大数据协作框架 · Flume
💧 “数据世界的超级运水工”Flume 是一个专门用来海量数据的工具。它就像数据世界里的,能把散落在不同服务器上的日志、事件数据,安全地运送到大数据仓库(比如 HDFS、Kafka)里。稳定、可靠、不洒水🧭 Flume 核心架构图 · 一个Agent内部长这样⭐ 一个Agent = Source + Channel + Sink,他们配合默契,让数据“旅行”不迷路。
💧 “数据世界的超级运水工”
🤔 Flume 是什么?
Flume 是一个专门用来收集、聚合、搬运海量数据的工具。它就像数据世界里的“智能水渠”,能把散落在不同服务器上的日志、事件数据,安全地运送到大数据仓库(比如 HDFS、Kafka)里。
🔧 它最厉害的三个特点:✅ 靠谱(数据不丢失) | ⚡ 高并发(每秒成千上万条) | 🧩 灵活搭积木(组件自由组合)稳定、可靠、不洒水

🧭 Flume 核心架构图 · 一个Agent内部长这样
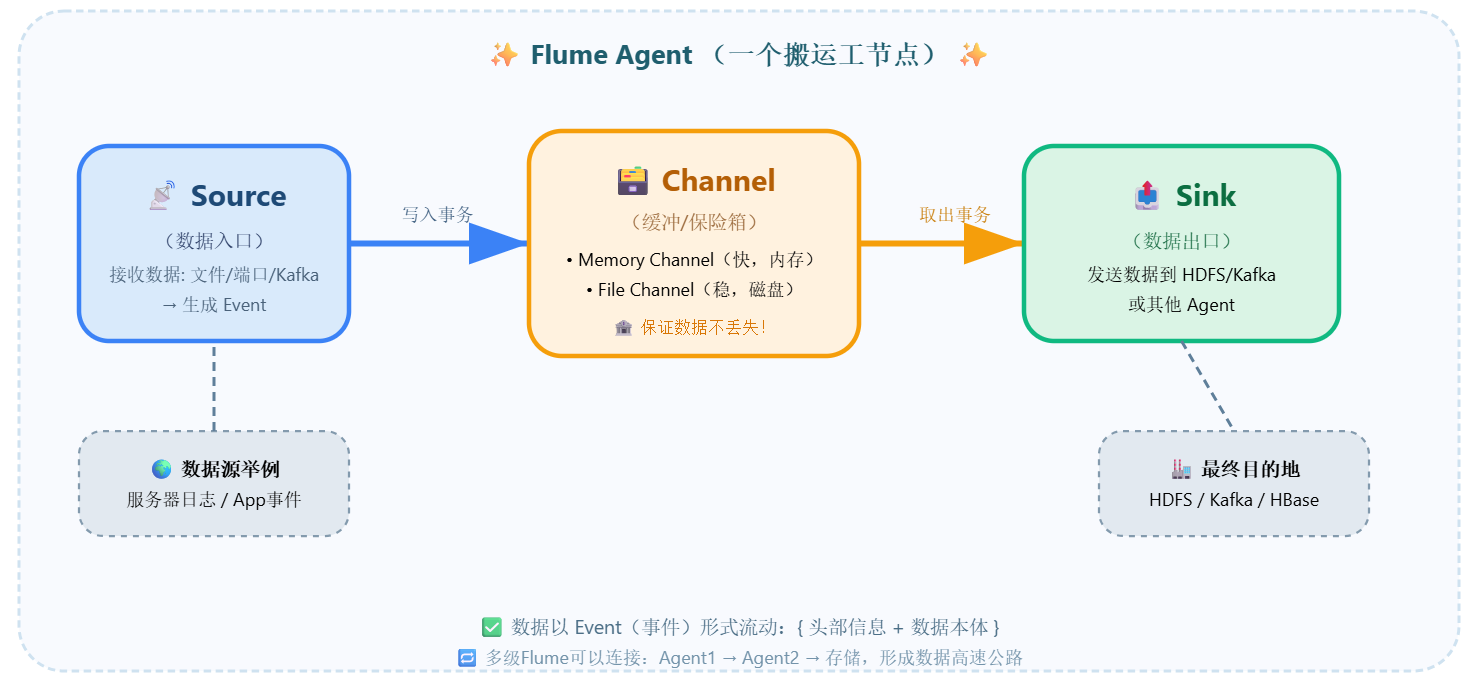
⭐ 一个Agent = Source + Channel + Sink,他们配合默契,让数据“旅行”不迷路
🎤 ① Source“数据水龙头”
从哪里获取数据?Source 负责“打开水龙头”。例如监控一个日志文件、监听网络端口、从Kafka读取消息。Source会把原始数据包装成Flume能理解的 Event(事件),然后递给Channel。
📋 常见类型:Taildir Source(监控文件)、Kafka Source、NetCat Source
🧺 ② Channel“可靠的缓冲水库”
数据临时存放在Channel里面,就像超市的货架。如果Sink来不及发送,数据会暂存在Channel,绝不会丢失。可以选择内存通道(快)或文件通道(安全)。
💾 Memory Channel / File Channel —— 保证事务性
🚰 ③ Sink“数据出口管道”
Sink从Channel取出数据,发送到目标系统:比如HDFS分布式文件系统、Kafka消息队列,或者另一个Flume Agent。Sink可以批量发送,让搬运效率更高。
📡 HDFS Sink / Kafka Sink / Logger Sink (测试用)
🔒 为什么Flume这么可靠?—— 事务机制 就像“图书馆借书登记”
想象一下:Source把数据放到Channel时,会盖上“事务印章”,只有Sink成功把数据交给下一个目的地(比如写入HDFS或传给另一个Flume),这个数据才会从Channel里删除。如果中途网络故障,数据会留在Channel中,等待重试。绝对不会中途弄丢! ✅
📌 高级玩法(大数据必备技能):多个Agent可以连接成复杂管道 ——
• 汇聚模式:成百上千台服务器的日志 → 发给几个聚合Flume → 再写入HDFS (减少写入压力)
• 多路复用:一份数据同时复制到HDFS和Kafka,用于分析和实时流两不误!
📝 动手小例子:监听端口 → 打印日志
配置一个Flume Agent,监听本地的6666端口,你发一句“Hello Flume”,它就在控制台显示出来。
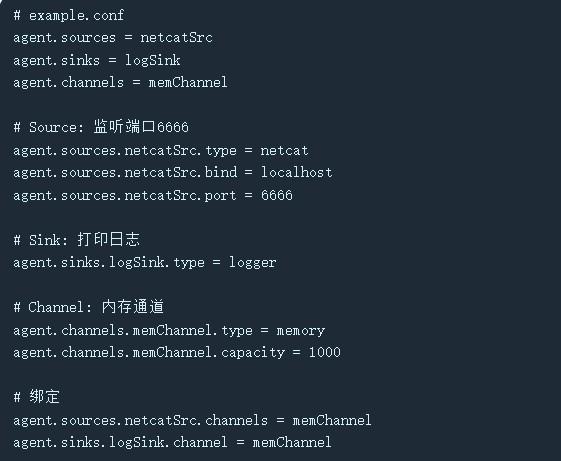
💡 启动命令: flume-ng agent --conf-file example.conf --name agent 然后用 telnet localhost 6666 发消息,就能看到日志输出!超神奇~
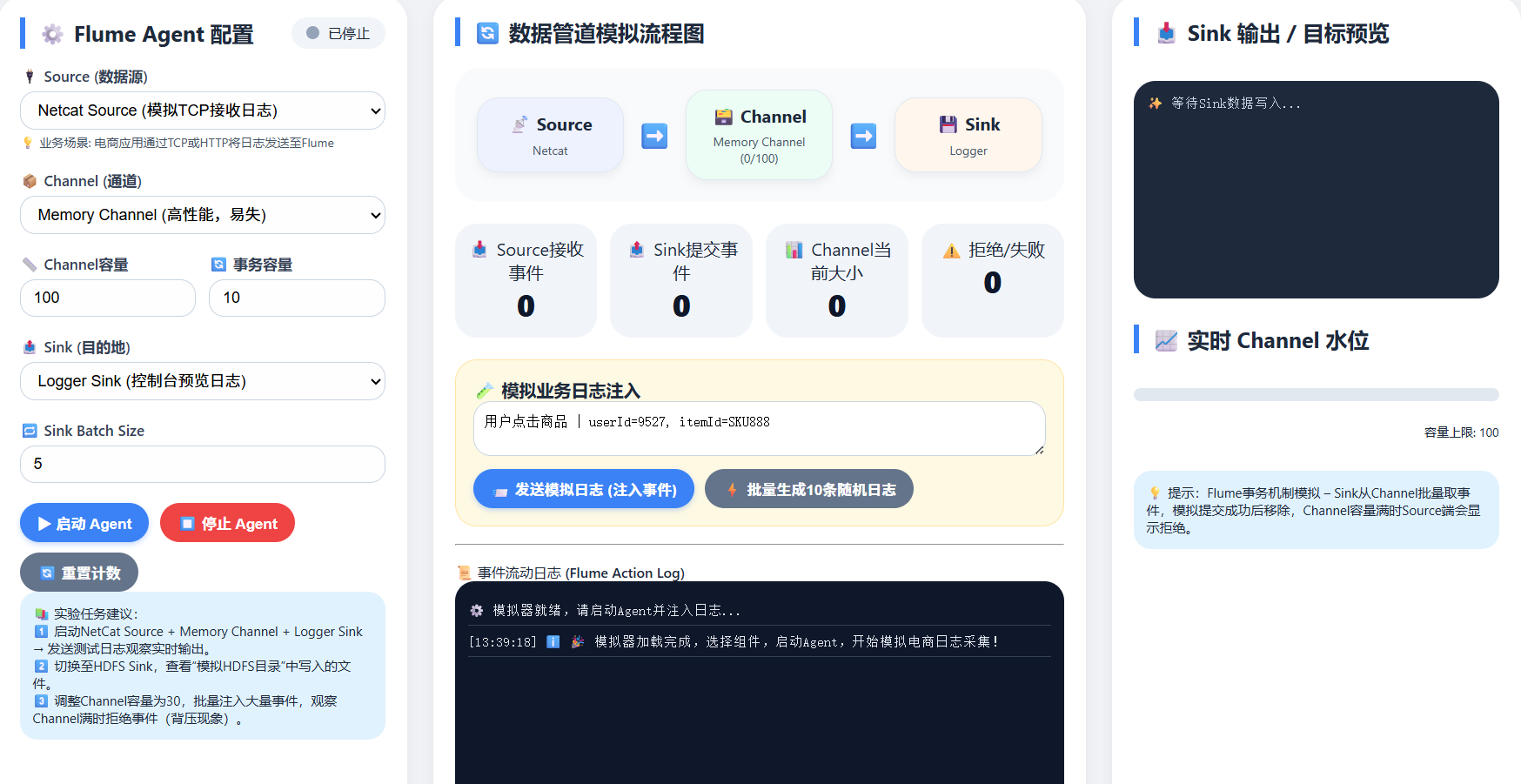
📊 电商实时日志采集实验 · Flume 模拟器真实业务场景
🛍️ 场景:欢乐购电商平台每天产生海量用户行为日志(点击、加购、下单、支付)。
需要使用 Flume 搭建高可靠日志采集管道:从业务服务器接收日志 → 通道缓冲 → 传输至数据平台(HDFS/Kafka/控制台)。
🎯 实验目标: 理解 Flume Agent 架构 (Source / Channel / Sink),动态配置组件,模拟实时数据流动,观察事务与背压。
🧩 实际生产中的Flume “豪华套餐”
在大公司里,Flume通常不是一个人在战斗,它和Kafka是好搭档:
- 🌊 ① 前端Flume收集日志 → 写入Kafka (高吞吐消息队列)
- ⚙️ ② 后端实时程序(Spark/Flink)从Kafka消费,实现实时分析
- 📂 ③ 同时另一个Flume从Kafka拉取数据存到HDFS做历史查询
🏆 一句话概括:Flume是“搬砖工”,Kafka是“大货梯”,HDFS是“超级仓库”。
🔁 真实世界:多个Flume Agent 组成“数据搬运网”
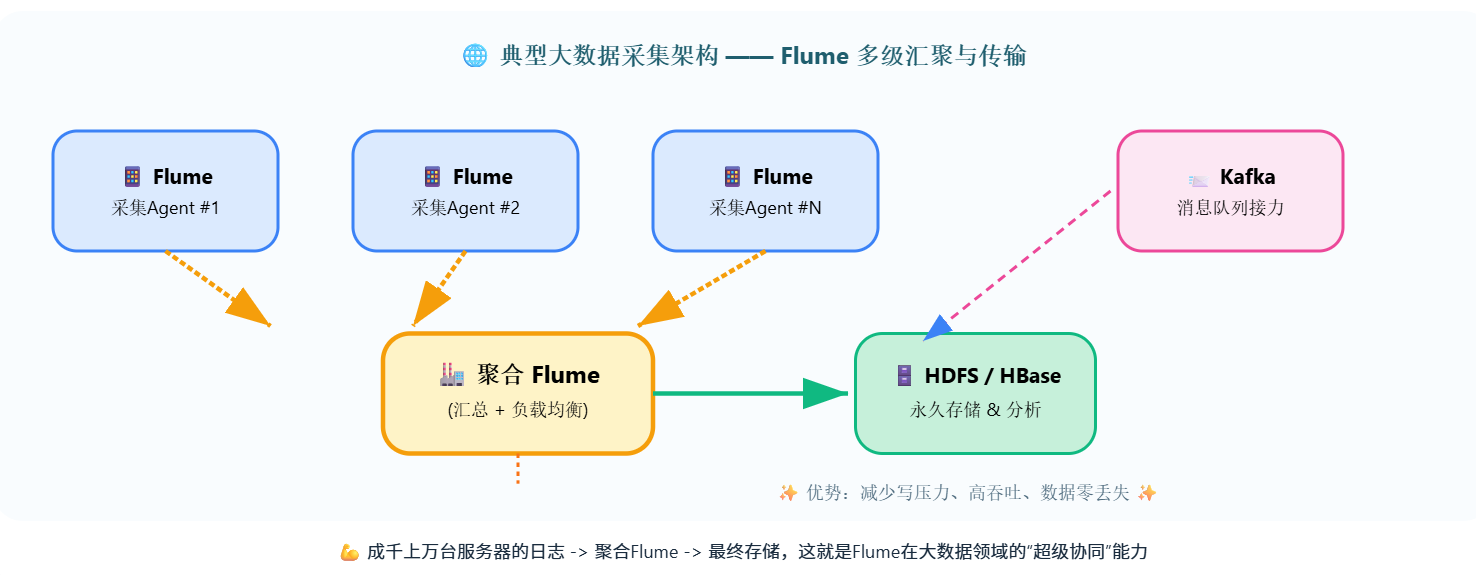
💪 成千上万台服务器的日志 -> 聚合Flume -> 最终存储,这就是Flume在大数据领域的“超级协同”能力
🧠 小结:Flume是大数据生态的“静脉血管”,轻松搬运海量数据,配合Hadoop/Kafka实现实时与离线处理。
🌟 就像快递分拣系统:把来自各个网点的包裹(数据)集中 → 中转站 → 送往最终仓库。学会了这个框架,你离大数据工程师又近了一步! 🚀

openEuler 是由开放原子开源基金会孵化的全场景开源操作系统项目,面向数字基础设施四大核心场景(服务器、云计算、边缘计算、嵌入式),全面支持 ARM、x86、RISC-V、loongArch、PowerPC、SW-64 等多样性计算架构
更多推荐

 6
6 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)