【新版 SeaTunnel Web 最佳实践 2】不用写配置,3 分钟完成 MySQL 单表同步
MySQL 单表同步到 MySQL。准备测试表和 10 万条数据新建 MySQL 数据源新建 Zeta 服务创建同步任务测试数据库和 Zeta 连通性查看自动生成的 HOCON配置调度发布任务手动运行查看日志验证目标表数据整个过程的重点不是“SeaTunnel 能不能同步”。SeaTunnel 本身当然能同步。能不能让更多人更快地把任务跑起来。不用一上来就写 HOCON。不用先背各种 Source
大家好,我是乐峰呀
填几个表,点几下按钮,把 MySQL 的一张表同步到另一张 MySQL。
如果你以前用过 SeaTunnel,应该知道它很强,但对新手来说,第一步往往不是“同步数据”,而是先搞明白:
HOCON 怎么写?
Source 怎么配?
Sink 怎么配?
Zeta 服务怎么连?
任务怎么发布?
日志去哪里看?
听起来不难,但真让一个没接触过 SeaTunnel 的同学上手,还是会有点门槛。
所以新版 SeaTunnel Web 想解决的事情很简单:
不是替代 SeaTunnel,而是补齐体验。
SeaTunnel 负责真正的数据同步能力。
SeaTunnel Web 负责把连接、配置、发布、运行、日志、结果查看这些步骤变得更直观。
这篇文章就用一个最常见的场景演示一下:
MySQL 到 MySQL 的单表同步。
整个过程不需要手写 HOCON 配置,按页面提示一步步填就行。
第一步:准备一张测试表
先在 MySQL 里准备一张源表,然后插入 10 万条测试数据。
这一步主要是为了模拟一个真实一点的数据同步场景。
不是只同步几条 demo 数据,而是让任务真正跑起来,看看 SeaTunnel Web 从任务配置、运行到日志查看的完整链路。
这里可以准备一张类似用户表、订单表、日志表都可以。
比如:
CREATE TABLE user_source (
id BIGINT PRIMARY KEY,
username VARCHAR(64),
email VARCHAR(128),
age INT,
create_time DATETIME
);
然后插入 10 万条数据。
INSERT INTO user_source (id, username, email, age, create_time)
SELECT
n AS id,
CONCAT('user_', n) AS username,
CONCAT('user_', n, '@example.com') AS email,
18 + (n % 50) AS age,
DATE_ADD('2024-01-01 00:00:00', INTERVAL n SECOND) AS create_time
FROM (
SELECT
a.n
+ b.n * 10
+ c.n * 100
+ d.n * 1000
+ e.n * 10000
+ 1 AS n
FROM
(SELECT 0 n UNION ALL SELECT 1 UNION ALL SELECT 2 UNION ALL SELECT 3 UNION ALL SELECT 4
UNION ALL SELECT 5 UNION ALL SELECT 6 UNION ALL SELECT 7 UNION ALL SELECT 8 UNION ALL SELECT 9) a
CROSS JOIN
(SELECT 0 n UNION ALL SELECT 1 UNION ALL SELECT 2 UNION ALL SELECT 3 UNION ALL SELECT 4
UNION ALL SELECT 5 UNION ALL SELECT 6 UNION ALL SELECT 7 UNION ALL SELECT 8 UNION ALL SELECT 9) b
CROSS JOIN
(SELECT 0 n UNION ALL SELECT 1 UNION ALL SELECT 2 UNION ALL SELECT 3 UNION ALL SELECT 4
UNION ALL SELECT 5 UNION ALL SELECT 6 UNION ALL SELECT 7 UNION ALL SELECT 8 UNION ALL SELECT 9) c
CROSS JOIN
(SELECT 0 n UNION ALL SELECT 1 UNION ALL SELECT 2 UNION ALL SELECT 3 UNION ALL SELECT 4
UNION ALL SELECT 5 UNION ALL SELECT 6 UNION ALL SELECT 7 UNION ALL SELECT 8 UNION ALL SELECT 9) d
CROSS JOIN
(SELECT 0 n UNION ALL SELECT 1 UNION ALL SELECT 2 UNION ALL SELECT 3 UNION ALL SELECT 4
UNION ALL SELECT 5 UNION ALL SELECT 6 UNION ALL SELECT 7 UNION ALL SELECT 8 UNION ALL SELECT 9) e
) t
WHERE n <= 100000;
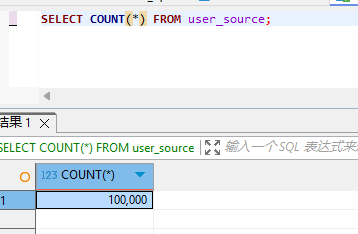
插入完成后可以验证一下:
SELECT COUNT(*) FROM user_source;
这一步完成后,我们就有了一个明确的目标:
把 user_source 这张表,同步到目标 MySQL 数据库中。
第二步:新建 MySQL 数据源
打开 SeaTunnel Web,先进入数据源管理。
这里需要分别创建源端和目标端数据源。
如果源库和目标库是同一个 MySQL,也可以创建一个数据源复用;如果是两个不同的 MySQL,就分别创建两个。
主要填写这些信息:
- 数据源名称
- 数据库类型:MySQL
- JDBC 地址
- 用户名
- 密码
- 数据库名称
填完之后,不要急着保存完就走。
新版 SeaTunnel Web 里可以直接测试数据库连接。
点一下测试连接,确认 SeaTunnel Web 能正常连上 MySQL。
这一步很重要。
很多同步任务失败,不是配置写错了,而是数据库地址、账号、网络、防火墙这些基础连接没有打通。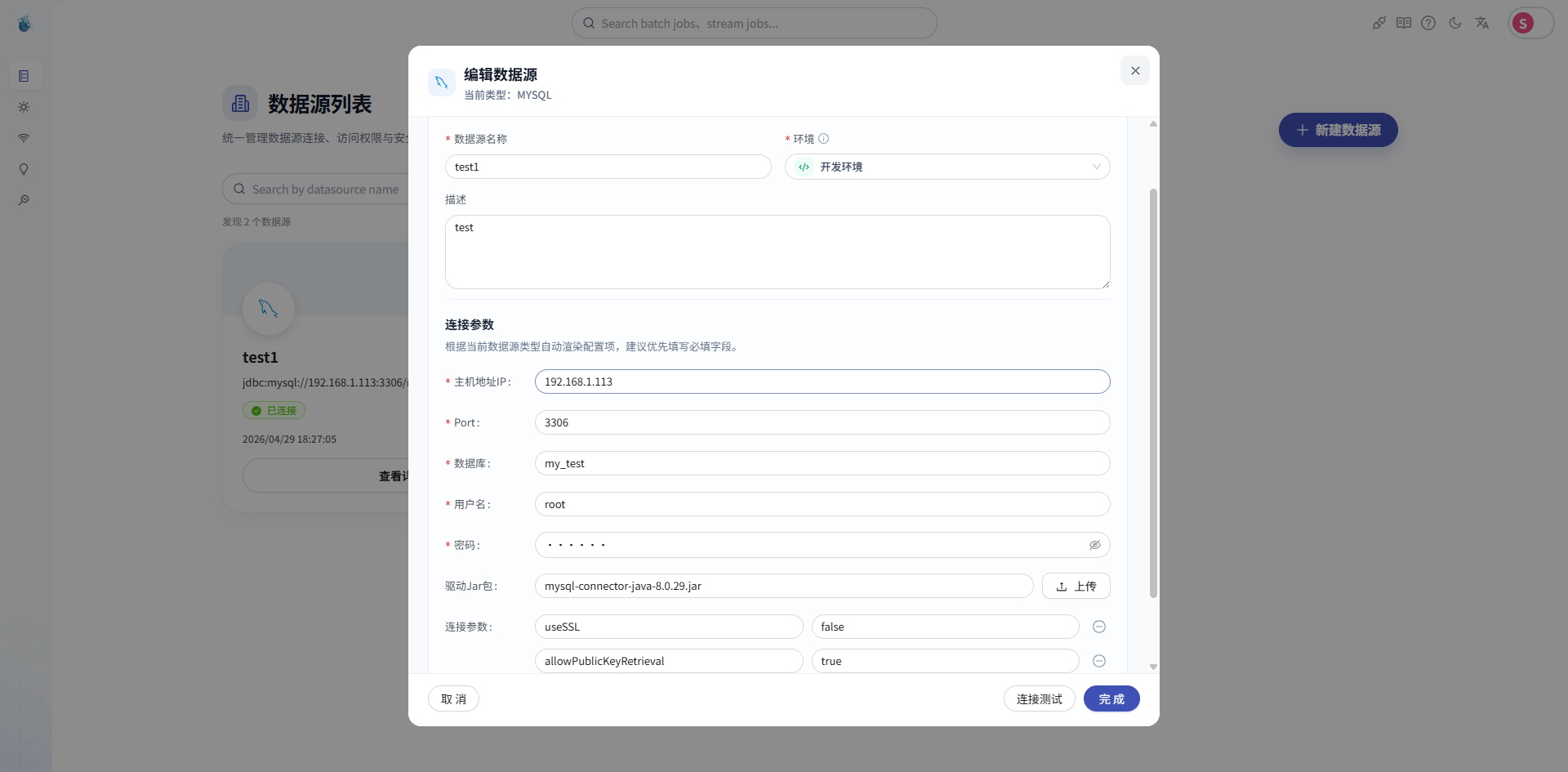
第三步:新建 Zeta 服务
数据源准备好之后,还需要配置 SeaTunnel 的执行服务。
这里使用的是 Zeta 引擎。
在 SeaTunnel Web 中新建 Zeta 服务,填写对应的服务地址和端口。
你可以把它理解成:
SeaTunnel Web 负责创建和管理任务,
Zeta 服务负责真正执行任务。
所以只配置数据源还不够,还需要确保 Web 能连接到 Zeta 服务。
配置完成后,同样建议先做一次连通性测试。
如果这里不通,后面任务即使配置好了,也无法正常提交执行。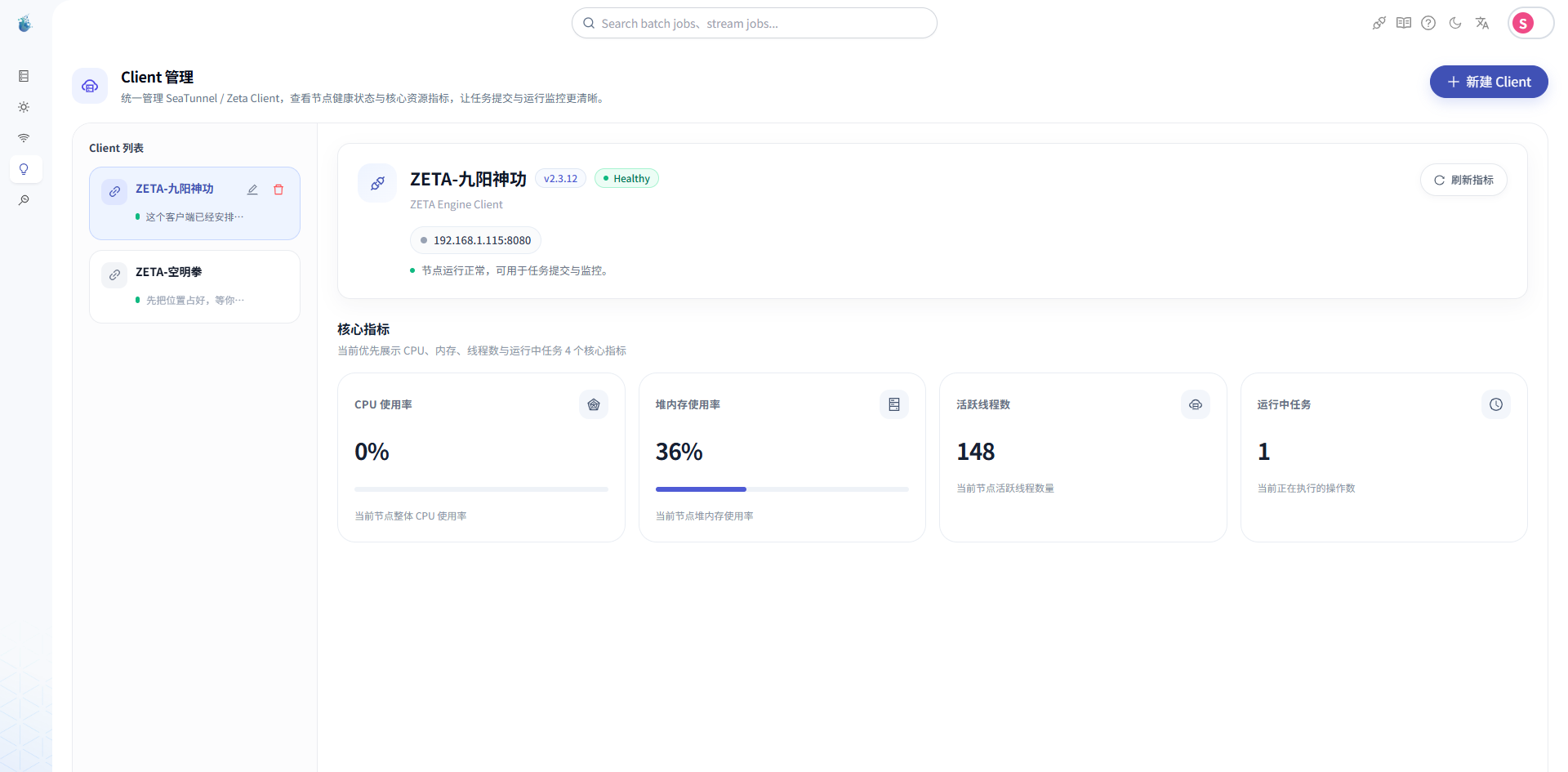
第四步:新建同步任务
接下来进入同步任务页面,创建一个新的同步任务。
选择任务类型:
MySQL 到 MySQL 单表同步
这里的重点是“单表”。
因为单表同步是最适合新手入门的场景:
源端明确。
目标端明确。
字段关系清楚。
任务链路短。
出问题也好排查。
在任务表单里选择刚才创建好的源端数据源和目标端数据源。
然后选择源表,比如:
user_source
再配置目标表,比如:
user_target
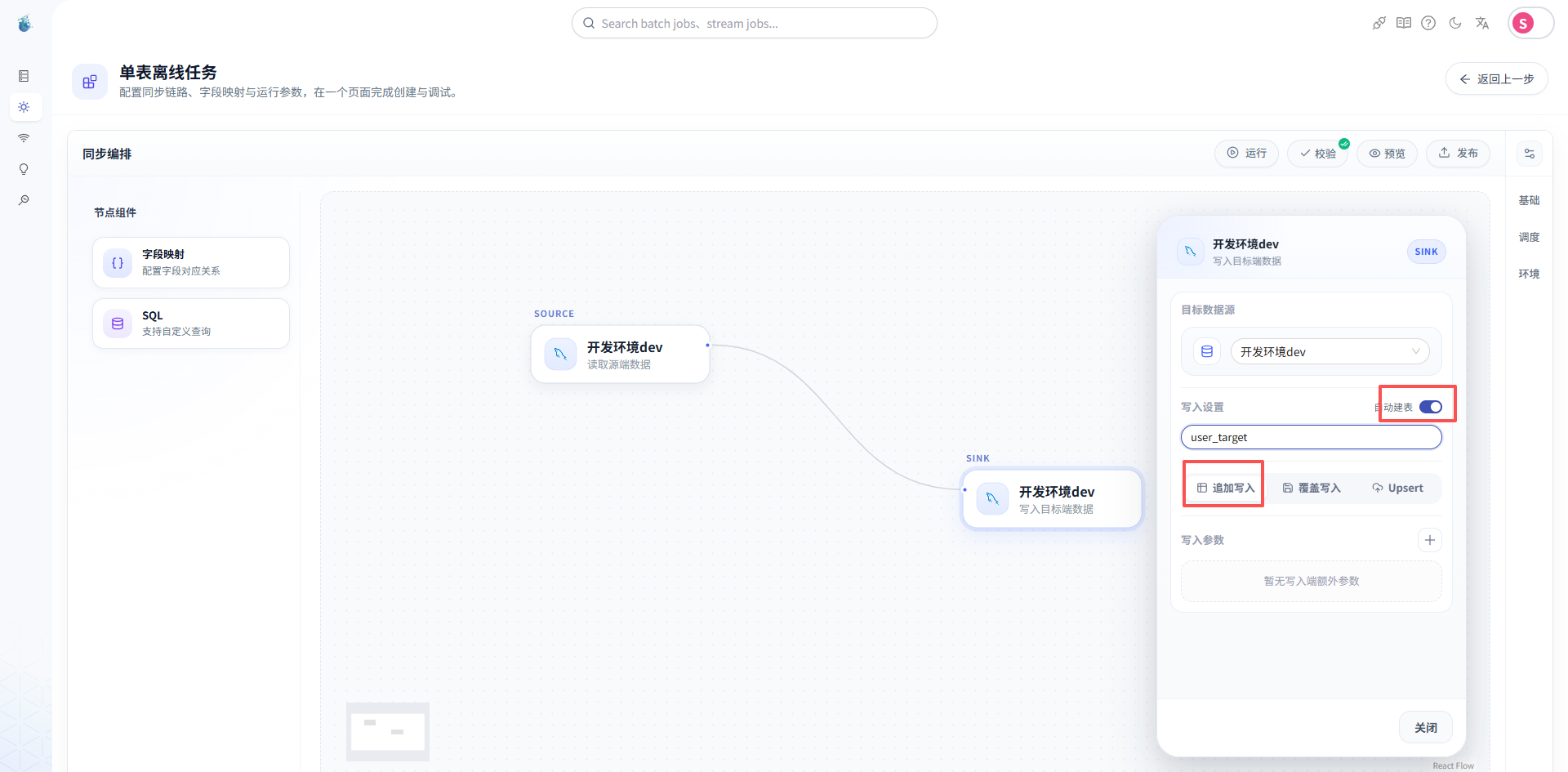
如果目标表不存在,可以根据系统能力选择自动建表,或者提前在目标库中创建好。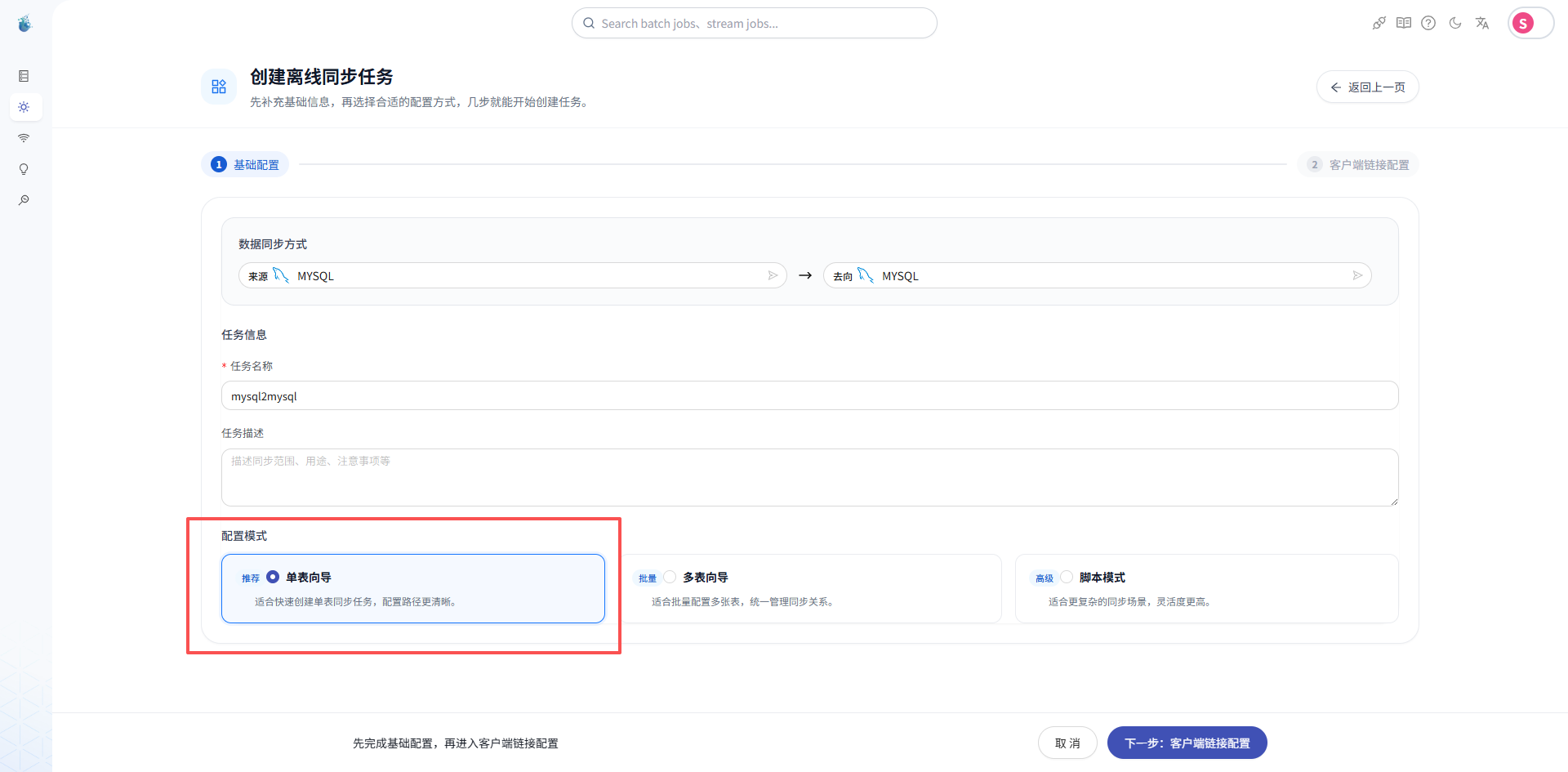
第五步:测试数据库和 Zeta 的连通性
在正式发布任务前,建议做一次完整连通性检查。
这里至少要确认三件事:
- SeaTunnel Web 能连上源端 MySQL
- SeaTunnel Web 能连上目标端 MySQL
- SeaTunnel Web 能连上 Zeta 服务
这一步看起来有点“多余”,但实际非常有用。
因为数据同步任务失败,最常见的问题就是连接问题。
比如:
数据库账号没权限。
JDBC 地址写错。
目标库网络不通。
Zeta 服务没启动。
端口没有开放。
SeaTunnel Web 和执行节点网络不通。
提前检测一下,可以少踩很多坑。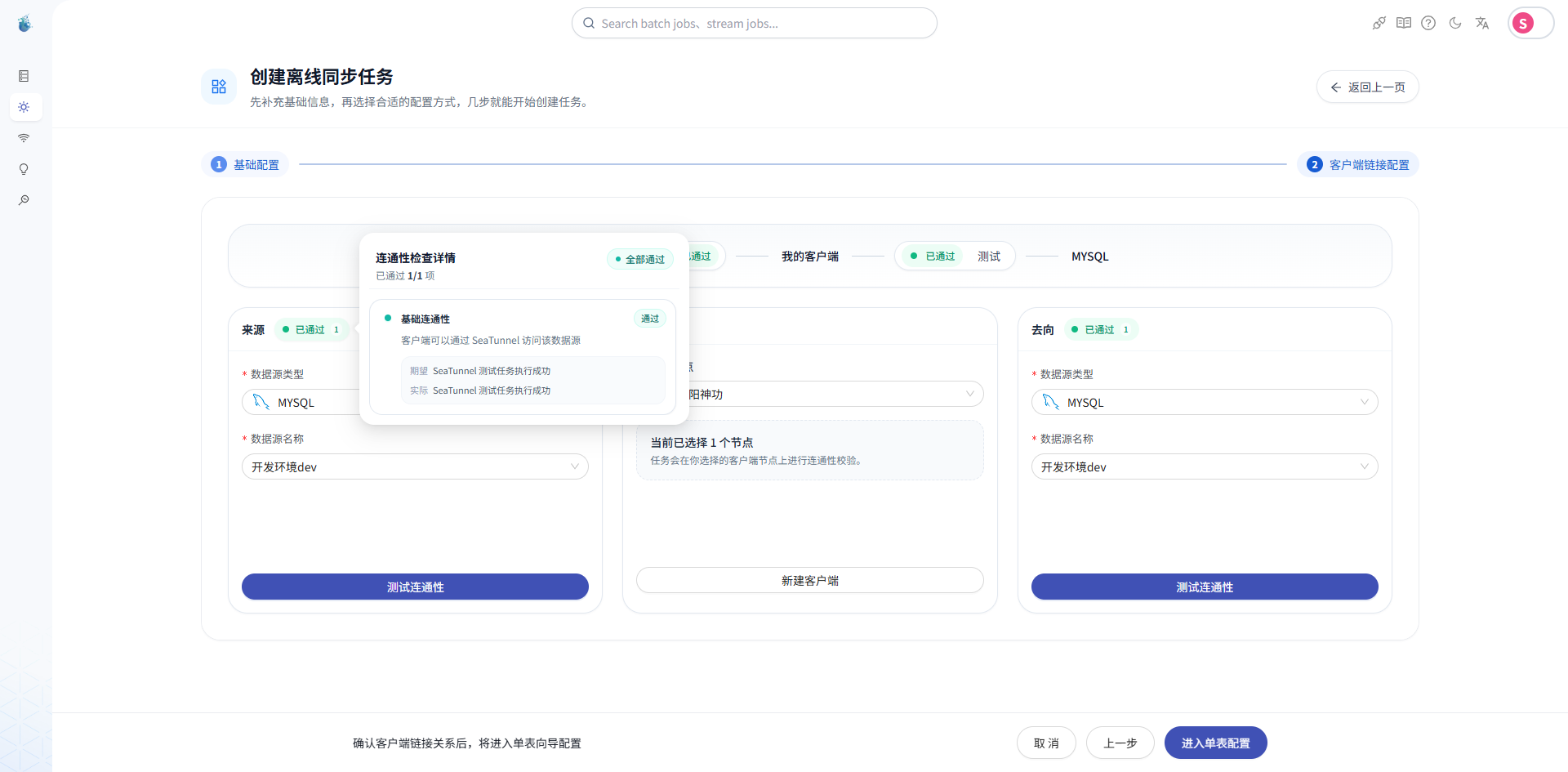
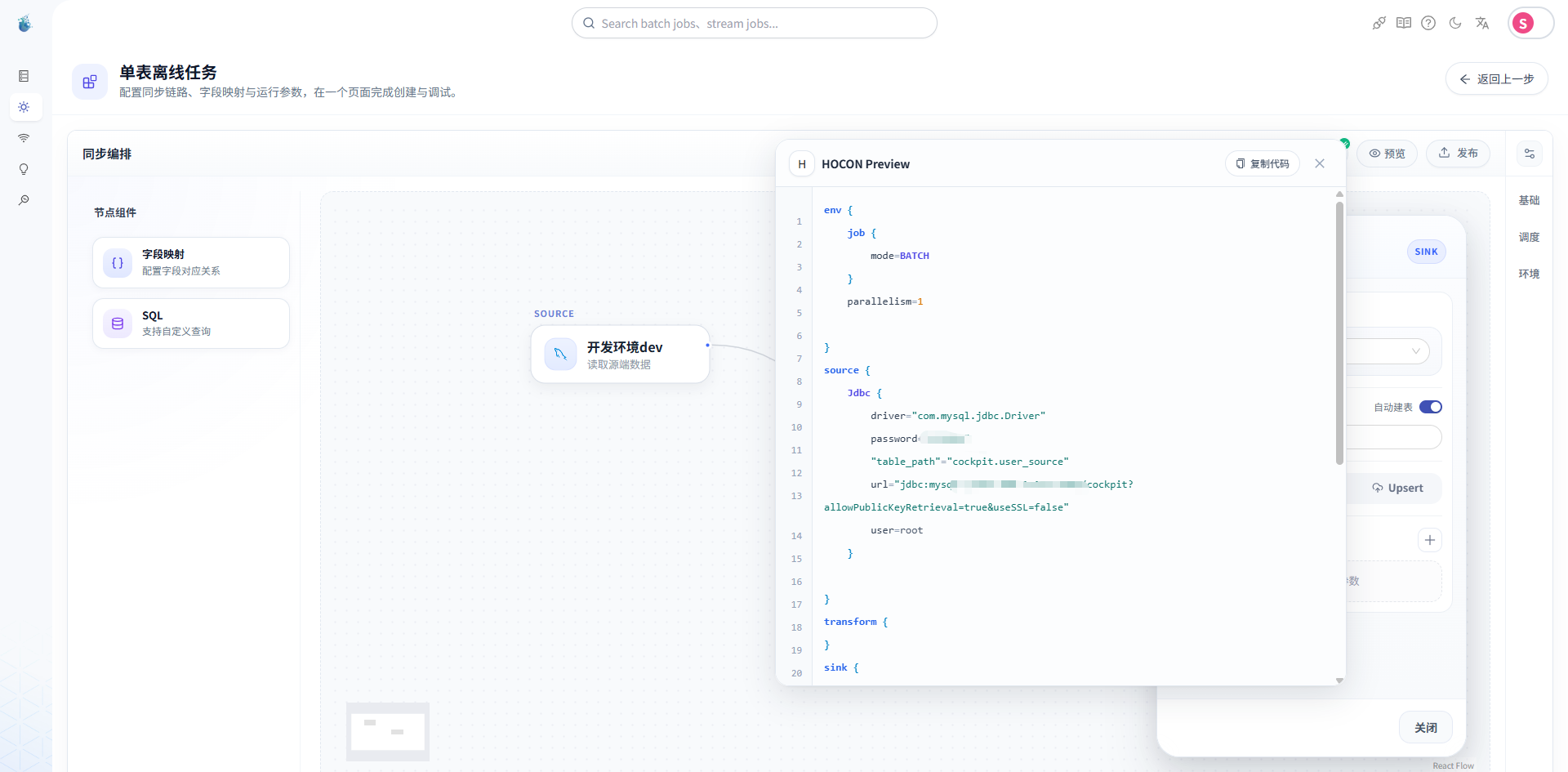
第六步:查看生成的 HOCON 配置
虽然这篇文章的主题是“不用写配置”,但我还是建议你看一眼生成出来的 HOCON。
因为这能帮助你理解 SeaTunnel Web 到底帮你做了什么。
在任务配置完成后,可以查看系统生成的 HOCON 内容。
你会看到类似这样的结构:
env {
parallelism = 1
job.mode = "BATCH"
}
source {
Jdbc {
url = "jdbc:mysql://..."
driver = "com.mysql.cj.jdbc.Driver"
user = "..."
password = "..."
query = "select * from user_source"
plugin_output = "source_table"
}
}
sink {
Jdbc {
url = "jdbc:mysql://..."
driver = "com.mysql.cj.jdbc.Driver"
user = "..."
password = "..."
database = "..."
table = "user_target"
plugin_input = "source_table"
generate_sink_sql = true
}
}
你不需要手写它。
但你可以通过它确认:
源端连的是哪张表。
目标端写到哪张表。
任务模式是不是批任务。
Source 和 Sink 是否正确串起来。
这也是 SeaTunnel Web 的一个核心价值:
降低配置成本,但不隐藏关键细节。
新手可以直接点页面跑任务。
熟悉 SeaTunnel 的用户,也可以查看底层配置,确认任务是否符合预期。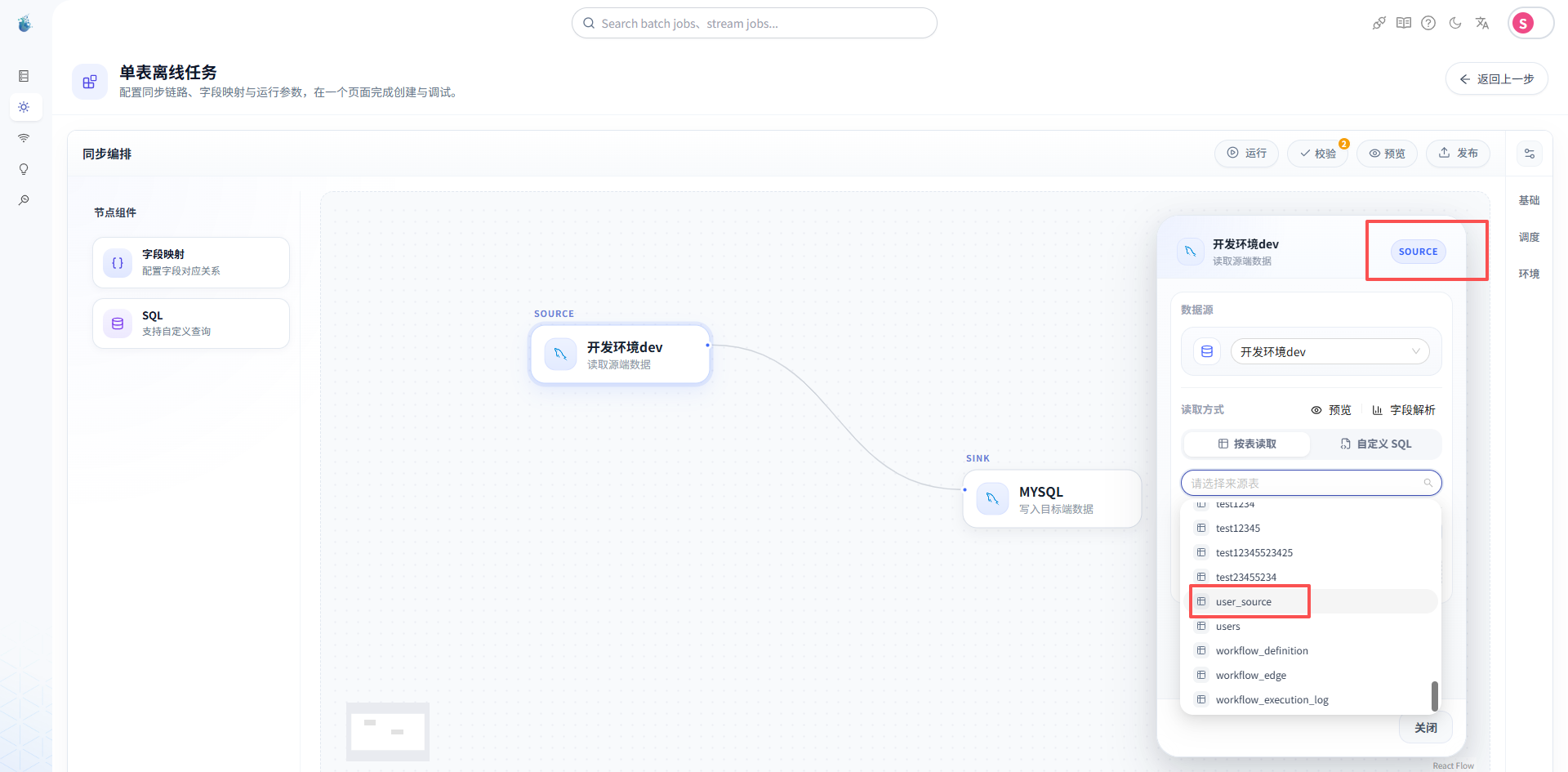
第七步:配置调度
如果只是临时跑一次,可以不配置复杂调度。
但在真实业务里,数据同步通常不是只跑一次。
比如:
每天凌晨同步一次。
每小时同步一次。
每 10 分钟同步一次。
手动触发一次补数据。
在 SeaTunnel Web 中,可以给任务配置调度策略。
这一步的目的就是让同步任务从“手动操作”变成“可管理的周期任务”。
你可以根据业务场景选择合适的执行方式。
对于这次 MySQL 到 MySQL 单表同步,我们可以先配置一个简单的调度,或者直接手动运行。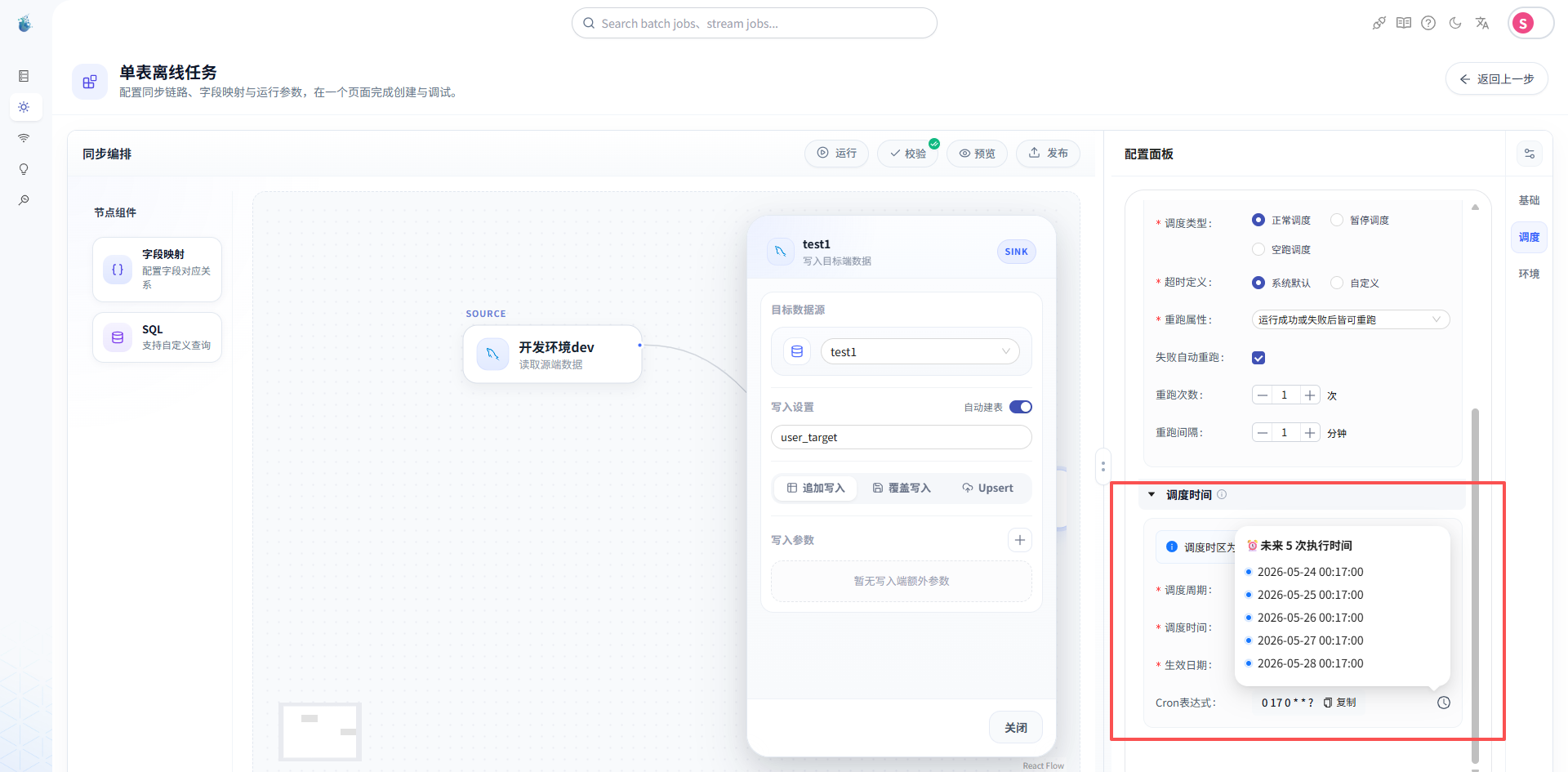
第八步:发布任务
任务配置完成后,下一步是发布。
发布这一步可以理解成:
把当前任务配置固定下来,生成一个可以执行的版本。
这在实际使用中很重要。
因为同步任务不是随便改随便跑的。
你可能会经历这些过程:
先配置。
再检查。
再发布。
再运行。
出问题后修改。
重新发布新版本。
通过发布机制,可以让任务配置和运行版本更加清晰。
尤其是多人协作时,能避免“我明明改了配置,为什么运行的还是旧任务”这类问题。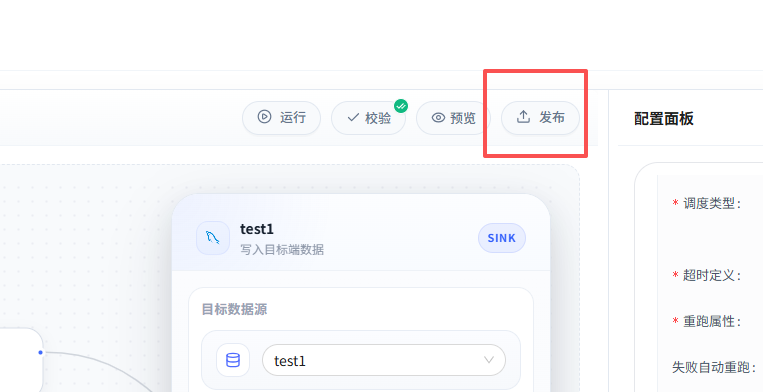
第九步:点击运行
任务发布后,就可以点击运行了。
这一步是最爽的地方。
以前你可能需要:
写 HOCON。
检查插件。
准备命令。
登录服务器。
执行脚本。
查看控制台输出。
现在只需要在页面上点一下运行。
SeaTunnel Web 会把任务提交给 Zeta 服务,由 Zeta 负责执行真正的数据同步。
如果任务提交成功,你会看到任务实例开始运行。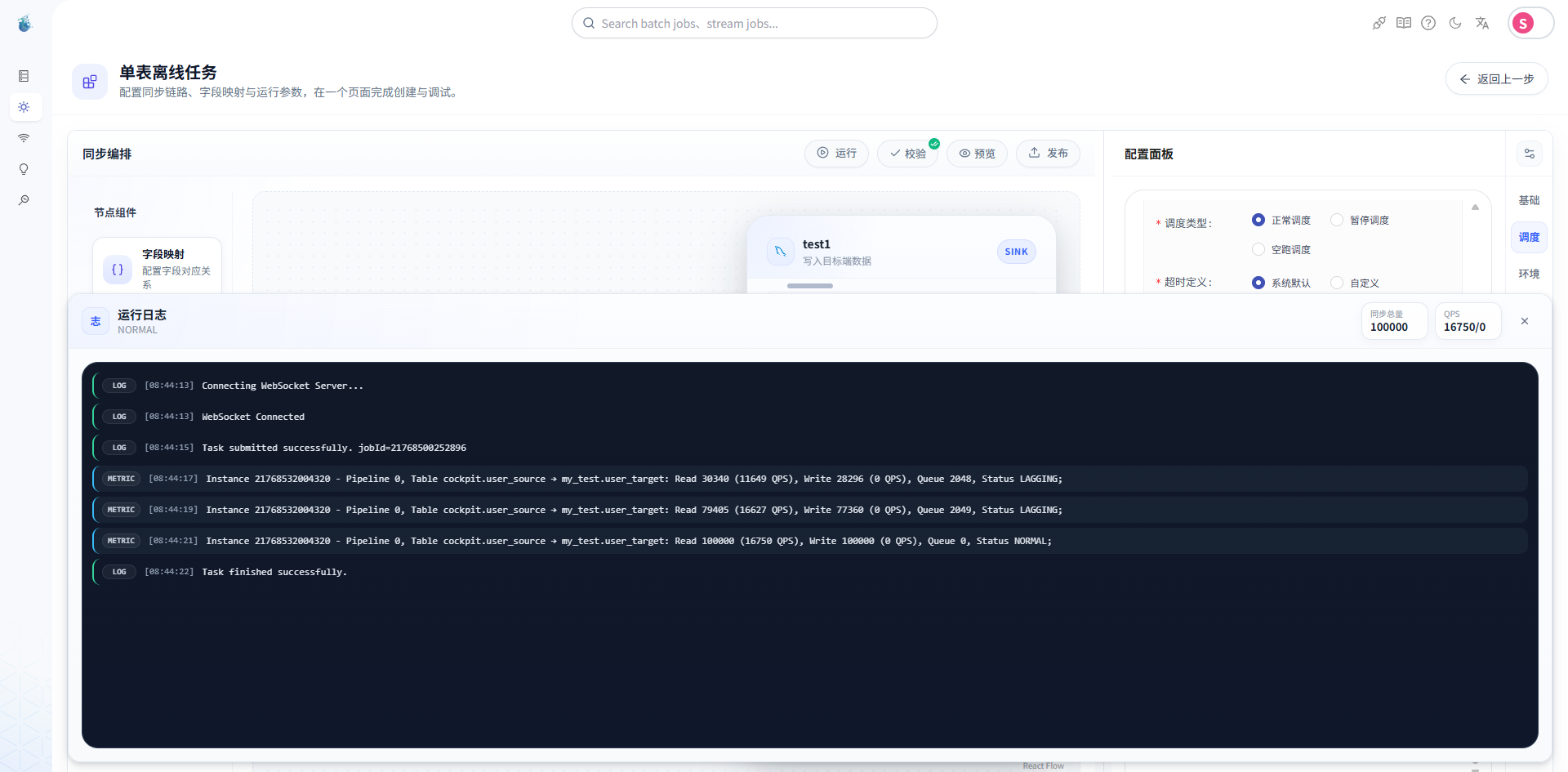
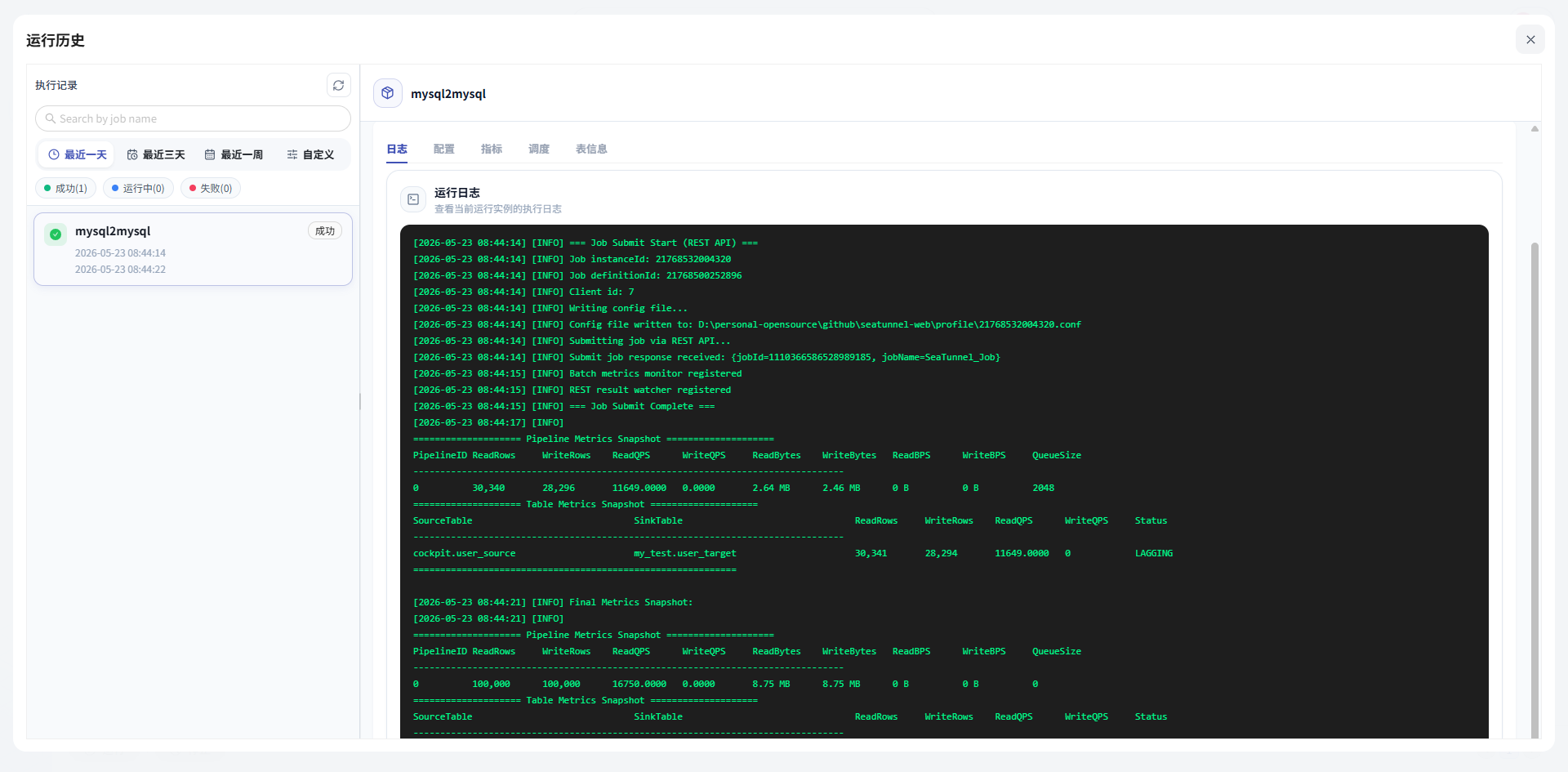
第十步:查看运行日志
任务运行后,不要只看状态。
建议直接点进日志看一下。
日志里可以看到任务从提交、初始化、执行到完成的过程。
如果任务失败,日志也是最重要的排查入口。
常见问题一般包括:
MySQL 驱动缺失。
数据库连接失败。
账号权限不足。
目标表不存在。
字段类型不兼容。
SQL 查询异常。
Zeta 服务异常。
通过日志,你可以快速判断问题发生在哪一层。
是数据源问题?
是任务配置问题?
是目标表问题?
还是执行引擎问题?
这比只看到一个“失败”状态要有用得多。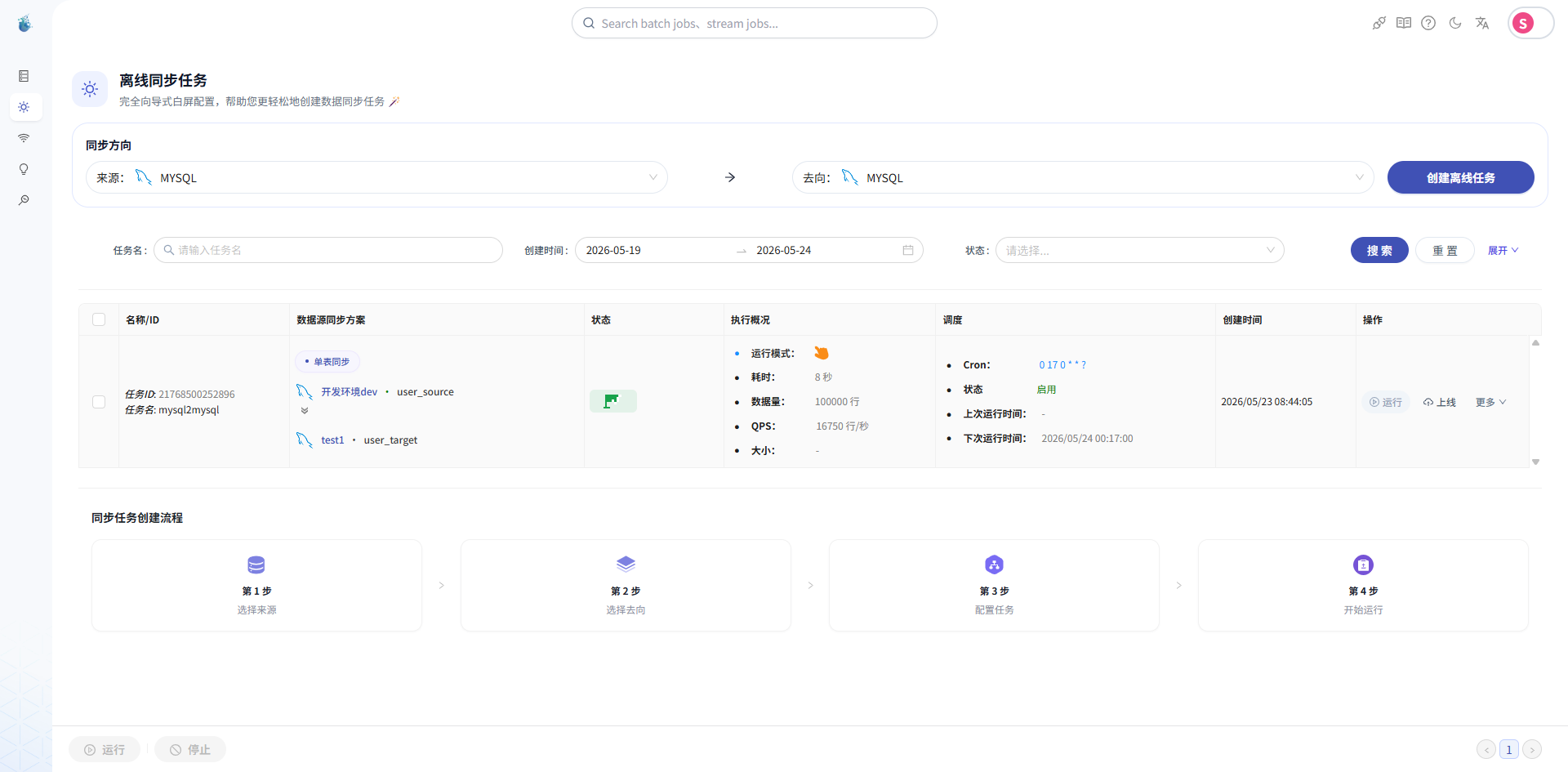
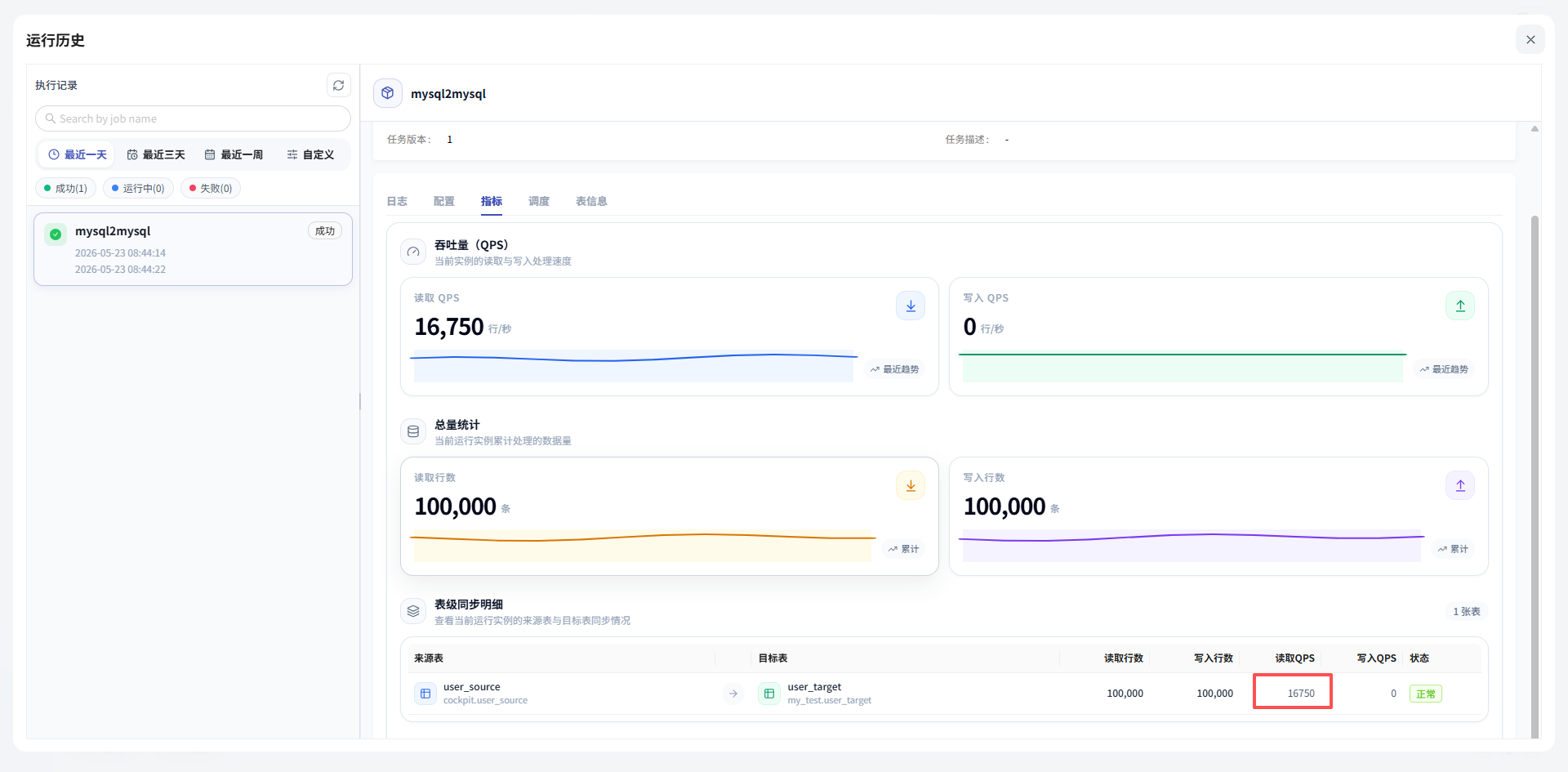
第十一步:查看目标表数据
最后一步,回到目标 MySQL,查看结果表。
比如执行:
SELECT COUNT(*) FROM user_target;
如果源表是 10 万条数据,目标表也同步到了 10 万条,就说明这次 MySQL 到 MySQL 单表同步已经完成。
也可以抽查几条数据:
SELECT * FROM user_target LIMIT 10;
确认字段、数据内容、时间字段等是否符合预期。
到这里,一个完整的数据同步流程就跑通了。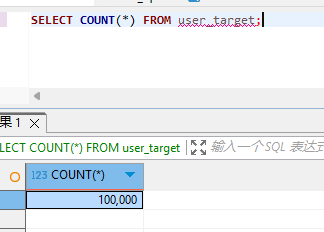
总结一下
这次我们完成了一个非常典型的同步任务:
MySQL 单表同步到 MySQL。
完整流程包括:
- 准备测试表和 10 万条数据
- 新建 MySQL 数据源
- 新建 Zeta 服务
- 创建同步任务
- 测试数据库和 Zeta 连通性
- 查看自动生成的 HOCON
- 配置调度
- 发布任务
- 手动运行
- 查看日志
- 验证目标表数据
整个过程的重点不是“SeaTunnel 能不能同步”。
SeaTunnel 本身当然能同步。
真正的重点是:
能不能让更多人更快地把任务跑起来。
不用一上来就写 HOCON。
不用先背各种 Source/Sink 参数。
不用在服务器和命令行之间来回切。
不用失败后到处找日志。
通过 SeaTunnel Web,把数据源、任务配置、执行服务、调度发布、运行日志、结果验证这些步骤串起来,数据同步这件事就会清晰很多。
一句话:
SeaTunnel 负责同步能力,SeaTunnel Web 负责让同步更好用。
Github 地址:
https://github.com/weifuwan/seatunnel-web

openEuler 是由开放原子开源基金会孵化的全场景开源操作系统项目,面向数字基础设施四大核心场景(服务器、云计算、边缘计算、嵌入式),全面支持 ARM、x86、RISC-V、loongArch、PowerPC、SW-64 等多样性计算架构
更多推荐


 13
13 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)