从“抽卡”到“交付”:GPT-Image-2 如何把 AI 生图变成生产力工具
一、AI生图商用化的“三座大山”
过去两年,AI生图一直在“看起来很厉害”和“用不起来”之间徘徊。
痛点一:文字乱码。 模型能画出绝美的画面,但一到文字就露馅——缺笔少画、字形崩塌、排版混乱。生成带文案的海报几乎都需要人工二次修图。
痛点二:排版失控。 设计师精调了十遍的提示词,出一张满意的图,下一张又完全跑偏。AI生图长期停留在“抽卡”阶段——输入一段精美的提示词,祈祷模型能理解你的意图,然后在一堆废片中寻找那一张“神图”。
痛点三:风格漂移。 第一张是橙色圆角卡片,第八张变成了紫色方角——无法保持品牌视觉一致性,无法批量生产。
GPT-Image-2 的出现,把这“三座大山”一并推倒了。
平时做这类AI工具的对比测试,我习惯在几个模型之间切着用,一个地方能接好几个,不用反复登录(gemini-zh.xyz),实测对比起来效率高不少。下面直接拆解它的核心能力。
二、核心突破:从“画得像”到“画得对”
2.1 文字渲染:99%准确率的降维打击
文字渲染一直是AI生图的“阿喀琉斯之踵”。在GPT-Image-2上,这个问题几乎被彻底解决。
| 模型 | 商用文字准确率 | 多行排版稳定性 | 二次修图率 |
|---|---|---|---|
| GPT-Image-2 | 99.0% | 对齐规整、自动适配行距 | ≈0% |
| DALL-E 3 | 61.5% | 轻微错位、行距不均 | 45% |
| Midjourney v6 | 47.2% | 多行文案极易错乱重叠 | 78% |
| SDXL | 34.8% | 排版混乱、字符缺失 | 92% |
数据来源:SegmentFault多场景压力测试
在实测中,无论是复杂的英文排版,还是大段的中文字符、日韩文,首次生成的准确率高达95%以上。你可以直接让它生成一张带有三行中英双语标题的春季营销海报,文字边缘锐利,毫无错漏。
更令人震撼的是它对复杂中文排版的理解——生成“广州市小学数学试卷”,卷头标题、填空题下划线、几何图形标注,以及试卷特有的宋体/楷体排版风格,全被精准还原。生成《蜀道难》真迹图片,文字不仅准确,还做到了书法作品应有的行云流水、笔锋苍劲,甚至连纸张的做旧纹理和印鉴都到位了。
这背后是技术架构的根本转变:传统扩散模型将文字作为“纹理”绘制,而GPT-Image-2采用自回归序列建模,将图像Patch与文本Token统一视为序列进行联合建模——文字作为“序列”被预测生成,而非作为“纹理”被绘制。针对CJK(中日韩)字符集进行了专门的语义空间映射训练,中英日韩混排场景下字符边界清晰,基线对齐精度接近矢量渲染效果。
2.2 推理驱动:先“想”再画
传统文生图模型依靠的是“词袋匹配”——你给什么词它画什么。而GPT-Image-2集成了推理能力:它不是直接画,而是先“理解任务→拆解结构→再生成”。
当你输入“生成一张信息图,展示明天旧金山天气适合的活动”时,它会先去查询明天的天气数据,然后根据天气推测适合的活动,最后再把这些逻辑视觉化。在实测中,让它生成“2026年AI行业报告封面,包含最新的市场增长率数据”,模型通过联网检索了最新信息,并在海报中准确呈现了数据图表。
这种“先思考、后落笔”的能力,让它不再是单纯的画图工具,而是一个具备信息处理能力的视觉系统。
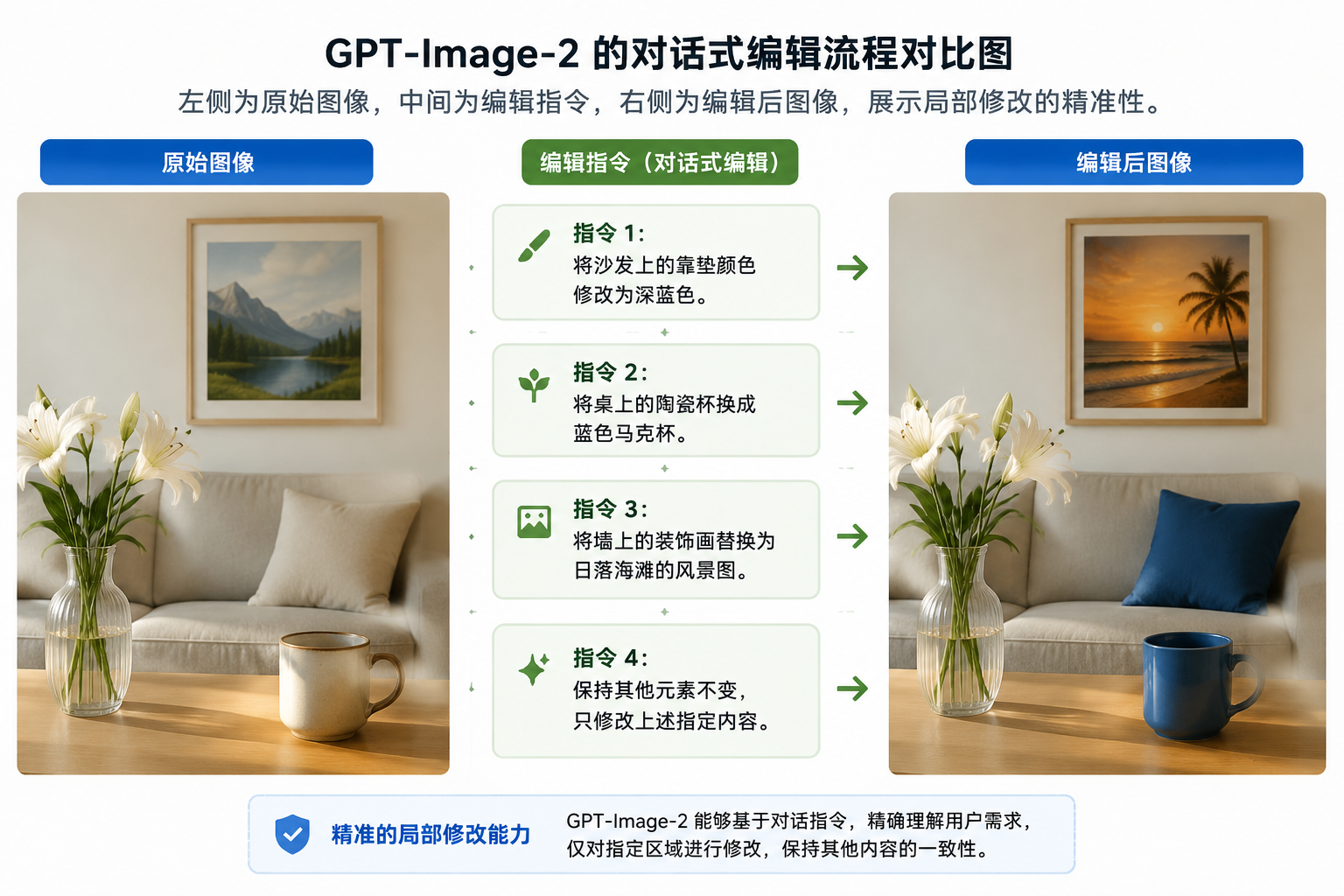
2.3 对话式精准编辑:自然语言改图
发现杯子放错位置了?不需要去拉遮罩(Mask)。只需要对它说:“把咖啡杯移到桌子左边”,或者“把天空的色调改成日落的暗橘色”。模型会在保持全图一致性的前提下,像一个听话的修图师一样完成局部修改。
GPT-Image-2运行于连续上下文环境中,支持多轮自然语言交互,用户可逐步细化需求、局部修改对象属性。核心原则是:每一轮都显式复述哪些元素必须保持不变,以减少漂移。
2.4 多图一致性:批量生产的利器
对于商业设计而言,风格的一致性至关重要。GPT-Image-2支持:
- 一次请求生成最多8张连贯图片,保持角色、光影和风格的惊人一致性
- 最多4张输入图像进行风格迁移、虚拟试穿、角色一致性保持
在实测中,上传一张自拍,要求生成“同一人物在不同夏日场景下的穿搭”,8张图中人物的面部特征、发型甚至配饰都保持了高度统一。这种能力对于制作品牌物料套系(Logo、名片、海报统一风格)具有极高的商业价值。
三、商用场景实测:从“灵感工具”到“工业化生产力”
3.1 电商营销:海报批量生成
OpenAI发布页展示了中文、日文、韩文、阿拉伯文等多语种样例,明确标注gpt-image-2具备“reliable text rendering with crisp lettering, consistent layout”。
在实测中,要求生成一张3:4竖版国潮咖啡新品上市海报,包含品牌名“山川茶事”、价格“中杯18元、大杯22元”、活动“第二杯半价”等近20处文字信息——模型一次性完成,版式松弛、层级清楚、留白舒服,中间咖啡杯的冰块、液体、奶泡、金箔细节都像一张真正拿来投放的饮品海报。
工程化价值:传统的电商海报出图流程——设计框架→跑图→修文字→调排版→多平台适配,单张耗时数小时。GPT-Image-2将这个过程压缩到几分钟,且二次修图率≈0%。

3.2 UI/产品设计:从原型到效果图
在UI设计场景中,GPT-Image-2能够从手绘草图直接生成高保真设计稿。实测“生成一个浅色模式的Dashboard界面”时,模型不仅还原了布局,甚至连按钮上的微小文字和图标都清晰可辨。
更进一步的用法是:先把原型丢给AI,让它辅助整理视觉描述,再通过GPT-Image-2出效果图,用较低成本快速看到多种可能性。这大幅缩短了从概念到可评审设计稿的周期。
3.3 多语言出海:全球化视觉营销
随着出海业务的深入,跨语言全球化的视觉营销成为刚需。GPT-Image-2在多语言渲染方面的表现,为企业出海提供了强大的技术支撑。
不同于以往需要设计师手动调整各语种的排版,该模型能够自动识别不同字符的视觉重心,并根据语种特征调整布局。例如生成面向东南亚市场的促销海报时,模型不仅能生成符合当地审美偏好的场景,还能准确地将泰语或越南语融入设计中,字体风格与背景完美契合。
四、开发者API接入指南
4.1 环境准备
pip install openai>=1.75.0
4.2 基础文生图
from openai import OpenAI
client = OpenAI(api_key="your-api-key")
result = client.images.generate(
model="gpt-image-1", # 注意:API端点仍为gpt-image-1
prompt="品牌名'慢时光咖啡',主标题'春日限定'用宋体,副标题'全场8折',竖版3:4,暖色调",
size="1024x1024",
quality="high",
output_format="png",
n=1
)
import base64
image_data = base64.b64decode(result.data[0].b64_json)
with open("output.png", "wb") as f:
f.write(image_data)
关键参数说明:
quality:low(快速草稿)、medium、high(终稿)size:支持任意满足约束的尺寸,最大边长可到3840pxoutput_format:png支持透明背景- 定价参考:输入$5.00/百万token,输出$10.00/百万token
4.3 图像编辑
# 基于已有图像进行编辑
edited = client.images.edit(
model="gpt-image-1",
image=open("input.png", "rb"),
prompt="把天空的色调改成日落的暗橘色,保持其他所有元素不变",
n=1
)
编辑技巧:每一轮都显式复述哪些元素必须保持不变,以减少漂移。
五、工程化建议与注意事项
✅ 推荐应用场景
- 自动化营销素材生成:动态生成包含变量(价格、日期、人名)的批量海报
- 多语言本地化配图:同一视觉模板快速切换多语言版本
- UI设计稿快速迭代:从手绘草图到可评审设计稿
- 品牌物料批量生产:保持风格一致性的系列化内容
⚠️ 需要注意的技术边界
1. 推理延迟增加:自回归序列预测导致单图生成耗时相比扩散模型延长约20%-30%。建议用quality: "low"做快速草稿迭代,终稿才用high质量。
2. 生态隔离:无法兼容基于U-Net的ControlNet等插件,布局控制需依赖结构化Prompt。
3. 超小字体瑕疵:常规商用场景实现文字零错乱,仅超小密集字号场景存在细微瑕疵。建议避开8号以下超小字体。
4. 不支持透明PNG输出(当前版本),需注意输出格式限制。
5. 分层工作流:草稿在1K/2K,终稿才冲4K。4K+高速不是默认同时成立,而是要用分层工作流来换。
六、总结
GPT-Image-2最值得关注的,不是某一张图有多惊艳,而是它代表的一次范式转移:AI图像生成正在从“灵感玩具”变成“视觉操作系统”。
它解决了AI生图商用化的三个核心瓶颈:
- 文字渲染:99%准确率,商用场景二次修图率≈0%
- 推理驱动:先规划后生成,告别“提示词+祈祷”的抽卡循环
- 多图一致性:一次生成8张风格统一的图像,支撑品牌批量生产
那个“有图有真相”的时代,正在被正式画上句号。AI生图已经跨越了从“能用”到“可用”的门槛——它不再是“技术圈自嗨”,而是真正可以嵌入赚钱链的生产力工具。
一个务实的判断:GPT-Image-2不会让你不用设计师,但它会让你从“画图工”变成“视觉导演”——你不再需要用笔去画,但你需要用脑去判断什么是对的方向。

openEuler 是由开放原子开源基金会孵化的全场景开源操作系统项目,面向数字基础设施四大核心场景(服务器、云计算、边缘计算、嵌入式),全面支持 ARM、x86、RISC-V、loongArch、PowerPC、SW-64 等多样性计算架构
更多推荐
 1
1 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)