大模型术语:小白程序员必备的六层工程分层架构(收藏版)
本文通过构建AI Agent的六层工程分层架构,深入解析了Token、LLM API、幻觉缺陷、RAG、Function Calling、MCP、Agent核心、ReAct循环、反思机制、Skill、SDD和Harness等关键术语的工程本质。从物理原子层Token到环境操作系统层Harness,为开发者提供了一套清晰的AI应用落地框架,旨在消除术语焦虑,提升大模型应用开发能力。

在前两期中,我们梳理了大模型从象牙塔到平民基建的十年范式更迭,也解构了为什么命令行终端正在成为 AI 编程的终局战场。
基建有了,操控界面也有了。但摆在大多数开发者面前的现实障碍,不是技术能力不够,而是 AI 领域满天飞的术语构成了一道高昂的“认知税”。
从 2024 年的 RAG、Function Calling,到 2025 年百花齐放的 Agent,再到 2026 年突然火热的 MCP、SDD、Skill 和 Harness。大量新名词不断涌现,许多开发者陷入了名词焦虑:这些概念之间到底是什么关系?哪些是底座,哪些是外挂?是颠覆性的新发明,还是老技术换了一层皮?
本篇的目标是为开发者画一张概念知识地图。我们拒绝抽象的哲学定义,而是将这些名词整理进一套六层工程分层架构中。从最底层的物理 Token,到顶层的 Harness 操作系统,一次性把所有核心术语的工程本质讲清楚。
AI Agent 的六层工程分层架构
正如现代软件工程有 OSI 七层网络模型和经典的系统分层架构,AI 应用的落地在工程上也已经分化出了清晰的六层架构。
我们将所有的核心术语映射到这六层架构中:
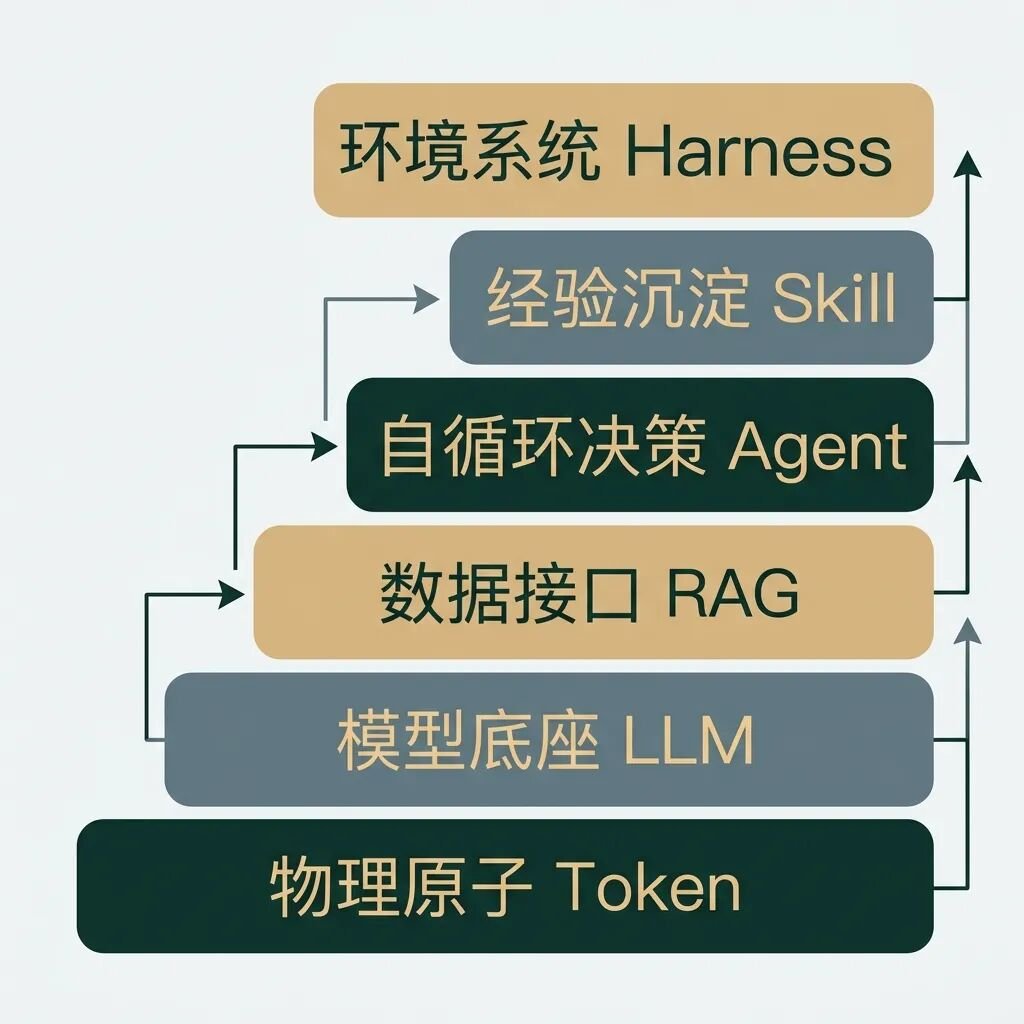
下面,我们由底向上,逐层剥离这些概念的学术外衣,还原它们的工程本质。
第一层:物理原子层 —— Token(词元)
一切大模型推理与计算的物理终点,都是 Token。
对于大语言模型来说,它根本不认识中文,也不认识英文,它只认识数字。因此,要让大模型处理输入,必须有一种方式把原始文本转换为数字。
这就是分词器(Tokenizer)所做的事情。分词器按照特定的分词算法(如 BPE 算法)把输入的文本切分为多个最小语义单元(即 Token),然后用一个数字 ID 来表示这个 Token。后续大模型的矩阵计算与推理,都是基于这些数字 ID 来进行的。
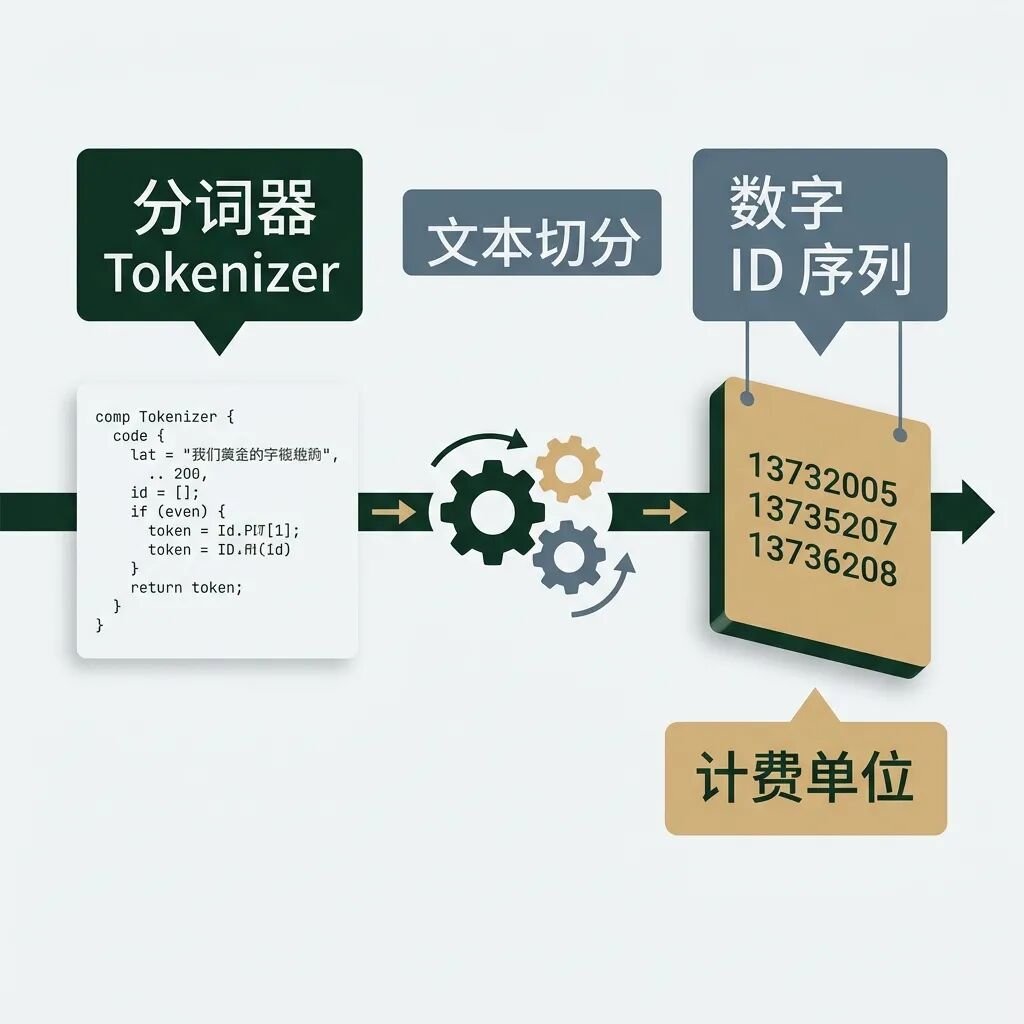
从工程视角看,Token 带来了三个极其显眼的工程约束:
-
Token 经济学:大模型 API 的输入(Prompt)和输出(Completion)是按 Token 数量计费的。类比于网络带宽按字节流量收费,请求体越庞大、响应体越长,费用就呈线性或指数级上升。
-
上下文窗口(Context Window)限制:每个模型能接收的最大数字 ID 序列是有限的(如 8K、128K 或 1M)。一旦超过这个物理限制,模型就会发生内存溢出(OOM)或者直接遗忘最早的输入。
-
分词退化隐形灾难:在代码生成或处理多语言文本时,Tokenizer 常常会发生分词退化。例如,代码中的泛型符号 List、多重转义符 /n/t 或不常见的中文生僻词,分词器无法将其识别为完整语义词,而是切碎成一堆单字符或乱码 Token。这不仅会导致 Token 消耗量暴增数倍,还会使得模型的推理准确度发生断崖式下跌。
第二层:模型底座层 —— LLM API 与幻觉缺陷
在 Token 之上,是提供核心推理能力的模型底座。
对于工程开发而言,LLM API 本质上就是一个“无状态的远程文本转换服务”。你发一段数字 ID 序列(Token)过去,它经过复杂的注意力机制计算,以流式(SSE)或一次性的方式,返回另一段数字 ID 序列出来。
理解大模型的“无状态性”是构建 AI 系统的核心前提。大模型在服务端没有任何记忆,它不会记住你上一秒对它说了什么。你在聊天界面看到的流畅多轮对话,全部是由客户端把所有历史上下文拼接在一起,在下一次请求时完整重新发送过去的。
在这一层,有两个大模型训练阶段的概念经常被提及:
预训练(Pre-training):这是大模型的“通识教育”。在数万亿 Token 的海量通用数据上进行自监督训练,核心任务非常单纯:根据前文不断预测下一个 Token。这训练出了模型的基座(Base Model)。
微调(Fine-Tuning):这是模型的“岗前业务培训”。在已经受过通识教育的基座模型上,使用规模较小(如几千条)的高质量针对性数据继续训练,调整部分权重参数,使模型在特定任务格式、敏感词过滤或垂直领域黑话(如医疗、金融术语)上输出概率更加符合预期。

工程红线:不可消灭的“幻觉”
无论微调得多么完美,大模型在本质上都只是基于统计概率输出下一个 Token,这决定了它天生自带一个致命 Bug:幻觉(Hallucination)。它会在置信度完全不足时,以极度自信、一本正经的语气编造事实。
后续所有高层工程方案(RAG、Function Calling、Agent、Harness 等)的统一出发点,不是为了消灭幻觉,而是为了约束、控制并增强这个有幻觉的无状态接口。
第三层:数据与接口外挂层 —— RAG、Function Calling 与 MCP
由于底座模型具有无状态和幻觉缺陷,且训练数据具有截止日期,我们必须在 API 之外为其挂载辅助系统。这就是外挂层。
1. RAG(检索增强生成)—— 开卷考试
RAG(Retrieval-Augmented Generation)的工程本质极其朴素:先查库,再回答。
既然大模型不知道你的私有数据,那我们就不让它凭空脑补。在调用 LLM 之前,先去你的私有知识库检索出与用户问题最相关的背景资料,拼进 Prompt 发给模型,强迫它“根据以下参考资料回答问题”。

经典的 RAG 包含四个核心阶段:
切片(Chunking):将海量文档切成小文本块,相邻块保留重叠区以防止信息被切断。
向量化(Embedding):把切片通过 Embedding 模型转为向量,存入向量数据库(如 pgvector、Milvus)。
检索与重排(Retrieve & Rerank):根据用户提问的向量相似度,召回最相关的 Top-K 切片,并用 Rerank 模型进行精准的二次排序。
生成(Generate):将最相关的文本拼入 Prompt,交给大模型做总结和格式化输出。
2. Function Calling(函数调用)—— 动态路由器
如果说 RAG 给了大模型看资料的“眼睛”,Function Calling 则给了大模型做事情的“双手”。
一个极其重要的工程事实:大模型自己不执行任何代码,它只负责输出结构化的 JSON 描述。
大模型在 Function Calling 中扮演的是“意图解析器”和“接口路由器”。开发者向模型注册可用工具列表,用户输入指令后,大模型自动判断应该调用哪个函数、需要哪些参数,并输出一个包含函数名和参数值的 JSON 对象。最后,由开发者编写的后端代码去执行真实操作。
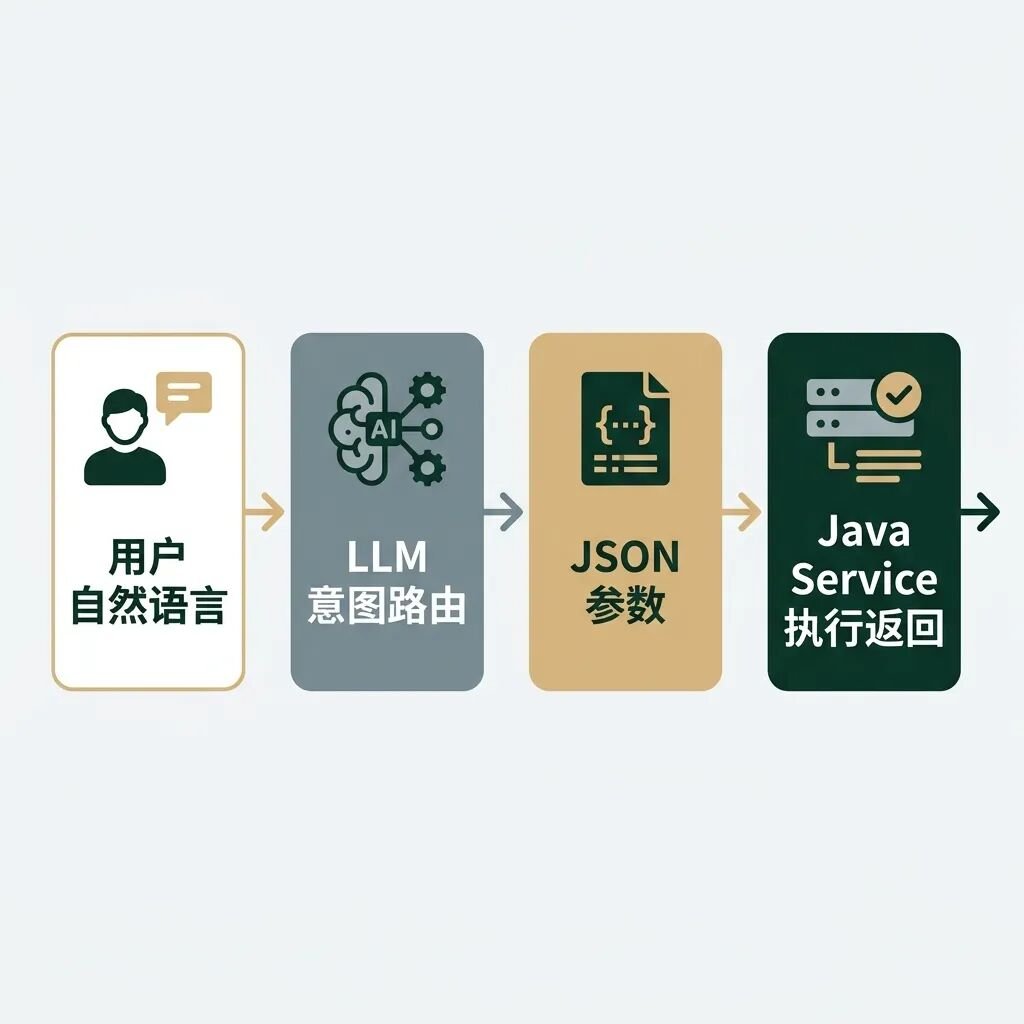
安全警示:由于幻觉存在,大模型完全可能输出带有注入攻击字符或完全非法的 JSON 参数。后端服务必须对大模型生成的 JSON 进行严格的参数校验、类型拦截,并把涉及文件读写、数据库修改的操作放进受限沙箱中运行,严禁直接执行。
3. MCP(模型上下文协议)—— AI 应用的“Type-C 接口”
在 2025 年末,Anthropic 提出了 MCP(Model Context Protocol,模型上下文协议),迅速成为行业标准。
在 MCP 出现前,如果你有三个不同的 Agent(写代码的、查数据库的、管日程的),你必须为每个 Agent 重复编写读取本地文件、查询 Slack 或操作 GitHub 的接口代码。Agent 数量和工具数量呈 M * N 的网状复杂度。
MCP 协议的核心本质是解耦了 AI 应用与外部数据/工具的连接,将复杂度降为 M + N。
MCP 采用了类似客户端-服务端(Client-Server)的经典架构:
MCP Server:数据和工具的提供者(如 Postgres-Server、Git-Server、Filesystem-Server),通过统一的 JSON-RPC 2.0 协议向外暴露 Resources(数据源)、Prompts(提示词模板)和 Tools(可调用函数)。
MCP Client:大模型 Agent 应用。它只需要实现一个 MCP Client 接口,就能无缝连接世界上任何一个现成的 MCP Server。
MCP 就像是 AI 时代的 Type-C 接口标准。只要双方都遵循这个协议,大模型就能随时插拔任何外部工具与数据源。
第四层:自循环决策层 —— Agent 核心、ReAct 与反思机制
在拥有了外挂数据和标准化工具后,大模型终于可以摆脱“一问一答”的被动响应模式,晋升为能够自主推进任务的 Agent(智能体)。
从工程定义上看,Agent 是以大模型为核心,具备规划(Planning)、记忆(Memory)和工具调用能力,能够自主拆解复杂任务并持续运行直至任务闭环的计算实体。
Agent 与 Function Calling 的层级关系一目了然:Function Calling 是 Agent 的“双手”,Agent 是 Function Calling 的“大脑”。
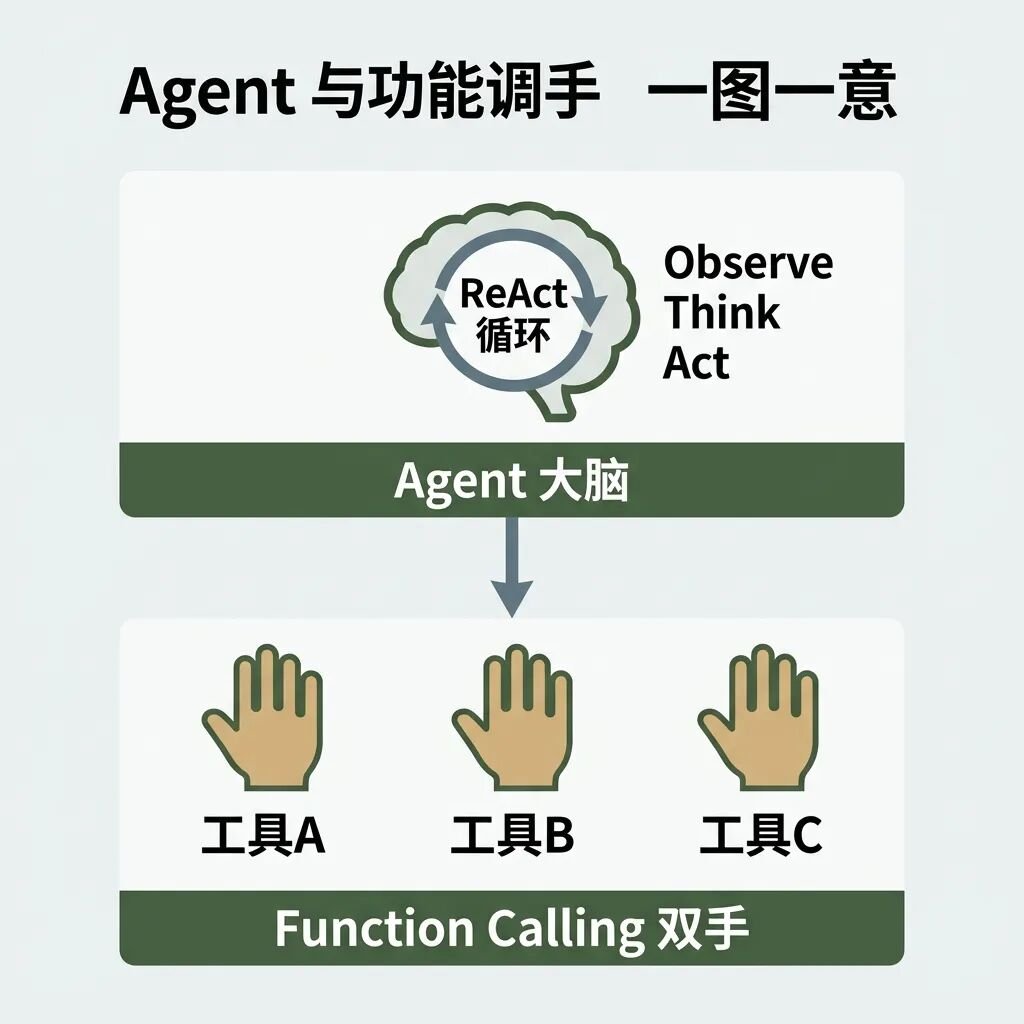
1. ReAct 自循环
Agent 驱动任务的核心机制是 ReAct 循环(Reasoning + Acting):
[开始] ──> Observe (观察环境/输入) ──> Think (推理下一步) ──> Act (调用工具) ──> Observe (拿回结果) ──> [判断是否闭环]
当用户输入一个模糊的指令(如“修复项目中的 NPE 异常”),Agent 会进入 ReAct 循环:
-
Think:我需要定位异常发生的位置。
-
Act:调用 grep 查找 NPE 关键字。
-
Observe:拿到文件路径和行号。
-
Think:我需要查看该文件的代码内容。
-
Act:调用 read_file 读取对应代码段。
-
Observe:发现变量未做非空校验。
-
Think:我需要编写补丁并验证。
-
Act:调用 modify_file 修改代码并执行 Maven 测试。
-
Observe:测试通过,任务完成。
2. 记忆系统(Memory)
为了在多轮 ReAct 中保持状态,Agent 的记忆系统在工程上通常被分为两层:
短期记忆(Short-term Memory):用于当前会话。由于上下文窗口限制,通常采用滑动窗口截断或历史对话摘要(Summary)的方式,在保留语义连贯性的前提下,主动压缩 Prompt 长度。
长期记忆(Long-term Memory):用于跨会话场景。Agent 会自动将历史会话的关键决策、用户习惯转化为知识摘要存入向量库。在新会话启动时,根据当前意图做向量检索召回,按需注入上下文。
3. 反思与反馈机制(Self-Reflection)
反思是 Agent 摆脱盲目循环、实现自我纠错的关键。反思机制在本质上就是“生成后再评估,根据反馈修正结果”。工程上主要分为两类:
自我反馈(Self-Feedback):大模型自己充当裁判,审查自己刚刚输出的文本或代码。例如:检查是否满足字数限制、是否遵循了格式约束、有没有意外改动不该改的内容。
外部反馈(External Feedback):不相信模型的自我审查,而是把结果放入真实物理环境中运行。例如:直接调用编译器编译生成的代码,运行单元测试查看结果,或者使用 JSON Schema 校验生成的 JSON 是否合规。外部事实反馈是防范 Agent 逻辑死锁与幻觉滑坡的终极防线。
4. 三道安全熔断机制
由于 Agent 具有自我循环能力,一旦发生异常很容易陷入无休止的“思考-行动”黑洞,导致费用失控。工程上必须在自循环决策层强制安装三道保险:
最大迭代次数(Max Iterations):例如强制限制单次任务最大循环 30 次,超出则必须暂停并向人类请求协助。
Token 费用熔断:单次任务累计消耗 Token 金额达到阈值(如 $5),立即触发硬熔断。
死锁与无用功检测:如果 Agent 连续 3 轮执行完全相同的 Action 且返回相同的 Error,或者在两个状态间反复横跳,判定为逻辑死锁,强制退出。
第五层:经验沉淀层 —— Skill(技能包)与 SDD(规格驱动开发)
当大模型具备了自主循环的能力后,企业在实际工业落地中很快遇到了新的挑战:如何让 Agent 的行为变得规范、可控,并能沉淀为企业的数字资产?
这促成了经验沉淀层的诞生。
1. Skill(技能包)—— 结构化任务经验包
正如前文提到的,Anthropic 研究员在 2026 年提出了一个变革性的观点:与其为每一个任务单独写一个 Agent,不如打造一个通用的 Agent,并为它装载不同的 Skill。
通用 Agent 提供基础的 ReAct 循环、文件操作、终端访问等底层 Harness 能力;而 Skill 则决定了 Agent 会做什么。
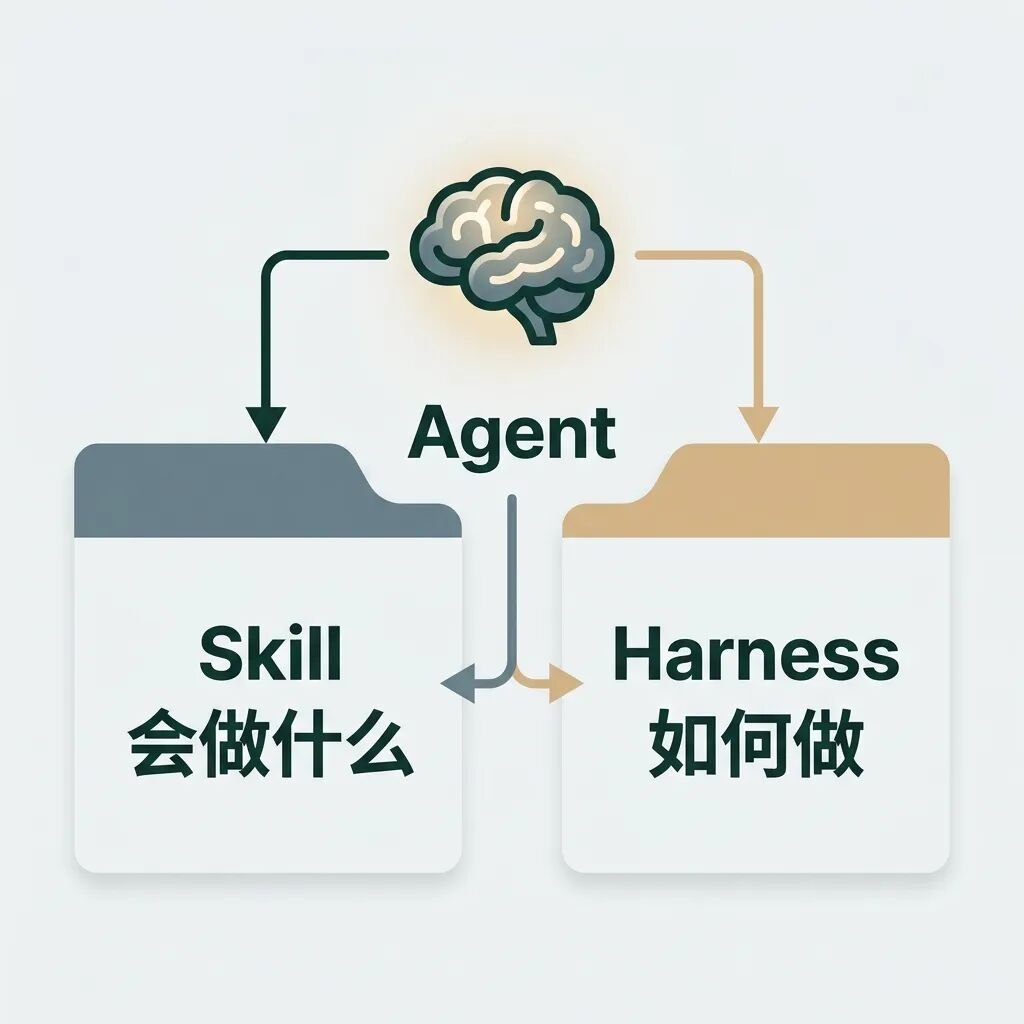
在工程实现上,一个 Skill 本质上就是一个结构化的本地文件夹。它将特定领域的 SOP(标准作业程序)和最佳实践进行了显式封装:
skill.md(主说明文件):告诉通用 Agent 遇到这类任务时该遵循什么逻辑。
rules/(流程与规则约束):细化的执行边界与安全红线。
examples/(One-shot/Few-shot 示例):告诉 Agent 好的输出长什么样,坏的输出长什么样。
scripts/(辅助小工具):提升 Agent 执行效率的本地脚本。
例如,一个企业可以拥有“SQL 注入漏洞修复 Skill”、“bug 修复处理Skill”等。遇到不同任务,Agent 挂载不同的 Skill 目录,就能立即以极高的标准执行任务。这使得 AI 的能力可以随着 Skill 的不断迭代而持续沉淀。
2. SDD(规格驱动开发)—— 契约化上下文管理
SDD(Spec-Driven Development,规格驱动开发) 是在正式编码之前,将模糊的用户意图彻底转化为稳定、具体工程上下文的一种设计模式。
如果你直接对 Agent 说“帮我把项目重构一下”,大模型会因为上下文太空泛而开始猜测需求,接着开始大面积修改代码,最后导致大量 Regression(回归 Bug)。
在 SDD 模式下:
-
在编码前,人与 AI 协作,先写出一份极其详细的 Specification(规格文档),明确写清楚:变更的目标、变更的范围、系统交互行为的改变、修改哪些具体文件、必须保留的历史逻辑以及任务的具体拆分步骤。
-
规格文档定稿后,再让 AI 严格按照这份规格去写代码。
通过这一契约,模糊的“自然语言意图”在第五层被过滤并固化为“规格上下文”。AI 只需要按图索骥去编码,极大地避免了实现跑偏、引入意外 Bug 或改坏历史代码的问题。
第六层:环境操作系统层 —— Harness 工程(驾驭工程)
在最顶层,是包容并控制一切的 Harness 工程。
业界在 2026 年达成了一个广泛的共识:
If you’re not the model, you’re the harness.(在 Agent 应用中,除了大模型本身,剩下的一切工作都是 Harness。)
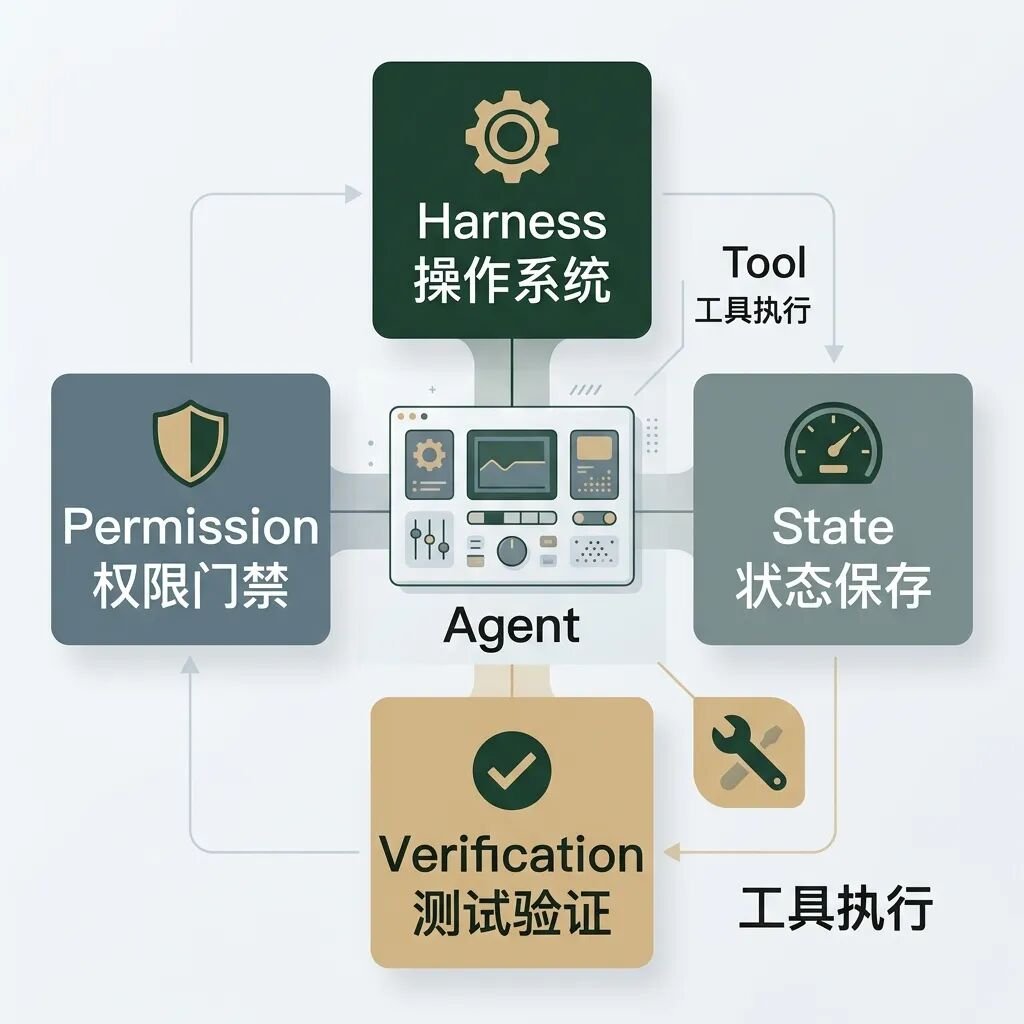
Harness(驾驭工程/运行控制框架)是 Agent 真正能够运行的操作系统。模型提供了推理,但 Harness 提供了生存的物理世界与控制律。
一个标准的 Harness 工程必须为 Agent 提供以下系统级支持:
| Harness 组件 | 物理实现与作用 |
|---|---|
| Tool Execution | 提供运行 Shell 命令的终端、隔离的 Docker 沙箱、Git 版本库、浏览器等物理环境。 |
| Context Management | 自动向模型注入必要的环境背景信息(如 README、AGENTS.md 约束、当前目录树结构)。 |
| State Tracking | 追踪任务进度的状态机。即使程序崩溃或网络中断,也能重新加载状态继续执行,而不是重新开始。 |
| Permission Gate | 权限门禁。敏感操作(如 git push、rm -rf、写大文件、网络请求)必须拦截并等待人类输入 Y/N 确认。 |
| Verification Loop | 验证回路。当 Agent 宣称完成任务时,Harness 自动运行 Maven Clean Build / Linter / Unit Test 检验真伪。 |
| Observer Logging | 日志观测。完整记录 Agent 的思考过程(Thought)、行动(Action)及报错,用于事后回溯与重放。 |
为什么 Harness 在 2026 年成为了竞争焦点?因为行业逐渐发现:拼模型参数的红利期正在过去,在相同模型底座下,Harness 做得差,Agent 成功率不到 20%;Harness 做到极致,成功率可以飙升到 80% 以上。 决定 AI 能否在真实生产环境中落地的,正是这套“操作系统”的工程质量。
六层架构全局速查表
我们将这六个层次及其代表的术语,用一张全景映射表做一次最终的工程脱水:
| 分层 | 术语 | 一句话本质 | 工程实践意义与边界 |
|---|---|---|---|
| 第一层:物理原子 | Token | 数字 ID 词元 | 推理和计费的物理原子单元;警惕代码转义带来的分词退化灾难。 |
| 第二层:模型底座 | LLM API | 无状态远程 RPC | 文本转换服务,天生自带幻觉 Bug;后续所有工程都是为了对其进行约束和增强。 |
| Fine-Tuning | 岗前格式微调 | 调整权重使其输出更符合特定格式/风格;大部分场景 Prompt+RAG 表现更优。 | |
| 第三层:数据接口 | RAG | 开卷检索生成 | 先用向量/全文检索查资料,再拼接成 Prompt 提交;解决私有数据盲区。 |
| Function Calling | 动态接口路由 | 大模型扮演网关路由器,输出 JSON 指令;后端必须设立严格的沙箱与校验红线。 | |
| MCP | AI 版 Type-C 接口 | 标准化的模型上下文协议,实现 Agent 应用与外部工具/数据源的插拔解耦。 | |
| 第四层:自循环决策 | Agent | 自循环 Worker | 具备规划、记忆与工具调用的自主闭环运行实体。 |
| ReAct | 推理-行动循环 | Think-Act-Observe 的状态机自循环,直至满足任务退出条件。 | |
| 反思机制 | 生成后评估修正 | 分为自我反馈与外部反馈;外部编译和测试反馈是防范逻辑失控的硬核防线。 | |
| 第五层:经验沉淀 | Skill | 结构化经验包 | 文件夹形式的领域 SOP 封装,让通用 Agent 快速装备并化身为专业领域专家。 |
| SDD | 规格契约开发 | 在编码前用规格文档锁定任务边界和拆分,防止 AI 因上下文模糊而盲目猜需求。 | |
| 第六层:环境系统 | Harness | Agent 操作系统 | 除了模型外的一切,包括沙箱环境、权限拦截、状态追踪与自动测试校验。 |
结语
从物理原子的 Token,到作为操作系统的 Harness,这六层架构画出了当前 AI 应用从底层推理到上层系统工程的完整坐标系。
消除名词焦虑的最好方法是看清其物理本质。你会发现,AI 工程的落地,并不是一门全新的玄学,其核心难点依然是我们熟悉的那套东西:接口的安全防线如何构建、网络通信的开销如何降低、复杂的状态机如何维护、系统的权限与沙箱如何隔离、SOP 与设计契约如何落地。
大模型提供了一个有幻觉的大脑,而我们后端工程师真正的舞台,恰恰是为这个大脑穿上盔甲、接入神经,构建一个坚固、安全且规范的 Harness 物理世界。
最后
如果说程序员已经是高薪职业,那么干AI的程序员,就是高薪中的高薪。
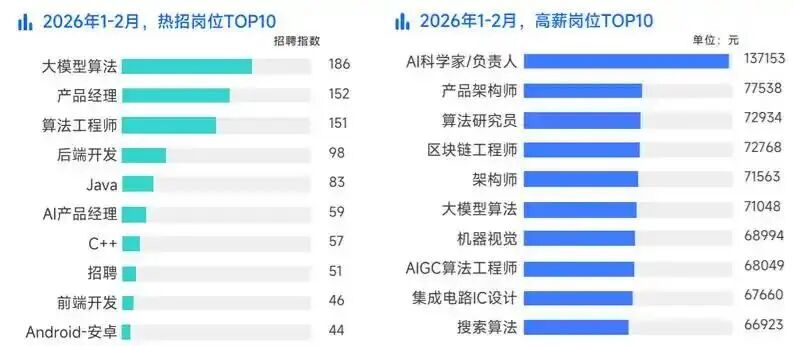
现在的市场,已经用数据给程序员指明了方向:学AI大模型,就是冲刺高薪的最优解!
看着身边越来越多的同行转型大模型、拿到高薪offer,很多人心里都动了心,但真正的难题来了:零基础小白不知道从哪入门?有基础的程序员找不到系统学习路径?实战项目练手无门?面试不知道考什么?
别慌!今天就给大家整理了一份【2026年最新版】AI大模型免费学习资源包,覆盖从入门到实战、从理论到面试、从基础到进阶的全流程,所有资料均已整理归档,无冗余、无套路,免费分享给每一位想抓住AI风口的程序员和小白!
👇👇扫码免费领取全部内容👇👇

1、大模型系统化学习路线
2、大模型学习书籍&文档

3、AI大模型最新行业报告

4、大模型项目实战&配套源码

5、大模型大厂面试真题

四阶段精细化学习规划(附时间节点,可直接照做)
结合上述资源,给大家整理了一份可直接落地的四阶段学习规划,总时长约2个月,小白可循序渐进,程序员可根据自身基础调整节奏,高效掌握大模型核心能力,快速实现从“入门”到“能落地、能面试”的跨越。
第一阶段(10天):初阶应用
该阶段让大家对大模型 AI有一个最前沿的认识,对大模型 AI 的理解超过 95% 的人,可以在相关讨论时发表高级、不跟风、又接地气的见解,别人只会和 AI 聊天,而你能调教 AI,并能用代码将大模型和业务衔接。
- 大模型 AI 能干什么?
- 大模型是怎样获得「智能」的?
- 用好 AI 的核心心法
- 大模型应用业务架构
- 大模型应用技术架构
- 代码示例:向 GPT-3.5 灌入新知识
- 提示工程的意义和核心思想
- Prompt 典型构成
- 指令调优方法论
- 思维链和思维树
- Prompt 攻击和防范
- …
第二阶段(30天):高阶应用
该阶段我们正式进入大模型 AI 进阶实战学习,学会构造私有知识库,扩展 AI 的能力。快速开发一个完整的基于 agent 对话机器人。掌握功能最强的大模型开发框架,抓住最新的技术进展,适合 Python 和 JavaScript 程序员。
- 为什么要做 RAG
- 搭建一个简单的 ChatPDF
- 检索的基础概念
- 什么是向量表示(Embeddings)
- 向量数据库与向量检索
- 基于向量检索的 RAG
- 搭建 RAG 系统的扩展知识
- 混合检索与 RAG-Fusion 简介
- 向量模型本地部署
- …
第三阶段(30天):模型训练
恭喜你,如果学到这里,你基本可以找到一份大模型 AI相关的工作,自己也能训练 GPT 了!通过微调,训练自己的垂直大模型,能独立训练开源多模态大模型,掌握更多技术方案。
到此为止,大概2个月的时间。你已经成为了一名“AI小子”。那么你还想往下探索吗?
- 为什么要做 RAG
- 什么是模型
- 什么是模型训练
- 求解器 & 损失函数简介
- 小实验2:手写一个简单的神经网络并训练它
- 什么是训练/预训练/微调/轻量化微调
- Transformer结构简介
- 轻量化微调
- 实验数据集的构建
- …
第四阶段(20天):商业闭环
对全球大模型从性能、吞吐量、成本等方面有一定的认知,可以在云端和本地等多种环境下部署大模型,找到适合自己的项目/创业方向,做一名被 AI 武装的产品经理。
- 硬件选型
- 带你了解全球大模型
- 使用国产大模型服务
- 搭建 OpenAI 代理
- 热身:基于阿里云 PAI 部署 Stable Diffusion
- 在本地计算机运行大模型
- 大模型的私有化部署
- 基于 vLLM 部署大模型
- 案例:如何优雅地在阿里云私有部署开源大模型
- 部署一套开源 LLM 项目
- 内容安全
- 互联网信息服务算法备案
- …
👇👇扫码免费领取全部内容👇👇
6、这些资料真的有用吗?
这份资料由我和鲁为民博士(北京清华大学学士和美国加州理工学院博士)共同整理,现任上海殷泊信息科技CEO,其创立的MoPaaS云平台获Forrester全球’强劲表现者’认证,服务航天科工、国家电网等1000+企业,以第一作者在IEEE Transactions发表论文50+篇,获NASA JPL火星探测系统强化学习专利等35项中美专利。本套AI大模型课程由清华大学-加州理工双料博士、吴文俊人工智能奖得主鲁为民教授领衔研发。
资料内容涵盖了从入门到进阶的各类视频教程和实战项目,无论你是小白还是有些技术基础的技术人员,这份资料都绝对能帮助你提升薪资待遇,转行大模型岗位。

这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

openEuler 是由开放原子开源基金会孵化的全场景开源操作系统项目,面向数字基础设施四大核心场景(服务器、云计算、边缘计算、嵌入式),全面支持 ARM、x86、RISC-V、loongArch、PowerPC、SW-64 等多样性计算架构
更多推荐

 4
4 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)