云计算Linux——数据库MySQL部分命令(十六)
一、SQL基础语法与进阶概念1. 核心增删改查(CRUD)数据操作:涵盖 `INSERT`(插入)、`DELETE`(删除)、`UPDATE`(更新)及 `TRUNCATE`(清空表并重置自增ID)的区别。条件与函数:介绍了 `BETWEEN AND`(区间查询)、`SUM`(求和)、`AVG`(平均)、`COUNT`(计数)等常用函数。2. 排序与分组。
一、数据库表结构设计与约束规范
1.1 基础语法与数据类型定义
字符串与数值类型规范:字符串类型(如 CHAR、VARCHAR)必须加引号,否则会报错;DECIMAL(10,2) 表示最多 10 位有效数字,其中小数点后保留 2 位。
日期类型应用场景:介绍了 DATE 类型,并结合银行理财业务(如期缴、趸交)的实际案例,说明了其在记录购买时间、到期时间及下一期交费时间中的应用。
1.2 字段约束与常见错误规避
约束类型:主键(Primary Key)、非空(Not Null)、默认值、外键、索引及自增长(Auto Increment)均属于字段约束,用于定义字段的个性化规则。
长度冲突陷阱:警示了字段长度定义与系统配置冲突的风险。举例说明若 MySQL 配置中密码最小长度为 6,而表结构中密码字段长度定义为 2,将导致无法创建用户。
1.3 Navicat 可视化操作实践
1.3.1 navicat工具功能
Navicat 作为独立工具可连接多种数据库,支持导入 Excel 等文件格式,以及通过图形化界面新建表、设置字段类型、主键、索引等操作。
1.3.2 增删改查(CRUD)核心语法
操作指令语义解析:解析了常见操作指令的语义,Add 表示新增,Delete 表示删除,Set 表示修改(设置),Get 表示查询,Change 表示变更(如改字段名)。
自增长机制应用: Auto Increment 的作用,即在插入数据时不指定 ID 值,系统会自动从 1 开始递增填充,并演示了 INSERT 语句中省略自增字段的写法。
创建表、插入表内容
alter table info01 set
在大部分的表达式中,增删改查:
增:add
删:delete
改:set modify 【sql change】
查:get1.4 生产环境查询优化与性能警示
1.4.1 基础查询语句编写
条件筛选与函数使用:WHERE 子句进行条件筛选(如部门、薪资、入职年份),并介绍了 YEAR() 函数在日期查询中的应用。
字段选择原则:建议在查询时明确指定所需字段,而非盲目使用 SELECT *,以提升查询效率。
1.4.2 SELECT * 的性能风险警示
生产环境性能瓶颈:指出在生产环境中,面对百万级数据量的表,滥用 SELECT * 会导致数据库加载大量无用字段,严重消耗系统 IO 和内存资源。
系统宕机风险类比: SELECT * 在大数据量场景下的危险性不亚于 `rm -rf` 或 `cat` 超大日志文件,可能导致服务器响应缓慢甚至宕机,尤其是在 MySQL 并发处理能力较弱的情况
select * from xxx; #高危语句二、MySQL命令进阶
2.1基础部分
2.1.1 排序语法与默认规则
基础排序逻辑:`ORDER BY` 用于指定排序字段,默认情况下为升序(ASC),可省略不写;降序排列需显式指定 `DESC`。
应用场景说明:降序排列常用于排行榜场景,如根据积分、消费额度或销售额进行排名,以快速筛选出销冠或头部数据。
2.1.2 结果集限制与筛选
限制输出数量:`LIMIT` 用于限制查询结果返回的行数,例如 `LIMIT 2` 表示仅输出前两条记录。
输出销售部门薪资最高的员工
select emp_name from employees where dept='Sales' limit 1;复合查询应用:结合 `WHERE` 子句和 `ORDER BY`,可实现特定条件下的排名筛选,如查询某个月份的销冠名单。
2.1.3 分组统计逻辑
分组依据设定:`GROUP BY` 必须指定分组字段(如部门),否则会导致报错。该语句将数据按指定维度(如学科、部门)划分为不同组别。
聚合函数配合:在分组基础上,使用 `AVG`(平均值)、`COUNT`(计数)等函数对组内数据进行计算,并可通过 `AS` 为计算结果设置别名。
平均薪资计算:通过 `SELECT dept, AVG(salary) AS avg_salary FROM table GROUP BY dept` 实现各部门平均薪资的计算与输出。
员工数量统计:通过 `SELECT dept, COUNT(*) AS emp_count FROM table GROUP BY dept` 统计各部门的员工总数。2.1.4 数据内容更新
批量更新操作:使用 `UPDATE` 结合 `SET` 和 `WHERE` 进行数据修改,例如为 IT 部门员工加薪 10% 的语句为 `UPDATE table SET salary = salary * 1.1 WHERE dept = 'IT'`。
删除数据操作:使用 `DELETE FROM` 结合 `WHERE` 条件删除指定数据,若无 `WHERE` 条件将清空整张表数据。
2.1.5 表结构变更
字段增删改:`ALTER TABLE` 用于修改表结构,如新增字段的语法为 `ALTER TABLE table_name ADD COLUMN column_name data_type`。
2.1.6 多字段排序与区间查询
多级排序逻辑:`ORDER BY` 支持多字段排序,如 `ORDER BY dept, salary DESC` 表示先按部门排序,部门内再按薪资降序排列。
区间范围筛选:使用 `BETWEEN AND` 进行区间查询,如查询薪资在 6000 到 8000 之间的员工。
2.2 SQL 语句进阶与数据操作
2.2.1 复杂查询语句详解
分组与排序组合:讲解了 `ORDER BY` 与 `GROUP BY` 的组合使用,指出多字段排序时会先执行左侧字段排序,再执行右侧字段排序。
LIMIT 分页查询:详细解释了 `LIMIT` 的两种用法。`LIMIT 3` 表示输出前 3 行;`LIMIT 3,1` 表示从第 3 行之后(不包含第 3 行)开始,输出 1 行数据。
2.2.2 数据删除操作的底层差异
DELETE 与 TRUNCATE 区别:`DELETE FROM` 仅删除表数据,自增 ID 会保留原有计数;`TRUNCATE TABLE` 则是删除表并重建,自增 ID 会重置,且该操作无法回滚。
2.3 子查询(Subquery)原理
子查询的基本概念与语法结构
嵌套查询定义:子查询是在一个 SQL 查询语句中嵌套另一个 SQL 语句,通常出现在 WHERE 或 HAVING 子句中。
集合匹配逻辑:通过 `IN` 操作符,将子查询的结果集(如多个姓名)作为外层查询的条件集合,实现多值匹配。
示例:
SELECT SUM(Sales) FROM store_info WHERE Store_Name IN (SELECT Store_Name FROM location WHERE Region = 'West');嵌套查询逻辑:利用 `WHERE ... IN (SELECT ...)` 结构,先在子查询中筛选出满足条件的集合(如兴趣爱好为IT的用户名),再在主查询中进行匹配。
2.4多表查询的核心语法与实战
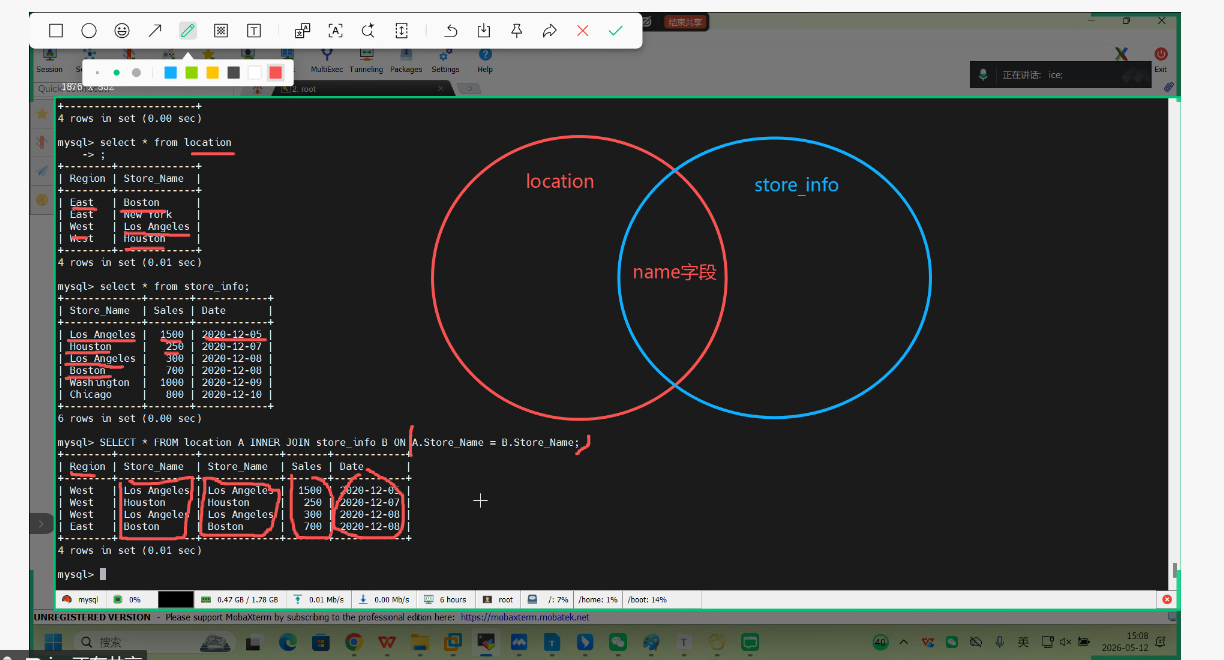
2.4.1 内连接查询(INNER JOIN)
交集匹配机制:通过 `INNER JOIN` 连接两张表,使用 `ON` 条件指定关联字段(如ID或Name),结果集仅包含两张表中关联字段完全匹配的记录。
别名应用:在复杂查询中推荐使用表别名(Alias)简化代码,避免字段歧义。
2.4.2 左连接与右连接(LEFT/RIGHT JOIN)
左连接(LEFT JOIN):以左表为基准,输出左表全部记录及右表中匹配的记录,若右表无匹配则显示为 `NULL`。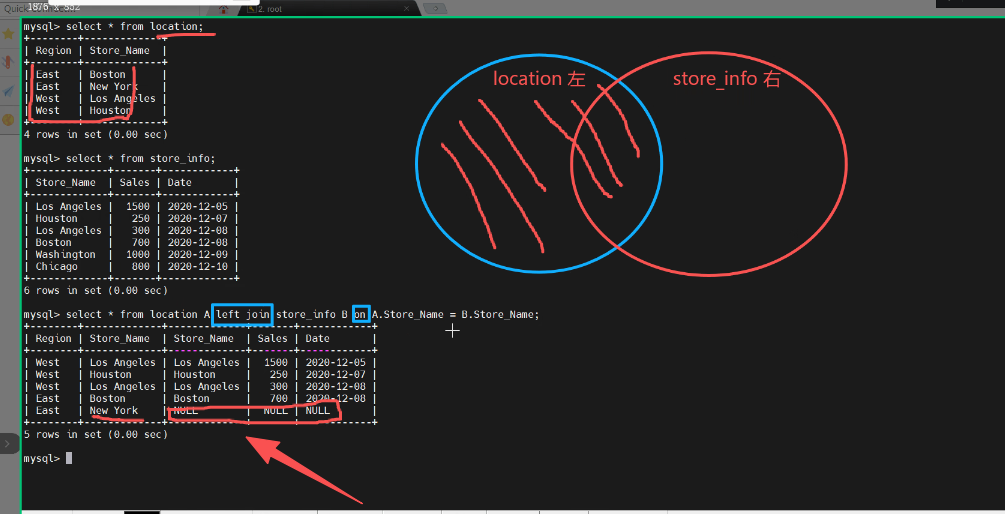
右连接(RIGHT JOIN):以右表为基准,输出右表全部记录及左表中匹配的记录,若左表无匹配则显示为 `NULL`。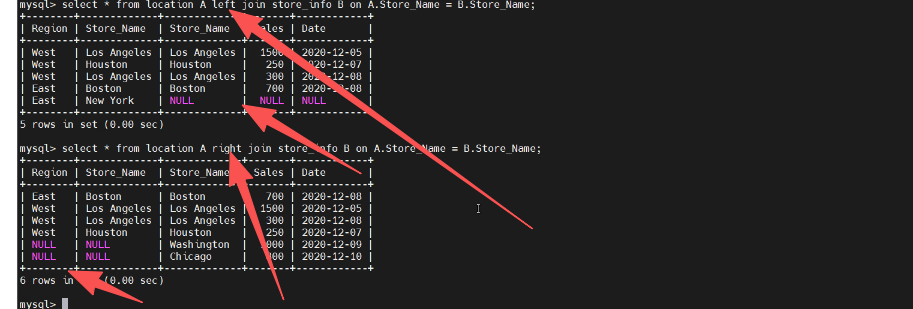
三、MySQL 索引机制与性能优化
3.1 索引的底层逻辑与工作原理
核心目的与类比:索引的核心目的是加快查询效率并减少资源消耗,其工作原理类似于书籍的目录或游乐园的地图,通过建立“目录”快速定位数据物理位置。
MySQL 工作流程:MySQL 通过 `mysqld` 进程监听 3306 端口,接收请求后创建线程执行 SQL。若查询字段无索引,线程需全表扫描;若有索引,线程会先查询索引表获取数据位置,从而避免全表扫描。
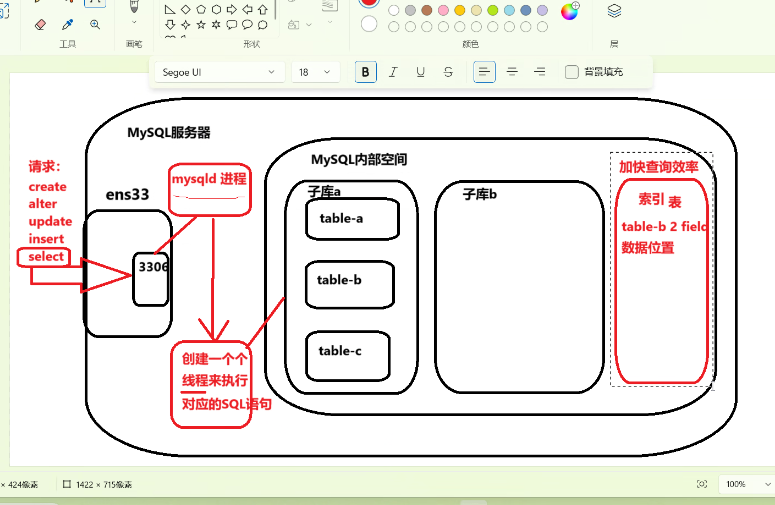
Nginx 类比:讲师通过 Nginx 的 `index` 配置类比索引,指出 Nginx 之所以轻量快速,正是因为它通过索引直接定位文件,而非遍历目录。
3.2 索引的创建与验证
索引创建语法:演示了使用 `CREATE INDEX` 语句为指定字段创建普通索引,并指出主键(Primary Key)本质上也是一种索引。
性能验证工具:介绍了 `EXPLAIN` 命令作为 SQL 执行计划的测试工具。通过对比有无索引的查询结果,可观察到 `type` 字段显示为 `index` 即表示使用了索引,`Extra` 字段会明确标注“Using index”。
3.3 用户权限管理与可视化工具
3.3.1 用户授权与密码修改
GRANT 授权语法:讲解了 `GRANT` 语句的完整语法,指出 `*.*` 代表所有库的所有表,`%` 代表允许从任意主机连接,`localhost` 代表仅允许本地连接。
密码修改机制:演示了 `ALTER USER` 修改密码的命令,并指出该命令本质上是修改 `mysql.user` 表中的数据。
3.3.2 可视化工具辅助
Navicat 工具优势:推荐使用 Navicat 等可视化工具,因其能更好地展示多字段宽表,解决命令行下字段过多导致显示错乱的问题。
格式化输出:介绍了在命令行中使用 `\G` 代替分号结尾,可以按行垂直显示查询结果,便于阅读。
3.4 数据库自增ID与数据同步风险
针对数据库表结构中的自增ID(Auto Increment)特性,讲师通过实际案例分析了其在数据同步场景下的潜在风险:
3.4.1 自增ID重置导致的冲突
同步报错机制:当使用 `DELETE` 删除表数据后,自增ID不会重置,若此时将数据同步至新数据库,新表的自增ID将从1开始,导致ID冲突。
解决方案:在导入数据时需手动设置 `auto_increment` 的起始值,或在建表时指定字符集以避免中文报错。
3.4.2 字符集兼容性问题
中文支持限制:MySQL 5.7 版本默认不支持中文字符集,若建表时未指定字符集,在涉及中文数据的查询或导入时会出现报错。
总结
一、SQL基础语法与进阶概念
1. 核心增删改查(CRUD)
数据操作:涵盖 `INSERT`(插入)、`DELETE`(删除)、`UPDATE`(更新)及 `TRUNCATE`(清空表并重置自增ID)的区别。
条件与函数:介绍了 `BETWEEN AND`(区间查询)、`SUM`(求和)、`AVG`(平均)、`COUNT`(计数)等常用函数。
2. 排序与分组
结果集处理:讲解了 `ORDER BY`(排序,ASC升序/DESC降序)、`LIMIT`(分页/限制行数)以及 `GROUP BY`(分组统计)的用法。
3. 进阶概念(拓展了解)
存储过程(Stored Procedure):介绍了将多条SQL语句封装为函数的概念,指出该功能通常由开发人员编写,运维人员需了解但非必须掌握。
DBA职业价值:强调了数据库管理员(DBA)在企业中的不可替代性,即使AI能生成SQL,仍需DBA进行校验与沟通,职业稳定性较高。
二、# 子查询 + 变量
select * from xxx; #高危语句
location / {
root html;
index index.html index.htm;
}
explain select * from employees;
sql
create 创建表结构、数据库
修改类:
alter 修改表结构
update 修改表数据
新增类:
insert into 插入表数据库
查询类(基本):
select * from table_name where 进行条件匹配;
select id,count(name) as count_name,ave(score) from table_name;
select * from table_name order by 排序 desc;
select * from table_name limit 3; 表示输出前3行,limit 3,1 表示输出第三行后的一行内容
select * from table_name group by 字段;
一个部分SQL 语句(子查询、内连查询外连查询)
索引
简单集群(主从复制)
mysql 是什么 干嘛的 怎么用的?
一种关系型数据库,以二维表存储数据并且不同表之间拥有一定的数据关联性
mysql 的默认结构:
① mysql的端口是3306
② mysql的主进程是mysqld
③ mysql有自己的内部空间,会包含多个不同的子数据库、每个子数据库中,会存储多个不同的二维表
二维表中,以记录为行、字段为列,存储实际的数据
mysql 内部的 SQL 语句
SQL语句 是MySQL内部管理数据的语言/语法
SQL 语句以我们常规的逻辑分类,其实就是增删改"查" (根因)
create
alter
update
delete
truncate
insert
select
查询类(基本):
select * from table_name where 进行条件匹配;
select id,count(name) as count_name,ave(score) from table_name;
select * from table_name order by 排序 desc;
select * from table_name limit 3; 表示输出前3行,limit 3,1 表示输出第三行后的一行内容
select * from table_name group by 字段;
子查询是在一个SQL查询中嵌套另一个SQL查询。子查询可以出现在WHERE子句或HAVING子句中。
**示例**:
```sql
SELECT SUM(Sales) FROM store_info WHERE Store_Name IN (SELECT Store_Name FROM location WHERE Region = 'West');
```
mysql> select * from location
-> ;
+--------+-------------+
| Region | Store_Name |
+--------+-------------+
| East | Boston |
| East | New York |
| West | Los Angeles |
| West | Houston |
+--------+-------------+
4 rows in set (0.01 sec)
mysql> select * from store_info;
+-------------+-------+------------+
| Store_Name | Sales | Date |
+-------------+-------+------------+
| Los Angeles | 1500 | 2020-12-05 |
| Houston | 250 | 2020-12-07 |
| Los Angeles | 300 | 2020-12-08 |
| Boston | 700 | 2020-12-08 |
| Washington | 1000 | 2020-12-09 |
| Chicago | 800 | 2020-12-10 |
+-------------+-------+------------+
6 rows in set (0.00 sec)
mysql>
1、创建2张表A 和 B
A表内容:
id name hobbid hobby_name
1 zangsan 1 running
2 lisi 2 eat
3 wangwu 2 eat
4 zhaoliu 3 reading
5 tianqi 4 playing
B表内容
id name hobbid paying
1 zhangsan 1 1000
2 lisi 2 300
3 wangwu 2 400
4 dingyi 2 2000
5 dinger 2 1000
hobbid 兴趣爱好的id编号
hobby_name 兴趣爱好名字
paying 花了多少钱
需求:统计A表中兴趣爱好为eat的用户,一共花了多少钱(参考B表的消费记录)
select sum(paying) from B where name in (select name from A where hobbid=2);
子查询,其实就是select 字段/函数 from table_A where 字段 in (集合--select)
内连接查询:
内连查询,拼接2张表的所有字段内容,并只输出name字段相等的记录行
SELECT * FROM location A INNER JOIN store_info B ON A.Store_Name = B.Store_Name;
左连接查询/右连接查询:
SELECT * FROM location A left JOIN store_info B ON A.Store_Name = B.Store_Name;
SELECT * FROM location A right JOIN store_info B ON A.Store_Name = B.Store_Name;
mysql> select * from location A left join store_info B on A.Store_Name = B.Store_Name;
+--------+-------------+-------------+-------+------------+
| Region | Store_Name | Store_Name | Sales | Date |
+--------+-------------+-------------+-------+------------+
| West | Los Angeles | Los Angeles | 1500 | 2020-12-05 |
| West | Houston | Houston | 250 | 2020-12-07 |
| West | Los Angeles | Los Angeles | 300 | 2020-12-08 |
| East | Boston | Boston | 700 | 2020-12-08 |
| East | New York | NULL | NULL | NULL |
+--------+-------------+-------------+-------+------------+
5 rows in set (0.00 sec)
mysql> select * from location A right join store_info B on A.Store_Name = B.Store_Name;
+--------+-------------+-------------+-------+------------+
| Region | Store_Name | Store_Name | Sales | Date |
+--------+-------------+-------------+-------+------------+
| East | Boston | Boston | 700 | 2020-12-08 |
| West | Los Angeles | Los Angeles | 1500 | 2020-12-05 |
| West | Los Angeles | Los Angeles | 300 | 2020-12-08 |
| West | Houston | Houston | 250 | 2020-12-07 |
| NULL | NULL | Washington | 1000 | 2020-12-09 |
| NULL | NULL | Chicago | 800 | 2020-12-10 |
+--------+-------------+-------------+-------+------------+
6 rows in set (0.00 sec)
mysql>
写一个子查询系列的话术
问:什么是子查询,是怎么做的?
问:什么是内连查询、是怎么做的?
问:左连接和右连接查询有什么区别?
MySQL SQL 语法:
SQL 语句以我们常规的逻辑分类,其实就是增删改"查"
create 创建
alter 修改表结构
update 更新表内容
delete 删除表数据 (auto increment,会接着之前的数字继续累加)
truncate 删除表数据(先删除整张表再重建一个相同的新表 --》auto increment 会从1重新开始)
insert 插入表数据
select
查询类(基本):
select * from table_name where 进行条件匹配; (可以使用 > < = 逻辑判断 between 200 and 300 表示区间关系)
select id,count(name) as count_name,ave(score) from table_name; (函数使用 sum、avg、counnt)
select * from table_name order by 排序 desc; (基于字段的数据进行排序 默认是升序排序、使用desc 可降序排列)
select * from table_name limit 3; 表示输出前3行,limit 3,1 表示输出第三行后的一行内容,第三行内容不输出
select * from table_name group by 字段; (以指定字段的内容作为分组依据-排列在一起,然后输出其他的记录行内容)子查询类型(多表相连查询)
### SELECT
`SELECT`语句用于从数据库表中检索数据。您可以指定要检索的字段,或者使用`*`来选择所有字段。
**示例**:
SELECT Store_Name FROM store_info; -- 仅选择Store_Name字段
SELECT * FROM store_info; -- 选择所有字段
### WHERE
`WHERE`子句用于过滤记录,只返回满足指定条件的记录。
**示例**:
SELECT Store_Name FROM store_info WHERE Sales > 1000; -- 返回Sales大于1000的Store_Name
### IN
`IN`操作符允许您指定多个可能的值,返回字段值等于这些值之一的记录。
**示例**:
SELECT * FROM store_info WHERE Store_Name IN ('Los Angeles', 'Houston'); -- 返回Store_Name为'Los Angeles'或'Houston'的记录
### BETWEEN
`BETWEEN`操作符用于选取在某个范围内的值,范围包括边界值。
**示例**:
SELECT * FROM store_info WHERE Date BETWEEN '2020-12-06' AND '2020-12-10'; -- 返回Date在'2020-12-06'和'2020-12-10'之间的记录
### ORDER BY
`ORDER BY`子句用于对结果集进行排序。您可以按一个或多个列进行排序,并指定升序(`ASC`,默认)或降序(`DESC`)。
SELECT Store_Name, Sales, Date FROM store_info ORDER BY Sales DESC; -- 按Sales降序排序
## 分组
### GROUP BY
GROUP BY用于对查询结果进行分组,通常与聚合函数(如SUM、COUNT、AVG等)一起使用。其原则如下:
- 在GROUP BY后面出现的字段,必须在SELECT后面出现。
- 在SELECT后面出现且未在聚合函数中使用的字段,必须出现在GROUP BY后面。
SELECT Store_Name, SUM(Sales) AS TotalSales FROM store_info GROUP BY Store_Name ORDER BY TotalSales DESC;

openEuler 是由开放原子开源基金会孵化的全场景开源操作系统项目,面向数字基础设施四大核心场景(服务器、云计算、边缘计算、嵌入式),全面支持 ARM、x86、RISC-V、loongArch、PowerPC、SW-64 等多样性计算架构
更多推荐

 7
7 0
0- 0



 已为社区贡献21条内容
已为社区贡献21条内容

所有评论(0)