Linux内存管理系列:2.虚拟地址空间的实现细节
从本篇文章开始将讲解虚拟地址空间的实现的具体技术细节,会涉及到一部分的Linux源代码分析,可能会比较枯燥,希望读者保持耐心,在此处还要进行说明的是:虚拟地址空间机制贯穿了整个操作系统中的几乎所有概念,因此本章会涉及到比较多的操作系统概念,比如进程,线程,文件系统,MMU....,所以本章并不建议没有系统的学习过操作系统的读者阅读,又或者是可以只挑自己可以理解的部分进行阅读。
从本篇文章开始将讲解虚拟地址空间的实现的具体技术细节,会涉及到一部分的Linux源代码分析,可能会比较枯燥,希望读者保持耐心,在此处还要进行说明的是:虚拟地址空间机制贯穿了整个操作系统中的几乎所有概念,因此本章会涉及到比较多的操作系统概念,比如进程,线程,文件系统,MMU....,所以本章并不建议没有系统的学习过操作系统的读者阅读,又或者是可以只挑自己可以理解的部分进行阅读。
在进入正题之前,笔者先来说明一下会按照什么顺序进行讲解,也就是先理顺逻辑链,简单来说是这样的:
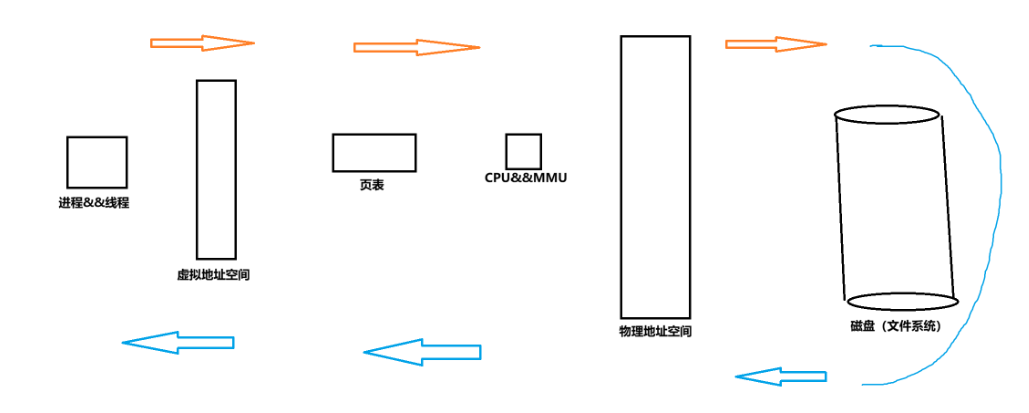
第一条逻辑链是"由外到内"(上面那条),即从进程和线程开始(主要是进程),到磁盘中文件系统结束,介绍虚拟地址空间具体的技术实现细节,第二条逻辑链是"由内到外"(下面那条),以具体的使用场景为例,看看虚拟地址空间的具体工作流程是什么样子的,好了,让我们进入正题。(注:1.后面的代码将在Linux环境下运行(使用VS Code);2.源代码的分析使用的是Linux2.6.24版本;3.笔者也是第一次尝试分析Linux源代码,如有错误,还请指出)
1.mm_struct
在上篇文章已经提到过(初探虚拟地址空间),虚拟地址空间就是操作系统给每一个进程发的一张内存使用的说明书,是一个复杂的结构体,并且每一个进程都会有一个独属于自己的虚拟地址空间,那么就让我们先着眼于单个进程和其虚拟地址空间,来看看虚拟地址空间在Linux内核中具体是什么样子的:
1.1源代码分析
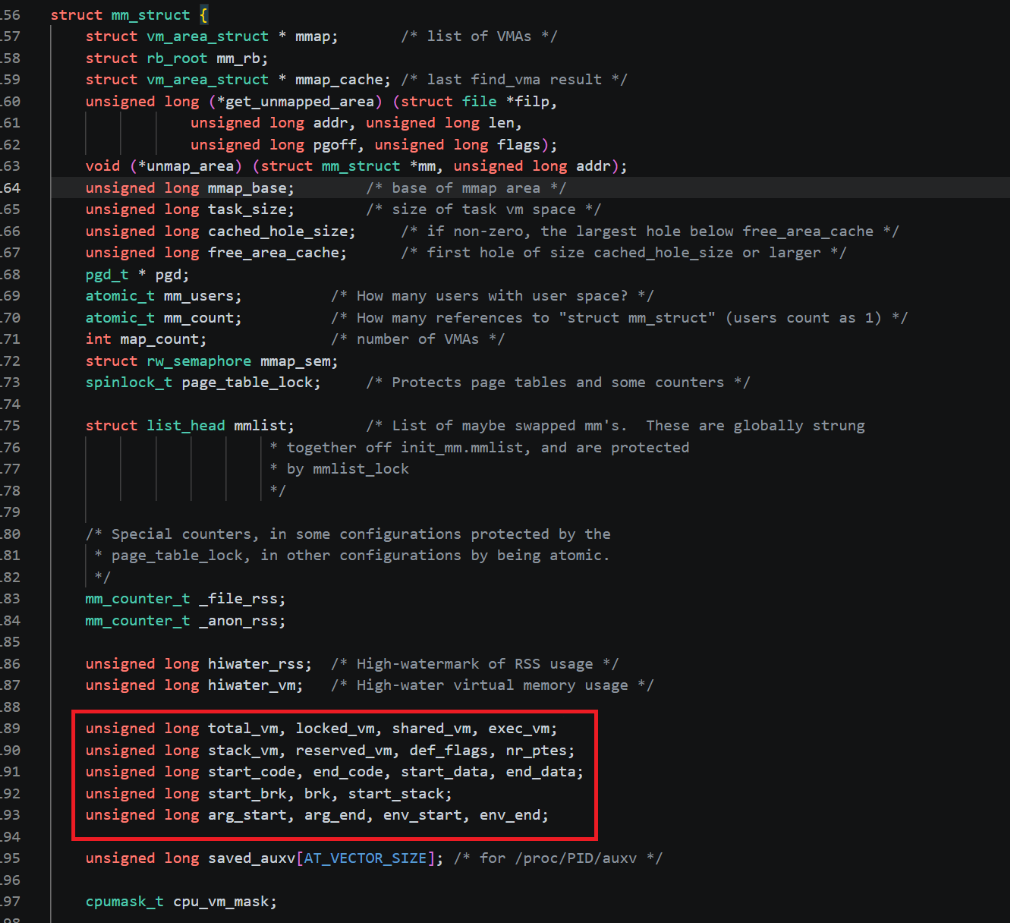
这就是在Linux内核中描述一个虚拟地址空间主要的结构体:mm_struct(这里只截取了一部分),非常的复杂,但是先让我们抓住重点字段,无论该结构体多么复杂,最终目的都是要描述出一个虚拟地址空间的"样貌"的,也就是这个东西:
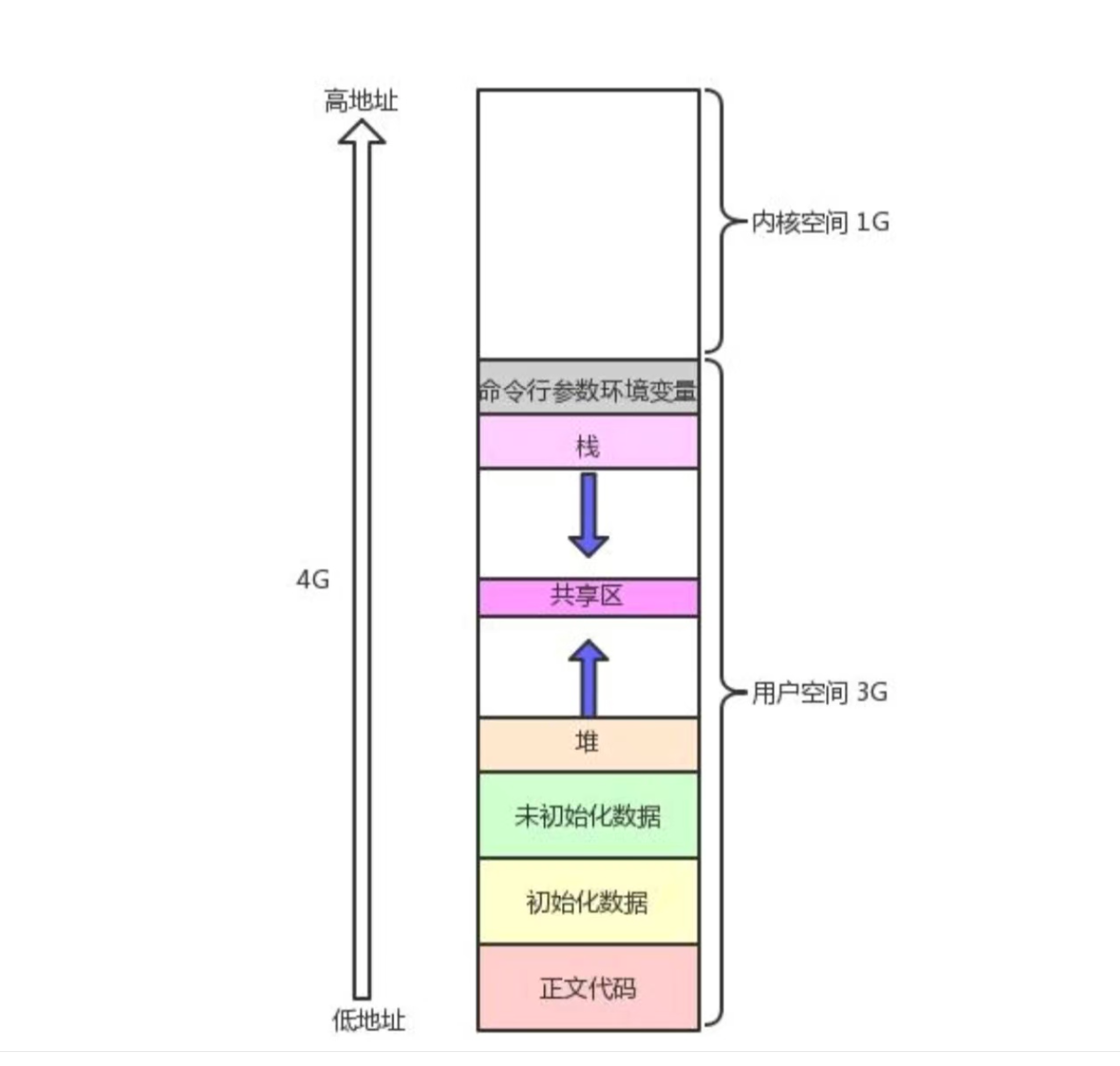
在代码中框出来的那部分就是用于描述该图片的,下面来解释一下其中部分字段的具体含义:
|
total_vm |
进程已使用的总虚拟内存页数。具体来说就是指进程已经使用了用户空间中的多少内存,要注意的是进程是无法直接使用内核空间中的内存的。(注:此处的内存指虚拟内存,不是物理内存) |
| locked_vm | 进程中被锁定在物理内存中的页数(不可换出)。换出这个概念与进程有关,简单来说就是在内存不足时,操作系统会把进程中不重要的部分暂时放到磁盘的swap分区中,等到CPU要执行这部分代码时,再加载到内存中;因此这里的不可换出就是指进程存储在这部分的代码和数据是非常重要的,操作系统不能把这部分内容换出到磁盘中。 |
| shared_vm | 共享内存页数(如共享库、IPC 共享内存)。具体来说,该字段指定了上图中共享区的大小,共享这个概念比较复杂,涉及到动态库,共享内存等知识,在这里简单的介绍一下共享这个概念,共享的操作也是和虚拟地址空间强相关的,比如在物理内存中存放了一个函数,那么我们就可以利用页表把这部分物理内存映射到多个进程的虚拟地址空间中,此时该函数在实际物理空间中就只有一份,但是可以同时被多个进程使用,也就是说这个函数就被共享了(动态库就是差不多的原理),要注意的是,共享的资源在大多数情况下都是不能被进程修改的,也就是说是只读的,因为会有多个进程都使用该共享的资源,如果该资源被修改了的话,那么所有进程就都会受到影响。 |
| exec_vm | 该值记录了代码段占用的页数,具体来说就是指上图中红色的正文代码那部分占用的虚拟内存大小。 |
| stack_vm | 当前已使用的栈空间占用的页数,可以把该值理解成一个计数器,每当进程已使用的栈空间多了一页,该值就会++,也就是说该值是会动态变化的。 |
|
|
标识了正文代码段的起始位置和结束位置。 |
| start_data | 标识了初始化数据段的起始位置。 |
| end_data | 标识了未初始化数据段的结束位置。 |
| start_brk |
标识了堆区的起始位置。 |
| brk | 标识了堆区当前的结束位置,要注意的是堆区的大小的实时变化的,具体来说就是在使用malloc申请堆区内存时,brk就会变大(结束地址往高地址方向移动) |
| start_stack | 标识了栈区的起始位置。要注意的是由于栈区是从高地址往低地址增长的,因此栈区的起始位置是位于高地址处的。 |
|
arg_start arg_end |
标识了命令行参数和环境变量中命令行参数部分的起始位置和结束位置,该部分存储的是main(int argc, char *argv[], char *envp[]) 中数组argv的所有字符串(如果用户有输入的话) |
|
env_start env_end |
标识了命令行参数和环境变量中环境变量部分的起始位置和结束位置,该部分存储的是main(int argc, char *argv[], char *envp[]) 中数组envp的所有字符串 |
| 备注 |
要重点注意的是,上方的字段都不是绝对固定的,并且对于不同的进程来说,这些字段的值也大概率是不同的,其中有些字段在编译期间会发生变化,比如start_code 和 end_code,这两个字段标识了代码区的范围,简单来说就是进程的代码写的越多,该范围就越大(即end_code - start_code就越大),但是当进程运行起来后,代码段的大小在大部分情况下就不会改变了(因为你不可能在代码跑起来后还继续往里面写代码);有些字段在运行期间也会发生变化,比如brk字段,在运行期间如果进程执行到了一个malloc或free,那么brk就会变化,又比如标识栈区总大小的stack_vm字段,要知道函数栈帧都是在运行期间动态开辟和销毁的,因此stack_vm在进程运行期间也是会不断的变化的,总的来说,上方那张虚拟地址空间的图片中的每一个段都绝不是固定的,一定要让它在你的脑海中动起来。 |
在上方多次提到了页这个概念,该概念在后续系列的文章会进行详细的介绍,目前只需要把一个页理解成一个4kb大小的物理内存块就可以了。要说明的是,理解上方这些字段对于编程也是有实际意义的,比如大部分人都遇到过栈溢出错误,那么为什么会出现该错误呢?为什么这个错误在运行时才会报出而不是编译时报出呢?操作系统又是怎么发现栈溢出错误的呢?在理解了这些字段后就可以回答这些问题了,首先在运行时才报出该错误是因为栈区是动态变化的,在实际调用到函数时,函数栈帧才会被开辟,那么此时进程所使用栈区部分的内存就会变多,也就是说stack_vm就会增长,而栈区是不能一直增长的,一般操作系统给栈区分配的可使用内存是8MB,也就是说如果一个进程的stack_vm大小超过了8MB,那么操作系统就会检测出来该进程发生了栈溢出错误了(实际上栈溢出错误比较复杂,操作系统还会设置一个陷阱页,一但栈区的增长覆盖到了该陷阱页,那么操作系统就会判断出现了栈溢出错误,也就是说stack_vm和陷阱页机制是配合使用的)。
1.2源代码分析技巧
相信对于不少读者来说,初次看到mm_struct这种复杂的结构体都会感到头皮发麻吧,但是如果你想要在编程这条路上走的更远,那么分析复杂的源代码就是必须的,说点实际的,你在入公司后少说也要管理几万行代码,如果连看都看不懂的话,那还管个毛线啊。因此笔者在这里介绍一些笔者使用的分析源代码的技巧,首先一定是不能直接一行行代码生啃的,尤其是在面向对象的项目中,稍微复杂一点就会涉及到大量的继承,多态,适配器....几十个类之间互相牵连,你啃几个月都不一定看的明白,但是在入了公司后,最多就是给你一周左右的看原码的时间,一般都会涉及几万行代码,然后就会给你分bug(指要修复的bug)和需求了,如果你做不到,那么就可以滚蛋了,也就是说在入职后,第一座大山就是分析源代码,因此分析源代码能力的重要性是不言而喻的。
下面就来介绍一下笔者分析源代码的方法,首先要看的不是代码,而是要搞清楚需求,即你要分析的源代码具体是要完成的任务是什么,起到的主要作用是什么,一定要先明确目的(一般来说公司内部都会有这方面的手册),比如上方的mm_struct,其主要目的就是描述出虚拟地址空间的全貌,明确了目的后,就要根据目的去源代码中寻找与目的相关的重点字段,在C++项目中一般来说就是要先找到一个具体的类,然后分析类中的成员变量所起到的作用,比如在mm_struct中找到的重点字段就是框出来的那些,然后最重要的一步就是要给这个类建模,说人话就是要画个图,把抽象的代码变成具体的图像,比如mm_struct中的虚拟地址空间的图像就是对mm_struct的一个建模,在理清楚了与目的直接相关的重点类的成员变量并为该类建模后,就要以已有的类模型为基础,去理清楚项目的结构,说人话就是要把已经理清楚的各个类之间关联起来,关联的方式有很多,比如继承,适配器等,但是其中最重要的就是数据结构,也就是链表,数组等,要知道无论多么复杂的项目,在整体代码中一定就分为两部分,即描述性代码和组织性代码,描述性代码中的核心就是一个个的类,而组织性代码中的核心就是数据结构,因此下一步要分析的就是源代码的数据结构,比如在之后要介绍的vm_area_struct中就是对mm_struct的具体组织结构,使用了红黑树和链表,然后就要通过数据结构把一个个类给联系起来,那么对于一个项目的整体大框架就有了,要注意的是,在这一步同样要进行建模,这非常重要(一定要画图),最后就可以着眼于你负责的那部分代码进行细节的分析了。
上方的分析并不一定就是完全适用于所有情况的,比如在面向对象的项目中,可能有一部分是使用继承和适配器等面向对象的方法进行类组织的,但是从大体上分析的步骤是一样的,都是先局部建模,再整体建模,要说明的时,在建模时并不需要搞明白类中每一个字段的作用,只需要搞清楚重点字段就可以了,比如在上方的mm_struct中,有50多行代码,但是其中的重点字段也就只有5,6行,只要分析清楚这5,6行就可以对mm_struct进行建模了,下面总结一下具体的分析流程,即:
| 明确需求->分析与需求直接相关的类并进行单体建模->根据数据结构/继承等关系进行范围建模->补充具体细节 |
当然实际场景多种多样,具体的分析方法也因人而异,笔者在此处仅仅只是提出了自己的一些见解,但是无论是何种方法,笔者在这里要强调的是:在分析源代码的过程中一定,一定,一定要时刻明确具体的需求和作用!一定,一定,一定要保持冷静!就算看不懂也不要慌,毕竟慌了就更看不懂了,在职场上,此时你就可以去问问你的前辈(因此搞好人际关系也是非常重要的,不能闷头高技术),如果你是个社恐的话也可以去问问AI,AI在大部分情况下无法直接给你答案,但是能够给你一个分析的方向。
下面让我们回到正题,继续分析虚拟地址空间的具体实现细节。
2.vm_area_struct(VMA)
我们可以明显的发现,在虚拟地址空间中划分出来的各个区域的属性是有很大的差异的,比如有的只能读(比如代码区),有的可读可写(比如栈区和堆区),有的可以动态申请,有的可以共享....这意味着如果只使用一个mm_struct管理所有的区域,那么就会变得非常的混乱,所以更好的做法应该是分而治之,即使用一个新的结构体把每一个区域单独的拎出来进行描述和管理,所以下面隆重介绍实现虚拟地址空间的另一个结构体,即vm_area_struct(通常称为VMA):
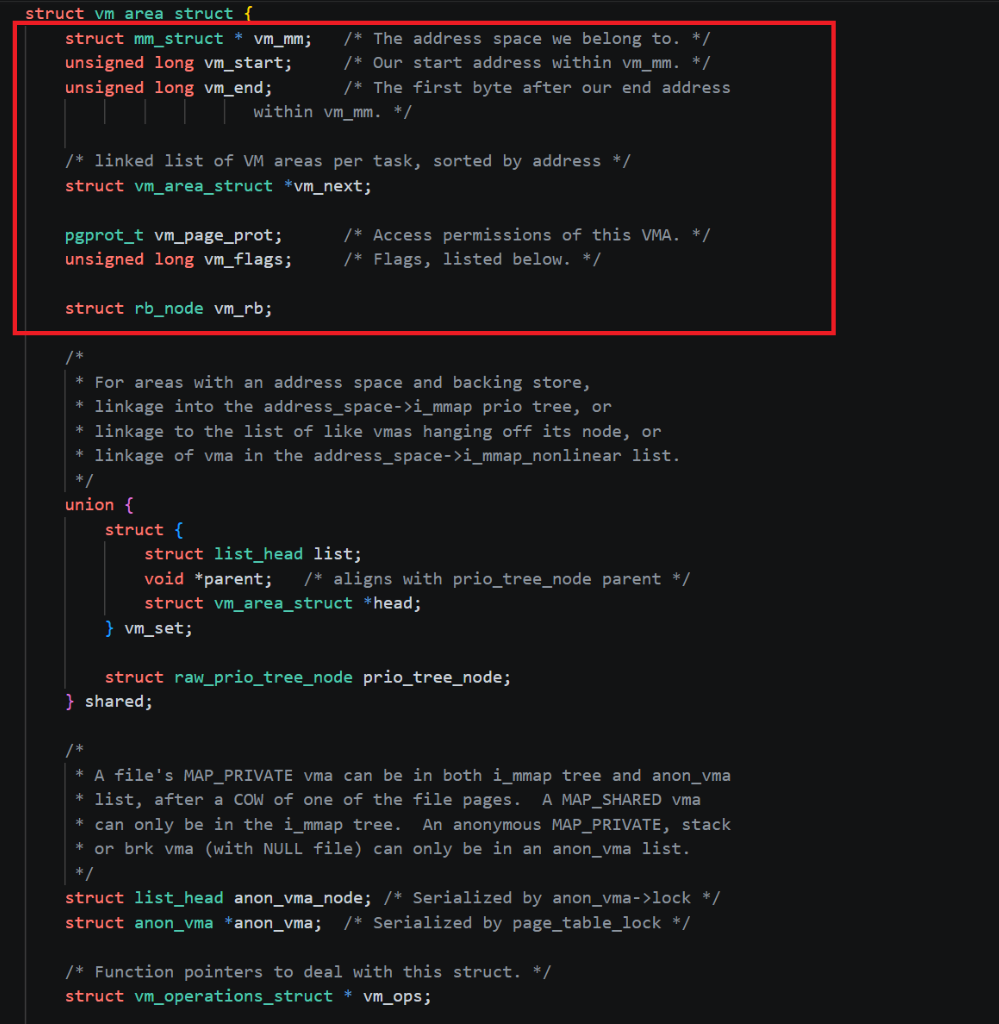
在上文对mm_struct的分析中可以明显看到,一个虚拟地址空间是会被分为多个段的,而每一个段都会使用一个vm_area_struct进行管理,这句话潜在含义就是一般来说每一个进程都会有一个独立的虚拟地址空间,也就是说操作系统只会给进程分配一个独立的mm_struct,而为了管理和组织虚拟地址空间中的段,操作系统会为一个进程分配多个vm_area_struct,也就是说一个进程会被分配一个mm_struct和多个vm_area_struct(单进程的情况下),要说明的是此处的段不一定就是虚拟地址空间中一个段,对于空间比较固定且范围较小的段(比如初始化区),一般是会只分配一个vm_area_struct进行管理的,但是对于占用空间范围大的段(比如堆区),分配vm_area_struct的机制比较复杂(尤其是堆区和栈区在运行时的范围还会动态变化),但是一般都不会是只分配一个vm_area_struct,具体细节在下文说明。
vm_area_struct的核心功能是组织,也就是说vm_area_struct中的核心是数据结构,因此就从数据结构开始分析,看看一个虚拟地址空间具体是怎么进行组织的,首先vm_area_struct采用红黑树+链表的数据结构进行组织,具体来说就是一个进程被分配的的多个vm_area_struct对象首先会被红黑树链接起来,每一个vm_area_struct对象就是红黑树的一个节点,并且各个vm_area_struct还会使用链表进行连接,也就是说该链表是一个嵌入式的链表,每一个vm_area_struct对象既是红黑树中的节点,又是链表中的节点,最简单的建模就是:
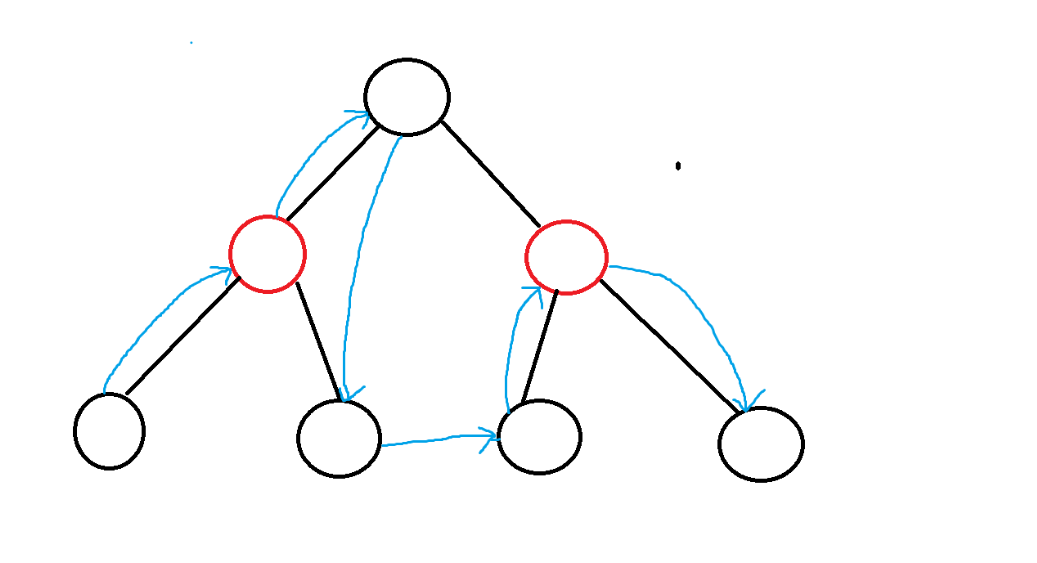
当然实际上红黑树的节点连接和链表节点的顺序肯定是有特定的规则的,上方仅仅只是最简单的建模,具体细节的讲解会在后面的vm_struct_area中进行。相信不是读者初次看到这种嵌入式的数据结构都是比较震惊的(笔者当时就被震惊到了),但是在这里要说明的是,在实际应用中,嵌入式的数据结构是非常常见的,但凡场景稍微复杂一点,就需要使用多个数据结构进行组合了,比如在epoll(多路复用)中,使用的也是类似的数据结构(红黑树+链表),希望读者之后在遇到复杂的场景时可以考虑到内嵌式数据结构的解决方案,如果内嵌式数据结构设计的好的话是可以大大提升代码的效率和空间利用率的(在select,poll和epoll中的对比就尤为明显(三个都是多路复用方案)),也就是说这种嵌入式数据结构一定是有一定的优势的,因此虚拟地址空间才会采用该方案,下面就来看看虚拟地址空间为什么要采用该方案,还要进行说明的是:在老版本的内核中,连接所有的vm_area_struct对象使用的是单链表(比如上方的2.6.24),使用的就是单链表进行主体的连接的,但是在4...版本往上就是使用双向链表进行所有vm_area_struct对象的连接了,一般来说,分析源代码时并不推荐直接分析最新的,因为版本越新就意味着代码越复杂,我们在分析源代码时分析的时逻辑,而不是代码,因此本篇bolg选择了经典的2.6...版本的内核进行分析。
要分析嵌入式的数据结构,首先应该将它们分开,即把红黑树+链表分成红黑树和链表,分开后,明显可以发现红黑树应该是为了快速搜索的,毕竟红黑树的主要优势就是搜索,而链表明显是为了快速进行遍历的,毕竟在空间不连续的情况下,链表就是遍历的最优解了。在实际使用中,一定是要经常在虚拟地址空间的各个段中进行跳转的,比如在创建函数时要在栈区进行操作,要动态申请空间时要在堆区进行操作....也就是说查找虚拟地址空间具体的一个段的操作是非常常用的,又由于各个段的地址不是连续的,因此数组这种O(1)查找的数据结构就不能使用了,那么红黑树这种链式的查找数据结构就是最优解了,因此vm_area_struct采用了红黑树作为主体的数据结构,而链表在实际使用中就是为了遍历所有vm_area_struct的(整个虚拟地址空间的所有段),在大范围的操作时,使用链表就非常快了,比如在进程结束要释放所有的空间时,就可以使用链表快速遍历所有的vm_area_struct释放进程使用的所有虚拟空间映射的物理空间了。但是真的是这样吗?了解红黑树和链表的读者就会知道,红黑树的遍历时间复杂度和链表的遍历时间复杂度是一样的(都是O(n)),那为什么还要在红黑树中嵌入一个链表呢?是那群写内核的人为了装逼秀操作吗?答案当然是否定的,写linux内核的人都是这个世界上最顶级的程序员,他们只会在意极致的效率,因此在这里要说明的是时间复杂度只是理论值,理论和实际是有差别的,但是具体的差别要在分析vm_area_struct的具体字段时才能够体现,因此下面就来分析vm_area_struct中的重点字段(框出来的那部分):
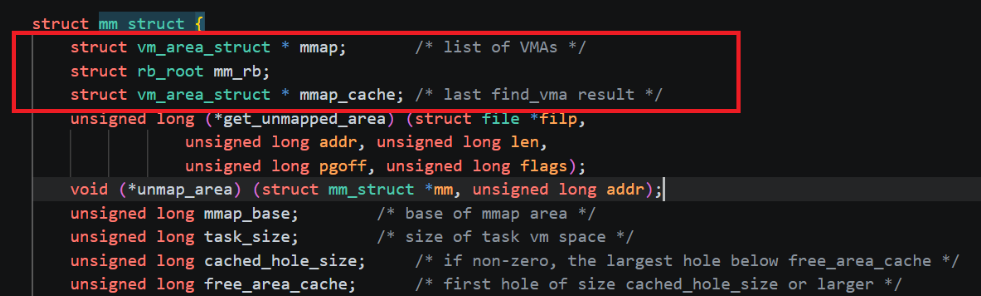
| vm_mm | 在本节之初就说明过,vm_area_struct是为了管理和组织mm_struct的各个段而诞生的,那么首先就得让vm_area_struct对象知道自己是属于哪一个mm_struct的(每一个进程的mm_struct对象都是独立的),因此该vm_mm指针就是回指向mm_struct的,比如一个进程的mm_struct对象描述了6个段,每一个段都有一个专门的vm_area_struct对象进行组织和管理,那么就会有6个vm_area_struct对象回指向该进程的mm_struct对象。 |
|
vm_start vm_end |
既然一个vm_area_struct对象是管理mm_struct中的一个段的,那么vm_area_struct对象当然要知道自己管理的段的具体范围,因此vm_start记录的就是该vm_area_struct对象管理段的起始虚拟地址,vm_end记录的就是该vm_area_struct对象管理段的结束虚拟地址。比如一个虚拟地址空间的大小是0到100,一共分为5个段,每个段的大小是20,那么就会使用5个vm_area_struct对象进行管理,第一个vm_area_struct的管理范围就是[0, 20),第二个就是[20,40).....在这里要强调一点:vm_are_struct是对整个虚拟地址空间进行划分和管理的,不是管理用户使用的虚拟地址空间。 |
| vm_next |
非常明显,该字段就是嵌入的链表了,是一条单链表,也就是说每一个vm_area_struct对象都会使用vm_next指向下一个vm_area_struct对象,"指向下一个"就是说该链表不是乱指的,具体来说这个链表是按照vm_area_struct对象管理虚拟地址空间范围的大小进行连接的,比如第一个vm_area_struct对象的管理范围是[0, 20),第二个是[20,40),第三个是[40, 60),那么这三个vm_area_struct对象的指向关系就是:[0,20)-->[20,40)-->[40,60),可以发现,肯定是要有一个指针指向该链表的头节点的,那么这个指针在哪呢?要时刻明确,vm_area_struct是为了描述mm_struct而生的,那么肯定就不仅仅得让vm_area_struct对象能够找到mm_struct对象,还得让mm_struct能够找到vm_area_struct,因此答案就非常明确了,这个指向头节点的指针会存放在mm_struct中,具体字段就是mm_struct中的mmap(上方有图)。(要注意的是在较新的版本的内核中,该链表已经被修改为双链表了,此处不作介绍) |
目前根据vm_mm,vm_start,vm_end和vm_next字段,我们已经可以描绘出vm_area_struct中的链表结构了,具体来说就是:
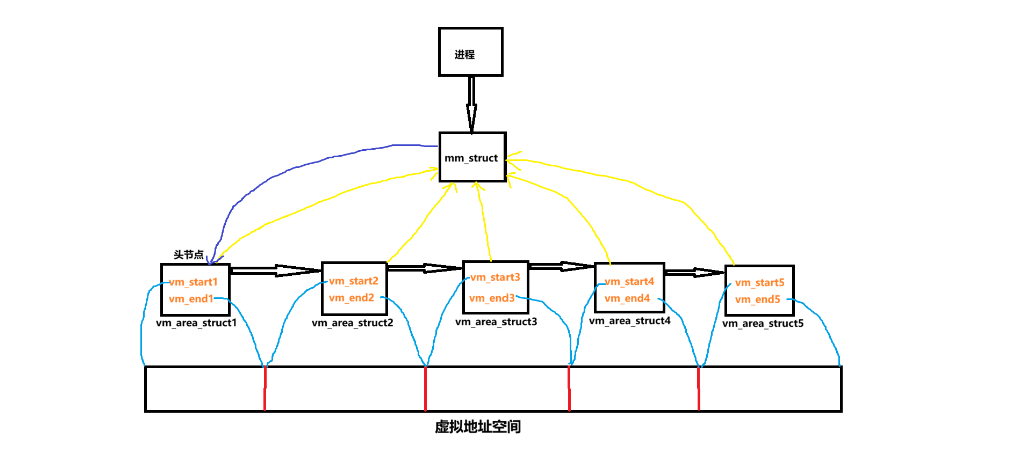
嵌入链表的结构已经明确,下面让我们来看看vm_area_struct中和红黑树有关的字段,要提前说明的是红黑树在vm_area_struct中的存在方式和链表其实是类似的,也是先使用红黑树把所有vm_area_struct对象连接起来,然后再在mm_struct中提供指向该红黑树根节点的字段,并不会非常复杂,下面来看看具体的字段:
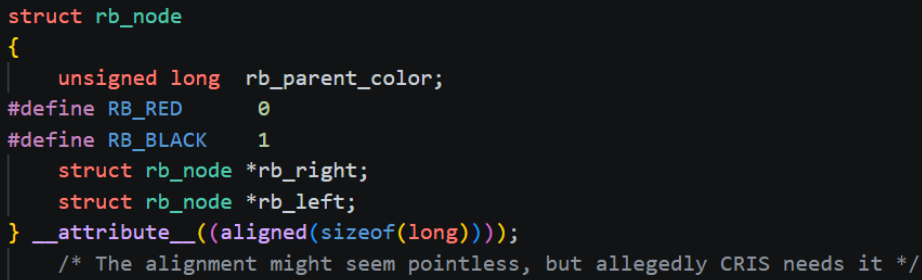
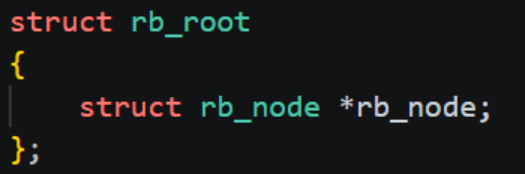
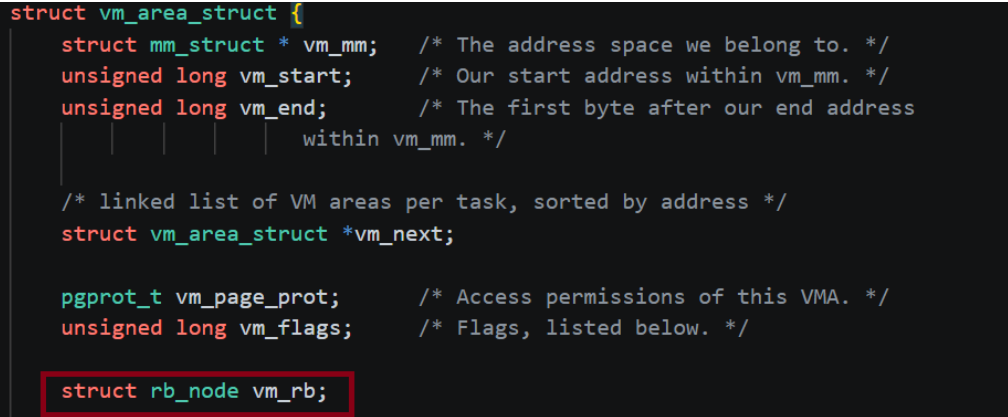

红黑树在虚拟地址空间中跨越的结构体比较多,但是其实这才是项目中的正常情况,在实际项目中一个类跨越连接几十个类都是常见的,对于这种情况,除了耐下性子一点点理顺外也没有其它方法了,因此下面就来理一下虚拟地址空间中的红黑树结构,首先实现红黑树的主要结构体是rb_node,显而易见该结构体是红黑树用于中存放左孩子指针,右孩子指针和节点颜色的,可以发现并没有直接在vm_area_struct中实现红黑树,内核采取的这种操作是让红黑树结构与红黑树节点存放的具体具体数据解耦了,简单来说就是无论是什么结构体,无论结构体中有什么东西,只需要往其中添加一个struct rb_root,那么该结构体就可以被连接到红黑树中,这种操作带来的另一个好处就是此时在一颗红黑树上连接的节点可以存放不同的数据,大大提高了红黑树的灵活性,要说明的是这种数据结构与存放的具体数据解耦操作在实操中也是非常常见的,是一种非常牛逼的设计思路(叫红黑树在虚拟地址空间中跨越的结构体比较多,但是其实这才是项目中的正常情况,在实际项目中一个类跨越连接几十个类都是常见的,对于这种情况,除了耐下性子一点点理顺外也没有其它方法了,因此下面就来理一下虚拟地址空间中的红黑树结构,首先实现红黑树的主要结构体是rb_node,显而易见该结构体是红黑树用于中存放左孩子指针,右孩子指针和节点颜色的,可以发现并没有直接在vm_area_struct中实现红黑树,内核采取的这种操作是让红黑树结构与红黑树节点存放的具体具体数据解耦了,简单来说就是无论是什么结构体,无论结构体中有什么东西,只需要往其中添加一个struct rb_root,那么该结构体就可以被连接到红黑树中,这种操作带来的另一个好处就是此时在一颗红黑树上连接的节点可以存放不同的数据,大大提高了红黑树的灵活性,要说明的是这种数据结构与存放的具体数据解耦操作在实操中也是非常常见的,是一种非常牛逼的设计思路(叫侵入式数据结构)。
现在读者最大的疑问应该就是,这个rb_node中的节点就只能指向rb_node啊,怎么能够指向vm_eare_struct呢?这个问题其实非常简单,rb_node确实无法指向vm_area_struct,但是它可以指向vm_area中的rb_node成员啊,也就是这样的:
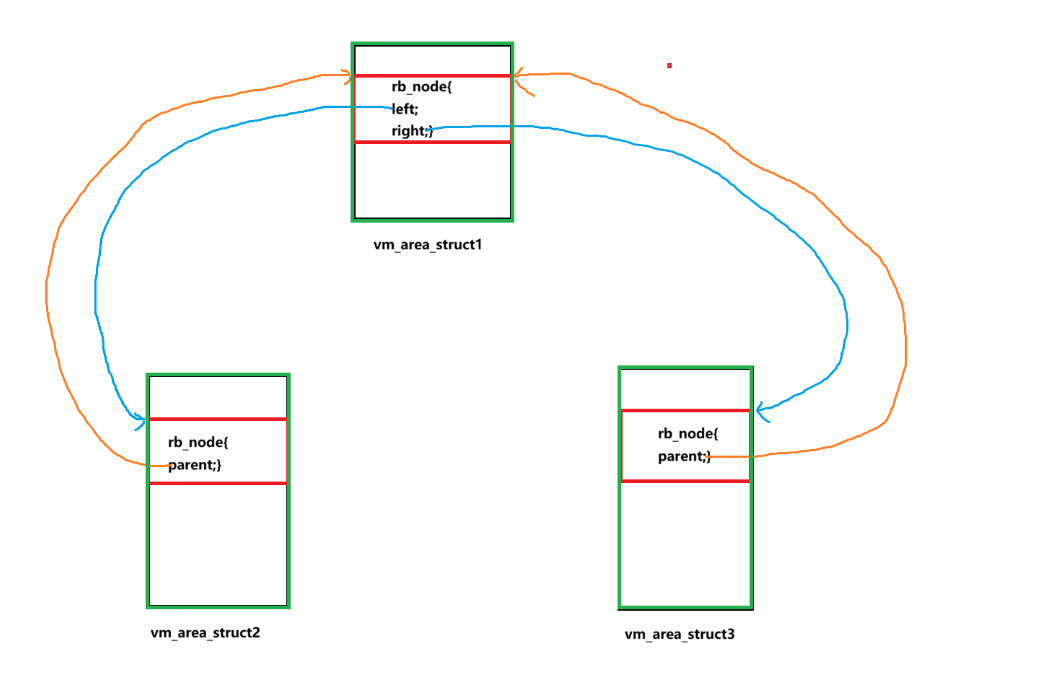
那么又出现了另一个问题:这只能指向vm_area_struct中间的位置啊,怎么能够完整的找到vm_area_struct中的所有字段呢,而且话说这根本就找不了吧,强制类型转换也不行的吧!这确实是一个非常严重的问题,那么下面就来看看要怎么解决,首先要明确一点,如果我们想要使用强制类型来找到一个结构体对象中的所有字段的话,那么就必须要获取该结构体对象首字节的地址,然后再对储存首字节的指针进行强制类型转换,比如:
struct test
{
int a;
char arr[10];
double b;
};
int main()
{
struct test t = { 1, "abcde", 3.14 }; //构建结构体test对象t
void* pt = &t; //此时pt指向t的首字节,但是pt是voit*类型的
//pt->a; //无法直接访问t的成员
printf("a = %d, arr = %s, b = %lf\n", ((struct test*)pt)->a, ((struct test*)pt)->arr, ((struct test*)pt)->b); //对首字节指针进行强制类型转换
return 0;
}
这个知识属于C语言的指针的范畴,简单来说就是指针类型决定了编译器看待一个地址的方式,因此在获取了一个结构体对象的首字节指针后,只需要使用强制类型转换让编译器以该结构体类型的方式看待该指针就能够访问到结构体对象中的所有成员了,想要了解指针的可以去看看笔者写的blog:C语言的指针(不是那本著名的《C语言的指针》,当然读者如果有时间去看看这本书就更好了),下面回到正题,我们现在拥有的是结构体的类型:vm_area_struct和指向结构体对象中某一个字节的指针,目标是获取到结构体对象中的所有字段,那么思路就非常明确了,我们需要使用某种方法获取vm_area_struct结构体对象的首字节指针,收悉C语言的读者应该知道,使用一个指向结构体对象任意位置的指针来获取结构体对象首字节的指针是完全可行的,比如使用offsetof,offsetof的具体实现并不属于本篇文章的范畴,因此只提供一个大概验证代码来证明这确实是可行的:
struct test
{
int a;
char arr[10];
double b;
};
int main()
{
struct test t = { 1, "abcde", 3.14 }; //构建结构体test对象t
double* pb = &t.b; //对象中间的指针
long long i = (long long)(&(((struct test*)0)->b)); //求出偏移量
printf("a = %d", ((struct test*)((long long)pb - (long long)i))->a);
return 0;
}
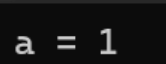
如果想要了解具体的细节,在笔者的C语言的指针中有介绍,问题到这里就已经解决了,这个侵入式的红黑树的实现流程就是:先利用vm_area_struct对象中的rb_node指向其它vm_area_struct对象中的rb_node成员构建出树形结构,再利用offsetof的技术(在内核中不叫offsetof,但是原理是一样的)就可以获取每一个vm_area_struct对象中的所有字段了。最后要说明的是该设计是一个牛逼到爆炸的操作,在Linux内核中大量使用了该技术,利用该操作可以使用C语言模拟出C++的多态和继承行为(内核中就是怎么做的),又或者说其实C++中的多态和继承就是使用类似的技术实现的,只不过进行了更完善的封装。
细心的读者应该发现了,在rb_node中并没有指向父节点的指针,但是有一个名称非常奇怪的东西,即unsigned long rb_parent_color;既带了parent,又带了color,从名称上来看,这个东西应该和父节点指针和节点颜色都有关,这就是Linux内核中的另一个牛逼的设计思路了:极致的空间节省,简单来说就是把父节点的地址和节点颜色压缩在一起了,具体原理就是由于结构体内存对齐规则,在rb_node中会有几个字节被浪费掉,而红黑树节点的颜色只需要一个bit位就可以表示了,那么就完全没必要为其单独设置一个字段,在实际操作时可以使用位运算把rb_parent_color中的父节点指针和本节点颜色分开提取出来(具体方法可以去问问AI,这里不做介绍)。有读者可能会问了,不就几个字节吗,浪费了又怎样,为什么要让代码的可读性变得这么差呢?答案很简单,在这里只是一个vm_area_struct浪费了几字节,要知道在电脑运行时少说也会同时运行几百个进程,每个进程都会分配多个vm_area_struct对象,那么同时存在的vm_area_struct对象就是一个非常恐怖的数字了,此时能够省下来的空间就非常可观了。
上方的内容更多介绍的是Linux内核的设计思想与侵入式红黑树的实现原理,理解了这些内容后剩下的就非常简单了,只需要进行结构体之间的组织就可以了,所以下面就让我们回到具体的字段中:
| vm_struct中的vm_rb | 我们现在已经知道,只要把struct rb_node设置到任意一个结构体中,那么该结构体就可以变成红黑树结构,也就是说vm_struct中的红黑树结构就是使用rb_node中的指针来实现的,还要进行补充的是该红黑树使用vm_area_struct对象管理的虚拟地址空间段的起始地址作为键值,也就是vm_start,而红黑树本质上是一个二叉搜索树,也就是说其满足:对于树中的任意一个节点,其左子树中所有节点的vm_start都小于它自己的 vm_start,其右子树中所有节点的vm_start都大于它自己的 vm_start,在就意味着在中序遍历遍历该红黑树时,得出的结果就是有序的(遍历的所有vm_area_struct对象管理的虚拟地址范围从小到大,比如[0,20)-->[20,40)-->[40,60)) |
| mm_struct中的mm_rb |
mm_rb的类型是rb_root结构体, 在该结构体中就只有一个rb_node的指针,显而易见这个mm_rb就是指向由vm_area_struct对象构成的红黑树的根节点的,仅仅只是封装了一层。总有一种脱裤子放屁的感觉,为什么不直接吧mm_rb的类型设置为rb_node*呢?这就又要提到另一个Linux牛逼的设计思路了:保证接口(API)的一致性,清晰性和代码的可读性,不要小看这些看似无用的东西,有一定编程经验的人就会知道接口的一致性是多么的重要,剖析过大型项目源代码的人就会知道清晰性和可读性是多么的重要。 下面就来简单的介绍一下该操作起到的作用:首先是名称方面,rb_root代表根,rb_node代表节点,对人来说,一目了然,对编译器来说,在编译阶段就杜绝了把中间节点当根的错误(比如在插入节点时参数就是这样的:void rb_insert_color(struct rb_node *node, struct rb_root *root);如果不小心往第二个参数中传 |
和红黑树有关的字段比较少,但是其中的设计思路是非常复杂的,在Linux内核中的其它地方也大量的使用了这些设计思路,总结一下就是:
1.嵌入式数据结构:把多个不同的数据结构组织起来,应对复杂的需求和不同的场景。
2.侵入式数据结构:让数据结构与存放的具体数据解耦,大大提高了数据结构中存放数据的灵活性。
3.利用偏移量和指针类型实现字段的提取。
4.利用位运算实现极致的内存利用。
5.保证接口(API)的一致性,清晰性和代码的可读性。
现在已经在字段上解析完了虚拟地址空间的核心数据结构,最后一步就是把解析结果进行建模,即:
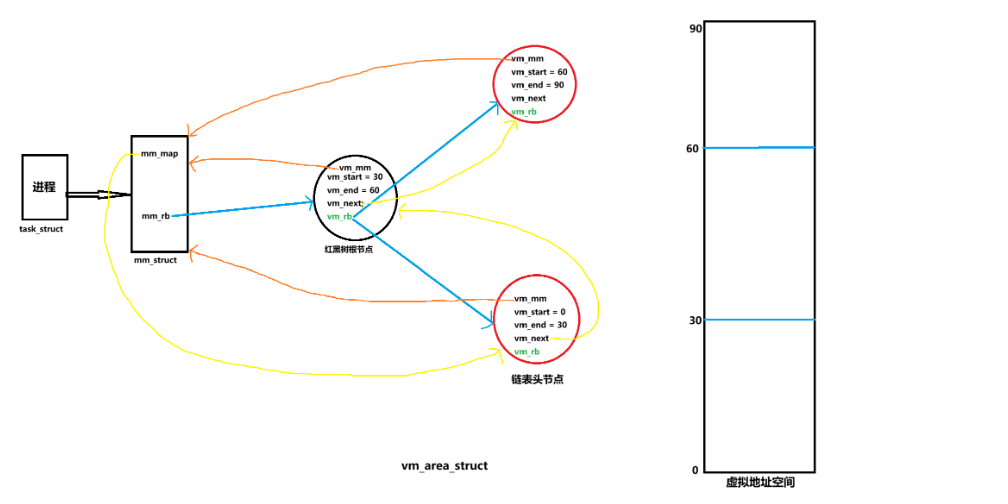
画的比较丑,其实最好是读者在看完了上面的内容后自己画一张图,毕竟自己画出来的才真的是"自己的"。下面来回答开始提出的问题:红黑树遍历的时间复杂度也是O(N)的,和链表是一样的,并且利用红黑树二叉搜索树的性质,采用中序遍历时遍历的大小也是有序的,和链表起到的效果也是一样的 ,那么为什么还要嵌入一个链表?
首先最好理解的一个原因就是链表的遍历非常简单,只要一步就可以了,而红黑树的遍历涉及递归,循环,而简单就意味着不容易出错,意味着CPU实际执行的指令更少,从代码的健壮性和CPU的效率来看,尽管时间复杂度相同,但是链表的遍历是更快,更简单,效率更高的,打个比方,你是喜欢遍历红黑树还是喜欢遍历链表?答案是非常明确的,就算是红黑树的创造者来了也会回答更喜欢遍历链表。
在说明第二个原因前,要先补充一个重要的细节(也是为下文的页表讲解进行过渡):说vm_area_struct管理的是虚拟地址空间是没错的,但是有点细节的偏差,比如虚拟地址空间中也是分为用户已使用的虚拟地址和未使用的虚拟地址的,那么vm_are_struct管理的是已使用的还是未使用的呢?从直观上来看,当然要管理已使用的,毕竟这部分才是进程实际使用的,才是有意义的,但是"已使用"在虚拟地址空间中也是分为多种情况的,大体上分为三种情况:
1.进程已经使用了虚拟地址,并且这部分虚拟地址也已经被映射到物理地址上了,那么此时就可以直接向其中(物理空间)中存储数据。
2.进程没有实际使用虚拟地址,但是操作系统许诺给进程了一片虚拟地址。
3.进程使用了非法的虚拟地址(这个非法也是有说法的)。
在三个概念在页表中才会有明显的体现,并且理解这三种情况也是理解页表的关键,说具体一点就是:情况1是虚拟地址填入了页表,并且页表也进行了向物理地址的映射,这部分空间可以存储实际数据,情况2就是虚拟地址没有填入页表,但是操作系统承诺这部分虚拟地址是属于该进程的,情况3就是使用了操作系统没有许诺给进程的虚拟地址,最抽象的就是情况2和3了,这个承诺是个什么鬼东西?先来想想看现实生活中的承诺是什么,不谈什么君子一言,承诺的本质上不就是一个描述嘛,只不过比较复杂罢了,而要描述复杂的东西,当然就是要使用结构体的了,这个结构体我们已经非常熟悉了,没错,其实就是vm_area_struct,操作系统承诺,只要是记录在VMA范围中(vm_start到vm_end)的虚拟地址,都是进程可以使用的,也就是说vm_area_struct管理的实际上是在虚拟地址空间中操作系统承诺给进程的所有虚拟地址,在承诺的虚拟地址中,有些是进程已经使用了的(映射到了物理地址),有些是还没有使用的,对于已经使用的部分是很好理解的,比如定义一个int a = 10;那么就有4字节虚拟地址被使用了(映射到了物理空间并存储了有效数据),那么这个未使用的部分又是什么鬼呢?打个比方,你使用了malloc申请了1000字节的空间,但是距离你实际使用申请的空间还要过个几秒钟(你可能要先经过几个循环判断后才使用),那么在这几秒钟内,操作系统有必要给你分配实际的1000字节的物理空间吗?那当然是没必要的嘛,在1000字节完全可以先另作他用,这不就大大提高了内存的利用率了吗,那么在这几秒钟内,这1000字节就是操作系统承诺给你的虚拟地址,具体来说就是给进程分配了一个vm_area_struct对象,其中vm_end-vm_start=1000,但是这1000字节的虚拟地址并没有被放入页表进行映射。
也就是说vm_area_struct管理的虚拟地址并不是虚拟地址空间的一个个大段,而是根据用户的实际需要进行范围管理的,一个vm_area_struct对象管理的范围也有说法,一般来说这个范围不能太大,也不能太小,那么为了让这个范围适度,就可以体现出嵌入式链表的另一个优势了。
现在假设一种情景,你先malloc了1000字节,然后又malloc了50字节,此时操作系统是不会创建两个vm_area_struct对象分别管理这两次malloc的内存的,而是会进行合并,直接使用一个vm_area_struct对象管理1050字节,也就是说对于小范围申请的权限相同的虚拟地址,一般都是不会分配一个vm_area_struct进行管理的,而是会选择将其合并到另一个大范围的vm_area_struct中。此时出现了一个问题:在合并时是先创建出vm_area_struct对象再进行合并,还是直接进行合并?比如上方的例子,是会先创建出一个1000字节的vm_area_struct和一个50字节的vm_area_struct,然后再合并两个vm_area_struct对象成一个vm_area_struct对象,还是会不创建那个50字节的vm_area_struct,直接把这50字节合并到1000字节的vm_area_struct对象中?答案其实非常简单,那个50字节的对象是必须创建的,因为如果不实际的创建出来,就无法得知其具体管理范围,字段权限等信息了,也就是说对于小范围的内存申请,其vm_area_struct会短暂的存在,当其被链入红黑树和链表后,操作系统会根据其中的字段信息和其相邻的节点信息判断是否可以进行合并(判断流程非常复杂,这里不多介绍)。
那么此时,如果使用红黑树进行合并,就会非常的恶心了,会涉及到节点的旋转和颜色变化,具体算法会非常复杂,但是如果使用链表的话,链表天生就可以进行合并,并且是O(1)的时间复杂度,只需要改变一下vm_start和vm_end的值就可以了,因此从这个角度来看,这个嵌入的链表也是必须的。最后要说明的是,嵌入的链表还会存在很多其它优势,比如在创建子进程时可以快速拷贝父进程的虚拟地址空间结构,可以提高CPU的命中率等,此处不再做过多说明(上方的两个理由已经可以说明这个嵌入的链表是必须的了),感兴趣的读者可以去问问AI。
3.小结
关于进程与虚拟地址空间的关系,还存在相当多的细节,比如在mm_struct和vm_area_struct中还有不少重要的字段,又比如子进程和虚拟地址空间的关系是什么(后续文章介绍),在此处不再介绍(本篇的篇幅已经够长了)。

openEuler 是由开放原子开源基金会孵化的全场景开源操作系统项目,面向数字基础设施四大核心场景(服务器、云计算、边缘计算、嵌入式),全面支持 ARM、x86、RISC-V、loongArch、PowerPC、SW-64 等多样性计算架构
更多推荐



 9
9 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)