操作系统 第九章 进程间通讯
通讯的四个级别(表格解析)

表格按“开销(从极小到极高)”和“实现空间”把通讯分为了四档:
-
指令流间(开销极低,用户空间实现):
-
这是什么:这是指同一线程内部,或者用户态协程(User-level Coroutines)之间的切换与通讯。
-
为什么便宜:因为根本不需要进入操作系统内核(不需要系统调用),只需要代码自己在内存里切换一下栈指针即可。纯算数级别的快。
-
-
线程间(开销低,用户或内核空间):
-
这是什么:同一个进程内的两个线程(比如Java里的两个Thread)共享同一块内存空间,用我们之前学的锁、信号量进行通讯。
-
为什么算低:因为它们共享内存(不用拷贝数据),只需要把变量改一下。但如果线程因为竞争锁而阻塞了,就要陷入内核。
-
-
进程间(开销高,内核空间):
-
这是什么:两个完全独立的程序(比如Chrome浏览器和Word文档)要互传数据。
-
为什么贵:因为它们的内存空间是隔离的。操作系统必须把数据从A的内存复制(拷贝)到B的内存,这个拷贝动作必须由操作系统内核来执行,涉及大量内存搬运。
-
-
应用程序间(开销极高,内核+中间件):
-
这是什么:比如A公司开发的微信和B公司开发的支付宝,要跨网络传输数据。
-
为什么极度昂贵:这不仅要过内核(网络协议栈),还要过物理网卡、网线,甚至跨越互联网路由器。开销巨大。
-
(1)为什么指令流间和线程间通讯可以在用户空间实现,进程间通讯和应用程序间通讯只能在内核空间实现?
(1)进程和应用程序间通讯必然要跨越空间边界,而跨越空间边界只有操作系统才做得到。跨越时间边界和角色边界则可以在用户模式完成,因为空间是共享的(同一个进程中)。
(2)在实践中,为什么线程间通讯总是在内核空间实现?
(2)线程是内核管理的,其阻塞式通信就必须在内核空间实现。指令流则是用户空间管理的,其阻塞式通信可以在用户空间实现。
可靠IPC与非可靠IPC
可靠 IPC 是指通信机制能够保证数据不丢失、不重复、按顺序且无错误地从发送方送达接收方。
非可靠 IPC 是指通信机制不保证数据一定能送达,也不保证送达的顺序和完整性。(信号 共享内存)
IPC总结
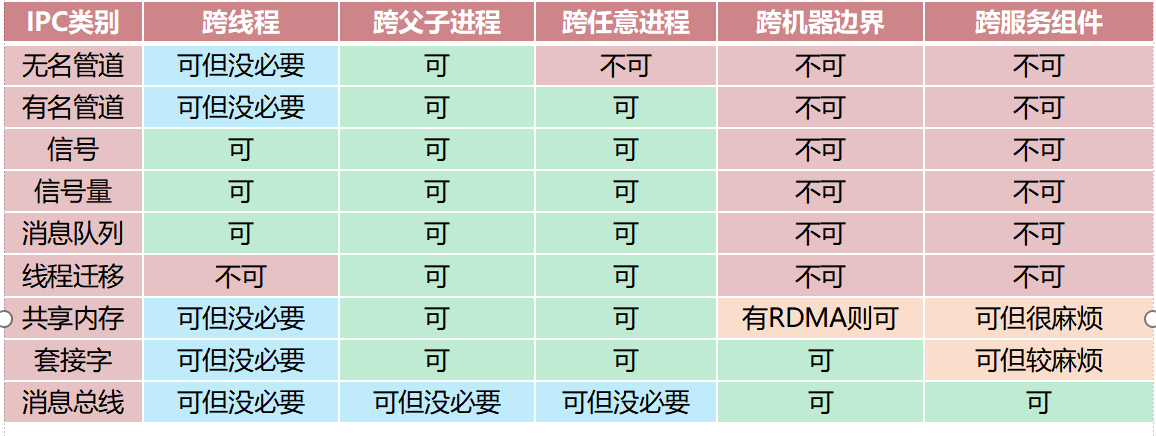
管道
点对点通信工具。在Linux中,管道分为无名和有名管道。
无名管道
用于父子进程之间点对点通讯的工具。父进程创建无名管道,Pipe然后调用fork(),父进程端使用一个端口,子进程端使用一个端口,且只能父发子收或父收子发。如果需要全双工,则只能创建两条无名管道。

读空管道 写满管道 就阻塞。
无名管道

1. fork() 的核心机制
当程序中调用 fork() 时,操作系统会复制当前进程,创建一个新的进程。
而 fork() 函数会返回两次:
-
在父进程中:
fork()返回子进程的 PID(一个大于 0 的整数)。 -
在子进程中:
fork()返回 0。
2. 代码逻辑详解
结合图片中的代码 if (fork() != 0) 来看:
-
当
fork()返回值!= 0时:-
意味着当前是 父进程。
-
所以父进程会进入
if语句块内部(执行红色的代码:close(fd[0]),write(fd[1])等)。
-
-
当
fork()返回值== 0时:-
意味着当前是 子进程。
-
所以子进程会跳过
if语句块,进入else分支(执行蓝色的代码:close(fd[1]),read(fd[0])等)。
-
无名管道只适用于父子进程,不适用于任何进程。
有名管道
用于任意进程之间通讯的工具。任意进程均可创建有名管道,该管道将作为一个特殊文件存在。此后,进程可以读写文件进行通讯。虽然有名管道允许多个读者和写者,但多个写者之间存在写交叉的风险。

步骤 1:创建管道(通常由 P0 做)
mkfifo("/tmp/myfifo", 0777);-
含义:在
/tmp目录下创建一个名字叫myfifo的管道文件。0777是权限,表示所有人都可以读写这个管道。
步骤 2:P0(写者)的行为 —— “只写”
fd = open("/tmp/myfifo", O_WRONLY);
write(fd, buf, len);
close(fd);
unlink("/tmp/myfifo"); // 用完后删除管道文件-
O_WRONLY(只写):P0 打开这个管道时,告诉操作系统“我只想往里面写数据,我不读”。如果 P0 试图去读,系统会报错。 -
write:把内存里buf中的len长度的数据写进去。 -
unlink:数据传完了,把这个管道文件从文件系统里删掉(做好清洁)。
信号 不能传递大量数据 (非可靠IPC)
Linux系统中的一种回调函数机制,可以用来在不同进程之间或同一进程的不同线程之间发送轻量级通知。当通知被送达时,线程暂停执行原程序,转去执行信号处理例程(Signal Handler),然后再返回原程序继续执行。

执行pid的SIGUSR1这个信号,P1收到后触发调用my_handler来处理这个信号。
信号量 可跨进程 Semaphore
Linux系统提供的标准信号量接口,同时具备资源计数和等待两种功能,适用于生产者-消费者关系。


1. 代码逐行分析
sem_t semaphore; // 1. 声明一个信号量变量
sem_init(&spin, 0, 0); // 2. 初始化信号量-
关键在这里:
sem_init的第三个参数是 0。这意味着,这个信号量的初始计数器是 0。这个状态意味着 “一开始没有任何资源”。
线程 T1(消费者 / 等待者):
sem_wait(&semaphore); // T1 执行这行时,发现计数器是 0,于是 T1 立刻被阻塞(进入睡眠),等着别人给它送资源。线程 T0(生产者 / 发送者):
sem_post(&semaphore); // T0 执行这行,计数器从 0 变成 1。内核发现刚才 T1 在排队,立刻把 T1 叫醒。
// 此时 T1 醒来,sem_wait 成功返回,T1 继续往下执行。最后:
sem_destroy(&semaphore); // 销毁信号量,清理内核内存。消息队列 多对多 支持
Linux提供的标准消息队列机制,可以在不同进程之间传送信息。 和管道不同,消息队列允许多个发送者和多个接收者,且收发均以消息为单位,无需考虑数据交叠的问题。为了跨越地址空间,Linux会先将消息从发送者拷贝到内核,然后再从内核拷贝到接收者。
为什么需要它?
管道是乱序混合的信息,消息队列是打包好的json
核心机制——怎么跨越“地址空间”?
“为了跨越地址空间,Linux 会先将消息从发送者拷贝到内核,然后再从内核拷贝到接收者。”
结合你之前学的知识,这就是进程间通信(IPC)开销高昂的根本原因。
-
P0(进程A)写数据 -> 内存拷贝 1 -> 内核空间的缓冲区。
-
P1(进程B)读数据 -> 内存拷贝 2 -> P1 的用户空间内存。
-
数据被彻底复制了两次,所以这是非常消耗性能的。

信号量+共享内存可以实现消息队列,但是消息队列不能实现信号量

1. 定义消息的结构体(图中灰色字体部分)
typedef struct msg_struct {
long type; // 消息类型(必须 > 0)。就像包裹上的“类别标签”
char msg[MAXLEN]; // 实际携带的数据(比如 "Hello")
} msg_t;-
精髓:
type这个东西非常实用。比如你可以定义type=1是控制指令,type=2是数据文件。接收方可以指定只接收type=1的消息。
2. P0(发送者)的流程:
msg_t msg;
msg.type = 1; // 假设我要发一个类型为 1 的消息
strcpy(msg.msg, "Hello from P0");
// 创建/获取消息队列 ID(标识符 1234)
int mqid = msgget(1234, 0777 | IPC_CREAT);
// 发送消息!
// 参数:队列ID, 消息指针, 消息结构体大小, 0(表示阻塞发送)
msgsnd(mqid, &msg, sizeof(msg_t), 0);
// 发送完,删除队列(释放内核资源)
msgctl(mqid, IPC_RMID, NULL); 3. P1(接收者)的流程:
msg_t msg; // 准备一个空的接收容器
// 消息队列 P0 已经建好了,P1 这边只要知道门牌号 1234 就能打开它
int mqid = msgget(1234, 0777);
// 接收消息!
// 参数:队列ID, 接收容器, 结构体大小, 0(只接收类型为 0 的消息,即接收任意类型)
msgrcv(mqid, &msg, sizeof(msg_t), 0, 0);
// 打印接收到的数据
printf("Received: %s", msg.msg);共享内存 最快的IPC机制
Linux提供的地址空间共享机制,可以使两个地址空间之间共享一段物理内存(虚拟地址未必要一致)。内核不再介入数据传递(所以快)。
为什么要他?
消息队列需要两次拷贝,陷入内核态。
-
物理内存的“映射”:正常情况下,进程 A 和 进程 B 的内存是隔离的。但是通过
shmget和shmat,操作系统会在物理内存条上划出一块区域,把这块物理内存同时映射到进程A和进程B的逻辑地址空间中。 -
零拷贝(Zero-Copy):
-
在消息队列和管道中,数据需要经历:用户A -> 内核缓冲区 -> 用户B(两次内存拷贝)。
-
在共享内存中,进程A 直接往物理内存地址写数据,进程B 直接从同一个物理内存地址读数据。没有经过内核的搬移,这就是极速的源泉。
-

代码逐行解析(P0 和 P1 怎么打通房间)
注意看底部的代码,这比消息队列简单得多,核心就是几个指针的操作。
1. 准备工作(通常在 P0 中执行)
int shmid;
// 申请一块 key=1234, 大小为 1024 字节的物理共享内存
shmid = shmget(1234, 1024, 0777 | IPC_CREAT); 2. P0 和 P1 分别“上墙”(挂载到自己的地址空间)
// P0 执行:把物理内存映射到 P0 的内存中,返回一个指针 ptr
char* ptr = shmat(shmid, NULL, 0);
// P1 执行(代码里的 `<SAME AS P0>` 就是这个意思):
// P1 也拿着同一个 shmid,挂载到自己的内存空间
char* ptr = shmat(shmid, NULL, 0);-
重点理解:P0 里面的
ptr和 P1 里面的ptr,它们指向的虚拟地址数值很可能不同(比如 P0 是0x7f1a...,P1 是0x5c3b...)。 -
但它们指向的底层物理内存地址是同一个!(就像两个门牌号不同,但都通往同一个房间)。
3. 真正的通信(在 ... 省略的部分)
由于 ptr 已经指向了同一块物理内存,所以通信变得极简:
-
进程 P0 写数据:直接执行
sprintf(ptr, "Hello from P0");。 -
进程 P1 读数据:P1 直接执行
printf("%s", ptr);。 -
数据被“直达”了,没有内核介入,没有内存拷贝!
4. 收尾工作(解除和销毁)
// P0 和 P1 分别解除映射
shmdt(mqid);
// 真正的销毁(一般在所有进程都用完后,由其中一个进程执行)
shmctl(mqid, IPC_RMID, NULL); 问题一 为什么管道一般不用于跨线程通信?
管道有系统开销需要进入内核。用共享变量会更好。(除了共享变量,其他的IPC都要cp2次)
问题二 为什么线程迁移虽然跨进程,但不跨线程?
线程是在不同的进程中游走不是自己在自己身上变。
代码细节 编程题考虑
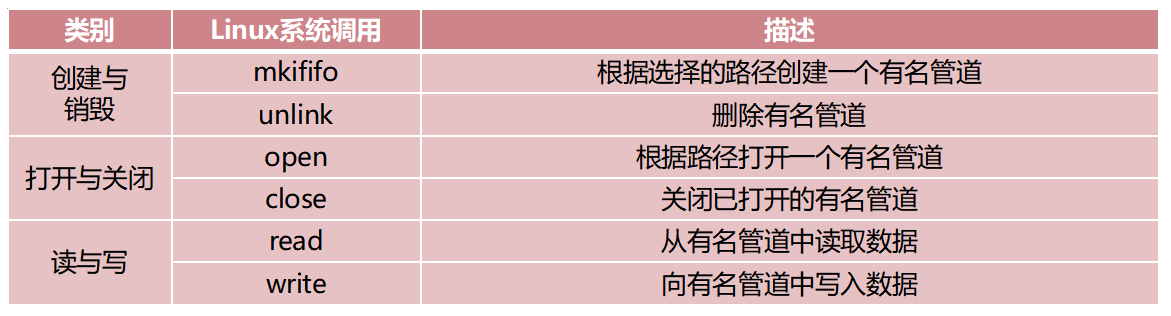
一、 有名管道 (Named Pipe / FIFO)
特点:通过文件系统中的特殊文件(路径名)进行通信,无血缘关系的进程也可使用。
1. mkfifo
-
英文全称:Make FIFO (First In First Out)
-
中文翻译:创建有名管道
-
函数原型:
int mkfifo(const char *pathname, mode_t mode); -
参数详解:
-
pathname:管道在文件系统中的绝对或相对路径(如"/tmp/myfifo")。 -
mode:文件的权限模式,如0777(表示所有用户都可读写执行)。
-
-
图中案例:
mkfifo("/tmp/myfifo", 0777);
2. unlink
-
英文全称:Unlink
-
中文翻译:删除/移除目录项(取消文件链接)
-
函数原型:
int unlink(const char *pathname); -
参数详解:
-
pathname:要删除的文件路径。
-
-
图中案例:
unlink("/tmp/myfifo");(注意:如果进程依然持有该文件的fd,文件实体需等到所有进程都关闭fd后才会真正销毁)。
3. open / close
-
英文全称:Open / Close
-
中文翻译:打开文件 / 关闭文件
-
函数原型:
int open(const char *pathname, int flags);/int close(int fd); -
参数详解:
-
flags:打开模式。O_WRONLY(只写),O_RDONLY(只读)。
-
-
图中案例:
-
写者:
fd = open("/tmp/myfifo", O_WRONLY); -
读者:
fd = open("/tmp/myfifo", O_RDONLY);
-
4. read / write
-
英文全称:Read / Write
-
中文翻译:读取 / 写入
-
函数原型:
ssize_t read(int fd, void *buf, size_t count);/ssize_t write(int fd, const void *buf, size_t count); -
参数详解:
-
fd:之前open返回的文件描述符。 -
buf:用于存放数据的缓冲区指针。 -
count:期望读取或写入的字节数。
-
-
图中案例:
-
写者:
write(fd, buf, len); -
读者:
len = read(fd, buf, max);
-
二、 信号量 (Semaphore) — 跨进程版 (System V / POSIX)
特点:不仅可用于线程同步,通过 sem_open 或共享内存 sem_init 也可用于进程间同步。这里展示的是 POSIX 无名信号量(通过共享内存跨进程)。
1. sem_init
-
英文全称:Semaphore Initialize
-
中文翻译:初始化信号量
-
函数原型:
int sem_init(sem_t *sem, int pshared, unsigned int value); -
参数详解:
-
sem:指向信号量变量的指针。 -
pshared:跨进程关键参数。0表示线程间共享(同一进程);非0表示进程间共享(必须在共享内存区域中)。 -
value:信号量的初始值(计数器初始数值)。
-
-
图中案例:
sem_init(&semaphore, 0, 0);(初始值为0,表示一开始没资源,常用于事件通知,生产者发信号前,消费者必须阻塞)。
2. sem_wait
-
英文全称:Semaphore Wait
-
中文翻译:P操作,获取信号量(阻塞式)
-
函数原型:
int sem_wait(sem_t *sem); -
参数详解:
-
sem:指向信号量的指针。
-
-
案例/原理:将计数器减 1。如果值大于 0,直接返回;如果值为 0,线程阻塞,直到计数器被
sem_post增大。
3. sem_trywait
-
英文全称:Semaphore Try Wait
-
中文翻译:获取信号量(非阻塞式)
-
函数原型:
int sem_trywait(sem_t *sem); -
参数详解:同
sem_wait。区别在于,如果计数器为 0,不阻塞,立刻返回错误。
4. sem_timedwait
-
英文全称:Semaphore Timed Wait
-
中文翻译:获取信号量(带超时)
-
函数原型:
int sem_timedwait(sem_t *sem, const struct timespec *abs_timeout); -
参数详解:多了一个
abs_timeout(绝对时间点)。如果在超时前没有获得资源,系统会唤醒线程并返回超时错误。
5. sem_post
-
英文全称:Semaphore Post
-
中文翻译:V操作,释放/发送信号量
-
函数原型:
int sem_post(sem_t *sem); -
参数详解:
-
sem:指向信号量的指针。
-
-
案例/原理:将计数器加 1。如果有线程正在
sem_wait上阻塞,系统会唤醒其中一个。
6. sem_destroy
-
英文全称:Semaphore Destroy
-
中文翻译:销毁信号量
-
函数原型:
int sem_destroy(sem_t *sem); -
参数详解:
-
sem:指向信号量的指针。
-
-
图中案例:
sem_destroy(&semaphore);
三、 消息队列 (Message Queue) — System V
特点:以“数据包”形式传递,自带类型 (type),支持多对多通信,无需担心写交叉(包裹有边界)。
1. msgget
-
英文全称:Message Queue Get
-
中文翻译:获取/创建消息队列
-
函数原型:
int msgget(key_t key, int msgflg); -
参数详解:
-
key:消息队列的唯一标识键值(如1234),不同进程通过同一个key找到同一个队列。 -
msgflg:权限标志。通常用0777 | IPC_CREAT表示如果不存在就创建。
-
-
图中案例:
int mqid = msgget(1234, 0777 | IPC_CREAT);
2. msgsnd
-
英文全称:Message Queue Send
-
中文翻译:发送消息
-
函数原型:
int msgsnd(int msqid, const void *msgp, size_t msgsz, int msgflg); -
参数详解:
-
msqid:由msgget返回的队列 ID。 -
msgp:指向消息结构体的指针。该结构体必须以long type开头。 -
msgsz:结构体中除type外的数据部分的大小。 -
msgflg:发送标志,0表示队列满时阻塞;IPC_NOWAIT表示非阻塞。
-
-
图中案例:
msgsnd(mqid, &msg, sizeof(msg_t), 0);
3. msgrcv
-
英文全称:Message Queue Receive
-
中文翻译:接收消息
-
函数原型:
ssize_t msgrcv(int msqid, void *msgp, size_t msgsz, long msgtyp, int msgflg); -
参数详解:
-
msqid:队列 ID。 -
msgp:接收缓冲区结构体指针。 -
msgsz:接收数据的最大长度。 -
msgtyp:接收类型选择。0接收队列中第一条消息;>0接收该类型的第一条;<0接收小于该绝对值的最小类型。 -
msgflg:接收标志,0表示队列空时阻塞;IPC_NOWAIT表示非阻塞。
-
-
图中案例:
msgrcv(mqid, &msg, sizeof(msg_t), 0, 0);
4. msgctl
-
英文全称:Message Queue Control
-
中文翻译:控制/删除消息队列
-
函数原型:
int msgctl(int msqid, int cmd, struct msqid_ds *buf); -
参数详解:
-
msqid:队列 ID。 -
cmd:控制指令。IPC_RMID表示立即删除该消息队列(回收内核资源)。 -
buf:用于获取或设置队列属性的结构体指针。设置为NULL用于删除。
-
-
图中案例:
msgctl(mqid, IPC_RMID, NULL);
四、 共享内存 (Shared Memory) — System V
特点:最快的 IPC,无需内核介入数据拷贝(零拷贝)。但需要程序员通过信号量或锁自行控制同步。
1. shmget
-
英文全称:Shared Memory Get
-
中文翻译:获取/创建共享内存块
-
函数原型:
int shmget(key_t key, size_t size, int shmflg); -
参数详解:
-
key:共享内存的唯一标识(如1234)。 -
size:申请共享内存的大小(字节),如1024。 -
shmflg:权限标志,如0777 | IPC_CREAT。
-
-
图中案例:
int shmid = shmget(1234, 1024, 0777 | IPC_CREAT);
2. shmat
-
英文全称:Shared Memory Attach
-
中文翻译:挂载/映射共享内存到进程地址空间
-
函数原型:
void *shmat(int shmid, const void *shmaddr, int shmflg); -
参数详解:
-
shmid:由shmget返回的 ID。 -
shmaddr:指定挂载的虚拟地址。通常填NULL,让操作系统自动分配合适的位置。 -
shmflg:挂载标志,0表示可读写;SHM_RDONLY表示只读。
-
-
图中案例:
char* ptr = shmat(shmid, NULL, 0);(成功后ptr指向共享内存区域)。
3. shmdt
-
英文全称:Shared Memory Detach
-
中文翻译:解除映射
-
函数原型:
int shmdt(const void *shmaddr); -
参数详解:
-
shmaddr:以前shmat返回的指针地址。解除映射后,不能再通过该指针访问该块内存。
-
-
图中案例:
shmdt(ptr);
4. shmctl
-
英文全称:Shared Memory Control
-
中文翻译:控制/删除共享内存
-
函数原型:
int shmctl(int shmid, int cmd, struct shmid_ds *buf); -
参数详解:
-
shmid:共享内存 ID。 -
cmd:控制指令。IPC_RMID表示标记删除该共享内存(所有进程shmdt后真正释放)。
-
-
图中案例:
shmctl(mqid, IPC_RMID, NULL);(注:图中代码此处变量名写成了mqid,实为shmid,逻辑相同)。

openEuler 是由开放原子开源基金会孵化的全场景开源操作系统项目,面向数字基础设施四大核心场景(服务器、云计算、边缘计算、嵌入式),全面支持 ARM、x86、RISC-V、loongArch、PowerPC、SW-64 等多样性计算架构
更多推荐

 8
8 0
0- 0



 已为社区贡献17条内容
已为社区贡献17条内容

所有评论(0)