统需要给指令流分配CPU使用的时间,让指令流拿着这个配额运行,但操作系统不知道程序有几条指令流,因此需要一个代理人线程,作为CPU时间的分配对象,指令流与线程对应后运行。
指令流——独立执行的指令序列,必须由线程代理
线程——CPU时间分配的对象
进程——内存空间分配的对象
问题:切换指令流就要切换线程,如何保留上下文
线程的描述
线程的身份证——线程控制块(TCB)
TCB放在内核
时间与优先级
线程上下文
内核阻塞:如果一个线程因为要读写硬盘(I/O)被卡住了(内核阻塞),操作系统会直接把整个线程挂起。如果这个线程里还跑着别的指令流,那些指令流也会跟着一起“冻结”。
操作系统通过TCB来管理线程(载体),利用时间预算和优先级来决定谁先谁后,利用上下文切换来实现并发。而指令流,就是依附在线程这个载体上,实际执行逻辑的“灵魂”。
“指令流”与操作系统眼中的“线程”之间,到底该怎么连线?
一对一
- 逻辑:一个指令流,分配一个内核线程。
- 优点:简单、清晰。指令流的状态和线程的状态完全同步。
- 缺点:太“贵”了。
- 每个指令流都要占用一个内核线程,而内核线程是稀缺资源。
多对一
- 逻辑:用户程序里有很多指令流,但它们共享同一个内核线程。
- 优点:高效。
- 因为只有一个内核线程,所以只需要一个TCB(线程控制块)。
- 指令流切换在用户态完成,不需要陷入内核。
- 致命弱点:怕阻塞。
- 一个指令流被卡住,整个内核线程都会挂起。
多对多
- 逻辑:用户创建很多指令流,映射到数量可控的一组内核线程上。
- 优点:灵活且健壮。
- 既保留了多对一的切换效率(用户态可以先调度)。
- 又解决了阻塞问题:如果一个指令流阻塞了,它只占用一个内核线程,调度器可以把其他没阻塞的指令流放到空闲的内核线程上继续跑。
- 缺点:复杂。
纤程与协程
- 协程:其实就是多对一模型下的用户态指令流。它强调“合作”,必须主动让出CPU,切换极快。
- 纤程:也是用户态指令流,但更强调“轻量”,通常由用户空间的调度器管理。
总结
指令流是什么?如何描述一个指令流?有哪三种状态,如何转化?如何分类?如何执行(顺序-合作-优先/抢占)
指令流要运行,必须依赖于线程,线程是什么?
如何管理线程?
线程和指令流的关系?
线程和指令流的对应关系?
(纤程与协程)
☆ 考点 调度策略
调度器如何决定哪个线程先运行,运行多久?
方案一:事先指定 硬实时系统
优点:对任务知根知底才行。功能简单
缺点:必须知晓整个任务,且程序必须自己开发。且用途固定,无法动态修改。
例子:刹车 火箭 飞机
固定优先级:
按优先级运行,时间预算无限
非抢占式:线程运行必须结束才会被打断,结束后执行池中优先级最高的线程
抢占式:高优先级的加入后立刻打断切换
方案二:“领导原则”动态分配
需要领导原则:决定最终目的——是让CPU一直忙碌 还是 保证公平
1.CPU利用率
2.系统的响应
是保证效率还是保证公正简单》保证效率
只要让CPU随便选一个线程运行就行。
公平的指标:一视同仁
个体指标
最大等待时间:最倒霉的线程要多久才执行他
最大周转时间:最大运行完一个程序的时间(包括等待时间和运行时间)(结果公平)
集体指标
吞吐率:单位时间完成了多少任务
平均等待时间:
平均周转时间:
- 集体公平(平均测度):
- 关注的是平均值(平均等待时间、平均周转时间)。
- 逻辑:只要大家的平均等待时间最短,系统整体效率就最高。
- 个体公平(最大测度):
- 关注的是最惨的那个人(最大等待时间)。
- 逻辑:不管平均值多好,如果有一个任务被饿死了(等待时间无限长),那就是不公平。
正义的指标:合理差异,按需分配
响应时间:用户提出请求到反馈的时间(用户更在意的要先响应,即使当前程序并不公平)
响应比:
Q:如何体现公平正溢?
同时体现对公平和正义的追求,既考虑了所有任务的执行效率,也惩罚了短任务的长时间等待
Q:平均测度与最大测度下的公平含义有什么不同?
平均测度下的公平是集体公平,它更贴切的说法是效率。最大测度下的公平才是程序作为个体期待的公平。
Q:吞吐率衡量的是整体意义上的公平还是个体意义上的公平?
集体意义上的公平,因为单个任务没有吞吐率—说。
Q:平均或最大周转时间和个别任务的响应时间相比有何区别?为何说前者体现了公平 (或效率) ,后者体现的则是正义?
平均和最大周转时间关心—切线程的运行时间,而响应时间仅关心那个用户在意的线程产生的第—个反馈。前者关心所有线程,后者只关心某个线程,仅仅是因为那个线程是用户在等待的。
调度算法
先来先服务:FCFS 公平
特点:先到先得,但要求任务短小且简单。适用于批处理系统
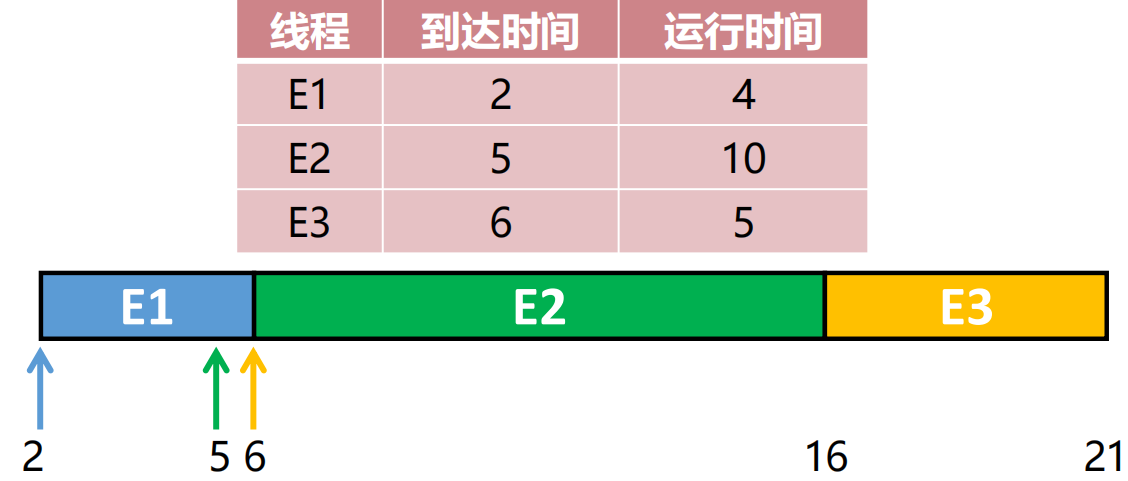
- 优点:简单,绝对公平。
- 缺点:对短任务极不友好。如果一个长任务排前面,后面一堆短任务都得等死。
Q:为什么说FCFS并非任何意义上的公平?
忽略了任务的大小。如果一个只需1秒的任务,因为排在需要1小时的任务后面,它就得等1小时。这对那个1秒的任务来说是极大的不公平(周转时间太长)
短作业优先:SJF 效率
特点:响应性好,适合简单的交互式系统。短任务先完成,让平均周转时间减小。
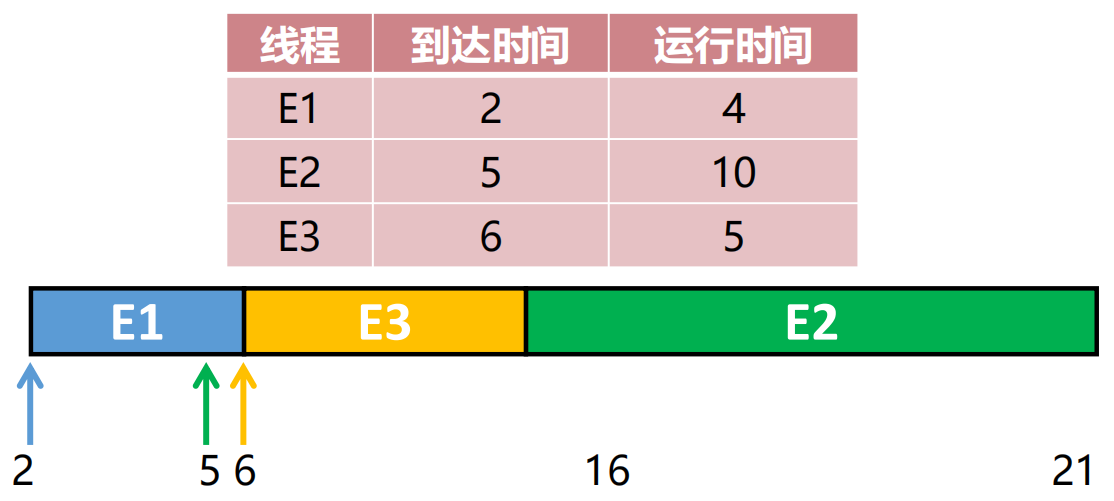
- 优点:平均等待时间最短。系统整体效率最高。
- 缺点:长任务会饿死。如果源源不断有短任务来,长任务永远轮不到。
最高响应比优先算法 HRNN
- 逻辑:响应比 = (等待时间 + 运行时间) / 运行时间。
- 解释:这个公式很妙。
- 等待时间越长,分子越大,优先级越高(照顾老任务,防饿死)。
- 运行时间越短,分母越小,优先级越高(照顾短任务,提效率)。
- 评价:这是FCFS和SJF的完美折中。
在线算法:线程是动态输入的,无法预测会输入什么输入,前面两种算法都是一次性输入完的
饥饿问题: 某些请求无限增加时, 另—些请求永远得不到分配
时间片轮转法 RR
- 逻辑:把CPU时间切片
- 优点:交互性极好。每个人都能在短时间内得到响应,不会觉得卡死。
- 改进版(FPRR):结合固定优先级。重要任务优先级高,先轮转;普通任务优先级低,后轮转。
特点:让所有的线程都获得了执行机会
但是如何划分时间片呢?
太长就变成FCFS流水线了,太短切换开销太大
加权时间片轮转
高优先级的分配更多的时间片,低优先级分配更少的时间片
固定优先级时间片轮转 FPRR
复杂系统的调度
单一的调度算法各有优缺点,如何综合起来
因人而异:不同功能的线程用不同的调度算法,类型不同的线程之间也需要调度算法:
分层置疑:只有上层高优先级的线程为空时,才会向下执行其他线程
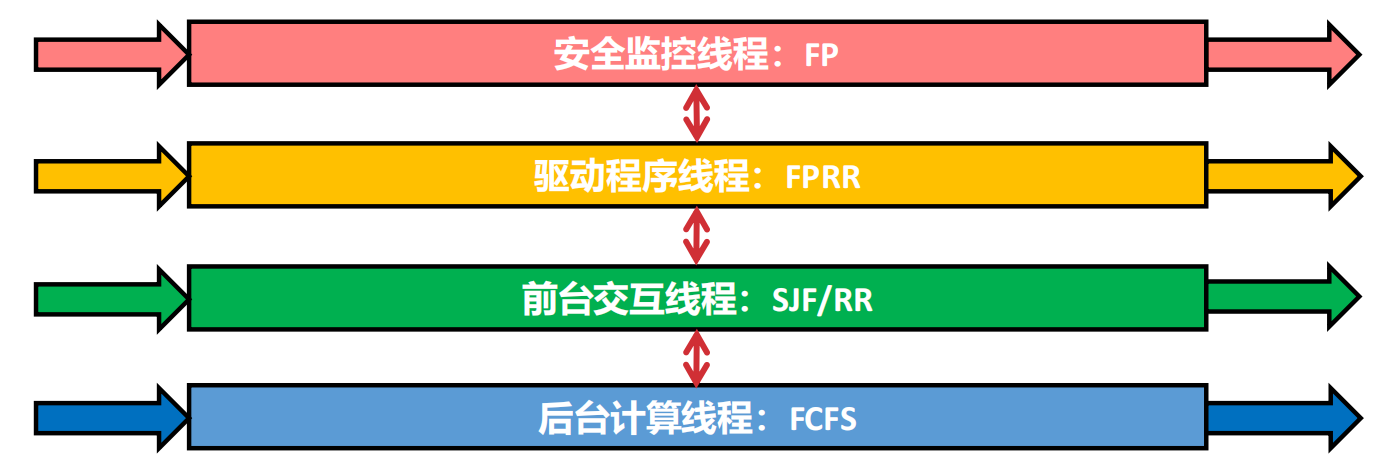
动态调整:同一个线程可能承载不同的指令流,但是在不同的阶段可能发生改变,比如计算完成后的后台计算线程计算完后想弹出交互窗口,就必须升到前台。
多级反馈队列:实时检测每个线程的行为,不合适时为其更换到合适的队列(允许队列迁移)
层次化调度算法:
除了按行为分,还能按什么分?
系统往往由不同的子系统组成的,对CPU的需求不同,且之间不能干扰。
将系统分为子系统,每个子系统都有子调度器,会共有一个父调度器。
时间维度
-
长期调度(进程准入):
- 做什么:用户决定哪些程序有资格“出生”。可执行文件(.exe)加载到虚拟内存中,变成进程。
-
中期调度(内存交换):
- 做什么:当内存不够用时,把暂时不运行的进程“换出”到硬盘
- 核心:这是存储器管理的范畴,解决的是内存紧张的问题。
-
短期调度(CPU抢占):
- 做什么:决定就绪队列里的哪个线程能拿到CPU的时间片。
TLB快表
段表:
每个程序逻辑段到物理段的映射关系组成段表。
工作集合:程序在某时刻前的一段时间内访问的内存的地址集合。两种形式WS(t,T)T是时间窗口 WS(t,Δ)最近Δ次访存
如何在保证地址转换速度极快的同时,又能支持足够大的程序(无限多的段)
最初的尝试——把段表全塞进CPU寄存器
- 优点(快): CPU查寄存器是瞬间完成的,不需要去访问慢吞吞的内存,地址翻译速度极快。
- 缺点(小): CPU里的寄存器太贵了,数量极其有限。这意味着能支持的“段”非常少
妥协的方案——把段表放回内存
- 优点(大): 内存很大,想建多大的段表都行,支持“无限”数量的段。
- 缺点(慢): 速度崩了。每次CPU想访问一个数据,得先去内存查一次段表(拿到基址),再去内存访问那个数据。这相当于每次访存都变成了两次访存
核心转折——利用“局部性原理”
- 逻辑: 程序在运行时,往往只在某一段时间内集中访问某几个段(这就是工作集)。既然CPU当前只关注这一小部分段,我们何必把整个巨大的段表都搬来搬去呢?
- 方案: 我们只需要在CPU里放一个小型的高速缓存,专门存放当前正在使用的那些“活跃段”的描述符。这个小缓存就是——快表(TLB)
地址翻译或TLB查找
- 工作流程:
- CPU要查段表时,先去快表里找。
- 如果找到了(命中): 直接拿走数据,速度飞快(走红色常规路径)。
- 如果没找到(未命中): 再去内存里的段表查,查到了之后顺手把这个数据存进快表,以备下次使用(走蓝色罕见路径)。
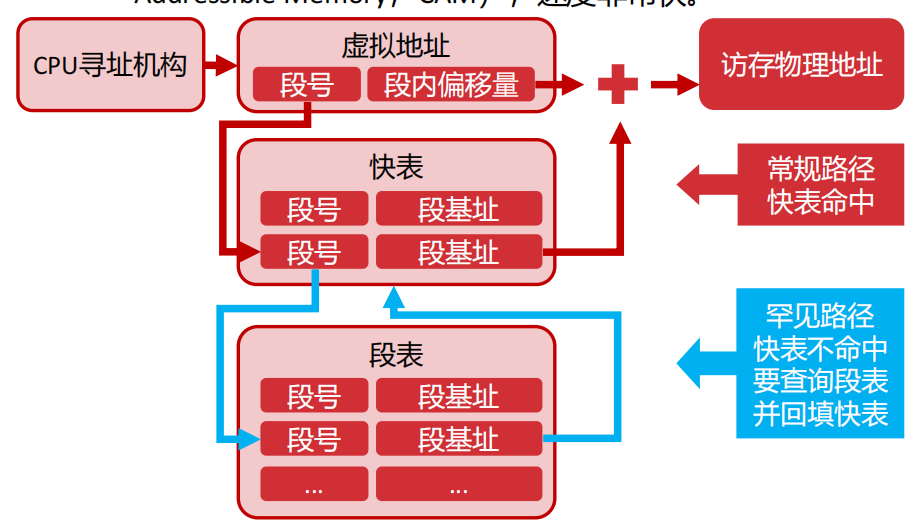
快表没命中怎么办?(填充机制)
-
软件填充(Software Filling):
- 做法: 没命中时,就触发内存管理异常。操作系统截获异常去内存查表,然后手动把数据写进TLB。
- 优缺点: 硬件设计简单、软件格式灵活,但处理异常很消耗CPU时间,比较慢。
-
硬件填充(Hardware Filling / Table Walker):
- 做法: CPU里专门有一个硬件电路(表查找器),发现没命中,它自动去内存把数据抓回来填进TLB,完全不需要操作系统插手。
- 优缺点: 速度极快,性能好,但硬件设计复杂,操作系统失去了对TLB内容的直接控制权
☆ 从“单核”到“多核”——并发与并行的质变
-
并发:
- 定义:逻辑上的同时发生。
- 场景:单核CPU。
- 原理:通过快速切换(时间片轮转),让多个任务交替执行。
- 比喻:一个厨师(CPU)同时炒四个菜,他一会儿炒这个,一会儿炒那个,看起来像是一起熟的,其实是轮流照顾。
-
并行:
- 定义:物理上的同时发生。
- 场景:多核CPU。
- 原理:多个指令流在不同的CPU核心上真正同时执行。
- 比喻:四个厨师(4核CPU),一人拿一个锅,四个菜真正的一起炒。
逻辑关系:并发是抽象概念(逻辑),并行是具体实现(物理)。并行是并发的一种特殊形态。
总结
CPU只能同时处理一个任务,那么哪个线程先执行呢?
调度算法:
固定顺序FP(可打断 不可打断)-动态分配(领导原则:公平、效率、响应)
公平、正义、响应测度(集体公平:吞吐量 平均等待 平均周转,个体公平:最长等待 最长周转,响应:响应时间 响应比)
如何实现动态分配?
先来先服务FCFS 公平
短作业优先SJF 正义
兼顾 公平正义 最高响应比HRNN
饥饿和在线算法?
时间片轮转RR 固定优先级轮转FPRR
加权时间片轮转
复杂调度:系统化 分层化(因人而异 分层置疑 动态调整)
宏观调度:长期(程序准入) 中期(内存交换) 短期(争抢CPU):考查定义
并行(物理上) 并发(逻辑上)概念

openEuler 是由开放原子开源基金会孵化的全场景开源操作系统项目,面向数字基础设施四大核心场景(服务器、云计算、边缘计算、嵌入式),全面支持 ARM、x86、RISC-V、loongArch、PowerPC、SW-64 等多样性计算架构
更多推荐

 4
4 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)