Apache Thrift:跨语言 RPC 框架,28 种语言一条 IDL 搞定
Apache Thrift 是一款跨语言 RPC 框架,支持28种编程语言,通过IDL(接口描述语言)定义服务接口后自动生成客户端和服务器端代码。它包含数据传输、序列化和应用处理三层架构,解决了异构系统间的通信问题,具有版本兼容性强、支持滚动升级等优势。项目提供编译器、运行时库和教程,适合需要跨语言调用、注重协议兼容性的开发团队。使用流程包括定义.thrift文件、生成目标语言代码并实现业务逻辑,
Apache Thrift:跨语言 RPC 框架,28 种语言一条 IDL 搞定
Thrift 在 GitHub 上已经拿到 10,928 Star。
Apache 开源了这个项目,核心就干一件事:让你用不同编程语言写的程序能互相调用远程方法。定义一份接口描述文件,代码生成器自动产出客户端和服务器端的桩代码,支持 28 种主流语言。
1、这玩意儿是干嘛的
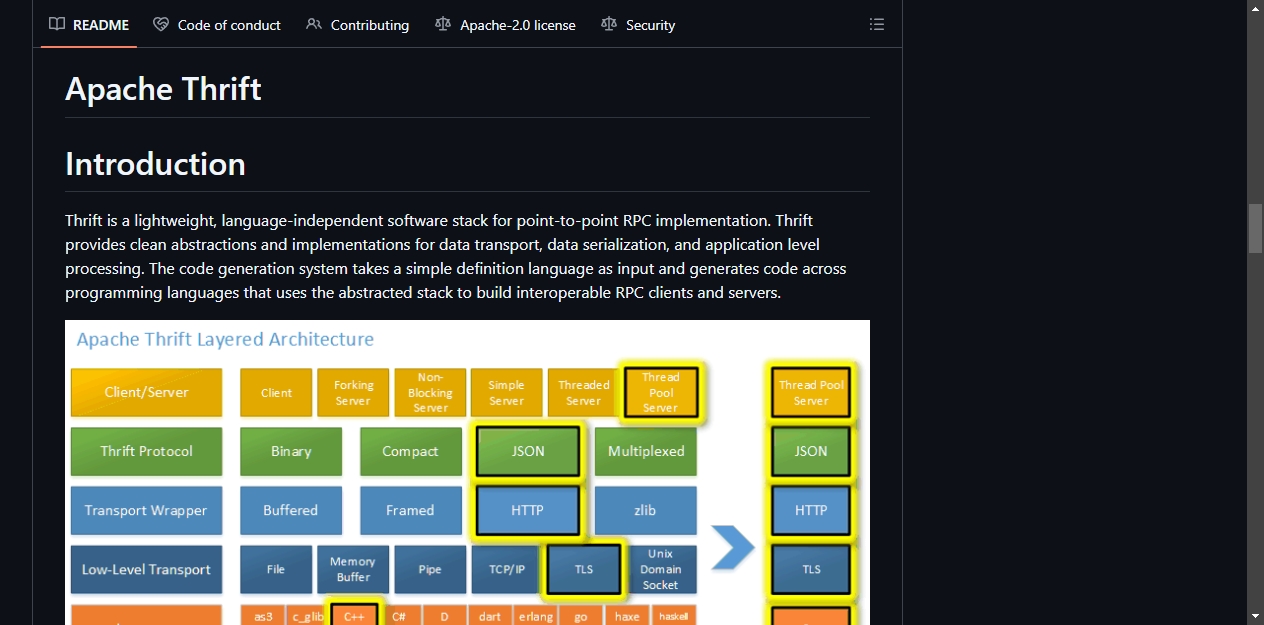
Thrift 是一套完整的 RPC 技术栈,包含三层:
数据传输层:负责字节在网络中的流动。序列化层:把内存里的数据结构转成字节流,或者反过来。应用处理层:支撑实际的 RPC 调用逻辑。
你写一份 .thrift 文件定义数据结构和服务接口,编译器读取后生成目标语言的代码。生成的代码里已经包含了客户端 stub、服务器骨架、序列化/反序列化逻辑。你在生成的骨架里填业务代码,客户端直接调用生成的方法就行,网络细节全部封装在底层。
支持的语言覆盖 C++、Java、Go、Python、PHP、Ruby、Node.js 等常见技术栈,小众语言比如 D、Erlang、Lua 也在支持列表里。
2、为什么要用它
跨语言通信是分布式系统的老问题。团队里前端用 Node.js、后端用 Go、数据分析用 Python、 legacy 系统用 Java,互相调用时总得选一种通用格式。
Thrift 的解决思路是定义中立的语言无关接口。IDL 文件就是契约,各方按契约生成代码,不需要手动维护协议文档,也不会有语言 A 的序列化结果语言 B 解析失败的麻烦。
另一个亮点是版本兼容性。Thrift 的序列化格式支持字段新增和删除,旧客户端读取新服务端返回的数据时,不认识的新字段直接跳过;新客户端访问旧服务端,缺失的字段走默认值。这意味着你可以逐个升级服务节点,不需要停服迁移。
3、项目结构长什么样
代码仓库主要分三块:
compiler/ 里面是 C++ 写的 Thrift 编译器,负责解析 IDL 并生成各语言代码。
lib/ 按语言分子目录,每个目录里是运行时库。这些库处理 socket 连接、内存缓冲、序列化细节,生成的 stub 代码依赖这些库才能跑起来。
tutorial/ 提供了一份入门教程,带你从写第一个 .thrift 文件开始,到跑通一个完整的客户端/服务端示例。
test/ 里有跨语言的测试套件,跑 make cross 可以验证不同语言客户端和服务端之间的互操作性。
4、怎么用
先从源码构建编译器:
./bootstrap.sh
./configure
make
make install
然后写 IDL 文件,比如定义一个计算器服务:
service Calculator {
i32 add(1:i32 num1, 2:i32 num2),
}
执行编译器生成目标语言代码:
thrift --gen py calculator.thrift
生成的 Python 代码里包含服务端骨架和客户端 stub,你只需在骨架里实现 add 方法的逻辑,客户端直接调用即可。
5、适合哪些人用
需要让异构语言服务互相调用的后端团队。已经在用 Protobuf 但想要自带完整 RPC 运行时而不是只拿到序列化格式的开发者。对版本兼容性有要求、希望逐个节点滚动升级的系统。
Thrift 的设计哲学很直接:一次定义,多处生成,跨语言互通。这个概念是 Adam D’Angelo 的 pillar 工具和 Google Protocol Buffers 启发而来,经过多年迭代,目前已经是 Apache 顶级项目。
gelo 的 pillar 工具和 Google Protocol Buffers 启发而来,经过多年迭代,目前已经是 Apache 顶级项目。

openEuler 是由开放原子开源基金会孵化的全场景开源操作系统项目,面向数字基础设施四大核心场景(服务器、云计算、边缘计算、嵌入式),全面支持 ARM、x86、RISC-V、loongArch、PowerPC、SW-64 等多样性计算架构
更多推荐

 2
2 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)