操作系统之线程
引言
这篇文章是基于阅读完《操作系统导论》之后的总结,如果大家希望能真正理解操作系统,这一本书我真的很推荐
并发:介绍
进程是资源分配的基本单位,而线程是任务器进行任务调度的最小单位
线程和进程在某一些程度上是差不多的,所以我们可以类比一下
对于进程,我们有PCB,而对于线程,我们也有,叫TCB,保存每一个线程的状态。但是线程之间的上下文切换有一点主要的区别:地址空间保持不变(即不需要切换当前使用的页表)
线程和进程之间的主要区别在于栈,在传统的进程地址空间模型可以称为单线程,只有一个栈
但是在多线程运行的时候,每个线程可以单独运行,所以不是地址空间只有一个栈,而是每个线程都有一个单独的栈。对于这个单独的空间,每个线程可以存放自己的私人物品,也就是变量,返回值,这个地方也被称为线程本地。
我们需要了解怎么样创建线程
#include <pthread.h>
#include <stdio.h>
#include <assert.h>
void *mythread(void *arg){
printf("%s\n", (char *)arg);
return NULL;
}
int main(){
pthread_t p1, p2;
int rc;
rc = pthread_create(&p1, NULL, mythread, "A");
rc = pthread_create(&p2, NULL, mythread, "B");
rc = pthread_join(p1, NULL);
assert(rc == 0);
rc = pthread_join(p2, NULL);
assert(rc == 0);
return 0;
}
大家可以看到线程的创建需要四个参数,第一个是线程号,第二个是线程的属性,一般是NULL,第三个是线程里要执行的函数,第四个是函数需要传递的参数,如果要多个参数就传递结构体。
我们还注意到函数的返回类型是void* 传递的参数也是void*,其实这也就是方便我们传递结构体和返回结构体的


大家可以看到,其实线程的运行并不是谁先创建谁先执行的,这似乎很像进程的创建。我们之后会解释
而线程的运行,都是并发的,这也让情况变得很糟糕
线程因为是共享一个进程的数据,所以那些全局变量,每个进程都会访问到,我们也把这些共享的数据叫做临界区。
那么这就会引出一个巨大的问题,我们会用例子说明这个问题
我们先建立一个背景:
有两个线程,每个线程的任务都是对于同一个全局变量a++,每个进程都运行10000次,按照我们的道理来说,在这个程序结束之后,我们得到a的值应该是20000,但是很糟糕的是,这个值比20000小很多,而且每一次运行得到的结果都不一样
首先解决这个问题时,我们需要对汇编语言有一定的了解,一个数进行++并不是直接一个操作,而是三个操作,先是寄存器先读取a的值,然后向寄存器里面加1,最后把这个值放回去。
我想大家已经想到了问题所在,如果一个进程的寄存器刚好读取了a的值,很不幸的是,这个时候时间片到了,发生了中断,这个时候操作系统就会把这个线程的所有状态都保存在TCB中,然后更糟糕的发生了,线程2被选中了,他也跑到CPU上运行,他也对a++,运行了半天之后线程1回来运行,但是,这个线程1会继续执行之前没有执行的操作,也就是对原来的那个a加1,然后把这个值放回去,那这个a的值很明显不对,他把线程2的所有努力全部浪费了,很悲伤,很难过。所以这个a最后的值就不可能到20000。
原子性
所以我们要解决这个问题,我们需要保证操作是原子性的,让那些改变全局变量的操作一次性执行完,然后再执行其他操作。
似乎这个想法很完美,但是执行这个想法是一个令人头晕的问题。其中一个问题就是当一个线程进入临界区的时候,另一个也想进入临界区的线程是睡觉呢,还是持续循环等待呢
插叙:线程的API
在解决这些难题的前面,我们还是要做一点铺垫。
这是一个很经典的例子
#include <pthread.h>
#include <stdio.h>
#include <assert.h>
#include <stdlib.h>
typedef struct myarg_t{
int a;
int b;
}myarg_t;
typedef struct myret_t{
int x;
int y;
}myret_t;
void* mythread(void* arg){
myarg_t* m = (myarg_t *) arg;
printf("a = %d, b = %d\n", m->a, m->b);
myret_t *r = malloc(sizeof(myret_t));
r->x = 1;
r->y = 2;
return (void*) r;
}
int main(){
int rc;
pthread_t p;
myret_t* m;
myarg_t args;
args.a = 10;
args.b = 20;
rc = pthread_create(&p, NULL, mythread, &args);
/*
pthread_join 等待线程结束,然后将线程的返回值传到 m 中
我们这里的m是一个指针,但是并没有初始化,所以我们需要传递m地址,最后函数返回的一个指针就跑到了m的地址里面,相当于给m赋值了
*/
rc = pthread_join(p, (void**) &m);
printf("x = %d, y = %d\n", m->x, m->y);
return 0;
}
如果你想等待一个进程结束之后再执行后面的代码,让代码更有层次感,那么join()是一个很好的选择
不过我们也需要注意
如果我们没有这一行代码:myret_t *r = malloc(sizeof(myret_t));会发生什么
函数是在栈空间上,如果这个函数运行完,那么所有的数据都会消失,所以我们得到了一个野指针,这个指针不知道指向哪,那个地方有什么。
锁
我们这里仅仅只简单的介绍一下锁的性质:
一个线程想要进到临界区,就必须要拿到锁,而一个临界区只有一把锁,如果有线程已经拿到了锁,那么这个线程无法进入临界区,直到锁被释放
条件变量
当线程之间必须发出某种信号,如果一个进程正在等待另一个进程执行某些操作,那么条件变量就很有用,而条件变量实际上就是一个队列。这个我们之后会详细讲解。
锁
在最早的时候,我们实现锁的办法是关闭中断。这看上去是一个很聪明的办法,但是实际想想就很不靠谱。关闭中断就意味着CPU的时间中断无法起作用,那操作系统就无法dedaoCPU的控制权,那么问题就很大了。我们只有等着这个线程自己执行完,然后打开中断。但是这个线程自己执行完听起来就很扯淡,如果这个线程不怀好意,一直死循环,那这个电脑只能重启了。或者如果在这个线程执行的时候,有一个线程发出来I/O请求,但是因为中断的关闭,我们就忽略了这个请求。
所以我们需要想想其他办法。
Peterson算法
这里我们设置了两个变量,一个是turn,表示的是轮到某个进程了,还有一个是interested,表示这个进程是否愿意进入。
所以我们每次进入临界区的时候,我们都要判断一下,是不是轮到对方进入,并且对方愿意进入。
所以这种算法我们也叫其”谦让“算法。
比如我先准备进入临界区,但是因为谦让,说你来你来,如果没有轮到你,我就直接进入,但是如果在进入的过程中时间片到了,轮到了你,你因为谦让,也说你来你来,最后谁是最后一个谦让的那被谦让的就进去。
#define TRUE 1
#define FALSE 0
// 临界区代码段
extern void critical_region();
// 非临界区代码段
extern void noncritical_region();
int turn; // 记录当前“轮到”哪个线程进入临界区
int interested[2]; // 记录每个进程是否愿意进入临界区
/*
A B
*/
void enter_region(int process){
int other = 1 - process; // 进程的编号就是0或者1
interested[process] = TRUE; // 标记本进程希望进入临界区
turn = other; // 尝试将turn设置为另一个进程的编号
// 等待条件:检查对方是否也想使用,且最后一次是谦让
while(interested[other] == TRUE && turn == other);
}
void leave_region(int process){
interested[process] = FALSE; // 标记本进程已离开临界区了
}
void process0(){
do{
enter_region(0);
critical_region();
leave_region(0);
noncritical_region();
}while(TRUE);
}
void process1(){
do{
enter_region(1);
critical_region();
leave_region(1);
noncritical_region();
}while(TRUE);
}
锁就是一个变量,一个进程进入临界区必须要持有锁,当这个线程离开临界区的时候就必须要释放锁。每次进入临界区的时候都要判断临界区的锁是否自由可用,如果有线程已经拿到了这把锁,那么这个线程有一下两种操作:
1、睡觉(互斥锁)
2、反复询问(自旋锁)
我们可以简单的思考一下,这两个锁其实都有他们自己的优势和缺点
对于互斥锁,它的优点就在于不占用CPU,当锁被释放的时候才会被唤醒,提高CPU的效率,但是缺点就是从阻塞态到就绪态需要系统调用,模式的切换会让性能变低
对于自旋锁,反复的询问让这个进程不需要变成阻塞态,所以不需要发生内核的系统调用,但是缺点也很明显,他很占用CPU
所以如果一个任务的时间很短,我们可以选择自旋锁,但是对于一个很长的任务,我们选择互斥锁。不过很长是相对的,那一些过长的任务,我们有另外的解决办法,我们之后再说。
自旋锁
那么我们这个里还是先实现一下一个简单的自旋锁
原理也很简单,得到了锁就标记为1,当释放锁就把锁标记为0
int lock = 0;
// 临界区代码段
extern void critical_region();
// 非临界区代码段
extern void noncritical_region();
void process0(){
while(1){
// 进入临界区
// 判断是否有锁,如果没有锁,死循环等待锁被释放
while(lock);
// 加锁
lock = 1;
critical_region();
// 释放锁
lock = 0;
noncritical_region();
}
}
void process1(){
while(1){
// 进入临界区
// 判断是否有锁,如果没有锁,死循环等待锁被释放
while(lock);
// 加锁
lock = 1;
critical_region();
// 释放锁
lock = 0;
noncritical_region();
}
}单变量轮询机制:
原理也就是轮到你了就进入,否则就循环等待
int turn; // 记录当前“轮到”哪个线程进入临界区
// 临界区代码段
extern void critical_region();
// 非临界区代码段
extern void noncritical_region();
void process0(){
while(1){
// 准备进入临界区,轮询判断当前进程是否可以进入
while(turn == 0){
critical_region();
turn = 1; // 标记当前可以进入临界区的是进程1
noncritical_region();
}
}
}
void process1(){
while(1){
// 准备进入临界区,轮询判断当前进程是否可以进入
while(turn == 1){
critical_region();
turn = 0; // 标记当前可以进入临界区的是进程0
noncritical_region();
}
}
}
总结一下,在自旋的代码里面,最好都是while(),不要用if判断
test and set
这是一个硬件支持的测试和设置的指令
这个过程大概就是第一个线程进入临界区,调用lock(),检查标志是否为1(这里不是1),然后设置为1,表示线程持有该锁。结束临界区的时候,调用unlock()函数,将标志设置为0,表示锁未被持有。
test_and_set是专门针对atomic_flag自旋锁使用的,用法是先观察有没有锁,如果别的线程正在用这把锁,那说明这里有锁
有锁的话就返回true,然后一直while循环,但是因为这样CPU的占有率就很高,所以选择线程让步的方式,时不时来询问一下
如果这里没有锁,那么就直接拿来用,并且把这个位置改成true,告诉之后来访问的线程,我正在用这把锁,你不能用这把锁了,然后返回false,不进行这个循环
条件变量
我们看到了通过硬件和操作系统支持实现了锁,但是锁并不是我们程序设计的唯一原语。
具体来说,在很多情况下,线程需要检查某一条件满足之后才会执行,比如父进程需要等待子进程结束。
线程可以使用条件变量,来等待一个条件变为真。条件变量是一个显式队列,当执行某种状态不满足的时候,线程可以把自己加入队列,等待该条件。另外一个线程改变了上述状态,就可以换成一个或多个的状态,让他们继续执行。这种思想被称为条件变量。
换一句话说,就是自旋太浪费CPU了,我们需要一种简单而又强势的方法。当进程无法获得临界区的时候,睡觉。等到别人从临界区出来,唤醒这个进程。
条件变量有两个操作,一个是wait(),线程要睡觉时,调用这个,一个是signal(),线程要唤醒等待在某个条件变量上的睡眠进程时,用signal()。
wait()这个函数有两个参数,一个是条件变量的队列,一个是一把锁。
前提当你拥有一把锁的时候,你调用wait(),你就会到队列里面睡觉,并同时释放掉这一把锁;当你被唤醒的时候,重新执行这个wait()函数,然后获得那一把锁,继续往下执行程序。
!!!!注意,这个唤醒是从阻塞态变成了就绪态,但是下一个程序是不是运行它,不好说。
生产者消费者问题
假设有一个或多个生产者,和一个或多个消费者线程。生产者负责把数据放到缓冲区,消费者负责把数据从缓冲区取走。
其实这个方法一不小心就会有很大的问题
假设有两个消费者,和一个生产者。
消费者1先执行拿到锁,发现没有东西,睡觉并释放锁。然后唤醒生产者,生产者生产了一个东西之后唤醒了消费者1,消费者1从阻塞态变成了就绪态。那这个时候问题来了,如果过了一会消费者2来了,它发现锁是自由的,里面也有东西,于是它拿了锁开始运行,把里面的东西全部拿走了,但是消费者1不知道,当它开始运行的时候,发现里面已经没有数据了,就会出现bug。
我们能避免这个问题的就是用while(),任何if都变成while(),每次执行的时候都要判断。
基于上述的问题,我们给出了代码:
#include <stdio.h>
#define FALSE 0
#define TRUE 1
/* 缓冲区 slot 槽的数量 */
#define N 100
/* 缓冲区数据的数量,使用 volatile 关键字防止编译器优化掉不必要的读取 */
volatile int count = 0;
extern void consumer(void);
// 模拟生成数据项的函数(示例)
int produce_item(void) {
// 这里应该实现生成数据项的逻辑,这里简单返回静态值作为示例
static int item = 0;
return ++item;
}
// 模拟消费数据项的函数(示例)
void consumer_item(int item) {
// 这里应该实现消费数据项的逻辑,这里仅打印作为示例
printf("Consumed: %d\n", item);
}
// 假设的插入数据项到缓冲区的函数(需具体实现)
void insert_item(int item) {
// 这里应实现将数据项放入缓冲区的逻辑
// 注意:实际实现中可能需要考虑缓冲区同步和互斥访问
}
// 假设的从缓冲区移除数据项的函数(需具体实现)
int remove_item(void) {
// 这里应实现从缓冲区取出数据项的逻辑
// 注意:实际实现中同样需要考虑同步和互斥
return 0; // 示例返回
}
// 模拟系统调用 sleep,这里使用忙等待(实际应使用系统提供的阻塞机制)
void sleep(void) {
// 这里仅为示例,实际应使用系统提供的 sleep 函数
// 在这里,我们简单地让出 CPU 时间片,但这不是真正的 sleep
// 实际应用中,应使用如 POSIX 的 sleep() 或 Windows 的 Sleep()
}
// 模拟系统调用 wakeup,这里假设有某种机制可以唤醒其他线程或进程
void wakeup(void (*func)(void)) {
// 这里仅为示例,实际应使用如 POSIX 的 pthread_cond_signal 或 Windows 的 SetEvent
// 这里我们不做任何操作,因为真正的唤醒机制依赖于操作系统
}
// 生产者
void producer(void ) {
int item;
while (TRUE) {
item = produce_item();
// 如果缓存区是满了,就阻塞(忙等)
while (count == N) {
sleep();
}
insert_item(item);
count++;
if (count == 1) {
wakeup(consumer);
}
}
}
// 消费者
void consumer(void) {
int item;
while (TRUE) {
// 如果缓存区是空的,就阻塞(忙等)
while (count == 0) {
sleep();
}
item = remove_item();
consumer_item(item);
count--;
if (count == N - 1) {
wakeup(producer);
}
}
}信号量
信号量是一个有数值的对象
对信号量有两个操作,一个是down(),这个操作又被叫做P操作,大致的意思就是减少一个信号量的值,如果这个信号量值小于0,那么这个线程就睡觉。
一个是up(),这个操作又被叫做V操作,大致的意思就是增加一个信号量,如果有等待的进程,那么就随机唤醒一个
大家可能会有一些疑问,就是如果up()操作之后这个数还是小于0,那么还需要唤醒吗?
答案是肯定的,我们需要思考一下这个信号量的值是什么。当这个信号量的值大于0的时候,代表着还有多少个数据,当这个数据等于0的时候,说明数据已经完全被用了。当这个数据小于0的时候,代表着有多少个进程等待被唤醒,当有一个资源被释放的时候,肯定要随机唤醒一个进程。
这个信号量其实是一个结构体,里面不仅仅有一个值,还有一个队列
但是我们还是有问题,这个消费者和生产者都在睡觉的时候,如果他们放在同一个队列里面,那不是容易弄混。可能本来应该唤醒生产者的变成了消费者,这很糟糕了。
那么我们可以实现一下这个情景
我们需要两个队列,一个是存放生产者(full),一个是存放消费者(empty),每一次生产者生产的时候,都会对empty的信号量减1,当减到0的时候,说明缓存区已经满了,而这个减法操作是要用锁的操作,这个问题我们等会会讲。当减法操作完了之后,说明缓冲区已经有了数据,那么就要对full信号量加1,告诉在full信号量队列里面睡觉的消费者可以开始读数据了。
那消费者读数据的时候,先对full的信号量减1,当减到0的时候说明缓冲区的数据已经没了,然后当减法操作结束后,说明读了一个数据了,那么要对empty信号量加1,从而唤醒在empty信号队列里面的生产者需要生产数据了
#include <stdio.h>
#include <sys/types.h>
#define FALSE 0
#define TRUE 1
/* 缓冲区 slot 槽的数量 */
#define N 100
struct queue{ pid_t pid;};
// typedef struct {
// int value;
// struct queue wq;
// } semaphore;
typedef int semaphore;
extern void down(semaphore *);
extern void up(semaphore *);
int produce_item(void) {
static int item = 0;
return ++item;
}
void consumer_item(int item) {
printf("Consumed: %d\n", item);
}
void insert_item(int item) {
}
int remove_item(void) {
return 0;
}
/* 标明缓存区有空位置的个数 */
semaphore empty = N; // 缓存区初始化时有N个空位
/* 标明缓存区已经放入资源的数量 */
semaphore full = 0; // 缓存区初始化时有0个可用资源
/* 控制区临界区互斥访问 */
semaphore mutex = 1; // 表示互斥锁
// 生产者
void producer(void ) {
int item;
while (TRUE) {
item = produce_item();
// 等待缓存区有空位置
down(&empty);
down(&mutex);
insert_item(item);
up(&mutex);
up(&full);
}
}
// 消费者
void consumer(void ) {
int item;
while (TRUE) {
// 等待缓存区有东西
down(&full);
down(&mutex);
item = remove_item();
up(&mutex);
up(&empty);
consumer_item(item);
}
}
但是我们还有一个需要注意的事情:能不能写成这样
down(&mutex);
down(&empty);
insert_item(item);
up(&full);
up(&mutex);答案是不行。我们可以假设一下,如果消费者开始运行了,它刚拿到了锁,但是发现这个地方没有数据,于是消费者阻塞,让出CPU,但是消费者的锁没有释放,它仍然持有。这个时候生产者来运行了,可是它没有锁,无法往里面加数据,所以没办法运行,只能大眼瞪小眼,形成了死锁。
读写锁
我们发现读数据不会改变临界区的值,所以读是一个安全的举措,所以我们可以让更多的人来阅读,但是写不行,写只能一个人在临界区里面。
所以我们有了读写锁。
这个锁的实现很简单,全局只有一把锁,对于读,用一个变量统计人数的变化,我们是第一个人拿到锁,最后一个人释放锁,中间可以很多人来读,但是不能写。而写锁和正常的一样。
线程的调度
当若干进程都有多个线程时,就存在两个层次的并行:进程和线程。在这样的系统中调度处理有本 质的差别,这取决于所支持的是用户级线程还是内核级线程(或两者都支持)。首先考虑用户级线程,由于内核并不知道有线程存在,所以内核还是和以前一样地操作,选取一个 进程,假设为 A,并给予 A 以时间片控制。A 中的线程调度程序决定哪个线程运行。假设为 A1。由于 多道线程并不存在时钟中断,所以这个线程可以按其意愿任意运行多长时间。如果该线程用完了进程的 全部时间片,内核就会选择另一个进程继续运行。在进程 A 终于又一次运行时,线程 A1 会接着运行。该线程会继续耗费 A 进程的所有时间,直到它 完成工作。不过,线程运行不会影响到其他进程。其他进程会得到调度程序所分配的合适份额,不会考 虑进程 A 内部发生的事情。
现在考虑使用内核线程的情况,内核选择一个特定的线程运行。它不用考虑线程属于哪个进程,不过如果有必要的话,也可以这么做。对被选择的线程赋予一个时间片,而且如果超过了时间片,就会强制挂起该线程。
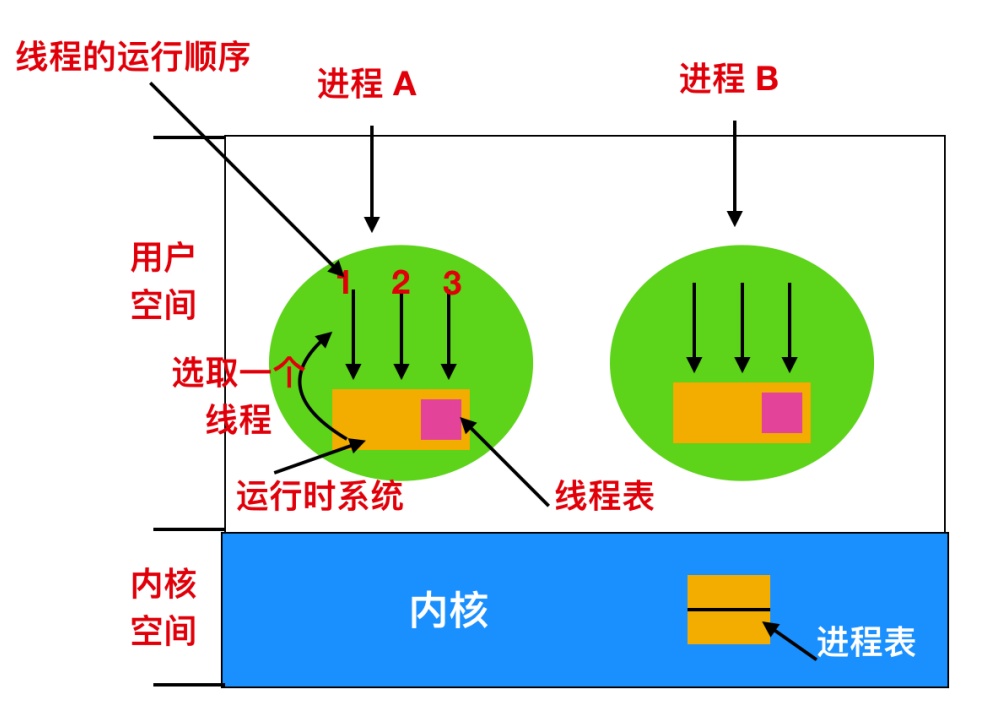
用户级线程和内核级线程之间的主要差别在于性能 。用户级线程的切换需要少量的机器指令(想象 一下Java程序的线程切换),而内核线程需要完整的上下文切换,修改内存映像,使高速缓存失效,这会导致了若干数量级的延迟。另一方面,在使用内核级线程时,一旦线程阻塞在 I/O 上就不需要在用户级线程中那样将整个进程挂起。从进程 A 的一个线程切换到进程 B 的一个线程,其消耗要远高于运行进程 A 的两个线程(涉及修 改内存映像,修改高速缓存),内核对这种切换的消耗是了解到,可以通过这些信息作出决定。
补充一些例子
/*
有2个buf作为临界资源,希望用户填入2个buf后,开启task2任务,统计两个缓存区里的内容
当任务2统计任务完成后,任务1才能继续填入数据
*/
#include <stdio.h>
#include <unistd.h>
#include <pthread.h>
#include <string.h>
#define N 32
pthread_mutex_t mutex;
pthread_cond_t cond_empty; // 缓存区为空的条件变量,为生产者提供睡眠
pthread_cond_t cond_full; // 缓存区为满的条件变量,为消费者提供睡眠
char buf1[N];
char buf2[N];
int is_data = 0;
void task1(void){
while(1){
pthread_mutex_lock(&mutex);
while(is_data != 0){ // 发现这里面有数据,那么就等待任务2统计完成
pthread_cond_wait(&cond_empty, &mutex);
}
printf("client....\n");
fgets(buf1, N, stdin);
buf1[strlen(buf1) - 1] = '\0';
fgets(buf2, N, stdin);
buf2[strlen(buf2) - 1] = '\0';
is_data = 1; // 有数据了
pthread_cond_signal(&cond_full);
pthread_mutex_unlock(&mutex);
}
pthread_exit(NULL);
}
void task2(void){
while(1){
pthread_mutex_lock(&mutex);
while(is_data == 0){
pthread_cond_wait(&cond_full, &mutex);
}
printf("server....\n");
printf("buf1: %s\n", buf1);
printf("buf2: %s\n", buf2);
is_data = 0; // 没有数据了
pthread_cond_signal(&cond_empty);
pthread_mutex_unlock(&mutex);
}
pthread_exit(NULL);
}
int main(){
pthread_t thread1, thread2;
int ret;
pthread_mutex_init(&mutex, NULL);
pthread_cond_init(&cond_empty, NULL);
pthread_cond_init(&cond_full, NULL);
ret = pthread_create(&thread1, NULL, task1, NULL);
if (ret)
{
perror("pthread_create task1 error");
return -1;
}
ret = pthread_create(&thread2, NULL, task2, NULL);
if (ret)
{
perror("pthread_create task2 error");
return -1;
}
pthread_join(thread1, NULL);
pthread_join(thread2, NULL);
return 0;
}线程的故事就到这里了,感谢大家的阅读!!!

openEuler 是由开放原子开源基金会孵化的全场景开源操作系统项目,面向数字基础设施四大核心场景(服务器、云计算、边缘计算、嵌入式),全面支持 ARM、x86、RISC-V、loongArch、PowerPC、SW-64 等多样性计算架构
更多推荐

 20
20 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)