【硬核Linux】打通OS任督二脉:从冯诺依曼到进程Fork,看完直呼过瘾!
本文为你硬核拆解Linux底层逻辑!从冯·诺依曼体系的数据流动出发,带你透彻理解操作系统“先描述,再组织”的管理哲学与系统调用机制。接着深入剖析核心概念“进程”,揭秘PCB结构与cwd路径,最后通过实战代码调用fork()创建子进程,带你亲眼见证“写时拷贝”的奇妙过程。一文帮你彻底夯实系统编程基石!

🔥个人主页:爱和冰阔乐
📚专栏传送门:《数据结构与算法》 、【C++】 、【Linux】
🐶学习方向:C++方向学习爱好者
⭐人生格言:得知坦然 ,失之淡然

🏠博主简介
文章目录
前言
欢迎来到本期博客!🌟
在探索Linux操作系统的浩瀚宇宙时,很多初学者往往会“知其然而不知其所以然”。为了帮你打牢底层基础,本文将带你从硬件底层的冯·诺依曼体系结构出发,深入浅出地理解计算机内部数据的真实流动过程;随后步入操作系统的核心殿堂,揭开OS作为“大管家”背后“先描述,再组织”的管理哲学以及系统调用的本质。
在此基础上,我们将硬核剖析Linux中最重要的概念之一——进程(Process)。从进程控制块(PCB)的认知、进程信息的查看与路径管理(cwd),一直推演到使用代码调用 fork() 创建子进程,并带你亲自验证神奇的“写时拷贝”机制。
无论你是刚接触Linux的新手,还是想夯实系统编程基础的C/C++学习者,相信这篇文章都能为你拨开迷雾,理清软硬件交互的底层逻辑。准备好了吗?让我们一起开启这场底层原理的探索之旅吧!🚀
一、认识冯诺依曼系统
我们常见的计算机 ,如笔记本。我们不常见的计算机 ,如服务器 ,大部分都遵守冯诺依曼体系。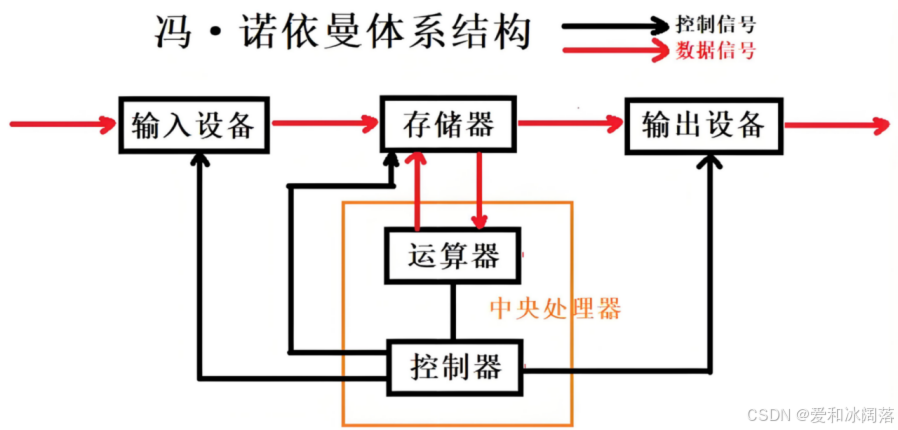
截至目前 ,我们所认识的计算机 ,都是由一个个的硬件组件组成
- 输入设备:包括键盘, 鼠标 ,扫描仪, 写板,
网卡,磁盘等 - 中央处理器(CPU):含有运算器和控制器等
- 输出设备:显示器 ,打印机,
网卡,磁盘等 - 存储器:内存
⚠️ 核心注意注意:
1. 在诺依曼系统体系中,我们将输入设备和输出设备称为外设,即外部存储
2. 在学语言时,我们进行文件读取时,将磁盘的数据读到内存里,写文件就是将内存的数据写入到磁盘中,这种读写的动作称为I/O,因此这类设备不一定严格意义上只是输入或者输出设备,既可以是输入也可以是输出设备(理解I/O站在内存的角度,外设将数据交给内存是I(写入),内存将数据给外设即输出O)
1.1 软件为什么要“加载到内存”?
❓ 灵魂拷问:编译好的程序,为什么运行前必须加载到内存?程序运行之前在哪?
在 Linux 中“一切皆文件”,程序在运行前就是一个存放在磁盘(外设)上的普通文件。
而在计算机体系结构中,有这样一条铁律:数据的流动只能从外设流到内存,CPU 只能从内存中读取数据和代码。CPU 无法直接越过内存去读取外设!因此,程序必须从外设加载到内存(这个加载的本质就是 I/O 操作)。
💡 阶段总结:
1.数据流动本质就是从一个设备拷贝到新的设备上,因此推导出体系结构的效率的高低是由设备的拷贝效率决定的
2.cpu在数据层面只和内存打交道,外设只和内存打交道
1.2存储分级:为什么不能只要 CPU 和外设?
❓ 灵魂拷问:能不能去掉内存?外设直接连 CPU,效率不是更高吗?
我们先来看一张“存储分级图”: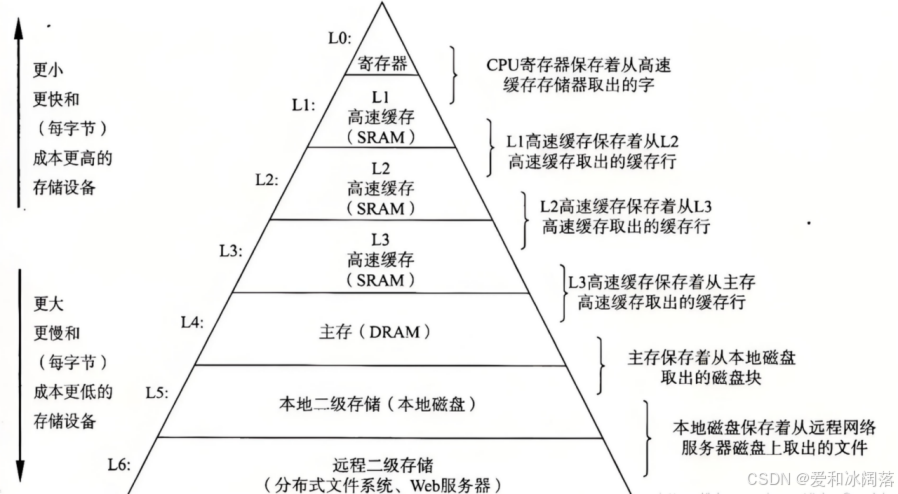
在如上图中,我们发现离cpu越近,存储容量越小,速度更快,离cpu越远,存储容量越大,速度更慢,这就是存储分级的概念,有了这个概念,我们便知道为什么计算机不是下图这样设计的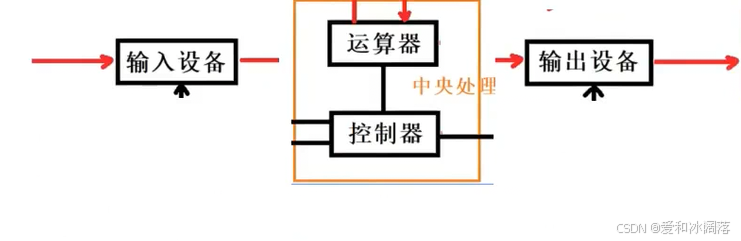
输入输出设备属于外设,在存储分级图中,离cpu远,运算效率低下(假设是毫秒级别),cpu的运算速度为纳秒级别,这样输入设备将数据交给cpu后其快速处理后交给输出设备,但是输出设备处理速度慢,cpu需要等输出处理完,并且由于cpu快速将输入设备处理完因此需要等输入设备将新数据交给cpu,导致整个体系结构的效率是由外设效率决定(木桶原理,效率是由最慢的决定),速度太慢
那么能不能帮我们的外设如磁盘全部变成寄存器,当然是可以的,但是由于成本太高不适合绝大数有需求的人,为了在价格和效率中找平衡,因此引入内存(假设微秒),让cpu和外设之间的效率进行适配(以内存效率决定)
可是不是说效率是由最低的决定吗,在这个架构中外设效率依然是最低的???
操作系统加载时就在内存里,其提前将外设预先的大量数据批量给给内存,因此便只是内存和cpu的交互速度来决定效率
1.3 聊个QQ,数据是怎么流动的?
对冯诺依曼的理解 ,不能停留在概念上 ,要深入到对软件数据流理解上 ,解释下 ,从你登录上qq开始和某位朋友聊天开始 ,数据的流动过程。从你打开窗口 ,开始给他发消息 ,到他的到消息之后的数据流动过程。如果是在qq上发送文件呢?
电脑手机等设备本质就是冯诺依曼体系,因此和朋友聊天本质就是两台冯诺依曼体系在聊天,因此用户在键盘输入数据,qq被启迪要加载到内存里,键盘要将数据交给qq,因此数据就从输入设备流动到存储器,数据发出去前需要将其加密(使用对应的算法),因此肯定要经过cpu进行处理,然后将数据再返回给存储器,再通过qq将数据输出到我们的网卡(输出设备),网卡经过网络将数据交给你朋友的机器的输入设备—网卡,同样也要启动qq到内存里,内存读到数据将其给给cpu进行解密,再将其返给存储器,最后输出到你朋友的输出设备-----显示器
同理文件传输是从输入设备----磁盘上,将文件拷贝到qq上即加载到内存中,内存将文件交给cpu并加密,cpu将加密文件返回给内存,内存将其写到网卡中,后面步骤就是类似的了(朋友输入设备是网卡,输出设备是磁盘)
注意:上述的流动,写入,加载等名词的本质均是数据的拷贝
二、操作系统(OS):计算机系统的大管家
2.1 概念
任何计算机系统都包含一个基本的程序集合 ,称为操作系统(OS),操作系统包括:
- 内核(进程管理 ,内存管理 ,文件管理 ,驱动管理)
- 其他程序(例如函数库 ,shell程序等等)
简单来说操作系统是一款进行软硬件管理的软件
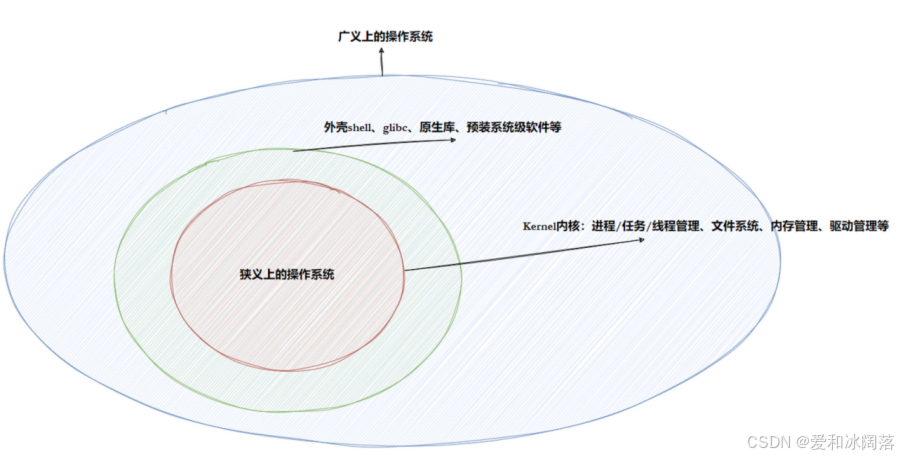
在日常我们说操作系统(狭义上的)即内核,广义上讲就是操作系统上内核之上安装的外壳shell,glibc,预装的系统软件等
安卓的底层用的是Linux内核,这句话的理解就是安卓使用的是Linux的内核,但是其有自己的外壳程序等
2.2 设计OS的目的
整个计算机结构示意图如下: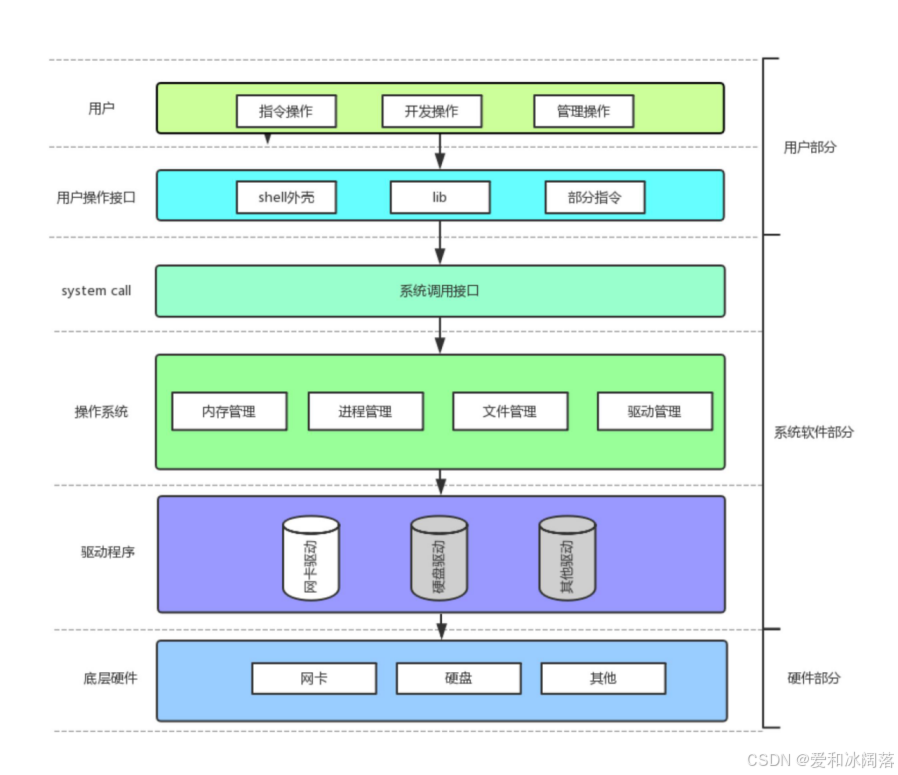
操作系统
对下,与硬件交互,管理所有软硬件资源(手段)
对上,为用户程序(应用程序)提供一个良好的执行环境(目的)
💡 分层架构的精妙之处:
-
高内聚低耦合:软硬件体系结构是
层状结构,在软件工程上体现为高内聚,即将相同数据代码放同一层(驱动和驱动放一起,硬件放一起),低耦合(层和层之间使用接口方式进行调用,在数据和逻辑上面没有强耦合),这样方便以后哪里错误改哪里,其他不需要变,方便后续代码的可维护性 -
贯穿体系:访问操作系统,必须使用系统调用——其实就是函数,只不过是系统提供的,因为操作系统不允许用户直接访问它,我们便知道了printf可以向显示器上打印数据,并不是我们写的c程序直接写到硬件上,而是c标准库的方法封装了系统调用,通过操作系统对显示器的驱动进行访问,驱动再访问显示器将数据再显示器上进行显示
-
通过结论2,我们程序,只要判断其访问了硬件,那么它必须贯穿整个软硬件体系结构
-
库可能在底层封装了系统调用
2.3理解管理
在整个计算机软硬件架构中 ,操作系统的定位是:一款纯正的“搞管理”的软件
为了方便理解,我们可以带入一个校园比喻:
-
校长(OS): 拥有最高决策权(管理者)。
-
辅导员(驱动程序): 负责跑腿执行(执行者)。
-
学生(底层硬件): 被安排得明明白白(被管理者)。
校长需要每天盯着每个学生学习吗?不需要!他只需要看辅导员递上来的期末成绩单(数据),就能决定谁拿奖学金,谁要被退学。
结论:
- 要管理,管理者和被管理者可以不需要见面
- 不见面怎么管理,通过被管理者身上的
数据进行管理 - 不见面怎么得到数据?由中间层(辅导员)获取,因此OS不与硬件交互,直接从驱动来拿数据即可管理硬件
当学生人数较少时,校长管理学生可以通过excel来获取学生的信息进行管理(对数据管理),可是当学生过多时,遍历excel需要花费过多时间O(n)的效率,管理数据的本质就是对数据进行增删查改,因此可以通过将学生的所有属性通过struct结构体来进行描述,在通过数据结构(如链表)将独立的结构体进行组织起来,我们得出对学生的管理可以转变为对链表的增删查改
因此操作系统管理硬件,将网卡,硬盘,显示器等统一定一个struct类,其包含硬件的所有属性,再通过数据结构进行组织起来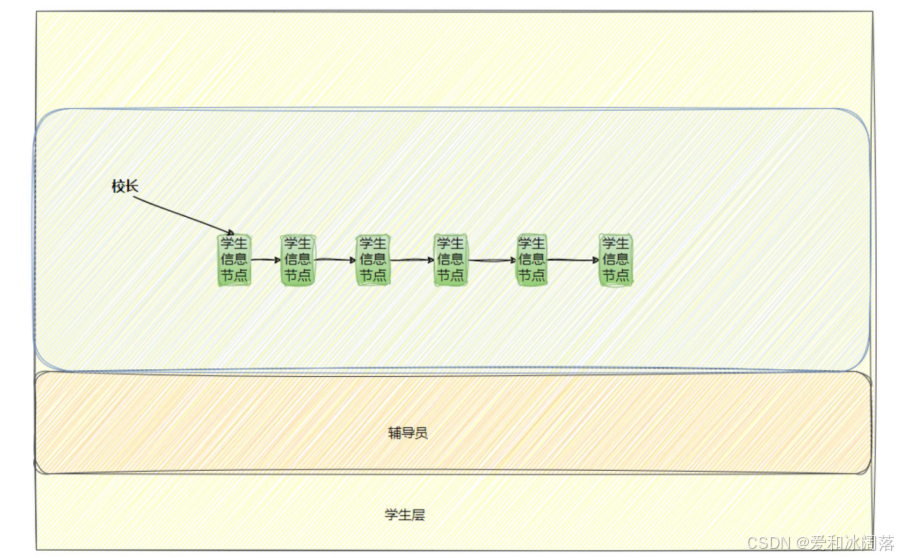
🔥 核心定律:先描述,再组织!
-
先描述: OS 会为网卡、硬盘等硬件统一抽取属性,定义成 struct 结构体(就像定义学生的姓名、学号、绩点)。
-
再组织: 利用双向链表等高效的数据结构,将这些 struct 串联起来。
从此,OS 对硬件的管理,就华丽转身变成了对“数据结构(链表)的增删查改”!
2.4 系统调用和库函数的概念
操作系统向上提供对应的服务,但操作系统不相信任何用户或人
举个例子:printf将数据写入到显示器上,操作系统提供系统调用实现了访问硬件的能力,但用户不能直接访问操作系统里面的数据
就像去银行取钱,银行提供存取款服务,但绝不会让你自己进金库拿钱。必须隔着防弹玻璃,由柜员(系统调用)帮你操作。
但直接使用系统调用门槛较高(需要了解底层参数),所以前辈大佬们对部分系统调用进行了适度封装,形成了各种标准库,大大降低了开发者的二次开发难度。

因此操作系统为我们提供了系统调用(函数调用)来进行为用户服务,进行了封装,用户也无法直接访问操作系统,系统调用既然是函数则大部分都有输入参数和输出参数,用户将参数传给系统调用,操作系统经过处理将输出参数输出,因此系统调用的本质就是方便用户和操作系统之间进行数据交互
总结:
- 在开发角度 ,操作系统对外会表现为一个整体 ,但是会暴露自己的部分接口 ,供上层开发使用,这部分由操作系统提供的接口 ,叫做系统调用。
- 系统调用在使用上 ,功能比较基础 ,对用户的要求相对也比较高 ,所以 ,有心的开发者可以对部分系统调用进行适度封装 ,从而形成库 ,有了库 ,就很有利于更上层用户或者开发者进行二次开发。
三、理解进程概念
3.1 什么是进程?
课本概念:程序的一个执行实例,正在执行的程序等
内核观点:担当分配资源系统(CPU时间,内存)的实体
分析:没有运行起来的程序相当于是文件,文件在磁盘里,当程序被执行,会将其的代码和数据加载到内存中(计算机体系结构决定,拷贝),磁盘上有很多可执行程序可以在同一时刻加载到无数程序到内存中,同理操作系统(软件)要被执行也要被加载到内存中(开机加载),程序被加载有很多状态,如已经执行完的,正在执行,暂停运行的状态,因此OS需要对加载到内存的多个可执行程序进行管理:先描述再组织,在OS内创建struct对象(包含属性集和指向自己代码和数据的指针,指向下一个节点的指针)即进程控制块 PCB,因此在OS内形成了一个程序列表(进程列表),那么进程就等于进程列表+其的代码和数据
在操作系统中struct对象的统称均是PCB,在具体Linux中是struct tast_struct(任务),相当于shell和bash的关系,一个是统称,一个是具体
总结:
- 进程=内核数据结构对象(PCB)+自己的代码和数据
- 进程的所有属性,都可以直接或间接通过task_struct找到
- 操作系统对进程的管理变为对数据结构的增删查改
3.2 PCB的属性集
内容分类
- 标示符PID: 描述本进程的唯一标⽰符 ,用来区别其他进程(类似身份证号)
- 状态: 任务状态 ,退出代码 ,退出信号等。
- 优先级: 相对于其他进程的优先级。
- 程序计数器: 程序中即将被执行的下一条指令的地址。
- 内存指针: 包括程序代码和进程相关数据的指针 ,还有和其他进程共享的内存块的指针
- 上下文数据: 进程执行时处理器的寄存器中的数据[休学例子 ,要加图CPU ,寄存器]。
- I∕O状态信息: 包括显⽰的I/O请求,分配给进程的I∕O设备和被进程使用的文件列表。
- 记账信息: 可能包括处理器时间总和 ,使用的时钟数总和 ,时间限制 ,记账号等。
- 其他信息
- 具体详细信息后续会介绍
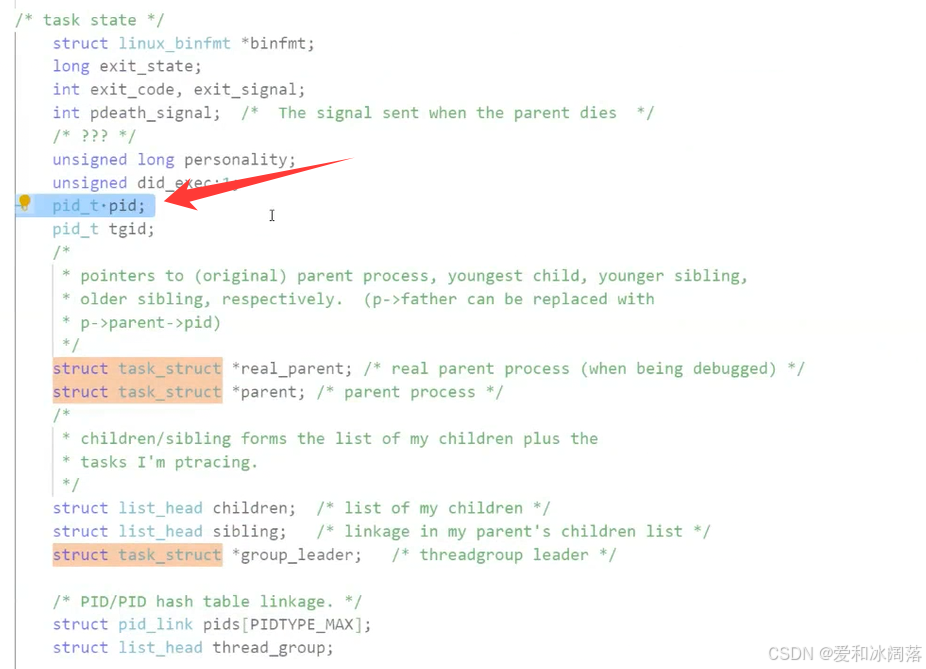
组织进程:可以在内核源代码里找到它。所有运行在系统里的进程都以 task_struct 双链表的形式存在内核里。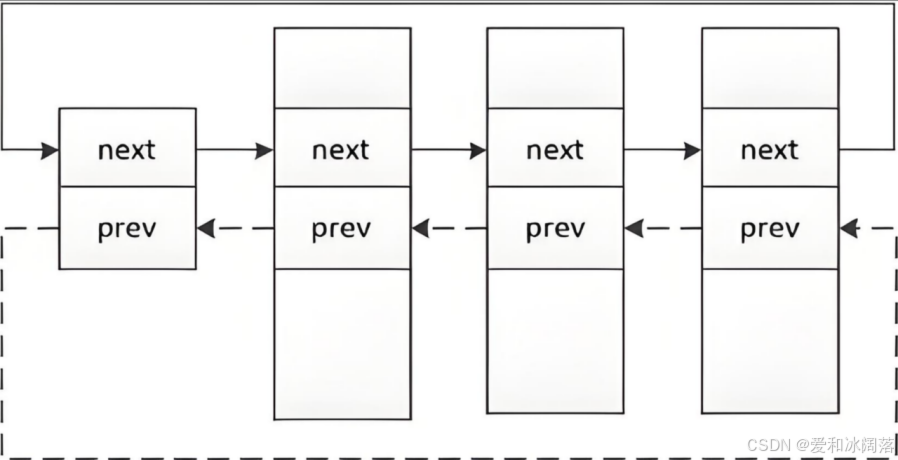
3.3. 查看进程
我们历史上执行的所有指令,工具,自己的程序,运行起来,全部都是进程
查看进程自己的标示符ID,使用系统调用 getpid,其的返回值就是自己进程ID,getppid是获取父进程ID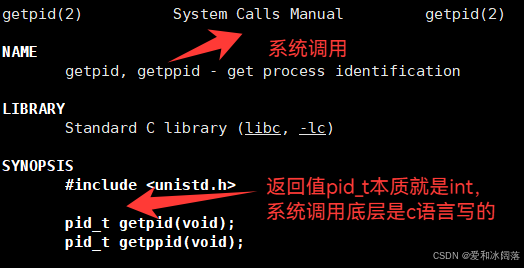
#include<stdio.h>
#include<unistd.h>
#include<sys/types.h>
int main()
{
while(1)
{
sleep(1);
printf("我是一个进程!,我的pid:%d \n",getpid());
}
return 0;
}
方法1:
查看当前系统内启动的进程有哪些:ps axj,查看特定进程 ps agx | head -1 (将头,第一条属性列的名字显示出来) ; ps ajx | grep code,将两条指令连接起来,当然也可以使用&&将其连接起来: ps ajx | head -1 && ps ajx | grep code也可以

注意:为什么使用grep过滤时会查到grepcode,这是因为查进程使用grep做过滤时候,其也是进程,跑起来后其自己过滤的关键字里也包含code,那么当然会将自己也查出来,如果不想看见可以在后面再跟 grep -v grep(-v是反向匹配,包括grep的内容都不匹配),即 ps ajx | head -1 ; ps ajx | grep code | grep -v grep
方法2:
通过文件的方式查看进程,操作系统不仅可以将磁盘的内容通过ls查看到,还可以将内存的内容也以内存的方式呈现,动态看到内存的数据
通过Linux的proc目录结构来查找:ls /proc,proc就是内存级的系统文件
举例如 :要获取PID为1的进程信息 ,你需要查看 /proc/1 这个文件夹
方法3:top指令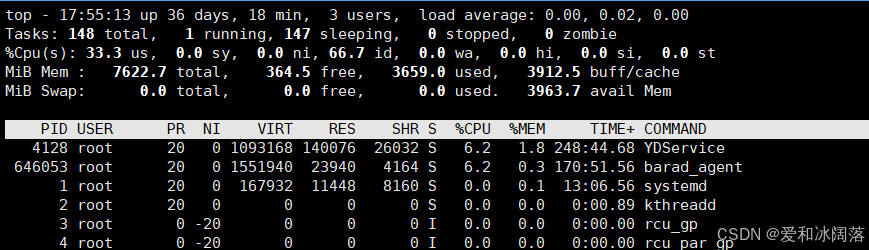
在上述代码中我们加入getppid来获取当前进程的父进程,并不断ctrl+c杀掉进程并不断启动进程,子进程的PID不断变化,而父进程的PID不变
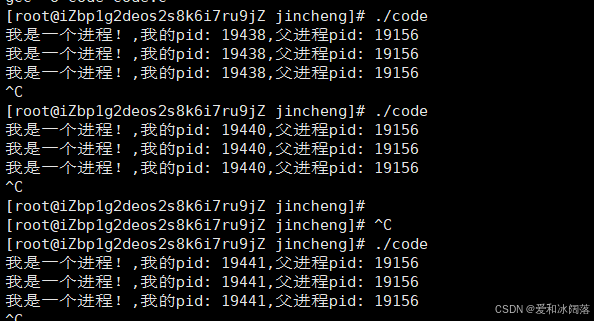
通过ps来查询,我们发现父进程是命令行解释器bash,因此我们可以得出bash本质也是一个进程,OS会给每个用户分配一个bash
bash是一个进程,那么命令行就是bash用C语言写的一串字符串,当我们没有输入指令时,命令行通过scanf函数使其就卡在这,当用户输入指令,也就是输入到bash上
3.4 理解cwd与chdir
在启动我们进程时,我们知道在proc文件里一定有我们启动进程的内容,我们通过 ls /proc/进程的PID -l ,里面的cwd是当前可执行程序所在的路径,exe则是进程对应的可执行文件
在我们之前学习的fopen函数中,我们打开文件可以带绝对路径,也可以不带路径,因为进程在启动时会记录自己的当前路径cwd,将cwd拼接到要打开的文件前面,因此文件便在当前路径下了
注意:当我们删掉进程的exe,进程还是在运行的,因为删掉的是磁盘上的文件,进程在启动时其的拷贝已经加载到内存了,因此不影响进程的运行
更改进程所处的当前路径:chdir
#include<stdio.h>
#include<unistd.h>
#include<sys/types.h>
int main()
{
while(1)
{
chdir("/root");
fopen("hello.txt","a");
sleep(1);
printf("我是一个进程!,我的pid: %d\n",getpid());
}
return 0;
}
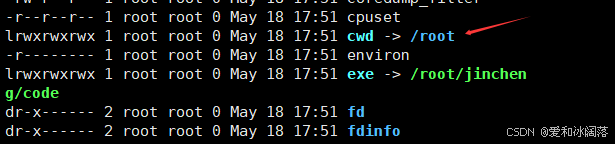
总结:因此当我们执行cd命令是,shell底层便执行系统调用chdir来进行切换
3.5 杀掉进程
方法1:ctrl+c可以杀掉进程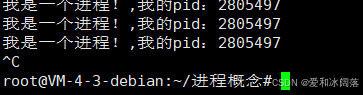
方法2:kill -9 进程的PID即可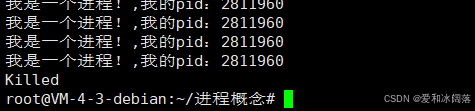

3.6 代码创建子进程(fork)
fork没有参数,只有一个返回值
当下面代码开始运行时是一个执行流,当fork创建子进程后,应该变成两个执行流,子进程和父进程均要执行fork后续printf代码
#include<stdio.h>
#include<unistd.h>
#include<sys/types.h>
int main()
{
printf("父进程开始运行,pid: %d\n",getpid());
fork();
printf("进程开始运行,pid: %d\n",getpid());
return 0;
}

果然是两个进程在运行,一个进程=PCB+自己的代码和数据,那么创建子进程就必然要为其创建PCB,将父进程PCB的内容拷贝给子进程(大部分代码是一样的,浅拷贝),因此子进程默认指向父进程的代码和数据,因此子进程被调度时就会执行父进程的代码,即子进程没有自己的代码和数据,因为目前没有程序新加载
fork的返回值:创建子进程成功,会将子进程的PID给父进程,将0返回给子进程,创建失败将-1返回给父进程
父子进程未来执行不同的代码逻辑
#include<stdio.h>
#include<unistd.h>
#include<sys/types.h>
int main()
{
printf("父进程开始运行,pid: %d\n",getpid());
pid_t id= fork();
if(id<0)
{
perror("fork");
}
else if(id==0)
{
//child
//
while(1)
{
sleep(1);
printf("我是一个子进程!我的pid:%d,我的父进程pid:%d\n",getpid(),getppid());
}
}
else
{
//father
while(1)
{
sleep(1);
printf("我是一个父进程!我的pid:%d,我的父进程pid:%d\n",getpid(),getppid());
}
}
printf("进程开始运行,pid: %d\n",getpid());
return 0;
}
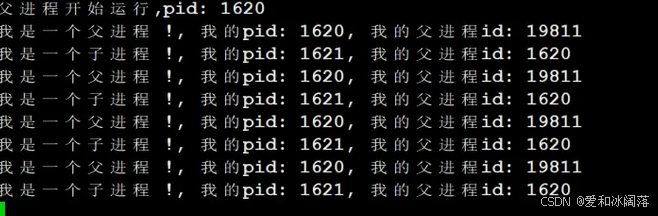
fork之后所有父子代码是共享的,不过父进程的返回值时大于0,子进程的返回值等于0,各自执行对应的语句,因此父子可以执行不同的代码。
3个问题:
- 为什么fork给父子返回各自不同的返回值
解答:
父进程:子进程=1:n,即一个父进程有多个孩子,但是一个子进程只能有一个父亲,因此一定要将子进程的PID返回给父进程,方便父进程通过PID区分子进程 - 为什么一个函数会返回两次?
解答:执行fork函数时(申请新的pcb,拷贝父的pcb给子进程,子pcb放入进程list甚至放入调度队列中)在fork执行自己的return前,子进程已经被创建,return也是代码语句,代码是共享的,那么父子要同时执行return语句,因此return被执行两次 - 为什么一个变量既等于0,又大于0?导致 if else 同时成立???
进程具有独立性(微信挂了不影响我qq的聊天),代码是只读的(共享的),父子进程均不可以修改,父子在数据层面是共享的,一旦一方修改数据,OS把要被修改的数据在底层拷贝一份,让目标进程修改这个拷贝(写实拷贝),在fork函数return返回时是向id写入变量,父子哪个先return,就先修改id,发生写实拷贝之后,父子就拿到不同的变量
验证写实拷贝
#include<stdio.h>
#include<unistd.h>
#include<sys/types.h>
int gval=100;
int main()
{
printf("父进程开始运行,pid: %d\n",getpid());
pid_t id= fork();
if(id<0)
{
perror("fork");
}
else if(id==0)
{
//child
printf("我是一个子进程!我的pid:%d,我的父进程pid:%d,gval:%d\n",getpid(),getppid(),gval);
sleep(5);
while(1)
{
sleep(1);
printf("子进程修改变量:%d->%d",gval,gval+10);
gval+=10;
printf("我是一个子进程!我的pid:%d,我的父进程pid:%d\n",getpid(),getppid());
}
}
else
{
//father
while(1)
{
sleep(1);
printf("我是一个父进程!我的pid:%d,我的父进程pid:%d,gval:%d\n",getpid(),getppid(),gval);
}
}
printf("进程开始运行,pid: %d\n",getpid());
return 0;
}
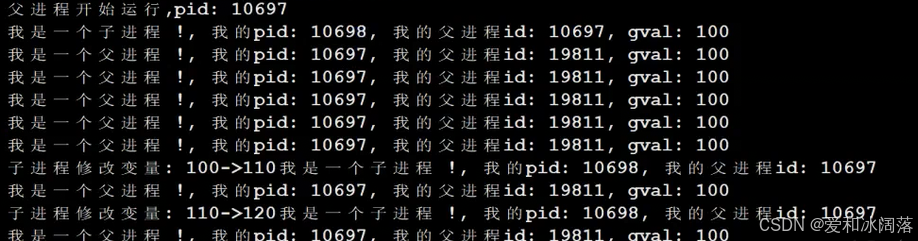
总结
📝 总结与互动
从冰冷的硬件架构,到鲜活的进程生命周期,操作系统的魅力在于它用最严谨的逻辑,管理着最庞杂的资源。希望这篇文章能帮你拨开Linux底层的迷雾,对“进程”有一个全新且立体的认识!
验证你是否真正掌握的标准,就是看能不能自己写出一段 fork() 代码,并成功向别人解释清楚“写时拷贝”的原理。
肝文不易,如果这篇文章对你有所启发,请不要吝啬你的支持:
👍 点赞:是对博主最大的鼓励!
⭐ 收藏:怕以后找不到?收藏起来随时复习!
💬 评论:有任何疑问或者不同的见解,欢迎在评论区和我激情讨论,我们一起进步!
关注 [爱和冰阔乐],带你解锁更多C++/Linux硬核干货!我们下期再见!👋
上集回顾:
【Linux工具链】从代码托管到精准追踪Bug:Git常用指令+GDB临时变量与调用栈剖析

openEuler 是由开放原子开源基金会孵化的全场景开源操作系统项目,面向数字基础设施四大核心场景(服务器、云计算、边缘计算、嵌入式),全面支持 ARM、x86、RISC-V、loongArch、PowerPC、SW-64 等多样性计算架构
更多推荐
 12
12 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)