操作系统期末复习--大题常考题型
目录
R8-1 进程调度算法题
在一个单道批处理系统中,一组作业的提交时刻和运行时间如下表所示:
| 作业 | 提交时间 | 执行时间(小时) |
|---|---|---|
| 1 | 8:00 | 1.0 |
| 2 | 8:50 | 0.5 |
| 3 | 9:00 | 0.2 |
| 4 | 9:10 | 0.1 |
试计算以下3种作业调度算法的平均周转时间T和平均带权周转时间W:
(1)先来先服务;(2)短作业优先;(3)响应比高者优先。
知识点:
周转时间:完成时间-提交时间
带权周转时间:周转时间/执行时间
先来先服务:按时间顺序,谁先来,先执行谁
短作业优先:同一情况下执行时间短的优先,有抢占式和非抢占式两种,默认是非抢占式
相应比高者优先:根据相应比大小,相应比高的优先,相应比是动态的。响应比 = 1 + 等待时间 / 执行时间
1:
执行顺序:1 → 2 → 3 → 4
| 作业 | 提交 | 执行 | 开始 | 完成 | 周转时间 T | 带权周转时间 W |
|---|---|---|---|---|---|---|
| 1 | 8:00 | 60 | 8:00 | 9:00 | 60 | 60/60 = 1 |
| 2 | 8:50 | 30 | 9:00 | 9:30 | 40 | 40/30 = 1.33 |
| 3 | 9:00 | 12 | 9:30 | 9:42 | 42 | 42/12 = 3.5 |
| 4 | 9:10 | 6 | 9:42 | 9:48 | 38 | 38/6 = 6.33 |
先分别计算每个作业的周转时间:
作业一:八点提交九点结束,周转时间是60分钟;
作业二:八点五十提交九点半结束,周转时间是40分钟;
作业三:九点提交九点四十二结束,周转时间42分钟;
作业四:九点十分提交九点四十八结束,周转时间38分钟
平均周转时间 T = (60 + 40 + 42 + 38) / 4 = 45 分钟
平均带权周转时间 W = (1 + 1.33 + 3.5 + 6.33) / 4 = 2.54
2:
执行顺序:1 → 3 → 4 → 2
| 作业 | 提交 | 执行 | 开始 | 完成 | 周转时间 T | 带权周转时间 W |
|---|---|---|---|---|---|---|
| 1 | 8:00 | 60 | 8:00 | 9:00 | 60 | 60/60 = 1 |
| 2 | 8:50 | 30 | 9:18 | 9:48 | 58 | 58/30 = 1.93 |
| 3 | 9:00 | 12 | 9:00 | 9:12 | 12 | 12/12 = 1 |
| 4 | 9:10 | 6 | 9:12 | 9:18 | 8 | 8/6 = 1.33 |
本题中八点只有任务一,先执行任务一,任务一结束时间是九点,此时有任务二和任务三,任务三执行时间短,先执行任务三,任务三结束时间是九点十二分,此时有任务二和任务四,因为任务四执行时间小于任务二,所以先执行任务四,然后再执行任务二
平均周转时间 T = (60 + 58 + 12 + 8) / 4 = 34.5 分钟
平均带权周转时间 W = (1 + 1.93 + 1 + 1.33) / 4 = 1.32
3:
8:00 只有作业1 → 执行作业1(到9:00)
9:00 计算响应比(等待时间 = 当前时间 − 提交时间):
| 作业 | 提交 | 等待时间 | 执行时间 | 响应比 |
|---|---|---|---|---|
| 2 | 8:50 | 10 分钟 | 30 | 1 + 10/30 = 1.33 |
| 3 | 9:00 | 0 分钟 | 12 | 1 + 0/12 = 1 |
→ 作业2先执行(9:00~9:30)
9:30 计算响应比:
| 作业 | 提交 | 等待时间 | 执行时间 | 响应比 |
|---|---|---|---|---|
| 3 | 9:00 | 30 分钟 | 12 | 1 + 30/12 = 3.5 |
| 4 | 9:10 | 20 分钟 | 6 | 1 + 20/6 = 4.33 |
→ 作业4先执行(9:30~9:36)
9:36 只剩作业3 → 执行作业3(9:36~9:48)
执行顺序:1 → 2 → 4 → 3
| 作业 | 提交 | 执行 | 开始 | 完成 | 周转时间 T | 带权周转时间 W |
|---|---|---|---|---|---|---|
| 1 | 8:00 | 60 | 8:00 | 9:00 | 60 | 60/60 = 1 |
| 2 | 8:50 | 30 | 9:00 | 9:30 | 40 | 40/30 = 1.33 |
| 3 | 9:00 | 12 | 9:36 | 9:48 | 48 | 48/12 = 4 |
| 4 | 9:10 | 6 | 9:30 | 9:36 | 26 | 26/6 = 4.33 |
平均周转时间 T = (60 + 40 + 48 + 26) / 4 = 43.5 分钟
平均带权周转时间 W = (1 + 1.33 + 4 + 4.33) / 4 = 2.67
R8-2 进程同步题
内存中有一组缓冲区被多个生产者进程.多个消费者进程共享使用,总共能存放10个数据,生产者进程把生成的数据放入缓冲区,消费者进程从缓冲区中取出数据使用。
缓冲区满时生产者进程就停止将数据放入缓冲区,缓冲区空时消费者进程停止取数据。数据的存入和取出不能同时进行,试用信号量及P.V操作来实现该方案。
知识点:
P操作是申请资源,--
V操作是释放资源,++
P 操作(进入临界区)—— 先资源,后锁
P(empty); // ① 先申请空闲位置(资源) P(mutex); // ② 再拿互斥锁
为什么要先申请资源再拿锁?
→ 防止占着锁不放,导致死锁。如果你先拿锁再资源,如果此时资源不够,就会陷入等待,而又因为你拿着锁,另一方无法释放资源,导致一直等待下去陷入死锁。
V 操作(离开临界区)—— 先解锁,后释放资源
V(mutex); // ① 先释放互斥锁 V(full); // ② 再释放资源(告诉别人有数据了)
为什么要先解锁再释放资源?
→ 尽量早地把锁让出来,让其他进程能进去操作,提高效率。注意此时V操作是不会陷入等待的,因为上面进行P操作时就相当于也判断是否满足V操作了,如果V操作不满足,P也绝不会满足,在P操作时就已经陷入等待,不会拿锁,这和P操作先资源后锁有点不同
用信号量+PV操作来解决:
设三个信号量:
1:互斥信号量mutex,保证取和放两个操作互斥
2:空闲位置信号量empty,缓冲区有多少空闲位置,对于放数据的一方来说如果empty<=0,则进入等待
3:现存多少信号量full,缓冲区现在有多少数据,对于取数据的一方来说如果full<=0,则进入等待
semaphore mutex = 1; // 互斥访问缓冲区(放和拿不能同时)
semaphore empty = 10; // 空闲位置数,初值10
semaphore full = 0; // 已有数据数,初值0
// ========== 生产者进程 ==========
void Producer() {
while (1) {
生产一个数据 product;
P(empty); // 申请一个空闲位置(缓冲区是否有空位)
P(mutex); // 互斥进入临界区(拿操作牌)
把 product 放入缓冲区;
V(mutex); // 释放互斥锁(还操作牌)
V(full); // 数据数量+1,通知消费者
}
}
// ========== 消费者进程 ==========
void Consumer() {
while (1) {
P(full); // 申请一个数据(缓冲区是否有数据可取)
P(mutex); // 互斥进入临界区(拿操作牌)
从缓冲区取出数据 data;
V(mutex); // 释放互斥锁(还操作牌)
V(empty); // 空闲位置+1,通知生产者
消费 data;
}
}同步关系:
-
生产者通过
empty和full与消费者同步 -
生产者用
P(empty)等待空闲位置,用V(full)通知消费者 -
消费者用
P(full)等待数据,用V(empty)通知生产者 -
mutex保证对缓冲区的互斥访问
R8-3 银行家算法题目
用银行家算法避免系统死锁:
当前系统资源总量为A类6个.B类3个.C类个4.D类2个,资源分配情况如表所示
(1)系统是否安全?请分析说明理由。
(2)若进程P2请求(0,0,1,0),可否立即分配?请分析说明理由。
| 进程 | 已分配资源 | 最大需求资源 |
|---|---|---|
| A B C D | A B C D | |
| P1 | 3 0 1 1 | 4 1 1 1 |
| P2 | 0 1 0 0 | 0 2 1 2 |
| P3 | 1 1 1 0 | 4 2 1 0 |
| P4 | 1 1 0 1 | 1 1 1 1 |
| P5 | 0 0 0 0 | 2 1 1 0 |
知识点:银行家算法
银行家算法的核心就是每次借给别人钱时都先判断一下把钱借给他之后我会不会破产(这里假设如果我把借钱人所需要的钱都借给他了,那他会立即把全部钱都换回来)
银行家算法需要维护四个数据结构,分别是
1:当前所剩资源总量Available
2:当前进程所需最大资源量Max
3:当前进程已给资源量Allocation
4:当前进程还需多少资源量Need,很明显Need=Max-Allocation
银行家算法步骤:
当pi请求资源时
1.首先先判断当前请求是否超过Need(你要10块就够用了,但你却申请了10万)
2.其次再判断当前所剩资源能否满足他的需求Need(看看我剩的钱够给你的吗)
3.然后如果满足再假装分配给他
Available = Available - Request//更新所剩资源
Allocation[i] = Allocation[i] + Request//更新已给资源
Need[i] = Need[i] - Request//更新仍需资源
4.执行安全性检查
安全性检查:
维护一个新数据结构work,work是动态变化的。再维护一个状态数组,这个数组存的是每个资源的状态(是否已经满足所需资源,不满足标记为false,满足标记为true)
对与每一个false,先判断work是否大于等于对应的need,如果大于等于则代表可以给他分配资源,false变成true,分配完资源后会立即回收他的全部资源(已满足要求,无需再继续占用),然后一直重复这个步骤,直到所有false都变成true,此时就找到了一个安全序列(分配资源的顺序),也就代表安全性检查通过,可以分配资源,否则不通过,撤销之前的假装分配。
银行家算法关键:
Available 是真实的钱;Work 是纸上推演的钱。先用 Work 推演未来是否安全,安全了才真正动 Available 的钱。满足请求 ≠ 一定能分,安全才能分。
题解:
1:这不能完整使用之前的银行家算法步骤判断,题目问的是当前系统是否安全,不是说给你一个新的请求,然后再问你是否安全。可以当成此时已经假装到达了银行家算法的第4步,已经假装分配完开始要执行安全性检查了。
在当前状态下是可以找到安全序列的,故而安全。
具体步骤,先计算分配完后abcd还剩多少,计算得到还剩1020,此时可以先执行4,此时abcd变成了2121,此时可以执行1或者5,假设执行1,abcd变成了5132,往后同理寻找,可以找到多条安全序列,41235是其中一条。
2:第二问就是需要完整进行银行家算法了,因为他先给了你一个请求,问你能不能分配,也就是问你分配了安不安全。
从第一步开始,判断他贪了吗?
然后第二步,现有的能不能满足他
第三步假装分配
第四步执行安全性检查发现可以找到安全序列,所以可以直接分配
注意:安全性检查要检查“系统中所有进程”,包括刚刚请求资源的 P2(p2的need会改变这需要注意一下)。因为安全检查是在找“一个全局的执行顺序”,而不是只检查“还没请求过的进程”。
R8-1 分页虚拟存储器
在一个分页虚拟存储管理系统中,用户编程空间32个页,页长1KB,内存为16KB。如果用户程序有10页长,若己知虚页0.1.2.3,已分到页框8.7.4.10 ,请将虚地址0AC5H和1AC5H转换成对应的物理地址。
知识点:
编程空间是理论上可以容纳的最大空间,但是因为内存可能比编程空间小,故而会有虚页分配,一部分放在内存,一部分放在外存,本题编程空间是32页也就代表虚页是从0~32,但是内存只有16KB,也就是只有16个页框
页长是每一页的大小,1KB=1024B=B,所以虚地址的低10位是页内偏移量
内存是16KB也就意味着内存最多存16页,剩下的页都在外存
用户程序有十页,代表他只占用了编程空间的10页,占用了虚页的0~9
虚页分配指的是:程序的哪些虚页已经被加载到内存的哪些页框里。
本题题目说:己知虚页0.1.2.3,已分到页框8.7.4.10,也就意味着虚页0~3在内存中,4~9还在外存
此时就有可能产生缺页中断,虚页还没有加载到内存却调用了,就会产生缺页中断。
内存是真实的物理存储空间,大小固定。
-
本题中:内存 = 16KB = 16 个页框(页框 0~15)
-
页框是内存中真正存放数据的地方
物理地址 = 页框号 × 页长 + 页内偏移
第(1)题:虚地址 0AC5H
第一步:把十六进制转成二进制
0AC5H 是一个十六进制数,一共 4 位十六进制 = 16 位二进制
0AC5H = 0000 1010 1100 0101B
第二步:拆分成“页号 + 页内偏移”
因为页长 1KB = 2¹⁰,所以低 10 位是页内偏移,高 6 位是页号(因为编程空间 32 页 = 2⁵,但地址 16 位中页号占 6 位)
0AC5H 用 16 位二进制写:
0000 10 | 10 1100 0101
高 6 位(红色)= 000010B = 2(虚页号)
低 10 位(蓝色)= 10 1100 0101B = 2C5H(页内偏移)
虚页号 = 2
第三步:查页表,找到对应的页框号
虚页号 2 → 页框号 4
第四步:计算物理地址
物理地址 = 页框号 × 1024 + 页内偏移
= 4 × 1024 + 2C5H
= 1000H + 2C5H
= 12C5H
答:虚地址 0AC5H 对应的物理地址是 12C5H
第(2)题:虚地址 1AC5H
第一步:转二进制
1AC5H = 0001 1010 1100 0101B
第二步:拆分
0001 10 | 10 1100 0101
高 6 位 = 000110B = 6(虚页号)
低 10 位 = 10 1100 0101B = 2C5H(页内偏移)
虚页号 = 6
第三步:查页表
页表中只给出了虚页 0、1、2、3 对应的页框号。
虚页 6 没有分配页框(程序只有 10 页,但只有前 4 页在内存中)。
虚页 6 不在内存中 → 产生缺页中断,系统会从外存把它调入内存。
答:虚地址 1AC5H 产生缺页中断,无法直接转换物理地址
R8-2 页面置换算法
请求分页系统中,设某进程共有9个页,分配给该进程的内存块数为5,进程运行时,实际访问页面的次序是0,1,2,3,4,5,0,2,1,8,5,2,7,6,0,1,2。
(1)采用FIFO页面置换算法,列出其页面置换次序和缺页中断次数,以及最后留驻内存的页号顺序。
(2)采用LRU页面置换算法,列出其页面置换次序和缺页中断次数,以及最后留驻内存的页号顺序。
1. 什么是页面置换?
想象你有一个只有 5 个口袋的背包(内存块数 = 5),但你有一本很多页的书(进程有 9 个页)。
你一次只能带 5 页在背包里,当需要看第 6 页时,必须扔掉背包里的一页,把新的一页放进去。
扔掉哪一页? 这就是页面置换算法要决定的事情。
2. 三个关键概念
| 概念 | 含义 |
|---|---|
| 缺页中断 | 要访问的页面不在内存里,需要从外存调入 |
| 页面置换 | 内存满了,必须淘汰一个页面,腾出空间给新页面 |
| 置换次序 | 每次发生置换时,被淘汰的页面号(按顺序记录) |
3. 两种算法的核心区别
| 算法 | 淘汰策略 | 通俗理解 |
|---|---|---|
| FIFO(先进先出) | 淘汰最早进入内存的页面 | “谁先来,谁先走” |
| LRU(最近最久未使用) | 淘汰最长时间没有被访问的页面 | “谁很久没被看了,谁先走” |
(1)FIFO 页面置换算法
算法规则
淘汰最早进入内存的那个页面。
逐步推演
| 步骤 | 访问页 | 内存状态(5个块) | 是否缺页 | 置换的页 |
|---|---|---|---|---|
| 1 | 0 | 0, -, -, -, - | ✅ 缺页 | 无(未满) |
| 2 | 1 | 0, 1, -, -, - | ✅ 缺页 | 无(未满) |
| 3 | 2 | 0, 1, 2, -, - | ✅ 缺页 | 无(未满) |
| 4 | 3 | 0, 1, 2, 3, - | ✅ 缺页 | 无(未满) |
| 5 | 4 | 0, 1, 2, 3, 4 | ✅ 缺页 | 无(刚好满) |
| 6 | 5 | 1, 2, 3, 4, 5 | ✅ 缺页 | 淘汰 0 |
| 7 | 0 | 2, 3, 4, 5, 0 | ✅ 缺页 | 淘汰 1 |
| 8 | 2 | 2, 3, 4, 5, 0 | ❌ 命中 | 无 |
| 9 | 1 | 3, 4, 5, 0, 1 | ✅ 缺页 | 淘汰 2 |
| 10 | 8 | 4, 5, 0, 1, 8 | ✅ 缺页 | 淘汰 3 |
| 11 | 5 | 4, 5, 0, 1, 8 | ❌ 命中 | 无 |
| 12 | 2 | 5, 0, 1, 8, 2 | ✅ 缺页 | 淘汰 4 |
| 13 | 7 | 0, 1, 8, 2, 7 | ✅ 缺页 | 淘汰 5 |
| 14 | 6 | 1, 8, 2, 7, 6 | ✅ 缺页 | 淘汰 0 |
| 15 | 0 | 8, 2, 7, 6, 0 | ✅ 缺页 | 淘汰 1 |
| 16 | 1 | 2, 7, 6, 0, 1 | ✅ 缺页 | 淘汰 8 |
| 17 | 2 | 2, 7, 6, 0, 1 | ❌ 命中 | 无 |
结果汇总
| 项目 | 结果 |
|---|---|
| 缺页中断次数 | 14 次(第 1~5 次是“装入”,第 6~17 次是“置换”) |
| 置换次序 | 0 → 1 → 2 → 3 → 4 → 5 → 0 → 1 → 8 |
| 最后留驻内存的页号 | 2, 7, 6, 0, 1(从老到新) |
(2)LRU 页面置换算法
逐步推演
最近访问的放在最左边
| 步骤 | 访问页 | LRU 内存状态(左=最近,右=最久) | 缺页? | 置换页 |
|---|---|---|---|---|
| 1 | 0 | [0] | ✅ | — |
| 2 | 1 | [1, 0] | ✅ | — |
| 3 | 2 | [2, 1, 0] | ✅ | — |
| 4 | 3 | [3, 2, 1, 0] | ✅ | — |
| 5 | 4 | [4, 3, 2, 1, 0] | ✅ | — |
| 6 | 5 | [5, 4, 3, 2, 1] | ✅ | 淘汰 0 |
| 7 | 0 | [0, 5, 4, 3, 2] | ✅ | 淘汰 1 |
| 8 | 2 | [2, 0, 5, 4, 3] | ❌ 命中 | — |
| 9 | 1 | [1, 2, 0, 5, 4] | ✅ | 淘汰 3 |
| 10 | 8 | [8, 1, 2, 0, 5] | ✅ | 淘汰 4 |
| 11 | 5 | [5, 8, 1, 2, 0] | ❌ 命中 | — |
| 12 | 2 | [2, 5, 8, 1, 0] | ❌ 命中 | — |
| 13 | 7 | [7, 2, 5, 8, 1] | ✅ | 淘汰 0 |
| 14 | 6 | [6, 7, 2, 5, 8] | ✅ | 淘汰 1 |
| 15 | 0 | [0, 6, 7, 2, 5] | ✅ | 淘汰 8 |
| 16 | 1 | [1, 0, 6, 7, 2] | ✅ | 淘汰 5 |
| 17 | 2 | [2, 1, 0, 6, 7] | ❌ 命中 | — |
📊 最终结果(标准 LRU 写法)
| 项目 | 结果 |
|---|---|
| 缺页中断次数 | 14 次 |
| 置换次序 | 0 → 1 → 3 → 4 → 0 → 1 → 8 → 5 |
| 最后留驻内存的页号(从最近到最久) | [2, 1, 0, 6, 7] |
R8-3 分页管理综合题
设某计算机的逻辑地址空间和物理地址空间均为64KB,按字节编址。某进程最多需要6页数据存储空间,页的大小为1KB,操作系统为此进程固定分配了4个页框(页框号分别为7.4.2.9),页面的当前分配情况如下所示:

当该进程执行到时刻260时,要访问逻辑地址为17CAH的数据。
(1)该逻辑地址对应的逻辑页号是多少?
(2) 若采用先进先出(FIFO)页面置换算法,求发生页面置换后,该逻辑地址对应的物理地址?要求给出计算过程。
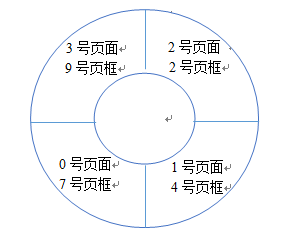
(3)若采用时钟(Clock)页面置换算法,该逻辑地址对应的物理地址是多少?要求给出计算过程。(设搜索下一页的指针按顺时针方向移动,且当前指向当前2号页框,示意图如下所示)
知识点:
逻辑地址空间就相当于上一题中的编程空间
物理地址空间就是内存
页的大小是1KB=1024B=B,所以低十位是偏移量
物理地址=页框号*页长+页内偏移
时钟页面置换算法:按扫描顺序,对于每一个指向的页,如果他的访问位是1那么给他一次机会先不淘汰他,但是会把他的访问位变成0;如果他的访问位是0,那么直接淘汰
-
检查当前指针指向的页
-
如果访问位 = 1 → 置为 0,指针移向下一个
-
如果访问位 = 0 → 淘汰这一页
-
如果转了一圈全是 1 → 全部置 0,再从第一页开始淘汰
第一题:
先转换为二进制0001011111001010低十位是偏移量为1111001011,高六位是页号000101转为十进制是5,所以逻辑页号是5
第二题:
逻辑页号5此时并没有分配到内存里,所以涉及到了页面置换,若采用FIFO则最先到达的先剔除掉,根据表格是页面0被替换,此时页面5分配页框7
所以物理地址=7*1024+3CAH=8138
第三题:
本题根据题目条件淘汰的是页面2
物理地址 = 2 × 1024 + 3CAH
= 800H + 3CAH
= BCAH
R8-1 磁盘调度
假设一个磁盘驱动器有 2000 个柱面,编号从 0 到 1999。
该磁盘当前正在为 143 号柱面的请求提供服务,并且前一个请求是在 125 号柱面。
等待队列中的请求是:
86, 1470, 913, 1774, 948, 1509, 1022, 1750, 130
从当前磁头位置开始,对于以下每种磁盘调度算法(FCFS、SSTF、SCAN 和 C-LOOK),请计算磁头移动的「总距离(以柱面数计)」和「服务顺序(序列)」,以满足所有等待中的请求。
| 算法 | 一句话规则 |
|---|---|
| FCFS | 谁先来,谁先被服务 |
| SSTF | 每次都去离当前磁头最近的请求 |
| SCAN | 磁头先往一个方向走到底,再掉头(像电梯) |
| C-LOOK | 磁头只往一个方向走,走到最远请求后直接跳回最近请求 |
(1)FCFS(先来先服务)
规则:按请求到达的顺序,一个一个服务。
顺序:86 → 1470 → 913 → 1774 → 948 → 1509 → 1022 → 1750 → 130
移动距离计算:
| 移动 | 距离 |
|---|---|
| 143 → 86 | 57 |
| 86 → 1470 | 1384 |
| 1470 → 913 | 557 |
| 913 → 1774 | 861 |
| 1774 → 948 | 826 |
| 948 → 1509 | 561 |
| 1509 → 1022 | 487 |
| 1022 → 1750 | 728 |
| 1750 → 130 | 1620 |
总距离 = 57 + 1384 + 557 + 861 + 826 + 561 + 487 + 728 + 1620 = 7081
✅ FCFS 结果:序列 86→1470→913→1774→948→1509→1022→1750→130,总距离 7081
(2)SSTF(最短寻道时间优先)
规则:每次都去离当前磁头最近的那个请求。
推演过程:
| 步骤 | 当前磁头 | 请求队列 | 最近的请求 | 距离 |
|---|---|---|---|---|
| 1 | 143 | 86,1470,913,1774,948,1509,1022,1750,130 | 130(差13) | 13 |
| 2 | 130 | 86,1470,913,1774,948,1509,1022,1750 | 86(差44) | 44 |
| 3 | 86 | 1470,913,1774,948,1509,1022,1750 | 913(差827) | 827 |
| 4 | 913 | 1470,1774,948,1509,1022,1750 | 948(差35) | 35 |
| 5 | 948 | 1470,1774,1509,1022,1750 | 1022(差74) | 74 |
| 6 | 1022 | 1470,1774,1509,1750 | 1470(差448) | 448 |
| 7 | 1470 | 1774,1509,1750 | 1509(差39) | 39 |
| 8 | 1509 | 1774,1750 | 1750(差241) | 241 |
| 9 | 1750 | 1774 | 1774(差24) | 24 |
顺序:130 → 86 → 913 → 948 → 1022 → 1470 → 1509 → 1750 → 1774
总距离 = 13 + 44 + 827 + 35 + 74 + 448 + 39 + 241 + 24 = 1745
✅ SSTF 结果:序列 130→86→913→948→1022→1470→1509→1750→1774,总距离 1745
(3)SCAN(电梯算法)
规则:磁头朝一个方向移动,沿途服务所有请求,直到最远端,再反向移动。
方向判断:上次请求 125 < 当前 143 → 磁头正在向柱面号增大的方向移动。
步骤:
-
从 143 向大方向移动,服务所有 >= 143 的请求:
-
913, 948, 1022, 1470, 1509, 1750, 1774
-
-
到达最大请求 1774 后,反向(向小方向)
-
向小方向移动,服务剩余请求:
-
130, 86
-
顺序:913 → 948 → 1022 → 1470 → 1509 → 1750 → 1774 → 130 → 86
移动距离计算:
| 移动 | 距离 |
|---|---|
| 143 → 913 | 770 |
| 913 → 948 | 35 |
| 948 → 1022 | 74 |
| 1022 → 1470 | 448 |
| 1470 → 1509 | 39 |
| 1509 → 1750 | 241 |
| 1750 → 1774 | 24 |
| 1774 → 130 | 1644 |
| 130 → 86 | 44 |
总距离 = 770 + 35 + 74 + 448 + 39 + 241 + 24 + 1644 + 44 = 3319
✅ SCAN 结果:序列 913→948→1022→1470→1509→1750→1774→130→86,总距离 3319
(4)C-LOOK(循环LOOK)
规则:磁头只朝一个方向移动,服务完最大请求后,直接跳回最小请求,继续服务,不反向移动。
步骤:
-
从 143 向大方向移动,服务所有 >= 143 的请求:
-
913, 948, 1022, 1470, 1509, 1750, 1774
-
-
到达 1774(最大请求)后,跳回最小的请求 86
-
继续服务剩余请求:86, 130
顺序:913 → 948 → 1022 → 1470 → 1509 → 1750 → 1774 → 86 → 130
移动距离计算:
| 移动 | 距离 |
|---|---|
| 143 → 913 | 770 |
| 913 → 948 | 35 |
| 948 → 1022 | 74 |
| 1022 → 1470 | 448 |
| 1470 → 1509 | 39 |
| 1509 → 1750 | 241 |
| 1750 → 1774 | 24 |
| 1774 → 86 | 1688(直接跳回,不计实际移动?还是计?) |
⚠️ 关键问题:C-LOOK 的“跳回”算不算移动距离?
答:通常是不计的
R8-2 外存空闲空间管理
一块硬盘有 500 个柱面,每个柱面有 10 个磁头(即 10 个盘面/磁道),每个磁道有 32 个扇区。
假定磁盘空间分配以 一个扇区 为基本单位。
(1)如果使用位示图(bitmap)来管理所有磁盘空间,位示图需要占用多少字节?
(2)如果根目录中每个目录项占 5 个字节,且根目录的大小与位示图的大小相同,那么根目录最多可以存放多少个目录项?
知识点:
扇区是最小的单位,使用位示图记录每个扇区的状态
-
每个扇区对应地图上的一个小格子
-
格子填 1 = 这个扇区已被占用
-
格子填 0 = 这个扇区是空闲的
第一题:
首先先计算一共有多少个扇区:500*10*32=160000个扇区
也就是160000位,再除以8变成字节
位示图大小 = 160,000 ÷ 8 = 20,000 字节
第二题:
20000/5=4000
R8-1 文件索引计算
假设某文件系统中磁盘物理块大小为4KB,每个物理块号占4个字节,在两级索引结构中,允许的最大文件长度是多少?
知识点:
二级索引就类似有两个目录表,其中一个目录表中的每一条目录都指向另一个目录表,先通过二级索引块找到要找的一级索引块,再在一级索引块中找到具体数据
文件 → 二级索引块 → 一级索引块 → 数据块
在本题中,每个索引块能放4*1024/4=1024个块号,每个块号都是一个地址,指向具体数据,所以能放多少个块号也就相当于能放多少个数据块
采用二级索引能放1024*1024=个块号
每个数据块4KB,4KB*=
KB=4GB
所以允许的最大文件长度是4GB
R8-2 文件组织方式
在UNIX系统中,当一个文件的规模分别如下3种情况时,其物理文件如何组织?
(a)不超过10块;(b)在11~256块之间;(c)超过256块
知识点:
在UNIX系统中有一个 inode(索引节点),里面有10行是直接块,可以直接放10个数据块,还有一个一级间接块和二级间接块,一级间接块里面写的是直接块地址,二级间接块写的一级索引块的地址,可以简单理解成一级索引块是个目录,二级索引块是目录的目录。
形象化讲解:
想象你开了一家迷你仓库租赁公司(UNIX 文件系统),每个客户租一个小隔间(文件)。
你的前台有一本登记簿(inode,索引节点),用来记录每个客户租了哪几个隔间(数据块)。
这本登记簿上,只有 10 行空位可以写隔间编号。
情况一:客户只租了 1~10 个隔间
你直接在登记簿上写:
| 行号 | 隔间编号 |
|---|---|
| 1 | 101 |
| 2 | 102 |
| ... | ... |
| 10 | 110 |
✅ 10 行够用,直接写完。
情况二:客户租了 11~266 个隔间
10 行写不下了,怎么办?
你拿出一张新纸(一级间接块),这张纸上能写 256 个隔间编号。
然后你在登记簿的第 11 行写上:
“这张新纸放在 201 号柜子里”
以后要找第 11 个及以后的隔间,就先去 201 号柜子拿那张纸,再看纸上写的编号。
✅ 10 行 + 1 张新纸,可以管 10 + 256 = 266 个隔间。
情况三:客户租了超过 266 个隔间
一张新纸也不够用了(一张纸只能写 256 个)。
你再拿出一张更大的纸(二级间接块),这张纸上写的是 “每张分纸放在哪个柜子”。
然后在登记簿的第 12 行写上:
“这张大纸放在 202 号柜子里”
要找更多隔间时:
-
先去 202 号柜子拿大纸
-
大纸上写:分纸1在 301 号柜子,分纸2在 302 号柜子……
-
再去对应的柜子拿分纸
-
分纸上写隔间编号
✅ 10 行 + 1 张新纸 + 1 张大纸,可以管 10 + 256 + 256×256 = 65,802 个隔间
(a)不超过 10 块
文件很小,10 个直接块完全够用。
组织方式:只用 10 个直接块
📌 画个图:
inode ├── 直接块 0 → 数据块 0 ├── 直接块 1 → 数据块 1 ├── ... └── 直接块 9 → 数据块 9
(b)在 11~256 块之间
文件稍大,10 个直接块不够了,需要一级间接块来帮忙。
-
10 个直接块:存前 10 块
-
1 个一级间接块:存剩下的块号(最多 256 个)
组织方式:10 个直接块 + 1 个一级间接块
📌 画个图:
inode
├── 直接块 0 → 数据块 0
├── 直接块 1 → 数据块 1
├── ...
├── 直接块 9 → 数据块 9
└── 一级间接块 → 索引块(存放 256 个数据块号)
│
├── 数据块 10
├── 数据块 11
└── ...
最多支持的块数 = 10 + 256 = 266 块
(c)超过 256 块
文件很大,需要二级间接块。
-
10 个直接块:存前 10 块
-
1 个一级间接块:存接下来的 256 块
-
1 个二级间接块:指向 256 个一级索引块,每个一级索引块再指向 256 个数据块
组织方式:10 个直接块 + 1 个一级间接块 + 1 个二级间接块
📌 画个图:
inode
├── 直接块 0~9(10个)
├── 一级间接块 → 256 个数据块
└── 二级间接块 → 一级索引块 0 → 256 个数据块
一级索引块 1 → 256 个数据块
...
一级索引块 255 → 256 个数据块
最多支持的块数 = 10 + 256 + 256×256 = 10 + 256 + 65,536 = 65,802 块
| 题目 | 答案 |
|---|---|
| (a)不超过10块 | 10 个直接块 |
| (b)在11~256块之间 | 10 个直接块 + 1 个一级间接块 |
| (c)超过256块 | 10 个直接块 + 1 个一级间接块 + 1 个二级间接块 |
R8-3 位示图计算题
设某系统磁盘共有500块,块号从0~499,若用位示图法管理这500块的盘空间,当字长为32位时:
(1)位示图需要多少个字?
(2)第i字第j位对应的块号是多少?
知识点形象化讲解:
想象你是一个停车场的管理员,停车场有 500 个车位(磁盘块),每个车位要么停了车(已占用),要么空着(空闲)。
你需要一张记录表来标记每个车位的状态,方便随时查看哪个车位是空的。
你决定:
-
用 1 表示“有车”(已占用)
-
用 0 表示“空着”(空闲)
如果每个车位用 1 个数字(0 或 1)来记录,500 个车位就要写 500 个数字。
但这样太占地方了!你发现:
-
1 个数字(0 或 1)只需要 1 个 bit
-
8 个 bit 才能凑成 1 个字节
-
32 个 bit 凑成 1 个“字”(word)
所以你的记录表,实际上是一连串的 0 和 1,每 32 个分成一组(一组就是一个字)。
🧱 先搞清楚:什么是“位示图”?
定义
位示图(Bitmap) 是一种用二进制位来记录磁盘块使用情况的数据结构。
-
每一位(bit)对应一个磁盘块
-
位 = 1 → 该块已被占用
-
位 = 0 → 该块空闲
为什么要用位示图?
| 方式 | 优点 | 缺点 |
|---|---|---|
| 位示图 | 占用空间小,查找快 | 需要额外空间存储 |
| 空闲链表 | 不需要额外空间 | 查找慢,链表长 |
位示图的本质
位示图就是一张“地图”,用最少的空间记录所有块的状态。
text
位示图(一共500位): 0 1 2 3 4 5 6 7 ... 499 1 0 1 1 0 0 1 0 ... 0 ↑ ↑ ↑ ↑ ↑ ↑ ↑ ↑ ↑ 块0 块1 块2 块3 块4 块5 块6 块7 块499
📝 第(1)问:位示图需要多少个字?
已知条件
| 项目 | 数值 |
|---|---|
| 磁盘总块数 | 500 块 |
| 每个字有多少位 | 32 位 |
计算过程
每个字 = 32 位 → 每个字能管 32 个磁盘块。
需要的字数 = 总块数 ÷ 每个字的位数
= 500 ÷ 32 = 15.625
不能有“半个字”,所以必须向上取整(因为即使只有 1 位,也要占用整个字的空间)。
500 ÷ 32 = 15.625 → 16 个字
验算
-
16 个字 × 32 位 = 512 位
-
500 块需要 500 位
-
16 个字共 512 位,足够覆盖 500 块,还剩 12 位空闲(不用管)
✅ 答案:位示图需要 16 个字
📝 第(2)问:第 i 字第 j 位对应的块号是多少?
先理解“第 i 字第 j 位”是什么意思
位示图可以看成一个二维表格:
第0位 第1位 第2位 第3位 ... 第31位 第0字 0 1 2 3 ... 31 第1字 32 33 34 35 ... 63 第2字 64 65 66 67 ... 95 第3字 96 97 98 99 ... 127 ...
-
第 i 字 = 第 i 行(从 0 开始)
-
第 j 位 = 第 j 列(从 0 开始)
-
每个字有 32 位 = 每行有 32 列
找规律
看表格:
-
第 0 字:块号 0 ~ 31
-
第 1 字:块号 32 ~ 63
-
第 2 字:块号 64 ~ 95
规律:第 i 字从 i × 32 号块开始,第 j 位就是 i × 32 + j
公式推导
-
第 0 字 第 0 位 → 0 × 32 + 0 = 0 ✅
-
第 0 字 第 31 位 → 0 × 32 + 31 = 31 ✅
-
第 1 字 第 0 位 → 1 × 32 + 0 = 32 ✅
-
第 1 字 第 15 位 → 1 × 32 + 15 = 47 ✅
-
第 15 字 第 15 位 → 15 × 32 + 15 = 495 ✅(小于 499)
特殊情况
如果块号从 1 开始(而不是从 0 开始),公式会变成:
块号 = i × 32 + j + 1
但本题明确说“块号从 0~499”,所以块号从 0 开始,公式是:
块号 = i × 32 + j
✅ 答案:块号 = i × 32 + j

openEuler 是由开放原子开源基金会孵化的全场景开源操作系统项目,面向数字基础设施四大核心场景(服务器、云计算、边缘计算、嵌入式),全面支持 ARM、x86、RISC-V、loongArch、PowerPC、SW-64 等多样性计算架构
更多推荐

 5
5 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)