操作系统 第八章 互斥与同步
互斥关注的是同一时间只有一个执行单元能访问共享资源;同步关注的是“先后次序”。
互斥就是厕所只能一个人上。
同步关注的是上完厕所,吸粪车才能来处理。
我们讨论应用程序之间的关系,应该以应用程序、进程、线程还是指令流为基本单位来讨论呢?
指令流是最基本的行为体,它代表了应用程序中的一个最细分的角色。因此,考虑程序之间的关系,应该从考虑指令流之间的关系开始。
指令流间的关系
合作 竞争 无关
指令流间的关系:Poset偏序集
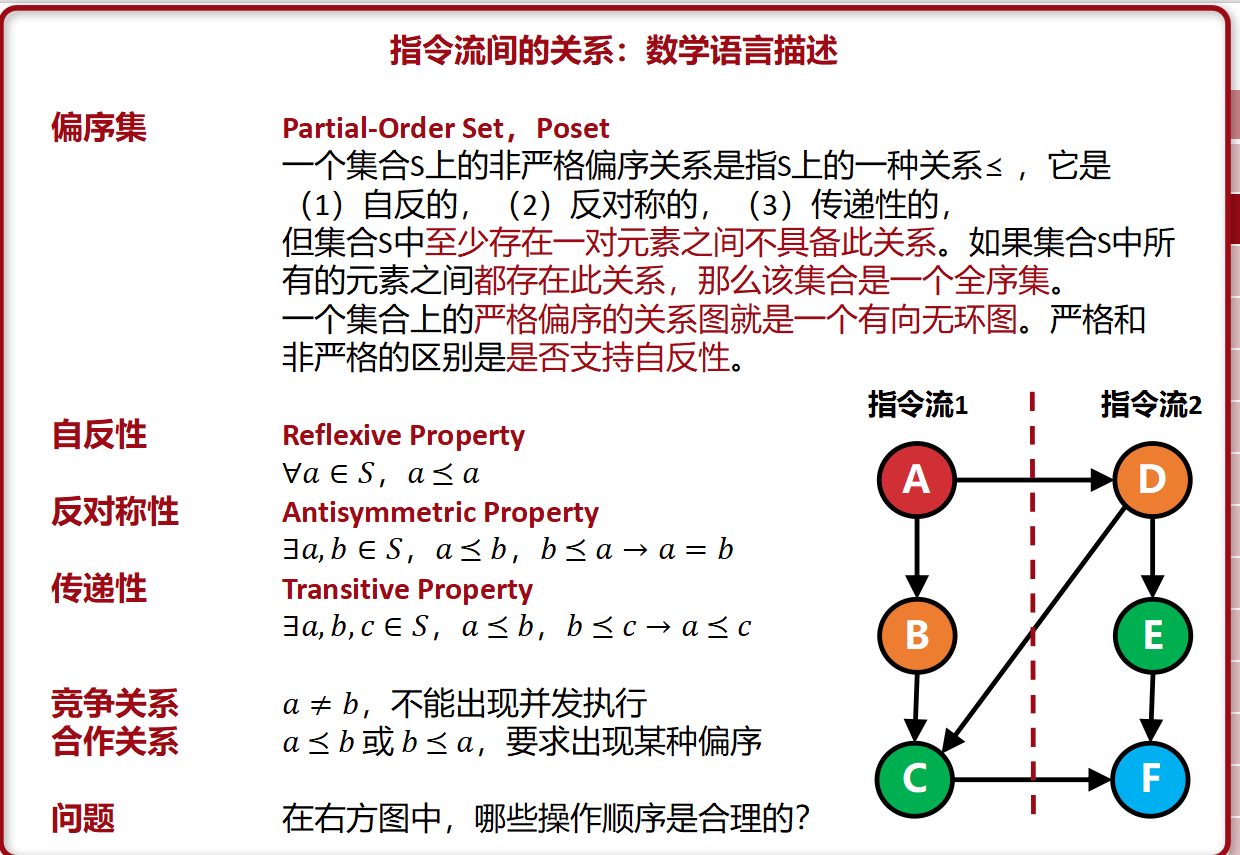
洪泛都是可以的 ABDCEF ADBCEF ADEBCF等
竞争关系:互斥
临界资源:
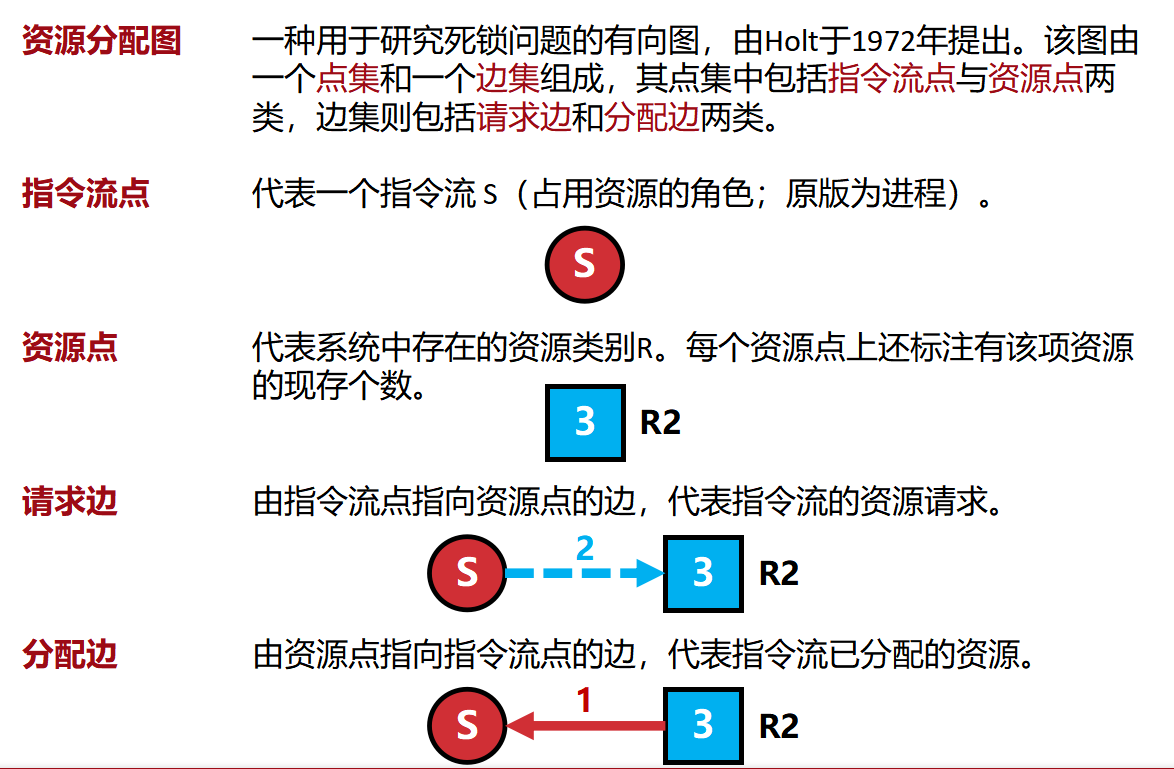
不能同时被两个指令流使用的资源。 文件 设备
临界区:
访问临界资源的程序段,临界区不能并发执行。又叫做关键区域。临界区越短越好,最好只包括访问临界资源的必要步骤。太长了就只能等着
互斥
临界资源不能并发使用的现象称为互斥。它在指令流的执行上,表现为临界区在任何时候只能最多被一个指令流执行。
伯恩斯坦(Bernstein)条件
对任意指令流S,我们使用 R(S)表示其进行读操作的资源的集合, W(S)表示其进行写操作的资源的集合。 则假设有两个指令流S1、S2,若
[R(S1)∩W(S2)] ∪ [R(S2)∩W(S1)] ∪ [W(S1)∩W(S2)] = Φ, 则操作可以并发执行。
就是只能同时读。不能有一方在写。
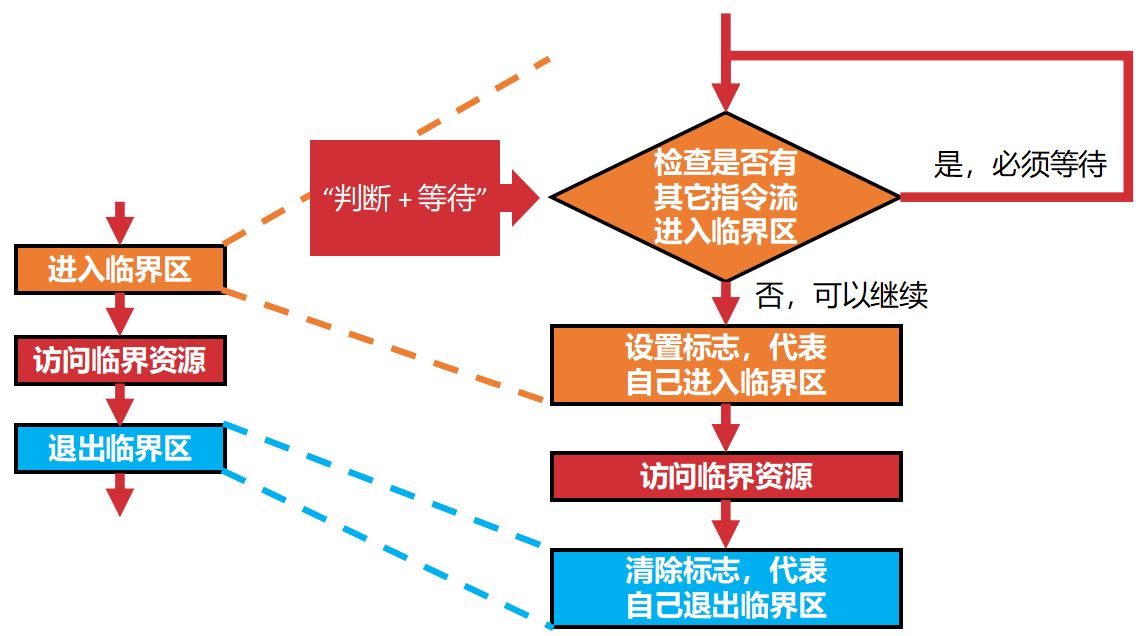
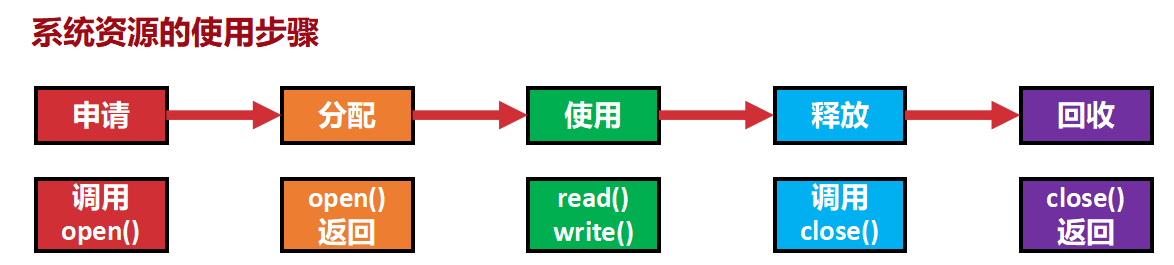
要实现互斥 进入和推出临界区的操作应该包含哪些流程
进去前,看看别人有没有在开大,如果有人开打你就憋着。
如果没有人开大,就锁上厕所门告诉大家。
排泄。
把锁打开,离开厕所。
Peterson算法(结合竞争 合作) 考点 ☆

对于指令流S0:
-
① want[0] = 1;
-
S0举起牌子说:“我想进去!” (宣布意图)
-
-
② turn = 1;
-
S0非常有礼貌,把“通行令牌”扔给S1说:“兄弟,你先,我等你。”
-
-
③ while (want[1] == 1 && turn != 0) { 等待 }
-
S0检查对方S1:如果S1也举着牌子(想进来),且现在通行令牌不在我手里(turn不是0),那我就乖乖等着。否则,我就跳过等待,进入④。
-
我想去,如果对方也有意愿且当前轮次不是我的 我就等待
能进去的情况,要么是
(1)对方want = 0,不想要
(2)对方主动让给自己的turn,对方肯定在等待。
上述实现会出现(1)死锁,(2)活锁或者(3)饥饿吗?
(1)不会出现死锁,如果两人都拿着 want=1 互等,最后执行 turn 的那个人会主动让出自己,另一方必定能进去,所以死锁破除。
(2)不会出现活锁,因为双方都在等待时均不放弃自己的进入意图。当一方退出(执行 ⑤ want[0]=0 时),另一方会立刻进入临界区
(3)不会出现饥饿,turn 变量就像一个交替换班的令牌。只要有人用完退出了,下次轮到对方的概率是公平的
互斥锁:自旋锁
互斥锁Lock/Mutex
一种用以控制临界区访问的互斥访问原语(原子语句,同时发生),分为加锁和解锁两个原子操作。进入临界区先加锁,退出临界区后解锁。
-
当一个线程想进临界区,但锁已经被别人拿走了。
-
阻塞锁:操作系统把这个线程挂起(放入等待队列),让CPU去干别的活。等锁空闲了,再唤醒它。(不浪费CPU,但切换有开销)。
-
自旋锁(Spin Lock):这个线程不放弃CPU,它在原地一直打转(执行一个空的循环
while(lock==1) {}),不断地问:“锁释放了吗?锁释放了吗?...”就像陀螺一样原地高速旋转,直到锁被释放,它立刻抢到锁。
好自旋锁的三个标准
互斥访问 Mutual Exclusion(忙则等待)
临界区保证互斥,任何时候只有一个指令流。
全局进展 Global Progress(空闲让进)
如果目前临界区没有占用,则在有指令流请求时应当满足它,不会陷入全局死锁。
局部进展(*) Local Progress(有限等待,Bounded Waiting)
任何一个指令流的等待时间都是有上界的,不会陷入局部或全局活锁。上界一般是O(n)。
硬件锁
如果我们能利用硬件功能,让①和②之间不发生调度,那也可以。
开关中断——不允许指令切换
封禁调度器的一个最简单办法就是关中断。一旦关中断,时钟中断就无法发生(此时若时钟中断到来,需要等待开中断后才发生),自然无法进行指令流或线程切换

处理器都有开关中断指令,为何这种方法仅在那些针对无内核模式的CPU的操作系统上(如FreeRTOS、RT-Thread)广泛使用?
该算法要赋予所有指令流直接开关中断的权限。一旦有恶意指令流,它关中断后不再开启,就可以得到100% CPU,可以轻易破坏线程间的时间隔离
第一部分:三大“原子指令”神仙打架(分别对应三张图)
先理解一个共同的概念:什么是“原子指令”?
通常情况下,读取变量和修改变量是两个动作,中间可能会被线程切换打断。而“原子指令”是CPU硬件提供的超能力,它保证上锁这个动作,“检查”和“修改”两个动作在一个不可分割的瞬间同时完成。要么全做,要么全不做,没有任何缝隙可以被别人插队。
这三张图分别用了三种经典的硬件原子指令来实现自旋锁:
1. SWAP / XCHG(图1)——“直接硬换”
-
指令含义:交换两个内存地址的值(完全替换)。
-
锁代码原理:
-
-
线程自己兜里揣着一个
1(current[0]=1)。 -
用
swap()指令,把自己的1和锁变量enter里的值瞬间互换。 -
结果:如果
enter原本是0(空闲),换回来current就是0,你成功抢到锁(enter变成了你兜里的1)。如果enter原本是1(别人占了),换回来current就是1,说明没抢到,继续while循环。
-
2. TAS / BTS(图2)——“测试并设置”(最经典、最常用)
-
指令含义:Test-And-Set。检查一个内存位的值,如果它是0,就把它改成1,并返回旧值(0或1)。这个过程也是原子的。
-
锁代码原理:
-
-

-
bts指令瞬间完成两件事:① 看看锁是不是1;② 把锁强行改成1。 -
如果返回1(说明锁原本就是1,被别人占着),那继续死循环等待。
-
如果返回0(说明锁原本是0),
bts已经把锁设成了1,说明你抢到锁了,立刻跳出while循环进入临界区。
-
3. CMPXCHG / CAS(图3)——“比较并交换”(现代高并发之王)
-
指令含义:Compare-And-Swap。判断内存里的值是不是等于我预期的旧值(old),如果是,就把它换成新值(new);如果不等,说明被别人改了,什么都不做。也是原子操作。
-
锁代码原理:
-

-
意思是:“我的期望值是0,我想把它改成1”。如果此时
enter确实是0,那瞬间变成1,返回0(成功上锁)。如果是1,则原子指令什么都不做,返回1(说明有人抢了),继续死循环。
-
第二部分:结合三张图下方的“问题”——它们的致命缺陷
你可能会发现,这三张图下面的问题(问题一、问题二)几乎一模一样。这说明这三种方法有共同的优点,也有共同的致命缺点。
优点(可以回答图里的问题1和2):
-
不会死锁:因为
while循环一旦抢到锁就会立刻退出,没有互相等待的闭环。 -
不会活锁:要么抢到,要么一直抢,不存在互相谦让导致谁也进不去的情况。
-
互斥完美:全靠CPU硬件保证一瞬间只有一个线程能成功修改
enter。
致命缺点(回答图里的问题3,以及图3的问题二):
这三张图底部的文字都问了同一个问题:“它能保证公平进入吗?” 以及 “有什么缺点?”
答案是:大缺点!这几种锁是绝对不公平的(会导致“饥饿”)。
-
不公平(饥饿问题):
请看这行代码:while (条件为真) { }-
假设有100个线程在排队抢这把锁。一旦当前持有锁的线程释放锁(执行
enter=0)。 -
问题来了:此时,这100个线程全都从
while循环里醒过来,一起并发地去执行硬件原子指令抢锁。 -
因为指令是原子的,但CPU总线带宽有限,总有一个线程会抢赢,其他99个继续转回去
while等待。 -
最倒霉的情况:线程A可能运气极差,连续100次抢锁都慢了一点点,被别的线程抢走了。在纯自旋锁中,没有排队机制,线程A可能永远等不到锁,导致“饥饿”。
-
图3底部的终极追问:“上述(自旋锁)最大的缺点是什么?”
答:是“忙等待(Busy Wait)”——也就是一直在消耗CPU算力空转!
这就是我们之前讲到的:如果临界区代码稍微长一点,或者持有锁的线程被操作系统挂起了,那么其他99个自旋的线程就会把CPU烧到100%,电脑变卡,系统整体吞吐量大幅下降。
互斥锁:阻塞锁
第一层:为什么需要阻塞锁?(顶部的“自旋的缺点”)
图里列举了自旋锁(Spinlock)的四个致命缺陷,尤其是第(1)和(2)条,是引入阻塞锁的根本原因:
-
无谓地浪费CPU:不拿到锁就不停地
while(1)空转。 -
造成内存总线压力:在多核系统中,成百上千个CPU核都在疯狂地通过总线“盯着”同一个锁变量,这会挤爆内存通道的带宽,让整个系统变慢。
-
无法在“多对一”模型中使用:这是高级并发考点。假设有很多用户线程(指令流)映射到同一个内核线程上。如果一个用户线程自旋等待,它霸占了整个内核线程,导致同一个内核线程上的所有其他用户线程全被卡死。
-
不公平:没有排队机制,靠运气抢锁,容易造成某个线程永远抢不到(饥饿)。
结论:为了解决上述问题,必须引入“遇到锁被占用时,主动放弃CPU”的机制。
第二层:阻塞锁是如何工作的?(中间的“阻塞锁”段落)
看图中间那段文字,它的核心逻辑就是“让权等待”和“排队”:

-
立即停止执行(让出CPU):当指令流发现锁被占用时,它绝不空转。相反,它调用操作系统内核,把自己的状态标记为“阻塞(Blocked)”,并将CPU交给别的线程去运行。
-
进入等待队列(排排坐):操作系统会维护一个“等待队列”。就像排队买奶茶一样,没抢到的线程按“先来后到”的顺序乖乖排在这个队列里。
-
唤醒机制(叫号):一旦锁的占有者释放了锁,操作系统不是把排队的所有人都叫醒(防止他们再次疯抢),而是只叫醒队列头部(排在最前面)的这一个线程,把锁直接交给它。
-
实现公平性:这种排队和叫号的机制,彻底解决了饥饿问题,保证了绝对的公平。
第三层:阻塞锁的实现方式
-
可以在“线程级别”(内核空间)实现:这是操作系统内核提供的原汁原味的睡眠锁(如 Linux 的
mutex)。当线程阻塞时,整个线程陷入内核并睡大觉。 -
可以在“指令流级别”(用户空间)实现:这通常指用户级线程(协程 / Green Thread)。在这种模型下,当一个指令流阻塞时,它只是把自己停掉,不让整个线程陷入内核,而是让同一个线程上的其他用户级指令流继续跑。
🔒 自旋锁 (Spin Lock)
自旋锁的原理是“忙等待”(Busy Waiting)。当一个线程尝试获取锁时,如果锁已被其他线程持有,它不会被挂起或进入睡眠状态,而是会进入一个循环,不断地检查锁是否被释放。
-
加锁过程:
- 线程尝试通过原子操作(如CAS)获取锁。
- 如果成功,则进入临界区执行代码。
- 如果失败,说明锁已被占用,线程不会放弃CPU,而是在一个循环中持续重复步骤1,这个过程被称为“自旋”。
-
解锁过程:
- 持有锁的线程执行完临界区代码后,通过原子操作释放锁。
- 此时,正在自旋的其他线程在下一次循环检查时会发现锁已被释放,其中一个会成功获取锁。
-
自旋锁的优缺点:
-
优点:
-
无上下文切换开销:线程在无法获取锁时不会进入阻塞状态,而是持续循环检查锁状态(即“自旋”),从而避免了操作系统线程调度与状态切换的开销。
-
适合短临界区:若持有锁的时间极短(小于一次上下文切换所需时间),自旋锁效率远高于阻塞锁。
-
多核友好:在多核系统中,不同核心可并行自旋,提高锁竞争时的响应速度。
-
-
缺点:
-
浪费CPU资源:若锁被长时间持有,自旋线程持续占用CPU,导致系统整体效率下降。
-
不适用于长临界区:临界区过长时,自旋锁会因持续空转而严重降低系统性能。
-
-
🛌 阻塞锁 (Blocking Lock)
阻塞锁的原理是“让权等待”(Yield and Wait)。当一个线程无法获取锁时,它会主动放弃CPU,进入阻塞(睡眠)状态,由操作系统调度器将其挂起,并切换到其他线程执行。
-
加锁过程:
- 线程尝试获取锁。
- 如果成功,则进入临界区。
- 如果失败,线程会向操作系统发起系统调用,请求将自己挂起。操作系统会将该线程的状态从“运行态”改为“阻塞态”,并将其放入一个等待队列中,然后调度其他线程运行。
-
解锁过程:
- 持有锁的线程执行完临界区代码后,释放锁。
- 操作系统会从等待队列中唤醒一个或多个线程,将它们的状态从“阻塞态”改为“就绪态”。
- 被唤醒的线程需要等待调度器再次分配CPU时间片,才能重新尝试获取锁。
-
阻塞锁的优缺点:
-
优点:
-
节省CPU资源:无法获取锁时线程进入阻塞状态,释放CPU给其他线程,系统资源利用率更高。
-
适合长临界区:锁持有时间长时,阻塞机制避免无效轮询,保证系统稳定性。
-
-
缺点:
-
上下文切换开销:线程从运行态进入阻塞态,再被唤醒,涉及状态保存与恢复,带来性能损耗。
-
调度延迟:线程唤醒需依赖操作系统调度,响应时间不如自旋锁即时。
-
-
前面是这些锁底层如何实现。接下来是如何使用这些加锁机制。
管程
管程封装了加锁解锁。
第一层:终极工具一——管程(Monitor)
-
管程看起来就像一个对象,该对象的各个成员函数均封装了加锁、访问资源、解锁三个过程。
管程的特点
互斥性
管程内的临界区只能由一个指令流进入并执行。
模块化
管程是可单独编译的程序的基本单元,一般写在一个单独的源文件内。
封装性
管程封装了对原始临界资源的一切操作,不向外界暴露任何接口。管程内的任何数据只能通过管程的接口访问,同时管程代码也只访问管程内部的数据。
抽象性
管程抽象掉了原始临界资源的细节属性,仅保留了其高层次的功能接口。
守护进程和管程的区别:
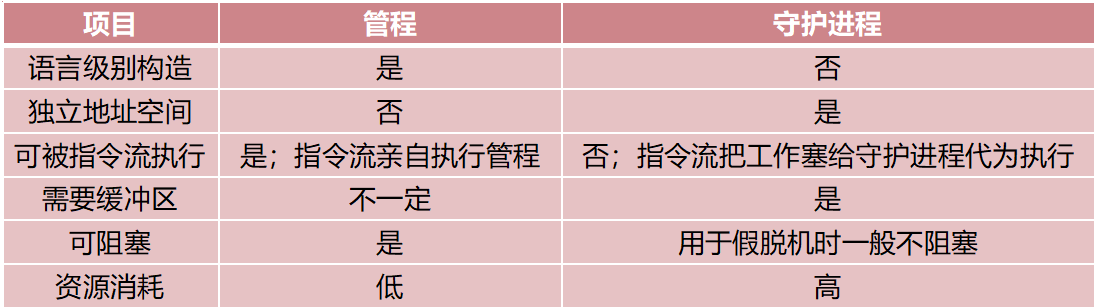
空间安全性(守护进程运行在内核,强隔离)
守护进程运行在独立的地址空间,垄断了临界资源。因此,指令流不可能得到机会亲自参与临界资源操作。
相比之下,管程只是将敏感操作藏起来,恶意指令流,还是可以强制I/O:因为I/O的代码和这些指令流在同一个地址空间。
时间安全性(管程内运行线程,消耗自己的时间片而不是代理人的时间片)
管程虽然在空间上不安全,在时间上却是安全的。
每个线程执行管程消耗的都是它自己的时间片,发起大量恶意请求只会导致自己的时间预算耗尽。
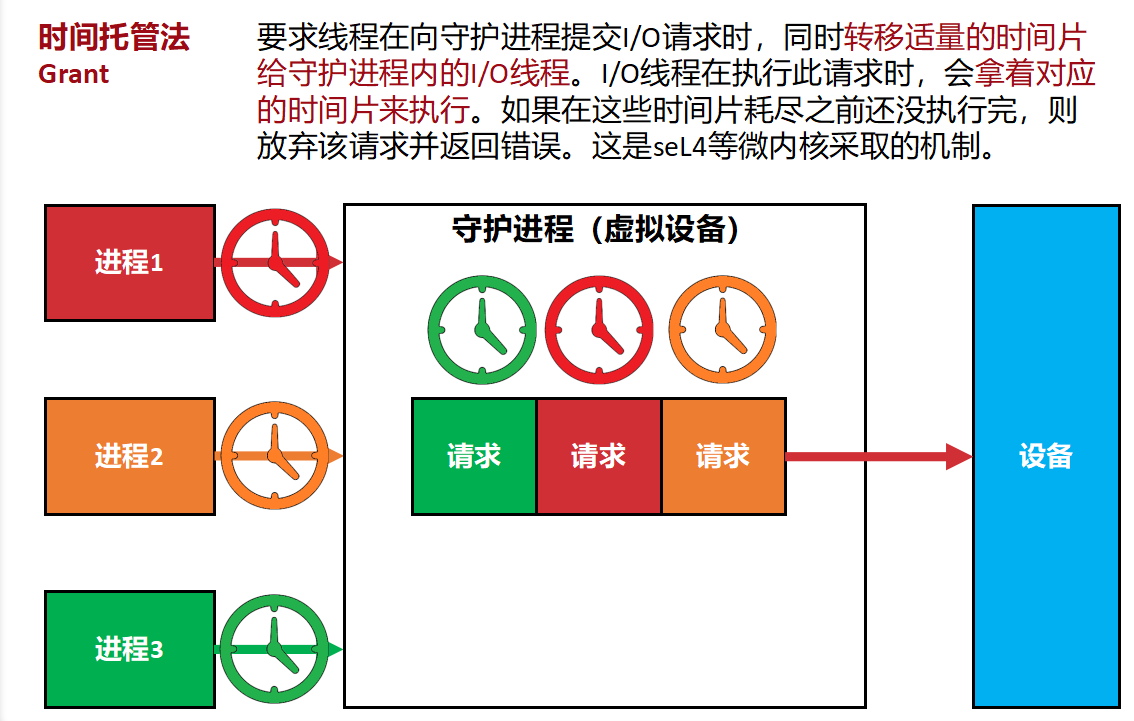
相比之下,守护进程却不是这样:因为工作都推给了守护进程,消耗的是守护进程内的I/O线程的时间片。
如果一个恶意线程向守护进程提交大量的垃圾I/O,就可以用掉该I/O线程的所有时间片,使其他线程的请求得不到执行。
如果想要守护进程的空间安全性,又要管程的时间安全性?
管程线程迁移法(管程运行在隔离空间内,线程不变,维护时间隔离)
需要访问临界资源的时候就把线程迁移到隔离管程中,访问完再离开。
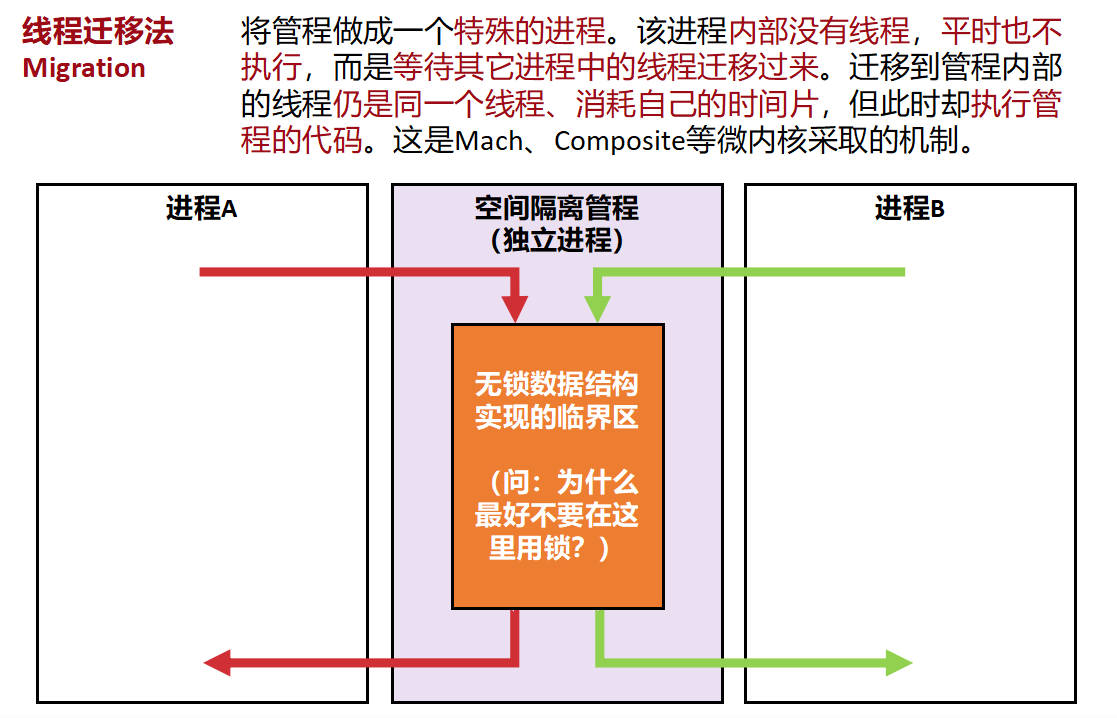
时间托管法(调用者转移时间片给守护进程,解决守护进程无时间安全性的问题)
要求线程提交IO请求的时候,要求给一些时间片给守护进程,守护进程中的IO线程用这个时间片执行。(守护进程中的线程充当代理人执行)
第二层:管程内部的沟通工具——条件变量(Condition Variable)
用于解决同步的问题(消费要在生产后)
-
核心作用:它总是与一个锁配合使用:如果条件不满足,则指令流自动释放锁并加入等待 队列;而当条件满足时,等待队列头部的指令流将被唤醒并自动恢复对锁的持有。
条件变量是指令流A在拿到锁后,根据条件决定对锁的操作的,比如不满足指令流A就会调用条件变量释放锁,进入阻塞态。如果满足,当前指令流A就唤醒下一个指令流B。
-
两个核心操作:
-
Wait(阻塞/入队):消费者发现资源不够时,调用
Wait。关键动作:它会在睡着的瞬间,先把你手里的锁给释放掉! -
Signal(唤醒/出队):当你生产了数据后,调用
Signal去叫醒一个排队睡觉的消费者。
-
场景:消费者线程 A 想要从空队列里取数据。
-
【准备阶段】:系统里已经存在了一个锁(Mutex)和一个条件变量(CV)。CV 本质上是空的队列。
-
【第1步:拿锁】指令流 A 调用
lock()。-
拿到锁。注意:此时条件变量什么事都没干,它只是安静地待在那里。
-
-
【第2步:检查条件】指令流 A 检查共享变量(如
queue.isEmpty())。-
发现队列为空。
-
-
【第3步:关键交互】指令流 A 调用
cv.wait(&lock)。-
此时条件变量才真正“动”起来!
-
动作1(原子操作):CV 帮 A 把拿到的锁给释放掉。
-
动作2(入队):CV 把 A 这个线程添加到自己的等待队列里(CV 内部队列现在多了 A)。
-
动作3(阻塞):让 A 睡去。
-
-
【后续】生产者线程 B 来了:
-
拿锁成功,往队列里放了一个数据。
-
调用
cv.signal()。 -
此时条件变量再次“动”起来:它去自己的等待队列里,把刚才排队的 A 叫醒。A 醒后,内核会自动让它重新去争取锁。
-
惊群效应
多个指令流的阻塞同时被解除,争抢同一个资源造成负载极具增大的现象。
条件变量的两种语义(Hoare vs Mesa)
Hoare语义 Hoare Semantics
条件变量的唤醒操作将保证被唤醒的线程立即得到调度并持有锁。
在这个语义下,一旦某个指令流被唤醒了,那就说明条件百分之百成立,指令流无需重复检查条件是否仍成立。
Mesa语义 Mesa Semantics
条件变量的唤醒操作仅保证被唤醒的线程进入就绪状态,需要参与锁的竞争,并不保证该线程立即得到调度。
在这个语义下,被唤醒的线程仅仅是得到了一个提醒:你的条件曾经可能满足过。要在醒来后再次检查
条件变量是的意思是“根据是否满足这个条件,执行上锁/解锁的操作”,是代理人,但是只能处理01问题。但是加上计数器就可以处理数值问题了。
阻塞锁是负责互斥的。别人用锁的时候自己要通知OS把自己加入等待队列。
-
阻塞锁(Mutex):最基础,负责“互斥(不让两个人同时进一间房)”。
-
条件变量(Condition):以“阻塞锁”为前提,加上了“同步(等待特定状态)”的功能。它必须配合阻塞锁一起用(负责在门内等纸)。
-
信号量(Semaphore):高级封装。它可以在内部自带计数器,可以直接当阻塞锁用,也可以当条件变量用(因为内部自带了锁 + 等待队列)。
信号量
同时具备资源计数和等待两种功能
获取操作Acquire
也叫“P”操作。减少计数器的计数,代表从系统中拿走资源。如果系统中当前没有资源,则可以阻塞或自旋并等待。
释放操作Release
也叫“V”操作。增加计数器的计数,代表向系统中投入资源。
死锁活锁与资源图
死锁
系统中有指令流发生无法自行解除的循环等待。
具体地,有如下三个条件:
互斥条件(有争夺)
系统中存在有一定互斥性的资源。
持有条件(不让放弃自己拿到的 且 不能夺取别人的)
指令流已获得的资源不释放,且新请求不撤销。
其中,持有条件又可以细分为如下两条:
保持请求 指令流不主动放弃已经持有的资源。
无法剥夺 不允许指令流互相剥夺资源;非抢占。
循环等待(你我都不让)
指令流互相循环等待资源释放,不能进展。
活锁
指令流并未死锁,但其在多次反复尝试获取资源均失败。
死锁能自动解除吗?活锁呢?
死锁不可能自动解除。因为持有资源+循环等待,任何指令流都在等待其它指令流释放资源。
但活锁则不一定,只要指令流的执行进度发生一些细微变化,不再碰巧让对方的条件在反复重试中失败,就有可能产生进展。
三种实现结构
就是说无阻碍结构是不保证多个指令流运行时有一个人能完成的,无锁数据结构是能保证至少一个人在多个指令流中完成的,而无等待数据结构是保证所有人都能正常完成
无等待数据结构——保障至少一个指令流能进展
无锁数据结构——所有的指令流都能进展
无阻碍数据结构——无死锁

-
定义(图里的红字):只能保障自己一个人指令流,多个指令流什么爷保证不了
-
定义(图里的红字):保证全局进展,不保证局部进展。即无论系统中有多少个线程在竞争,至少有一个线程能保证在有限步数内完成自己的操作(整个系统的CPU不会空转)。
-
定义(图里的红字):保障局部进展 + 全局进展。即无论系统中发生多么严重的竞争,每一个指令流,都能在有限个步骤内完成自己的操作,绝对不会出现某个线程永远重试失败(饥饿)。
资源分配图——用于研究死锁问题的有向图
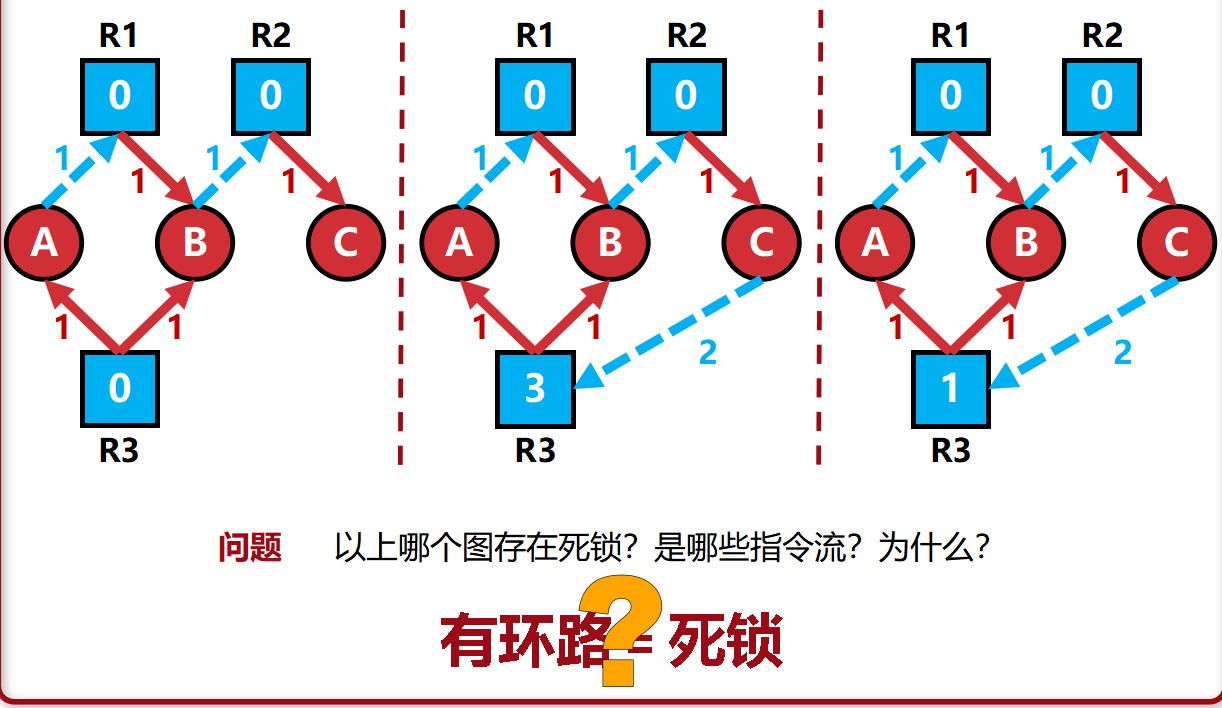
图一是链式等待,不是死锁。
图二是有环路A->R1->B->R2->C->R3->R1R2
图三有死锁,R3被C请求2,只有1,无法分配,而R3被AB占用,而AB不愿意放弃自己占有的资源,A->R1->B->R2->C->R3->R1R2,导致链式依赖。
化简资源分配图
资源分配图的分析方法
1. 若某指令流的所有请求都可以得到满足,则删除其所有请求边和分配边,并将分配边上的资源归还给各个资源池。
2. 重复上述步骤,直到无可执行。
此时若所有指令流都执行结束则无死锁。若还有指令流存在(无法被化简掉),则它们一定在循环等待,此时发生死锁。 只有最后剩下的指令流是死锁的
银行家算法
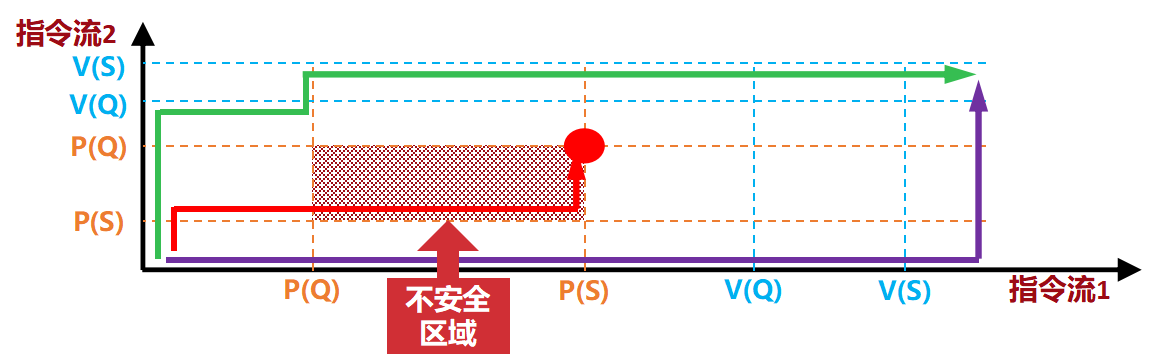
-
假设线程1已经申请了
Q(进入了不安全区域的左边缘)。此时,操作系统(或调度器)绝对不能允许线程2去申请S(进入不安全区域的下边缘)。 -
操作系统的做法:如果线程2这时候想申请
S,系统会判断“如果你现在拿了S,你们俩就会进入红色阴影区,有死锁风险”。于是,系统会让线程2阻塞(暂停等待),直到线程1安全地拿到了S并释放了资源,走出红区后,才允许线程2去拿S。
操作系统像一个交通指挥官,它会实时监控你和另一个线程的资源使用轨迹。如果发现你们接下来的步伐会导致“你拿我的,我拿你的”这种交叉等待(即跨入红色阴影区),系统就会强制按住其中一个人不让走,直到另一个人彻底跑完拿到所有资源,确保安全了,才放行。
一种用于资源分配的算法。通过检查请求仅批准那些不会让系统进入不安全状态的请求,完全避免死锁风险。
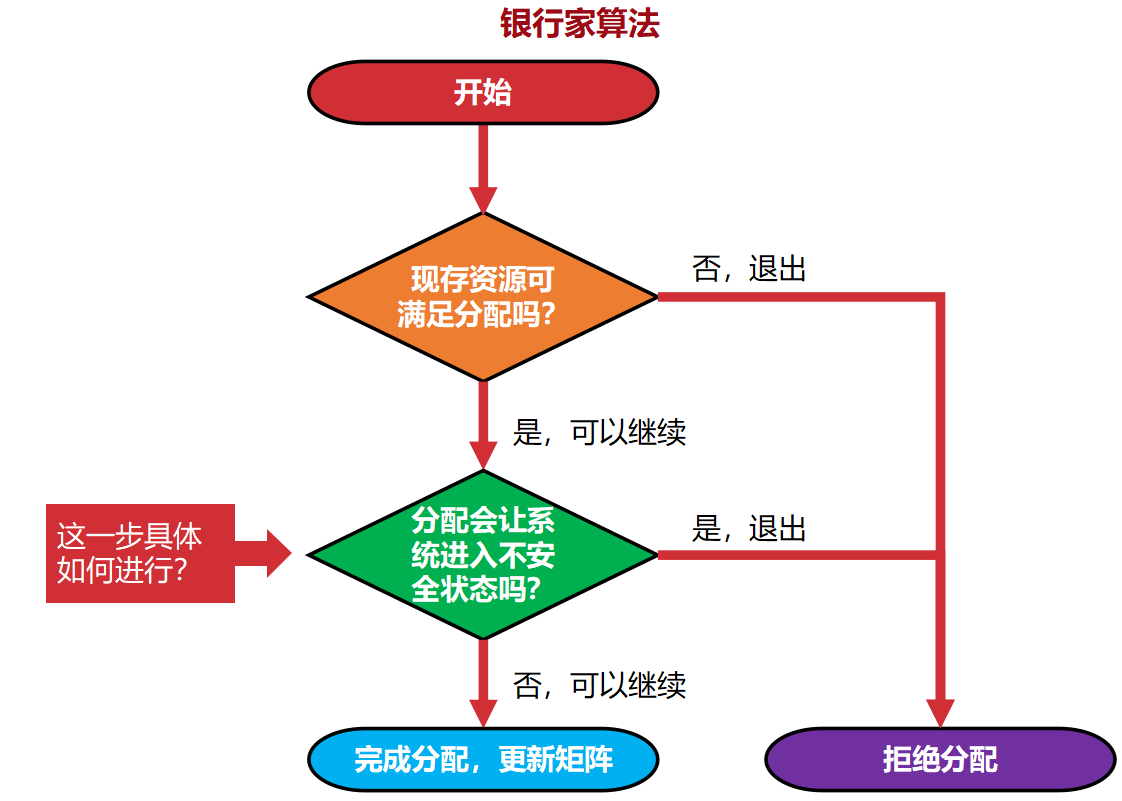
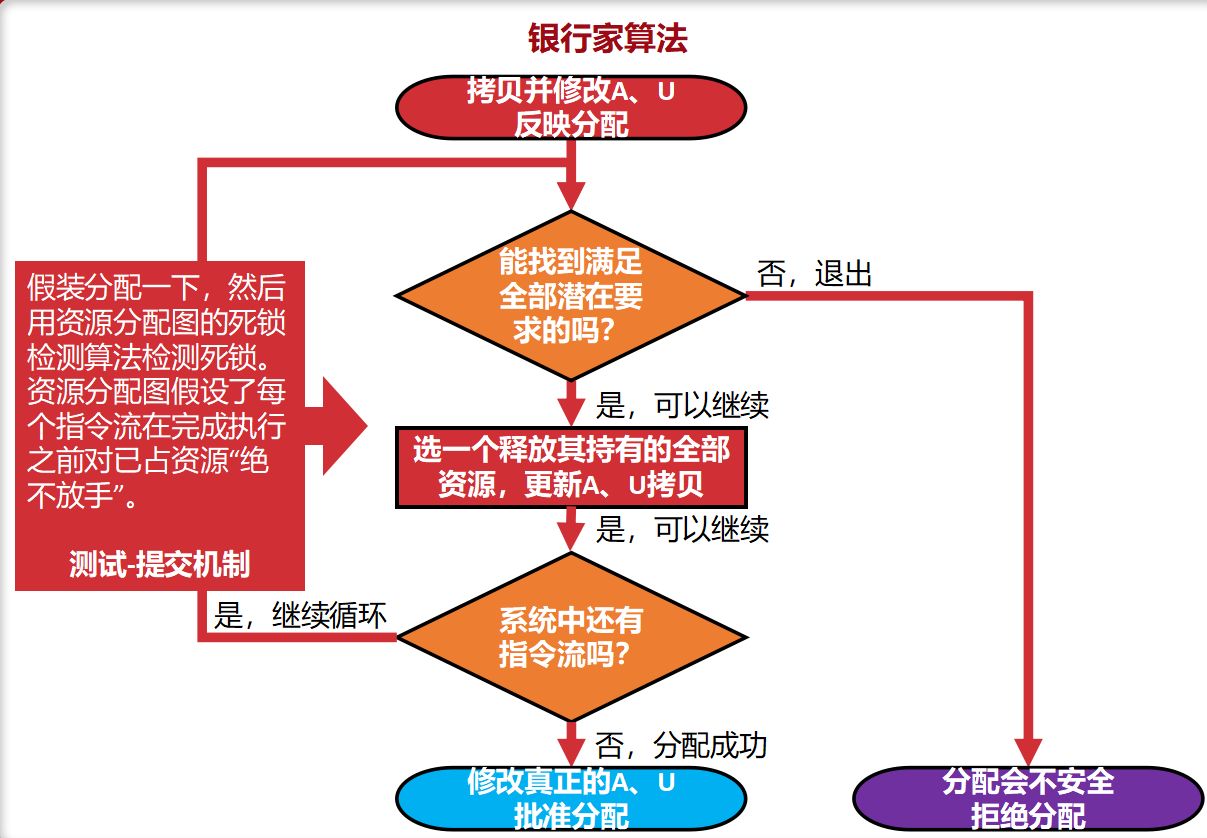 ‘
‘
如何避免死锁
鸵鸟政策
操作系统仅提供同步工具,不负责探测和解决死锁,而是由人或其它系统服务在死锁时介入。
破坏互斥条件
只要想办法让资源本身不互斥、不竞争,就自然不存在等待问题,就不可能死锁。
破坏保持请求
要求指令流在无法进展时主动放弃之前获得的资源。
破坏无法剥夺
一旦探测到有可能死锁,就强制剥夺死锁参与者的全部资源。
破坏循环等待
阻止系统中生成可能的等待环路。

openEuler 是由开放原子开源基金会孵化的全场景开源操作系统项目,面向数字基础设施四大核心场景(服务器、云计算、边缘计算、嵌入式),全面支持 ARM、x86、RISC-V、loongArch、PowerPC、SW-64 等多样性计算架构
更多推荐

 9
9 0
0- 0



 已为社区贡献17条内容
已为社区贡献17条内容

所有评论(0)