从 “拆东墙补西墙“ 到 “全局掌控“:Seata 分布式事务的修仙之路
前言:分布式系统的 "钱袋子" 难题
想象一下,你在淘宝上下单买了一部手机。这个看似简单的操作背后,其实发生了三件大事:
-
订单系统创建了一个新订单
-
库存系统扣减了一部手机的库存
-
支付系统从你的账户里扣了钱
如果这三个操作都在同一个数据库里,那一切都好说,一个本地事务就能搞定 —— 要么全部成功,要么全部失败。但在微服务架构下,这三个系统分别部署在不同的服务器上,用着不同的数据库。这时候问题就来了:如果订单创建成功了,库存也扣了,但支付失败了怎么办?
这就是分布式系统中最头疼的问题之一:分布式事务。今天我们就来聊聊分布式事务领域的 "当红小生"——Seata,看看它是如何优雅地解决这个难题的。
一、本地事务的 "一亩三分地"
在聊分布式事务之前,我们先回顾一下本地事务。本地事务就像是你自己的钱包,你想怎么花就怎么花,花多花少自己说了算。它遵循我们熟悉的 ACID 原则:
-
原子性 (Atomicity):要么全做,要么全不做
-
一致性 (Consistency):事务前后数据状态保持一致
-
隔离性 (Isolation):多个事务之间互不干扰
-
持久性 (Durability):事务一旦提交,数据就永久保存
本地事务之所以这么好用,是因为它有一个强大的后盾 ——数据库。数据库通过日志和锁机制,完美地实现了 ACID 特性。但本地事务有一个致命的缺点:它只能控制自己的 "一亩三分地",管不了别人的数据库。
二、分布式事务:当多个 "钱袋子" 需要同步
当我们的系统从单体架构拆分成微服务架构后,就相当于把一个大钱包拆成了好几个小钱包,每个小钱包都由不同的人保管。这时候,如果你想从 A 钱包转 100 块到 B 钱包,就需要:
-
从 A 钱包里拿出 100 块
-
把这 100 块放到 B 钱包里
但如果第一步成功了,第二步失败了,那这 100 块就凭空消失了。这就是分布式事务要解决的核心问题:如何保证多个独立数据库操作的原子性。
在 Seata 出现之前,人们也想了很多办法来解决这个问题,比如:
-
2PC (两阶段提交):准备阶段→提交阶段,但性能差,容易阻塞
-
TCC (补偿事务):Try→Confirm→Cancel,侵入性强,开发成本高
-
SAGA 模式:长事务拆分成短事务,通过补偿机制保证一致性,复杂度高
这些方案要么性能差,要么开发成本高,要么复杂度高,都不是完美的解决方案。直到 Seata 的出现,才让分布式事务变得简单易用。
三、Seata 登场:分布式事务的 "大管家"
Seata 是阿里开源的一款分布式事务解决方案,它的全称是Simple Extensible Autonomous Transaction Architecture,也就是 "简单可扩展自治事务架构"。正如它的名字一样,Seata 的设计理念就是简单、高效、对业务无侵入。
Seata 的核心思想是:把一个分布式事务看成是一个全局事务,下面包含若干个分支事务。每个分支事务其实就是一个本地事务。Seata 负责协调所有的分支事务,要么全部提交,要么全部回滚。
听起来是不是很简单?但实现起来可没那么容易。Seata 通过三个核心组件来实现这个功能。
四、Seata 的核心 "三剑客":TC、TM、RM
Seata 的架构非常清晰,主要由三个核心组件组成:
1. TC (Transaction Coordinator) - 事务协调者
TC 是 Seata 的 "大脑",负责全局事务的协调和管理。它维护着全局事务和分支事务的状态,接收 TM 的提交和回滚请求,并通知所有 RM 进行提交或回滚。
2. TM (Transaction Manager) - 事务管理器
TM 是全局事务的发起者。它负责开启一个全局事务,并最终向 TC 发起全局提交或全局回滚的请求。
3. RM (Resource Manager) - 资源管理器
RM 是分支事务的管理者。它负责管理本地数据库资源,向 TC 注册分支事务,报告分支事务的状态,并执行 TC 的提交或回滚指令。
这三个组件的工作流程可以用一个简单的例子来理解:
-
你 (TM) 要组织一场聚会 (全局事务)
-
你联系了一个聚会策划公司 (TC)
-
策划公司分别联系了餐厅 (RM1)、KTV (RM2) 和电影院 (RM3)
-
所有场地都确认有空 (分支事务准备成功)
-
策划公司通知所有场地确认预订 (全局提交)
-
如果有一个场地没空,策划公司就通知所有场地取消预订 (全局回滚)
五、手把手教你搭建 Seata 环境
说了这么多理论,我们来动手搭建一个 Seata 环境,感受一下它的魅力。
步骤 1:下载 Seata
首先,我们从 Seata 的官方 GitHub 仓库下载最新版本的 Seata: https://github.com/seata/seata/releases
步骤 2:配置 Seata
解压下载的压缩包,进入 conf 目录,修改 file.conf 文件:

步骤 3:启动 Seata
进入 bin 目录,执行以下命令启动 Seata:
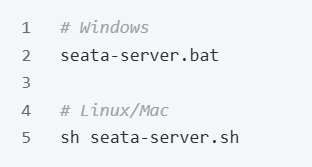
看到 "Seata Server started successfully" 的日志,就说明 Seata 启动成功了。
六、实战:用 Seata 搞定分布式事务
现在我们来创建一个简单的微服务项目,演示如何使用 Seata 解决分布式事务问题。我们将创建三个服务:订单服务、库存服务和支付服务。
步骤 1:添加依赖
在每个服务的 pom.xml 文件中添加 Seata 的依赖:

步骤 2:配置 Seata
在每个服务的 application.yml 文件中添加 Seata 的配置:

步骤 3:创建数据库表
在每个服务对应的数据库中创建 undo_log 表,这是 Seata 实现回滚的关键:

步骤 4:编写业务代码
在订单服务的创建订单方法上添加@GlobalTransactional注解:

就是这么简单!只需要一个@GlobalTransactional注解,Seata 就会自动帮我们管理分布式事务。如果任何一个步骤出现异常,Seata 会自动回滚所有已经执行的操作。
七、总结与展望
Seata 作为一款优秀的分布式事务解决方案,凭借其简单易用、高性能、低侵入性的特点,已经成为了微服务架构下处理分布式事务的首选方案。它不仅支持 AT 模式 (自动事务模式),还支持 TCC、SAGA 和 XA 模式,可以满足不同场景的需求。
当然,Seata 也不是万能的,它也有一些局限性,比如:
-
不支持跨语言
-
对某些特殊的 SQL 语句支持不够好
-
在高并发场景下可能会有性能瓶颈
但总的来说,Seata 已经足够优秀,能够解决绝大多数分布式事务问题。随着 Seata 社区的不断发展,相信这些问题都会逐步得到解决。
分布式事务是微服务架构中绕不开的一个坎,而 Seata 为我们提供了一个优雅的解决方案。希望通过这篇文章,你能对 Seata 有一个全面的了解,并在实际项目中应用它。

openEuler 是由开放原子开源基金会孵化的全场景开源操作系统项目,面向数字基础设施四大核心场景(服务器、云计算、边缘计算、嵌入式),全面支持 ARM、x86、RISC-V、loongArch、PowerPC、SW-64 等多样性计算架构
更多推荐
 11
11 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)