ComputePilot 系列(二):从模型库到 vLLM 推理服务,跑通 AI 服务发布
很多 GPU/HPC 平台的使用门槛,不只在“有没有 GPU”,还在模型、环境、调度和服务入口之间能不能顺畅衔接。 在传统流程里,用户往往需要自己登录服务器,手动找模型目录,确认依赖环境,拼接启动命令,再去调度系统里查任务状态。ComputePilot 把这条链路收进 Web 控制台里:模型库负责沉淀模型,推理服务负责把模型变成 OpenAI 兼容接口,任务调度负责承接资源申请、Slurm
很多 GPU/HPC 平台的使用门槛,不只在“有没有 GPU”,还在模型、环境、调度和服务入口之间能不能顺畅衔接。
在传统流程里,用户往往需要自己登录服务器,手动找模型目录,确认依赖环境,拼接启动命令,再去调度系统里查任务状态。ComputePilot 把这条链路收进 Web 控制台里:模型库负责沉淀模型,推理服务负责把模型变成 OpenAI 兼容接口,任务调度负责承接资源申请、Slurm 作业和日志观测。
本文以一个已下载的 Qwen/Qwen3-0.6B 模型为例,演示从模型库到 vLLM 推理服务的完整观察路径。为了避免误操作,本文只做页面浏览和功能说明,不执行删除、取消、重跑等会影响任务状态的操作。
一、登录平台:进入统一控制台
打开 ComputePilot 地址后,会先看到登录页。这里不建议在公开文章里展示真实账号密码,只需要说明平台支持基于账号进入控制台即可。
登录后,用户会进入统一的 GPU/HPC 控制台,左侧是功能导航,右侧是当前模块的操作区。本文主要会用到三个入口:
- 数据中心:先确认集群资源是否在线。
- 模型库:查看已下载模型,确认模型路径、大小和状态。
- 推理服务:选择模型并配置 vLLM 服务规格。
- 任务调度:观察推理服务背后的 Slurm 任务、日志和资源曲线。
图 1:ComputePilot 登录页
二、数据中心:发布服务前先看资源底座
在创建推理服务之前,最好先回到“数据中心”看一眼资源情况。推理服务不是普通 Web 表单,它最终会消耗 GPU、CPU、内存和端口资源,所以先确认节点健康和资源余量很有必要。
示例环境里可以看到 1 台健康节点、8 个 CPU 核心、15.6 GB 内存、1 张 GPU,以及当前任务运行和排队情况。对于管理员来说,这一屏可以快速判断三个问题:
- 节点是否在线。
- GPU 是否空闲或已经被任务占用。
- 队列里是否有任务等待资源。
如果集群资源紧张,推理服务提交后可能会进入 PENDING 状态;这不是平台异常,而是调度器在等待可用资源。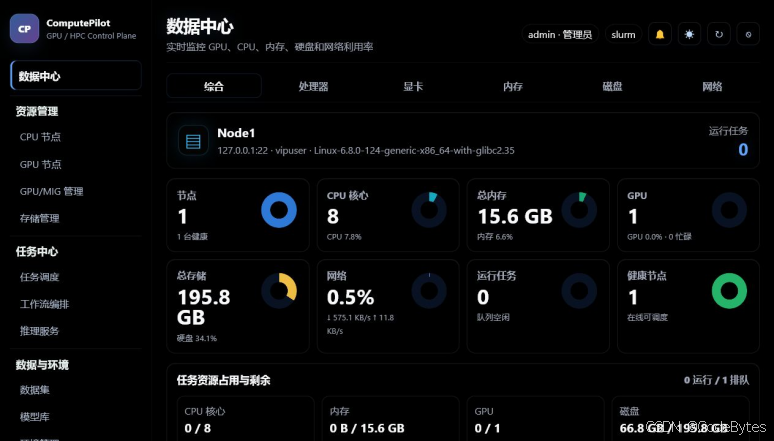
图 2:数据中心展示节点、GPU、内存、磁盘和任务队列状态
三、模型库:让推理服务有模型可选
“模型库”是本文的第一条主线。推理服务页面里的模型下拉框,不是让用户随便输入一个路径,而是来自模型库中已经下载完成、并且当前用户有权限访问的模型。
在示例环境中,模型库里已经有一个 Qwen/Qwen3-0.6B 模型,显示名称为“千问3-0.6B”,位于个人模型库,状态为 downloaded。页面还展示了模型大小、存储路径和更新时间。
这里有几个细节值得注意:
- 模型状态必须是已下载完成,推理服务才能稳定加载。
- 模型可以属于个人模型库,也可以由管理员放入共享模型库。
- 模型路径已经迁移到用户存储目录下,方便后续推理服务从固定路径读取。
- 页面提供“刷新列表”和“扫描我的目录”,适合在手动导入模型后重新同步。
如果模型下载过程中断,模型库也可以作为恢复入口。用户不需要重新理解底层目录结构,只需要在模型条目上继续处理即可。
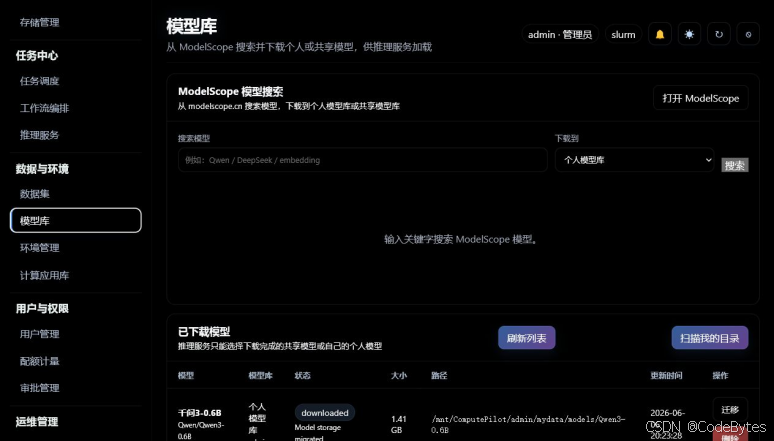
图 3:模型库中已经下载完成的 Qwen3-0.6B 模型
四、推理服务:把模型发布成 OpenAI 兼容接口
有了可用模型后,就可以进入“推理服务”页面。这个页面的上半部分是申请表,下半部分是已有推理服务列表。
申请表里比较关键的字段包括:
|
字段 |
作用 |
|
服务名称 |
用来标识本次推理服务,例如 qwen-chat-api |
|
模型名称 |
从模型库中选择已下载模型 |
|
计算环境 |
示例中为 ComputePilot vLLM |
|
访问入口 |
默认是 `/v1/chat/completions`,兼容 OpenAI Chat Completions 风格 |
|
副本数 |
控制服务副本数量 |
|
每副本 GPU 数量 |
控制每个服务实例占用多少 GPU |
|
vLLM 显存利用率 |
对应 vLLM 的 `--gpu-memory-utilization` |
|
CPU / 内存 GB |
提交给调度器的 CPU 和内存资源 |
|
Slurm 分区 |
选择 GPU 分区或其他可用分区 |
|
运行时长 |
控制作业最长运行时间 |
|
vLLM 启动参数 |
追加自定义 vLLM 参数,例如最大上下文长度、dtype 等 |
示例页面中,模型下拉框已经能看到 Qwen/Qwen3-0.6B · 个人,说明模型库和推理服务之间已经打通。用户只需要补齐服务名称和资源规格,就可以提交审批或部署流程。
下方已有服务列表展示了服务名称、模型、环境、资源规格、访问入口、申请人和状态。示例中服务入口形如 http://服务器地址:端口/v1/chat/completions,点击“复制”即可拿到调用地址。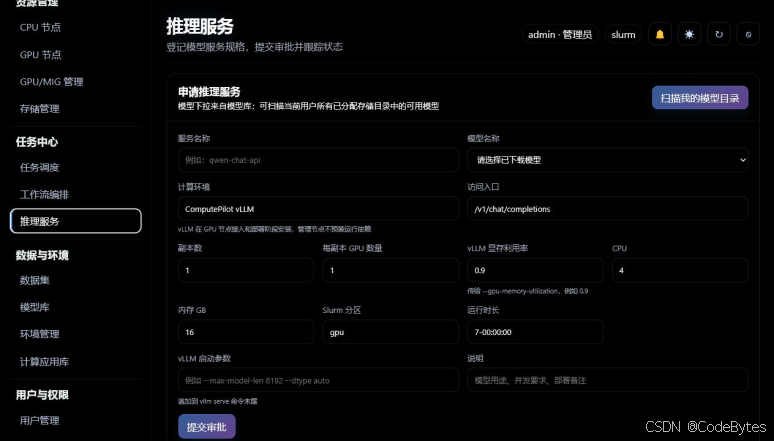
图 4:推理服务申请页面,选择模型并配置 vLLM 资源规格
五、任务调度:推理服务背后仍然是可观测的计算任务
推理服务提交后,并不是一个黑盒后台进程。它会被 ComputePilot 转换为调度任务,并进入“任务调度”页面。
在任务列表中,可以看到推理服务对应的任务类型为 inference,资源规格为 1 GPU / 2 CPU / 4 GB,并且关联了调度 ID。示例中的任务状态是 RUNNING,表示任务已经提交给 Slurm。
这一层设计的好处是:推理服务和普通训练任务共享同一套调度观测能力。管理员可以在任务中心看到谁提交了服务、申请了多少资源、调度器分配到了哪个 ID,以及是否需要查看日志、克隆配置或一键重跑。

图 5:推理服务提交后会出现在任务调度列表中
六、实时日志与资源曲线:定位服务启动状态
在任务列表中点击“日志”,可以打开实时日志与资源曲线窗口。这个窗口把资源观测、stdout、stderr 和事件放在同一个弹窗里。
对推理服务来说,这个入口非常重要。因为 vLLM 服务启动时可能会经历模型加载、显存分配、端口监听、依赖检查等步骤。如果服务迟迟没有可用,通常需要先看三类信息:
- GPU 利用率曲线:判断任务是否真正开始占用 GPU。
- stdout:查看正常启动输出,例如模型加载、服务监听信息。
- stderr:查看依赖缺失、显存不足、端口占用、模型路径错误等异常。
- 事件:查看平台记录的调度、启动、失败或状态变更信息。
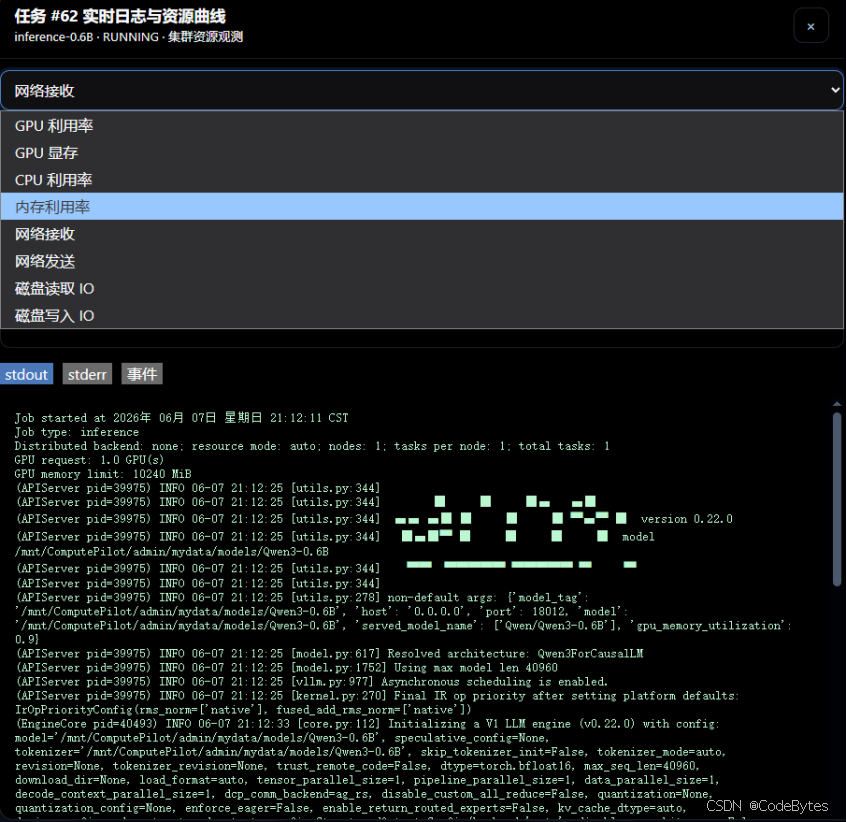
图 6:任务实时日志与资源曲线,集中查看 GPU 利用率和 stdout/stderr
七、从页面到命令:平台帮我们封装了哪些细节
站在用户视角,创建推理服务只是填写表单;但平台背后其实做了不少工作。
以本次示例为例,任务会被转换为类似下面的 vLLM 启动逻辑:
vllm serve /mnt/ComputePilot/admin/mydata/models/Qwen3-0.6B \
--host 0.0.0.0 \
--port 18012 \
--served-model-name Qwen/Qwen3-0.6B \
--tensor-parallel-size 1 \
--gpu-memory-utilization 0.9
也就是说,平台把模型路径、服务端口、模型别名、GPU 数量和显存利用率拼装成可运行命令,再交给调度器执行。这样用户不用每次手写启动脚本,也不用在多个终端里来回确认模型路径和日志位置。
更重要的是,ComputePilot 还把这个过程重新映射回 Web 控制台:服务列表能看到访问入口,任务列表能看到调度状态,日志窗口能看 stdout/stderr 和资源曲线。
八、这条链路适合哪些场景
模型库到推理服务这条链路,适合下面几类场景:
- 团队内部共享大模型服务,减少每个人重复部署。
- 实验室或企业内部做模型验证,把模型快速发布成接口。
- 多个用户共用 GPU 服务器,需要统一排队、配额和日志追踪。
- 管理员希望保留服务申请、资源占用和任务运行记录。
- 算法同学不想直接维护复杂的 Slurm 脚本和 vLLM 启动参数。

openEuler 是由开放原子开源基金会孵化的全场景开源操作系统项目,面向数字基础设施四大核心场景(服务器、云计算、边缘计算、嵌入式),全面支持 ARM、x86、RISC-V、loongArch、PowerPC、SW-64 等多样性计算架构
更多推荐

 9
9 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)