带着问题去探险:亲手“设计”出 Ceph BlueStore
1 问题初现 —— “文件用得好好的为什么要换”
🎯 初始设定:我们有一块普通的硬盘,想在上面存 Ceph 的对象(比如一张图片)。操作系统教我们:先格式化一个文件系统(比如 XFS),然后 open 一个文件,把数据 write 进去。
❓ 灵魂拷问 1:直接用操作系统的文件系统存数据,有什么不对吗?
在早期的ceph(FileStore时代),我们就是这么干的。但运行久了,发现了几个及其别扭的“拧巴”现象:
- 拧巴点一:写 4KB 数据,磁盘写了两次。
为了保证断电不丢数据,必须先写一份Journal日志(AOF),等日志落盘了,再回过头修改XFS的文件。问:这像不像寄快递时,你先在本子上记一笔(日志),再把包裹塞进快递柜(硬盘),结果本子和柜子各占一份空间? - 拧巴点二:修改文件中间的1个字,硬盘忙半天
如果你只改一个对象(文件)中间的 4KB,文件系统没法直接覆盖。你必须把整个对象读出来(Read),改掉那 4KB,再把整个对象写回去(Modify-Write)。问:这不就是“为了换灯泡,把整个房子拆了重建”吗?
2 破局之问 —— “我能不能不要中间商”
❓ 灵魂拷问 2:既然 XFS 这个“中间商”老在中间赚差价(带宽)和添乱,那如果我直接接管这块硬盘,不要文件系统了,行不行?
当然行!操作系统本身就允许我们使用O_DIRECT的方式绕过内核的Page Cache直接write到硬盘的某个扇区(LBA地址)写数据
❓ 灵魂拷问 3:没有了XFS的文件系统,那么对于一个文件路径(/pg1/obj1)就没了。当我收到客户端请求“给我对象obj1”时,我如何具体的对应到硬盘的哪个扇区(偏移量)上呢?
这就需要一张“地图”
- 以前文件系统XFS帮我们维护了这张地图(文件名->inode->磁盘块)
- 现在如果不使用XFS就必须自己维护这张地图
3 分而治之 —— “数据地图存放在哪里?”
❓ 灵魂拷问 4:既然要维护“对象名 -> 磁盘扇区”的映射关系,那这张“地图”本身总得找一个地方存吧?
这里,我们必须把“真正的大块数据(比如 10GB 的电影)”和“记录位置的元数据(比如 10MB 的索引)”分开。
- 数据(Data):大块、大流量。我们直接调用
write丢进硬盘深处的大块连续空间。 - 元数据(Metadata):高频、小块、极其重要。
但是,为什么要分开呢?
- IO 模型不匹配:用户数据(
block)是大块顺序 IO,HDD 擅长这个;但 RocksDB 的元数据是高频随机小块 IO,放在 HDD 上会产生大量机械寻道,导致性能骤降。 - 避免相互干扰:如果混盘,元数据的小 IO 会打断数据的大 IO 流,磁头来回摆动,整体吞吐量会损失 50% 以上,还会引发元数据锁的队头阻塞。
- 成本最优解:用 90% 成本的廉价 HDD 存海量数据,用 10% 成本的高性能 SSD 存敏感元数据,以最低的经济代价撬动最高的集群性能。这本质就是分布式存储里的‘冷热分层’思想。”
总体来说就是,HDD读取速度慢但是成本低,SSD读取速度快但是成本高。让“大块吃肉(顺序读)”和“小块喝汤(随机写)”互不打扰,各自安好。
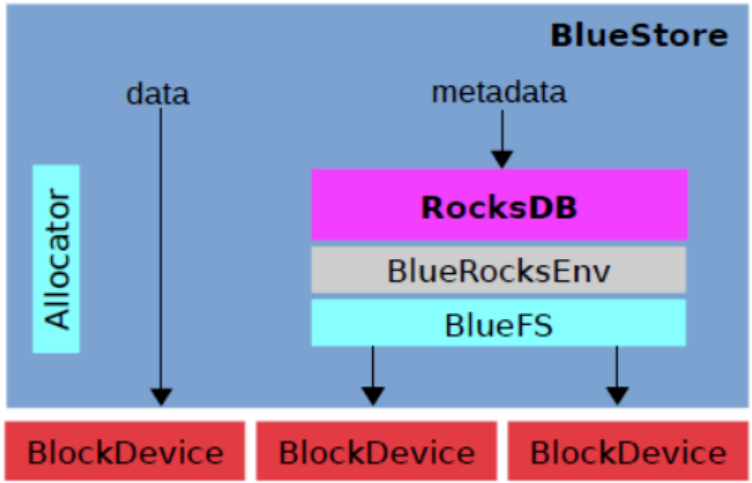
因此Ceph的bluestore把一块物理盘从逻辑上(或物理上)拆成了三条路:
| 组件名(部署目录) | 存的是什么? | IO 特性是什么? | 该用什么盘? | 为什么? |
|---|---|---|---|---|
block |
真正的用户数据 | 大块、顺序读写(吞吐量型) | 大容量 HDD | 机械硬盘顺序跑满带宽,性价比最高。 |
block.db |
RocksDB 的索引表(元数据) | 极度随机的小块读写 + LSM 树后台合并(IOPS 敏感型) | SSD / NVMe | 必须用 SSD 的微秒级随机读写来扛住高频查表和后台整理。 |
block.wal |
RocksDB 的预写日志 | 极其频繁的顺序追加写 + 刷盘(延迟极度敏感型) | 最快的 NVMe SSD | 客户端在等 ACK,每慢 0.1ms 都会累积成巨大延迟,必须用最快的盘。 |
❓ 灵魂拷问 5:元数据适合用什么数据库来存?
我们写 C++ 的,天然想到 LevelDB 或 RocksDB。它们是基于 LSM 树的 KV 数据库。LSM 树有个神仙优点:写入极快(只做追加写),并且天然按 Key 排序。
想到这里你该兴奋了:以前 FileStore 要列举一个目录下的 10 万个对象,需要遍历 XFS 目录并排序(O(n log n)),慢死了;现在只要问 RocksDB:“给我列出 Key 前缀为
obj的所有项”,RocksDB 因为存的时候就是排好序的,瞬间就能返回(O(log n))。
4 死循环难题 —— “鸡生蛋,蛋生鸡肉”
❓ 灵魂拷问 6:RocksDB本身就是一个嵌入式数据库,它也需要在硬盘上存文件(.sst和WAL日志)才能持久化。而我们把XFS砍掉了,Rocksdb不知道该调用哪个函数去创建自己的文件怎么办?
🚀 我们的第三个伟大决策(BlueStore 最秀的操作):骗过 RocksDB!
我们写一个极小的“文件系统”,起名:BlueFS。
- 这个BlueFS什么都不干,它只实现了Rocksdb需要的open、write、mkdir这几个极简的API
- 当Rocksdb说:“我要创建log.sst”文件时,BlueFS 说:“好的,你稍等。”然后 BlueFS 偷偷转过头,调用我们底层管理硬盘的代码(Allocator,ceph自身实现的),在硬盘上划出一块空间,告诉 RocksDB:“文件创建好了,你的数据尽管往这个地址写!”
本质:BlueFS 就是个“翻译官”兼“傀儡”,它让 RocksDB 以为自己活在 XFS 下,实际上数据最终全被我们直接塞进了裸盘。
5 原子炸弹 —— “断电如何处理”
现在我们有了三层的架构:
- 底层老大(blockdevice):复制直接读写硬盘扇区
- 大脑(RocksDB + BlueFS):负责记地图
- 管家(Allocator):负责管理哪些扇区空着,哪些满了
❓ 灵魂拷问 7:如果我正在写一个对象,突然服务器断电了。数据只写了一半,元数据(地图)还没来得及更新。重启后,数据对不上,怎么办?
以前的FileStore采用的时双重写入解决断电问题。我们现在是裸盘,还搞双重写入么?那不是又回到原来的问题了?
不,既然元数据存储在了Rocksdb上,而Rocksdb本身就有自己的WAL(预写日志,用来保证ACID)。
我们解法(事务原子性):
我们把“数据落盘”和“元数据更新”打包成一个事务(Transaction)。
- 先把用户数据直接写进硬盘的某个位置(假设为0X1000)
- 然后在rocksdb启动事务,把这个记录写进去(obj1->0x1000)
- rocksdb会把这条修改先在自己的WAL日志里刷盘,再写进自己的SST表
关键来了:如果第 2 步写完元数据后断电,重启后 RocksDB 回放 WAL,发现 obj1 -> 0x1000 这条记录在,那对应 0x1000 的数据肯定也在(因为第 1 步先于第 2 步落盘了)。
如果第 1 步写完断电,第 2 步没写,RocksDB 里没有 obj1 的映射,那 0x1000 那块空间就成了垃圾,我们回收它就好,用户没收到 ACK,数据不算数。
6 覆盖写之痛 —— “我改了几个字,却要复制整个文件?”
❓ 灵魂拷问 8:用户想覆盖写对象的一个小片段。如果我们在原地(0x1000 地址)直接覆盖修改,万一写到一半断电,数据就损坏了。而且原地修改非常慢。能不能不覆盖?
对于覆盖写,业界有两种解决的方案:
- 写时复制(COW):这是一种“空间换时间”的策略。当需要修改数据时,不直接在原位置修改,而是先在磁盘的新位置写入修改后的完整数据,然后通过更新元数据(指针),将对象指向新的数据位置
- 优点:将随机写改为了顺序写,性能高;天然支持快照
- 缺点:可能导致磁盘空间碎片化
- 读-改-写(RMW):这是一种“就地更新”(In-Place Update)的策略。当需要修改数据时,必须先把整个数据块(Chunk)从磁盘读出来,在内存中修改目标部分,然后再将整个修改后的数据块写回原位置。
- 优点:数据在磁盘上保持连续,空间利用率高。
- 缺点:引入了额外的读操作,写放大明显,性能开销大
了解上面的内容之后,我们发现无论是COW或是RMW都有缺点,因此Bluestore采用了分而治之的混合策略,在性能和空间利用率之间取得最佳平衡。它决策的核心依据是写入操作是否与“最小分配单元”(min_alloc_size,SSD通常为4KB,HDD为64KB)对齐
任何一个写请求,根据磁盘块大小,将其切分为三个部分,即首尾非块大小对齐部分和中间块大小对齐部分,然后针对中间块对齐部分采用COW策略,首尾非块对齐部分采用RMW策略。考虑到RMW策略存在数据损坏的隐患,还需要针对这类操作引人日志,即将对应的数据先写入日志盘后才去真正更新数据盘,数据盘更新完成之后才能释放日志
我们可以根据官方文档 BlueStore Internals中的描述,将这个策略总结如下
| 写入场景 | 采用策略 | 内部代号 | 说明 |
|---|---|---|---|
| 全量写入新对象 | 直接写入 | U |
直接分配新空间并写入。 |
| 覆盖写(块大小对齐) | COW(重定向写) | W |
首选方案。写入大小正好是 min_alloc_size 的整数倍且对齐。直接在新位置写入,性能最佳。 |
| 覆盖写(小于块大小) | RMW | R+W 或 X |
写入大小不足一个 min_alloc_size。必须读取整个块,修改后再写回。 |
| 部分写入现有对象 | COW 或 RMW | P 或 W |
写入一个现有对象中未使用的部分。如果该部分与块对齐则可能用 W,否则可能退化为 P。 |
| 压缩写入 | 直接写入 | C |
数据压缩后写入新块。 |
因此,ceph对于覆盖写,并不是非此即彼的,而是:“大块、对齐的覆盖写走高效的 COW 路径;小块、不对齐的覆盖写走 RMW 路径,并通过 WAL 进行延迟优化。”
7 性能涡轮 —— “有了这几个问题,你就全懂了”
走到这里,我们已经把 BlueStore 最核心的灵魂设计全“推导”出来了。最后我们再带着问题看一眼它的物理部署,你就全通了:
❓终极拷问 9:为什么生产环境建议把 block.db 和 block.wal 放在 SSD 上,而 block(数据)放在 HDD 上?
- block(数据):大块数据,现在HDD顺序读写能力很强(200MB/S以上),放HDD不亏
- blcok.db(Rocksdb的SST文件):因为LSM数的Compaction(合并)会产生大量的随机小块读写IO,而HDD最怕随机IO,所以必须放在SSD上扛住随机IO
- block.wal(RocksDB的日志):每次写事务都要线刷WAL日志,这是延迟敏感型操作。问:谁延迟最低?NVMe SSD!所以放最快的盘

openEuler 是由开放原子开源基金会孵化的全场景开源操作系统项目,面向数字基础设施四大核心场景(服务器、云计算、边缘计算、嵌入式),全面支持 ARM、x86、RISC-V、loongArch、PowerPC、SW-64 等多样性计算架构
更多推荐



 0
0 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)