【redies0-导论】分布式系统的演进-引进redis原因
摘要:分布式系统通过多服务器部署解决单机性能瓶颈,其演进过程包括:单机架构→应用与数据库分离→负载均衡集群→数据库主从读写分离→引入缓存→分库分表→微服务架构。微服务具有单一职责、独立部署等优势,但也带来运维复杂度增加、分布式事务等挑战。系统衡量指标包括可用性、响应时长等。集群部署涉及主从节点分工,大数据量时采用分片集群。分库分表策略包括垂直分库和水平分表。分布式系统核心在于利用硬件资源解决业务扩
一、分布式系统
简介
系统中的多个模块被部署于不同服务器之上,即可以将该系统称为分布式系统。如Web服务器与数据库分别工作在不同的服务器上,或者多台Web服务器被分别部署在不同服务器上。
演进
--从单体到微服务
分布式系统的本质,就是通过引入更多的硬件资源,解决单机无法承载的业务压力。其演进过程与业务发展密切相关:业务是核心驱动力,技术则是为业务提供支撑的手段
1. 初始阶段:单机架构
结构:应用程序与数据库服务器部署在同一台主机上。
特征:开发简单,部署方便。
局限:无法应对高并发,一旦主机宕机,整个业务立即瘫痪。
2. 纵向扩展:数据库与应用分离
结构:将应用程序和数据库服务器分别部署在不同的独立主机上。
提升:初步利用了多台主机的硬件资源,缓解了单台服务器在 CPU 和磁盘 I/O 上的竞争压力。
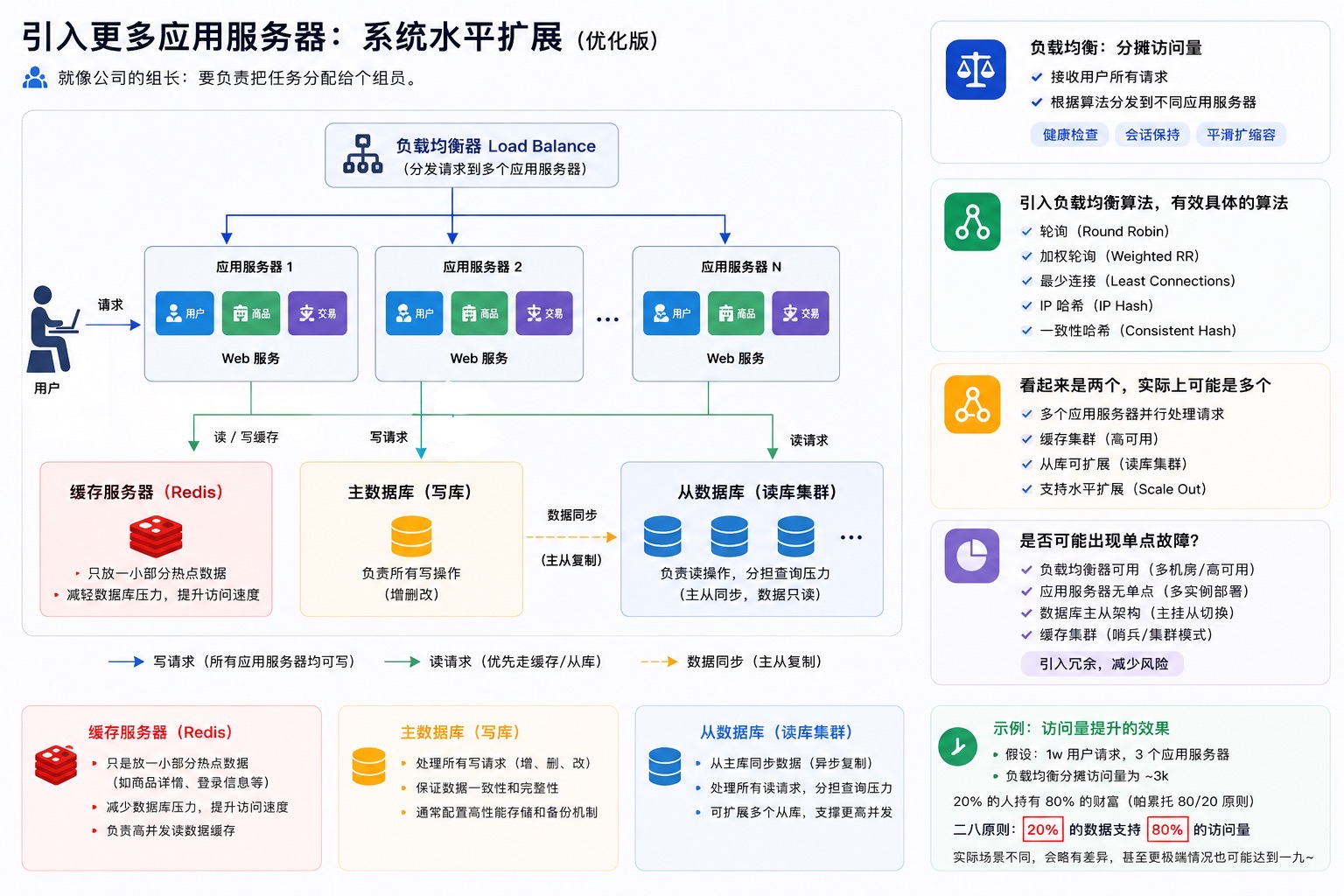
3. 高可用起步:引入负载均衡与应用集群
核心操作:应用服务器由单点变为集群,并在前端引入负载均衡器。
作用:负载均衡器将请求均匀分发给集群中的各个应用服务器。
关键价值:提高了系统可用性。当集群中某个主机宕机时,其他主机仍能继续提供服务,业务不中断。
4. 读写压力分担:数据库主从结构
结构:设置一个主节点(Master)负责写数据,多个从节点(Slave)负责读数据。
同步机制:主节点需要实时将修改后的数据同步给从节点。
目的:通过“读写分离”,大幅提升数据库在面对大量查询请求时的处理效率。
5. 性能飞跃:引入缓存(冷热数据分离)
角色:通常由 Redis 在分布式系统中扮演缓存角色。
原理:根据“二八原则”(80% 的请求集中在 20% 的热点数据上),将热点数据存入内存缓存中。
新挑战:引入缓存后,需要额外处理数据库与缓存之间的数据一致性问题。
6. 存储瓶颈突破:分库分表
操作:通过分库分表,将海量数据分散存储在不同的数据库和表里。
价值:进一步扩展了系统的存储空间和单表的查询性能,解决了单物理库的容量上限。
7. 终极形态:微服务架构
核心思想:从业务功能角度,对应用服务器进行深层次拆分。
操作:将原本臃肿的应用拆分成多个功能单一、逻辑简单、体积更小的服务节点。
意义:微服务架构彻底解决了大型项目中的开发效率与系统扩展性问题,使各业务模块可以独立演进。
分布式系统的演变不是一蹴而就的,而是业务规模与技术边界不断博弈的结果。其核心逻辑始终围绕着:如何利用更多的硬件,去解决更复杂的人与业务的问题。
二、中间件
和业务无关的服务(功能更通用的服务)
1.数据库
2.缓存(redis---热数据暂存---数据库和缓存数据库一致性问题
3.消息队列... ...
三、衡量指标
可用性:系统整体可用的时间/总的时间(4个9即系统可以提供99.99%的可用性)
响应时长:衡量服务器的性能,指用户完成输入到系统给出用户反应的时长,越小越好
吞吐:衡量服务器的性能,考察单位时间段内,系统可以成功处理的请求的数量
并发:衡量服务器的性能,指系统同一时刻支持的请求最高量
四、主从集群
集群:被部署于多台服务器上的、为了实现特定目标的一个/组特定的组件,整个整体被称为集群。比如多个MySQL工作在不同服务器上,共同提供数据库服务目标,可以被称为一组数据库集群。
---主节点 (Master)负责处理写操作,并将数据同步给从节点;
---从节点 (Slave):负责处理读操作,接收并执行来自主节点的数据同步命令
【服务器与数据库布局的演进如下】
【多机房,一个机房有多个服务器,多个服务器共享(缓存+主写+从读数据库)】
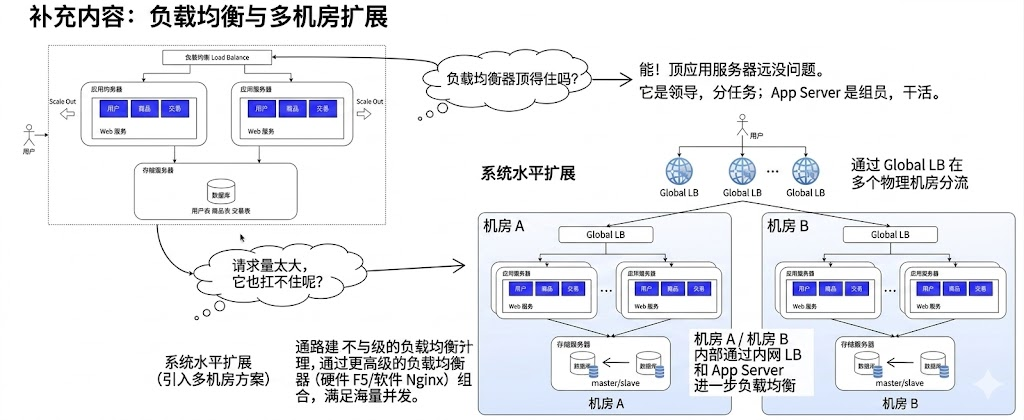
五、分片集群
数据量大到单台服务器的内存无法装下时,将数据分散存储在多个不同的 Redis 节点上,每个节点只负责一部分数据
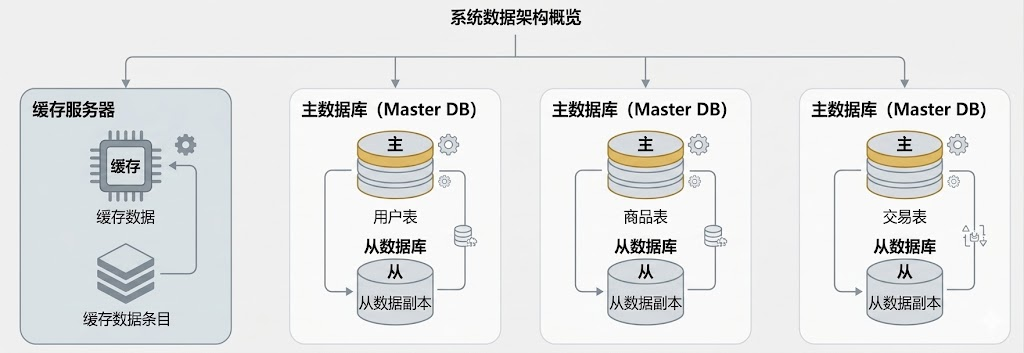
【分库】
分库:将原本存储在一个逻辑数据库中的数据,分散存储到多个独立的数据库服务器
垂直分库:按照业务维度进行拆分。例如将“用户”、“商品”、“交易”相关的表分别存放在不同的数据库服务器中
【分表】
分表:是指在同一个数据库(或跨库)中,将一张大表拆分成多张物理小表
水平分表:最常见的形式。将一张巨型表按照某种规则(如按时间范围)拆分为表 1、表 2 等。例如,一个巨大的用户表可以被拆分成 128 个子表分布在不同主机上
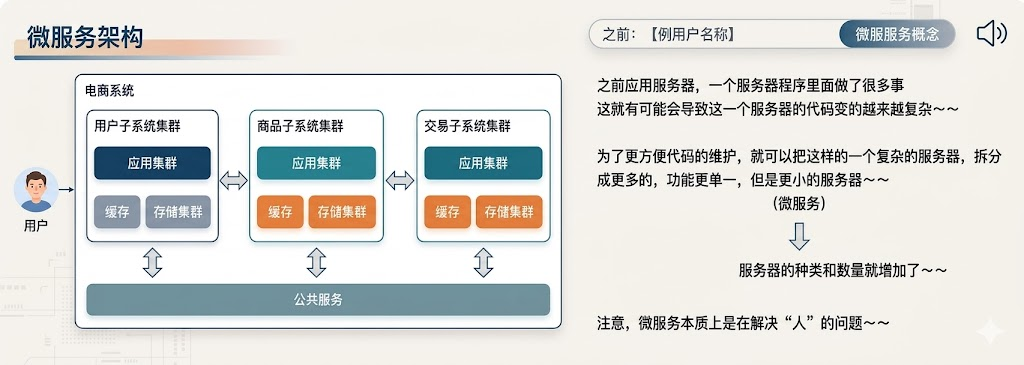
六、微服务架构
微服务 是一种架构风格,它将一个大型的单一应用程序拆分为一组小型、松散耦合的服务
【主要特征】
单一职责: 每个服务只专注做好一件事(例如:用户服务只负责管理用户信息,订单服务只处理订单逻辑)。
自治性: 每个微服务都可以由不同的团队开发,使用不同的编程语言(如 Java, Go, Python),并拥有独立的数据库(防止数据耦合)。
独立部署: 修改某个功能时,只需重新部署对应的微服务,而不需要重启整个庞大的系统。
去中心化治理: 不强求统一的技术栈,团队可以根据业务场景选择最合适的工具。
【问题缺点】
运维复杂度显著增加:需要管理成百上千个服务的部署、监控、日志收集和治理工作。这通常要求具备成熟的容器化(如 Docker/K8s)和 CI/CD 能力。
分布式系统的复杂性:
服务间通信:服务需要通过网络(消息队列等)进行通信,这会带来额外的网络延迟和不确定性。
分布式事务:在跨多个服务时,保证数据的一致性变得非常困难。
测试与调试难度:由于服务间存在复杂的调用链路,定位 bug 往往需要借助分布式链路追踪系统。
资源消耗:每个微服务通常都有自己的运行环境(如 JVM)和数据库,这可能导致内存和存储资源的占用比单体架构更高。
【核心组件】
服务注册与发现: 动态记录各个服务的 IP 和端口。
API 网关: 系统的单一入口,负责请求路由、负载均衡、认证和限流。
配置中心: 集中管理所有服务的配置文件。
容错与熔断: 防止某个服务故障引发系统雪崩。
链路追踪: 监控一个请求在各个服务之间的调用路径

openEuler 是由开放原子开源基金会孵化的全场景开源操作系统项目,面向数字基础设施四大核心场景(服务器、云计算、边缘计算、嵌入式),全面支持 ARM、x86、RISC-V、loongArch、PowerPC、SW-64 等多样性计算架构
更多推荐
 11
11 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)