Java线程(五)阻塞队列、消费者生产者模型的解析和代码实现
本文介绍了阻塞队列和生产者消费者模型的核心概念与应用。阻塞队列是一种线程安全的特殊队列,具有阻塞功能:当队列为空时出队操作会阻塞,队列满时入队操作会阻塞。通过包饺子的生动例子,解释了生产者消费者模型如何通过阻塞队列协调工作节奏。 文章重点阐述了生产者消费者模型的三大优点:模块解耦、减少资源竞争和削峰填谷,并举例说明了其在服务器开发中的重要作用。同时指出了该模型的缺点,如系统复杂度增加和网络开销增大
前言
hello hello💕,这里是洋不写bug~😄,欢迎大家点赞👍👍,关注😍😍,收藏🌹🌹
铁汁们在上网时可能遇到过服务器因流量突增被瞬间冲垮,进而产生宕机,例如在一些报名页面,查分页面,选课页面
阻塞队列和消费者生产者模型就是解决这个的核心防护手段,这篇博客会从原理解析和代码的实现来解析这部分内容🐵🎆个人主页:洋不写bug的博客
🎆所属专栏:JavaEE学习
🎆铁汁们对于JavaEE的各种常用核心语法,都可以在上面的前端专栏学习,专栏正在持续更新中🏀,有问题可以写在评论区或者私信我哦~
1,阻塞队列
我们在数据结构中学习过队列,队列具有先进先出的特点
队列的底层数据结构就是堆(特殊的完全二叉树)
阻塞队列是一种特殊的队列,具有以下特点
- 线程安全(普通队列是线程不安全的)
- 带有阻塞功能
1)如果队列为空,尝试出队列,就会引发阻塞,直到队列不为空
2)如果队列满了,尝试入队列,就会引发阻塞,直到队列不满
阻塞功能是比较重要的,给铁汁们举个例子
大家春节都会吃饺子,就拿包饺子来举个例子,假设有三个滑稽围坐在一张桌子前包饺子,滑稽A负责擀饺子皮,滑稽B和C负责包饺子(这里就可以把滑稽A看作生产者,把滑稽B和看作消费者)

滑稽A擀饺子皮的速度不一定刚好跟滑稽B,C包饺子的速度相同,这时候搞一个存饺子皮的东西(盖帘,如下图)

这个盖隆用于协调工作,如果滑稽A包的快了,那滑稽A就阻塞等待一会(等B和C把盖帘里的饺子皮用的差不多了再开始包)
如果滑稽A包的慢了,那滑稽B和C就阻塞等待一会
这些阻塞等待在编程中就要依靠阻塞队列
这其实就是生产者消费者模型,引入这个模型,主要的目的就是为了减少锁竞争,因为生产者和消费者的步调不一定总是一致的,生产者消费者模型的核心就是阻塞队列,阻塞队列可以起到协调的效果
2,生产者消费者模型
生产者消费者模型主要有三个优点:
- 可以更好的做到模块之间的解耦合
- 减少资源竞争,提升效率
- 削峰填谷
在服务器开发上会经常使用这个模型,因为一些事情(比如网页搜索)单靠一台机器是没办法完成的,*就需要多个机器合作进行,这就需要开发一组服务器程序
例如搜索程序的开发(如下图),用户发出搜索请求,调用网关服务器(做接入、转发和基础防护,不处理核心搜索逻辑),网关服务器再调用检索服务器(理解用户意图、召回、排序),检索服务器再调用用户服务器(根据用户的历史记录,提供个性化的搜索结果)
层层调用后,再层层返回结果,返回给用户
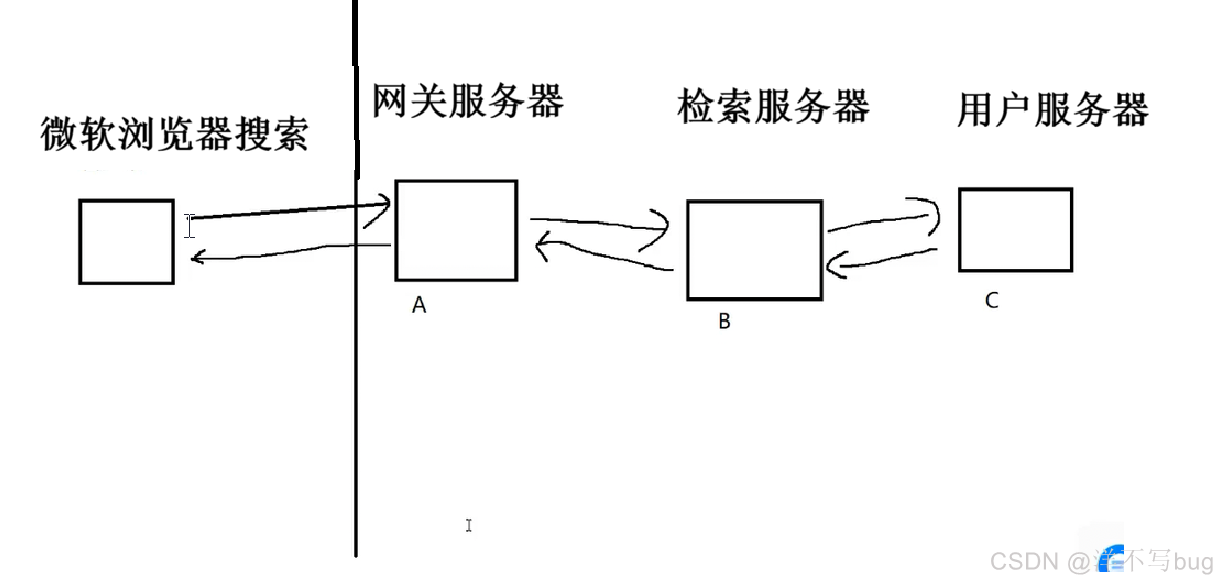
这里如果直接调用的话,就拿B和C而言,B 要调用 C,必须知道:C 的 IP / 端口、接口地址、请求参数格式、返回结果格式、超时时间等。只要 C 的任何一个细节变了,B 的代码必须同步修改,否则调用直接失败。
加了阻塞队列后,C只需要知道怎么从队列中取消息即可,就降低了耦合度
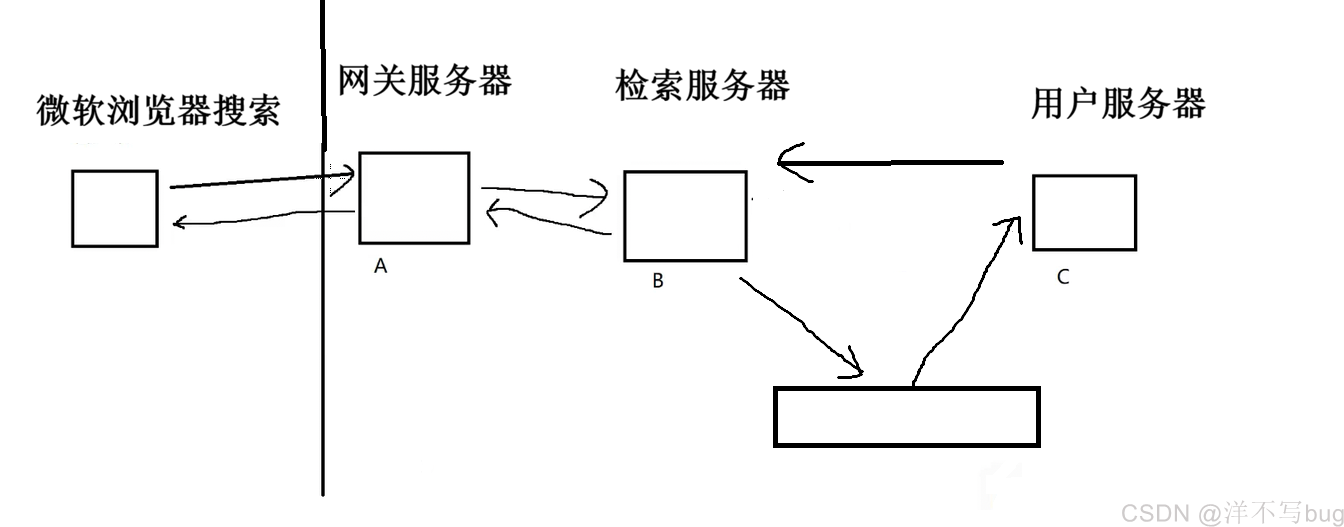
不加阻塞队列时,B 发请求,线程死等 C,后面处理请求时, 线程就不够了,就开始在线程池中抢线程
加了阻塞队列后, B 把任务丢进队列后,线程立刻释放,去处理下一个搜索请求
因此,加阻塞队列后能减少资源竞争,提升效率
最后就是削峰填谷
在10年前,经常会有选课系统,报名系统在使用高峰,服务器挂了的情况
一个服务器,每处理一次请求,都是需要消耗一定的硬件资源的(cpu,内存,网络带宽,硬盘…),一个机器,提供的硬件资源数是有限的,同一时刻,如果请求太多,消耗的总资源超出了机器能够提供的资源上限,那机器这时候就挂了(无法访问了)
上面在B和C之间加了一个阻塞队列,在使用高峰,B受到的压力,就不会立刻都传给C,C会力所能及的处理阻塞队列中的数据,不会立刻挂掉
那在访问高峰,给C加阻塞队列是保护住了,那A和B就不会挂掉吗?
每个服务器完成的功能是不一样的,有的服务器处理一个请求,消耗的资源多,有的消耗的资源少
单个资源消耗较多的服务器(例如MySQL服务器),就比较容易挂掉,就需要用阻塞队列来保护
但是,生产者消费者模型也具有缺点:
- 系统更复杂
- 引入的队列层数太多,就会增加网络开销
3,代码实现
阻塞队列在Java中就使用BlockingQueue,BlockingQueue是一个接口,不能直接new,要用实现类来new
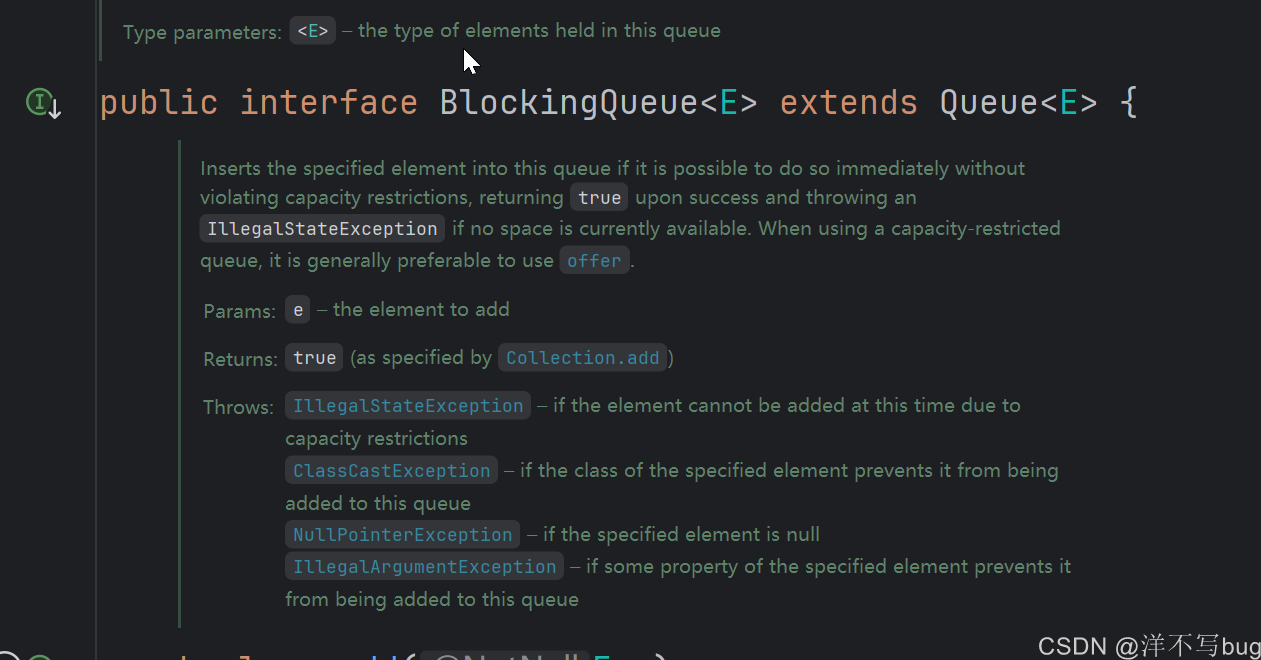
BlockingQueue有两个实现类,ArrayBlockingQueue的底层是数组,LinkedBlockingQueue的底层是链表,后面括号中填上数字,表示这个阻塞队列的最大容量,代码如下所示
public static void main(String[] args) {
BlockingQueue<String> queue = new ArrayBlockingQueue<>(1000);
BlockingQueue<String> queue2 = new LinkedBlockingQueue<>(1000);
}
注:出队列和入队列使用的是take和put方法(因为有阻塞效果,因此是需要抛出异常的),虽然也能使用普通队列的offer和add方法(因为BlockingQueue接口是继承Queue接口的),但是使用offer和add方法是没有阻塞效果的
当往队列中加入的元素数量超过队列容量时,元素就加不进去了,如下所示:
import java.util.concurrent.ArrayBlockingQueue;
import java.util.concurrent.BlockingQueue;
public class Demo28 {
public static void main(String[] args) throws InterruptedException {
BlockingQueue<String> queue = new ArrayBlockingQueue<>(3);
queue.put("aaa");
System.out.println("加入一个元素");
queue.put("aaa");
System.out.println("加入一个元素");
queue.put("aaa");
System.out.println("加入一个元素");
queue.put("aaa");
System.out.println("加入一个元素");queue.put("aaa");
System.out.println("加入一个元素");
}
}

如果取元素把阻塞队列中的元素给取完了,那代码就会卡在这里不执行,如下所示:
import java.util.concurrent.ArrayBlockingQueue;
import java.util.concurrent.BlockingQueue;
public class Demo28 {
public static void main(String[] args) throws InterruptedException {
BlockingQueue<String> queue = new ArrayBlockingQueue<>(3);
String s = queue.take();
System.out.println("取出一个元素" + s);
}
}

接下来模拟下生产者消费者模型,让生产者和消费者线程以相同的速度运行,如下所示:
import java.util.concurrent.BlockingQueue;
import java.util.concurrent.LinkedBlockingQueue;
public class Demo29 {
public static void main(String[] args) throws InterruptedException {
BlockingQueue<String> queue = new LinkedBlockingQueue<>(1000);
Thread producer = new Thread(() -> {
int count = 0;
try {
while (true) {
queue.put(count + "");
System.out.println("生产了一个元素" + count);
count++;
Thread.sleep(1000);
}
} catch (InterruptedException e) {
e.printStackTrace();
}
});
Thread consumer = new Thread(() -> {
while (true){
try {
String elem = queue.take();
System.out.println("消费了一个元素" + elem);
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
});
producer.start();
consumer.start();
producer.join();
consumer.join();
}
}
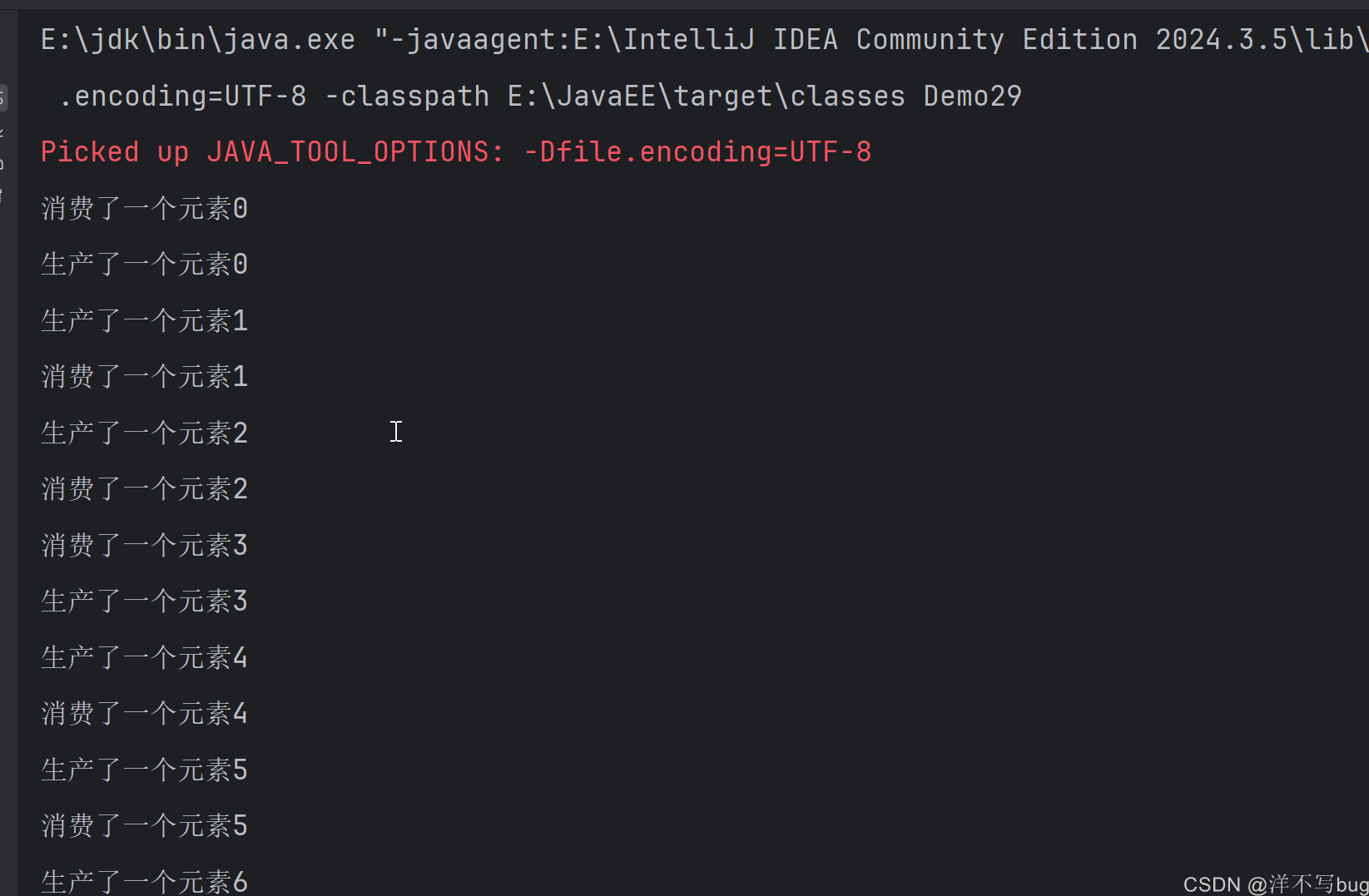
如果把生产者的sleep代码删掉,那生产者就会以很快的速度来生产,消费者还是以正常的速度消费
4,阻塞队列的模拟实现
为了更好的理解阻塞队列的特征,我们可以模拟实现一个自己的阻塞队列
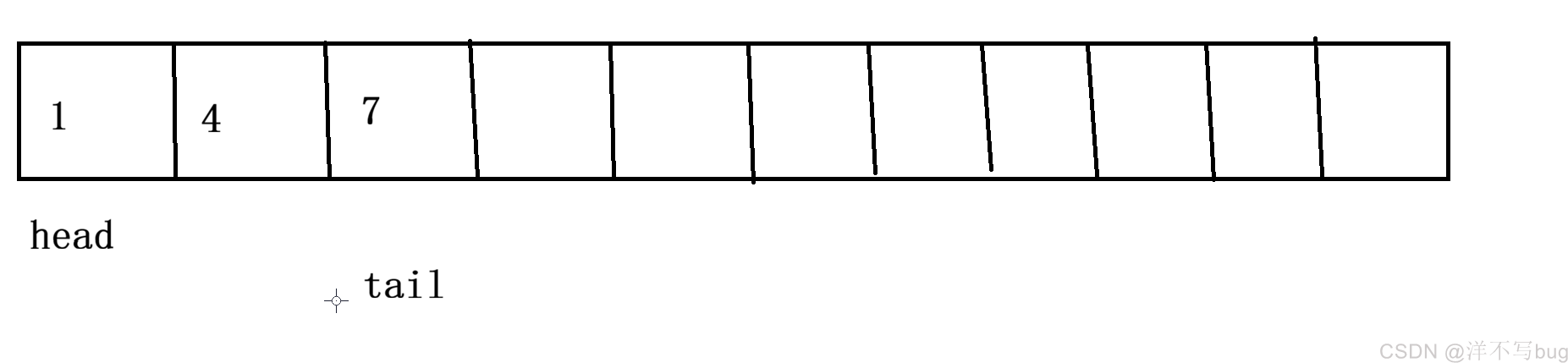
在数据结构的队列中,初始时head和tail都在最前面,后来随着元素的添加,tail就会向后方移动
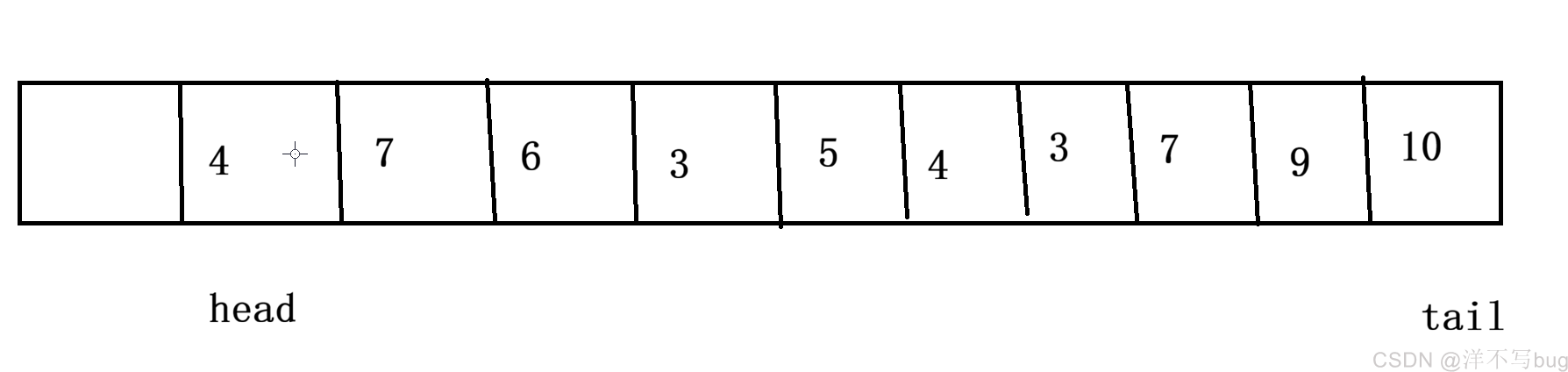
如果删除元素的话,head就会向前移动,tail到末尾后,需要再重新返回开头,head跟tail指向同一个位置时,要不就是队列全空,要不就是队列全满,一会代码我们就可以通过一个size来区分记录当前队列元素的个数,进而区分这两种情况
不考虑线程安全问题和阻塞,基础代码如下所示:
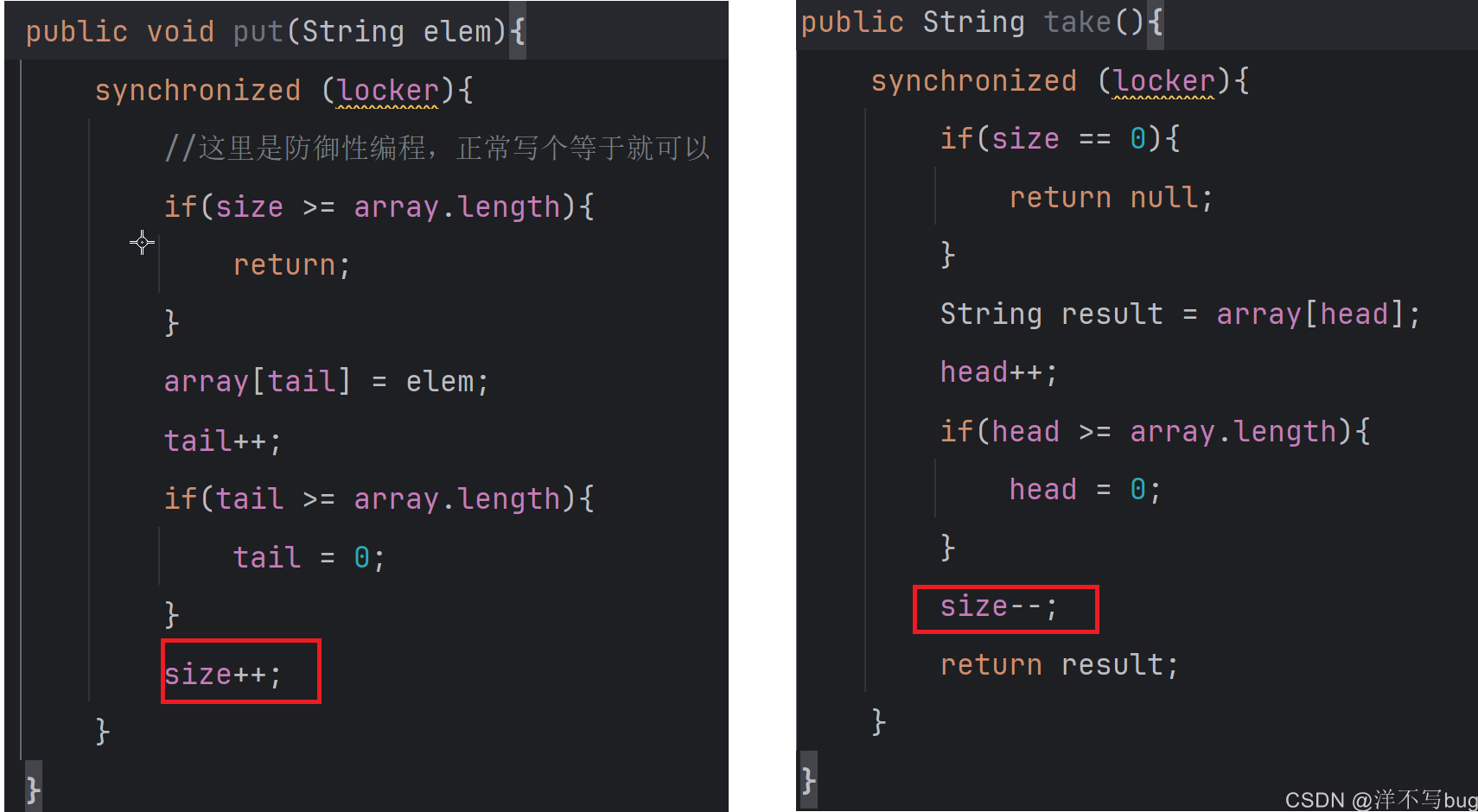
public class MyBlockingQueue {
private String [] array = null;
private int head = 0;
private int tail = 0;
private int size = 0;
public MyBlockingQueue(int capacity){
array = new String[capacity];
}
public void put(String elem){
//这里是防御性编程,正常写个等于就可以
if(size >= array.length){
return;
}
array[tail] = elem;
tail++;
if(tail >= array.length){
tail = 0;
}
size++;
}
public String take(){
if(size == 0){
return null;
}
String result = array[head];
head++;
if(head >= array.length){
head = 0;
}
size--;
return result;
}
}
接下来处理一下线程安全问题,对于put操作,可能多个线程同时调用put的话,put里面的每行代码线程不能插队,因此就需要给整个put代码都加上锁(这部分不太理解的铁汁可以看一下前面Java线程(三)中的线程执行顺序问题)
同理,take方法里面的每行代码线程也不能插队,因此take方法也要整体加锁
那put方法和take方法是必须加同一把锁,还是可以加不同的锁
这里put和take方法中都有关于修改size的操作,这行代码在cpu上不是原子的,是分为多条指令的,这些指令之间可能会相互插队,因此,要加同一把锁
那线程安全问题解决了,怎么来实现阻塞功能呢,阻塞队列的规则如下:
- 如果队列为空,尝试出队列,就会触发阻塞,直到队列不为空
- 如果队列满了,尝试入队列,就会触发阻塞,直到队列不满
这时候就可以巧妙的使用wait和notify
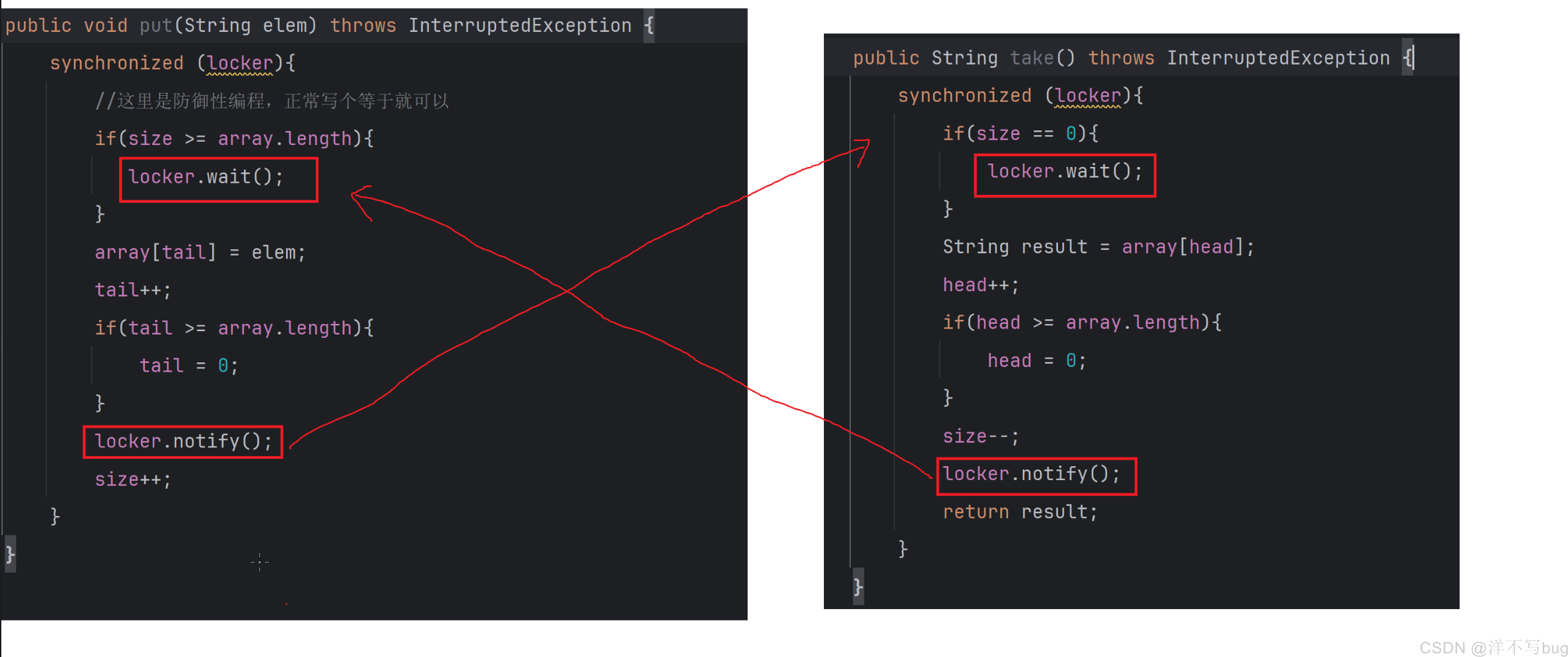
在put方法中,当阻塞队列满了,还有线程往阻塞队列中添加元素时,那这个线程就会处于wait状态,那什么这个添加元素线程什么时候能正常执行呢,当其他线程从阻塞队列中取出元素的时候,阻塞队列不满了,添加元素的线程就会被激活
take方法也是同样的道理,当阻塞队列为空时,还有线程取元素,那这个线程就会处于阻塞状态,当下次有线程往阻塞队列中添加元素时,这个线程才会被激活
也就是put方法中的notify激活调用take方法的线程,take方法中的notify激活调用put方法的线程
put方法的notify是不会激活调用put方法的wait的,因为线程如果在执行put方法时被卡住了,就不可能往下执行,也就执行不到notify🐵
代码如下:
public class MyBlockingQueue {
private String [] array = null;
private int head = 0;
private int tail = 0;
private int size = 0;
private Object locker = new Object();
public MyBlockingQueue(int capacity){
array = new String[capacity];
}
public void put(String elem) throws InterruptedException {
synchronized (locker){
//这里是防御性编程,正常写个等于就可以
if(size >= array.length){
locker.wait();
}
array[tail] = elem;
tail++;
if(tail >= array.length){
tail = 0;
}
locker.notify();
size++;
}
}
public String take() throws InterruptedException {
synchronized (locker){
if(size == 0){
locker.wait();
}
String result = array[head];
head++;
if(head >= array.length){
head = 0;
}
size--;
locker.notify();
return result;
}
}
}
可以写代码来测试下我们模拟实现的阻塞队列的效果,如下所示:
public class Demo30 {
public static void main(String[] args) throws InterruptedException {
MyBlockingQueue queue = new MyBlockingQueue(1000);
Thread producer = new Thread(() -> {
int count = 0;
while (true){
try {
queue.put("" + count);
System.out.println("生成了一个元素" + count);
count++;
} catch (InterruptedException e) {
e.printStackTrace();
}
}
});
Thread consumer = new Thread(() -> {
while(true){
try {
String elem = queue.take();
System.out.println("消费了一个元素" + elem);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
});
producer.start();
consumer.start();
producer.join();
consumer.join();
}
}
另外补充一点,在标准库中,put方法里面的判断size和array.length的大小,写的不是if,是while

正常进入wait之前,当然要进行一次条件判定,写成while,当唤醒之后,还要进行一次条件判定
正常来说,肯定是条件被打破了,才能唤醒,此处的条件是size >= length,当其他线程take时,size就会小于 length,触发notify
但是会有一些特殊的代码,在唤醒之后,仍有size >= length条件成立的可能性,加个while相当于是二次判断,更保险了
结语💕💕
阻塞队列和生产者消费者模型,在后端开发、高并发业务、中间件、服务开发中,都是比较常用的
代码并不难理解,在日常中只需要知道如何使用即可,这里模拟阻塞队列的代码实现只是为了更好的理解🐵
以上就是今天的所有内容啦~完结撒花~🥳🎉🎉


openEuler 是由开放原子开源基金会孵化的全场景开源操作系统项目,面向数字基础设施四大核心场景(服务器、云计算、边缘计算、嵌入式),全面支持 ARM、x86、RISC-V、loongArch、PowerPC、SW-64 等多样性计算架构
更多推荐



 11
11 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)