Prometheus + Grafana监控平台-显卡集群监控
工作中有需要监控大量算力卡的需求,所以进行Prometheus + Grafana监控平台的部署搭建:
一:首先需要部署nvidia的显卡监控工具DCGM Exporter,先安装docker服务,再拉取必要的镜像
docker pull nvcr.io/nvidia/k8s/dcgm-exporter:3.0.4-3.0.0-ubuntu20.04
docker pull prom/prometheus
docker pull grafana/grafana二:部署DCGM Exporter,我的服务器在内网,所以先将镜像文件导入docker服务
docker load -i dcgm-exporter.tar
sudo docker run --pid=host --privileged -e DCGM_EXPORTER_INTERVAL=60000 --gpus all --restart=always -d -p 9400:9400 --name dcgm-exporter nvcr.io/nvidia/k8s/dcgm-exporter:3.0.4-3.0.0-ubuntu20.04 直接启动可能会报错,could not select driver with capabilities[[gpu]],这是因为 Docker 容器运行时无法识别 GPU 设备,简单来说,Docker 本身不认识 --gpus all 这个参数,它需要 NVIDIA 提供的容器工具包来充当“翻译官”,所以还需要下载相关的依赖包,这里注意要下载与服务器操作系统版本相适配的rpm包版本,下载的版本过高可能会报其他的依赖错误导致安装失败
sudo yum install -y --downloadonly --downloaddir=./nvidia-con nvidia-container-toolkit-1.16.2-1 libnvidia-container-tools-1.16.2-1 libnvidia-container1-1.16.2-1
cd nvidia-con && rpm -ivh *.rpm现在再运行DCGM Exporter 容器后,容器启动正常
三:部署Prometheus,先将镜像导入内网服务器中
docker load -i prometheus.tar
mkdir -p /home/prometheus
cd /home/prometheus
cat > prometheus/prometheus.yml << 'EOF'
global:
scrape_interval: 15s # 数据采集间隔
scrape_configs:
# 1. 监控 Prometheus 自身
- job_name: 'prometheus'
static_configs:
- targets: ['localhost:9090']
# 2. 监控 NVIDIA GPU 数据 (刚刚部署的 dcgm-exporter)
- job_name: 'nvidia-gpu'
static_configs:
- targets: ['localhost:9400']
EOF创建 Docker Compose 启动文件 (docker-compose.yml)
cat > docker-compose.yml << 'EOF'
version: '2.2'
services:
prometheus:
image: prom/prometheus:latest
container_name: prometheus
restart: always
ports:
- "9090:9090"
volumes:
- ./prometheus/prometheus.yml:/etc/prometheus/prometheus.yml
- prometheus_data:/prometheus
command:
- '--config.file=/etc/prometheus/prometheus.yml'
- '--storage.tsdb.path=/prometheus'
- '--storage.tsdb.retention.time=30d' # 数据保留30天
- '--web.enable-lifecycle' # 支持配置热重载
volumes:
prometheus_data:
EOF
docker-compose up -d #启动容器查看容器运行状态,测试prometheus接口,查看prometheus服务页面


在浏览器中访问 http://<服务器IP>:9090,在顶部的查询框中输入 DCGM_FI_DEV_GPU_UTIL,如果能查到图表或数据,说明 Prometheus 已经成功对接了 GPU 监控
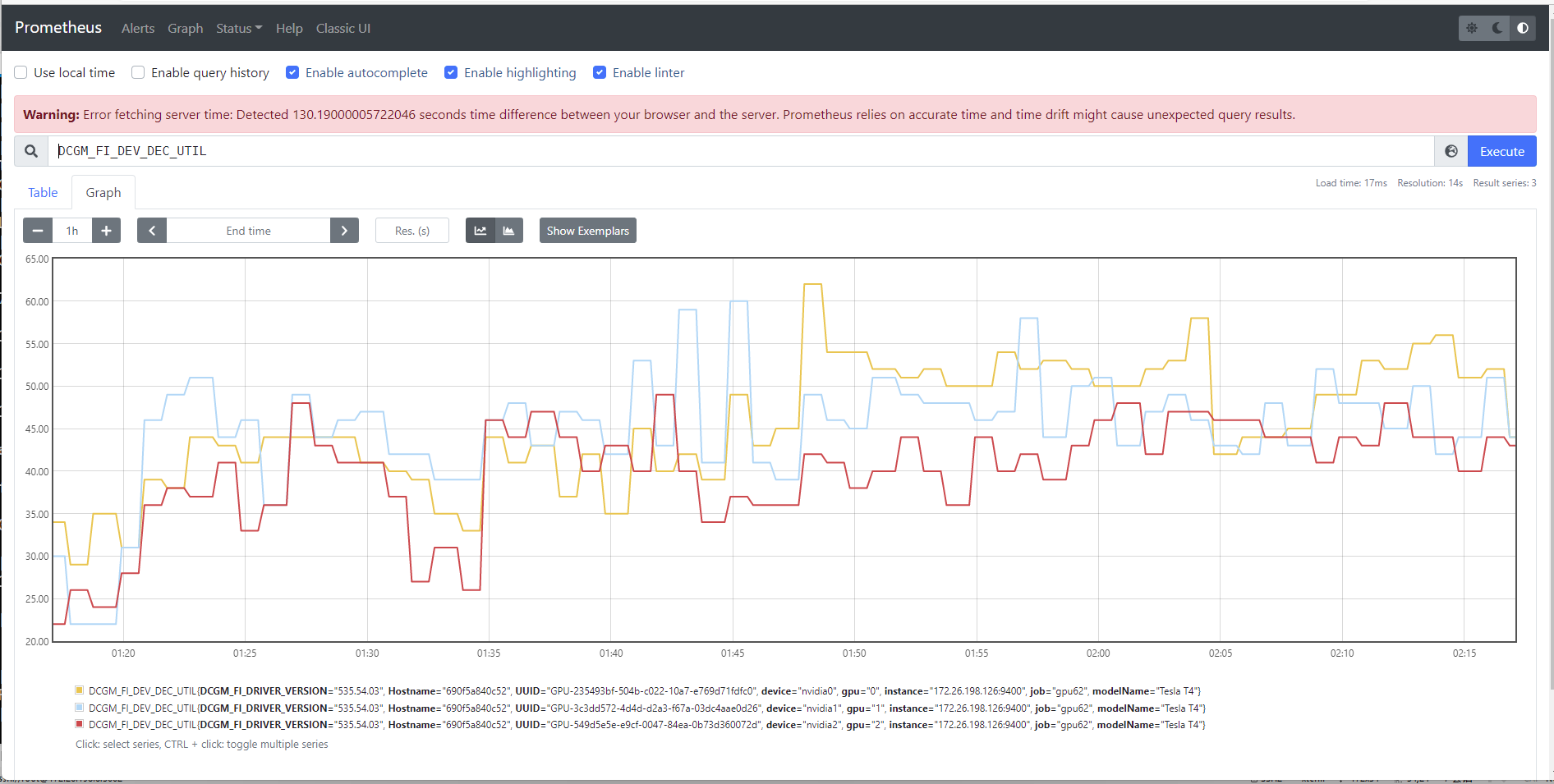
四 Grafana部署,首先导入镜像,创建应用目录
docker load -i grafana.tar
mkdir -p /home/grafana/{data,provisioning/datasources}
cd /home/grafana 创建 Docker Compose 文件 (docker-compose.yml)
version: '2.2'
services:
grafana:
image: grafana/grafana:latest
container_name: grafana
restart: always
ports:
- "3000:3000"
volumes:
- ./grafana/data:/var/lib/grafana # 数据持久化
- ./grafana/provisioning:/etc/grafana/provisioning # 自动配置数据源
environment:
- TZ=Asia/Shanghai # 设置时区
- GF_SECURITY_ADMIN_PASSWORD=admin123 # 初始化密码(建议修改)
user: "472" # 防止权限问题然后还需要将data目录的权限改为472,否则容器启动会报错,启动容器后可以看到系统也,页面
chown -R 472:472 /home/grafana/data 
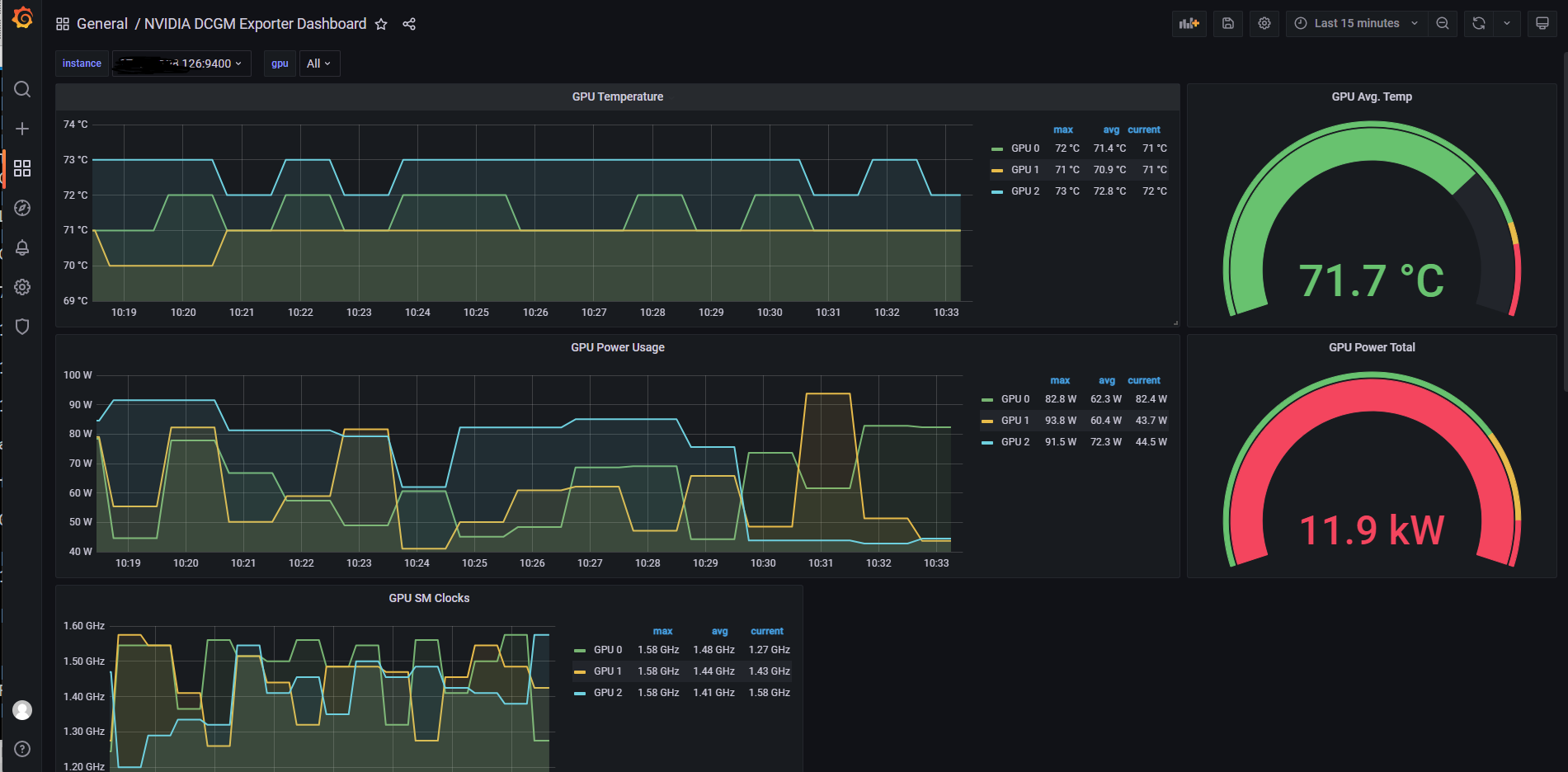
从NVIDIA DCGM Exporter Dashboard | Grafana Labs,下载监控模板文件,然后到内网平台上上传
选择Prometheus数据源,然后配置Prometheus的IP和端口,就可以查看显卡状态了

openEuler 是由开放原子开源基金会孵化的全场景开源操作系统项目,面向数字基础设施四大核心场景(服务器、云计算、边缘计算、嵌入式),全面支持 ARM、x86、RISC-V、loongArch、PowerPC、SW-64 等多样性计算架构
更多推荐
 4
4 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)