欧拉函数模板、最大质因子个数【算法赛】
欧拉函数模板
问题描述
这是一道模板题。
首先给出欧拉函数的定义:即 Φ(n)Φ(n) 表示的是小于等于 nn 的数中和 nn 互质的数的个数。
比如说 Φ(6)=2Φ(6)=2,当 nn 是质数的时候,显然有 Φ(n)=n−1Φ(n)=n−1。
题目大意:
给定 nn 个正整数,请你求出每个数的欧拉函数。
输入格式
输入共两行。
第一行输入一个整数表示 nn 。
第二行输入 nn 个整数。
输出格式
输出共 nn 行,每行输出 11 个整数表示对应数字的欧拉函数。
样例输入
3
3 6 8
样例输入
2
2
4
说明
小于等于 33 的数中与 33 互质的有:1,21,2。
小于等于 66 的数中与 66 互质的有:1,51,5。
小于等于 88 的数中与 88 互质的有:1,3,5,71,3,5,7。
评测数据规模
保证对于所有数据有:
1≤n≤1001≤n≤100,输入的 nn 个整数范围为 [1,2×109][1,2×109] 。

注意是质因子
import java.io.BufferedReader;
import java.io.BufferedWriter;
import java.io.IOException;
import java.io.InputStreamReader;
import java.io.OutputStreamWriter;
import java.util.*;
public class Main {
static int N=110;
static int a[]=new int[N];
static BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
static BufferedWriter bw=new BufferedWriter(new OutputStreamWriter(System.out));
public static void main(String[] args) throws IOException {
StringTokenizer st=new StringTokenizer(br.readLine());
int n=Integer.parseInt(st.nextToken());
st=new StringTokenizer(br.readLine());
for (int i = 0; i < n; i++) {
a[i]=Integer.parseInt(st.nextToken());
}
//首先给出欧拉函数的定义
// Φ(n) 表示的是小于等于n的数中和n互质的数的个数。
// 比如说Φ(6)=2, 因为是2和3
//当n是质数的时候,显然有 Φ(n)=n−1。
//暴力做法是枚举1-n的数 如果这个数和n的gcd为1 则加1
// for (int i = 0; i < n; i++) {
// method1(a[i]);
// }
//可以用欧拉函数公式优化
for (int i = 0; i < n; i++) {
method2(a[i]);
}
br.close();
bw.close();
}
static void method2(int n) throws IOException{
int res=n;
for (int i = 2; i * i <= n; i++) {
if(n%i==0){
res=res/i*(i-1);//先除以i 也一定能整除
while(n%i==0){
n/=i;
}
}
}
if(n>1)res=res/n*(n-1);
bw.write(res+"\n");
bw.flush();
}
static void method1(int n) throws IOException{
int res=0;
for (int i = 1; i<= n; i++) {
if(gcd(n,i)==1){
res++;
}
}
bw.write(res+"\n");
}
static int gcd(int a,int b){
return b==0?a:gcd(b,a%b);
}
}斐波那契数列
题目描述
斐波那契数列:{F(1)=F(2)=1F(n)=F(n−1)+F(n−2)n>2,n∈N∗{F(1)=F(2)=1F(n)=F(n−1)+F(n−2)n>2,n∈N∗
给定一个正整数 NN,求F(N)F(N)在模 109+7109+7 下的值。
输入描述
第 11 行为一个整数 TT,表示测试数据数量。
接下来的 TT 行每行包含一个正整数 NN。
1≤T≤1041≤T≤104,1≤N≤10181≤N≤1018。
输出描述
输出共 TT 行,每行包含一个整数,表示答案。
输入输出样例
示例 1
输入
6
1
2
3
4
5
1000000000
输出

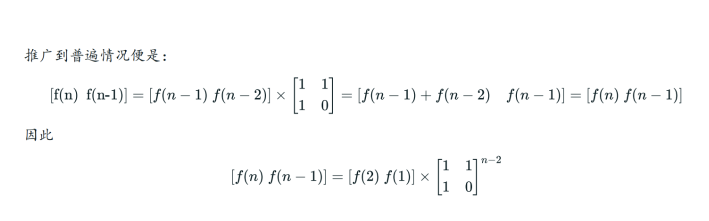
import java.io.BufferedReader;
import java.io.BufferedWriter;
import java.io.IOException;
import java.io.InputStreamReader;
import java.io.OutputStreamWriter;
import java.util.*;
public class Main {
static int N=110,mod=(int)(1e9)+7;
static int a[]=new int[N];
static BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
static BufferedWriter bw=new BufferedWriter(new OutputStreamWriter(System.out));
public static void main(String[] args) throws IOException {
StringTokenizer st=new StringTokenizer(br.readLine());
int t=Integer.parseInt(st.nextToken());
for (int i = 0; i < t; i++) {
st=new StringTokenizer(br.readLine());
long n=Long.parseLong(st.nextToken());
method(n);
}
br.close();
bw.flush();
bw.close();
}
static void method(long n) throws IOException{
if(n==1||n==2){
bw.write(1+"\n");
return;
}
long result[][]=new long[1][2];
long begin[][]={{1,1}};
long base[][]={{1,1},{1,0}};
base=multiple(base,n-2);
result=matrixMul(begin, 1, 2, base, 2, 2);
bw.write(result[0][0]+"\n");
}
static long[][] multiple(long base[][],long a){ //base^a
long res[][]={{1,0},{0,1}};//单位矩阵
while(a>0) {
if((a&1)==1){
res=matrixMul(res,2,2,base,2,2);
}
a=a>>1;//这个绝对不能取模
base=matrixMul(base,2,2,base,2,2);
}
return res;
}
static long[][] matrixMul(long a[][],int row1,int col1,long b[][],int row2,int col2){
long res[][]=new long[row1][col2];
for (int i = 0; i < row1; i++) {
for (int j = 0; j < col2; j++) {
for (int k = 0; k < col1; k++) {
res[i][j]=(res[i][j]+a[i][k]*b[k][j]%mod)%mod;
}
}
}
return res;
}
}最大质因子个数【算法赛】
问题描述
给定一个正整数 NN,请你在 22 到 NN 之间找到拥有不同质因子个数最多的整数,并求出该整数的不同质因子的个数。
输入格式
第一行包含一个整数 TT(1≤T≤1031≤T≤103),表示测试用例的数量。
接下来 TT 行,每行包含一个正整数 NN(2≤N≤10182≤N≤1018),表示要求解的范围。
输出格式
对于每个测试用例,输出一个整数,表示在 22 到 NN 之间拥有最多不同质因子的整数的质因子个数。
样例输入
1
7
样例输出
2
样例说明
在 2∼72∼7 中:
-
22 的质因子有: [2][2]。
-
33 的质因子有: [3][3]。
-
44 的质因子有:[2][2]。
-
55 的质因子有:[5][5]。
-
66 的质因子有:[2,3][2,3]。
-
77 的质因子有:[7][7]。
因此,66 是 2∼72∼7 中不同质因子个数最多的整数,其拥有的不同质因子个数为 22。

import java.io.BufferedReader;
import java.io.BufferedWriter;
import java.io.IOException;
import java.io.InputStreamReader;
import java.io.OutputStreamWriter;
import java.util.*;
public class Main {
static int N=1010,mod=(int)(1e9)+7,cnt;
static int a[]=new int[N];
static int prime[]=new int[N];
static boolean st[]=new boolean[N];
static BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
static BufferedWriter bw=new BufferedWriter(new OutputStreamWriter(System.out));
public static void main(String[] args) throws IOException {
StringTokenizer st=new StringTokenizer(br.readLine());
int t=Integer.parseInt(st.nextToken());
get_Prime(1000);
for (int i = 0; i < t; i++) {
st=new StringTokenizer(br.readLine());
long n=Long.parseLong(st.nextToken());
long p=1;
for (int j = 0; j < cnt; j++) {
if(p>n/prime[j]){//相当于n/p==0 这里怎么写只是为了防止溢出
// 若n / p1 p2 ... pk >0 这个数一定能在n以内找到
bw.write(j+"\n");break;
}
p=p*prime[j];
}
}
br.close();
bw.flush();
bw.close();
}
static void get_Prime(int n){
for (int i = 2; i <= n; i++) {
if(!st[i]){
prime[cnt++]=i;
}
for (int j = 0; j<cnt && i * prime[j] <= n; j++) {
st[i * prime[j]]=true;
if(i%prime[j]==0)break;
}
}
}
}

openEuler 是由开放原子开源基金会孵化的全场景开源操作系统项目,面向数字基础设施四大核心场景(服务器、云计算、边缘计算、嵌入式),全面支持 ARM、x86、RISC-V、loongArch、PowerPC、SW-64 等多样性计算架构
更多推荐

 2
2 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)