LV.10网络编程高级
1. web开发基本概念
1.1 万维网的基本工作原理
引入
思考:你是如何上网的?
什么是万维网?
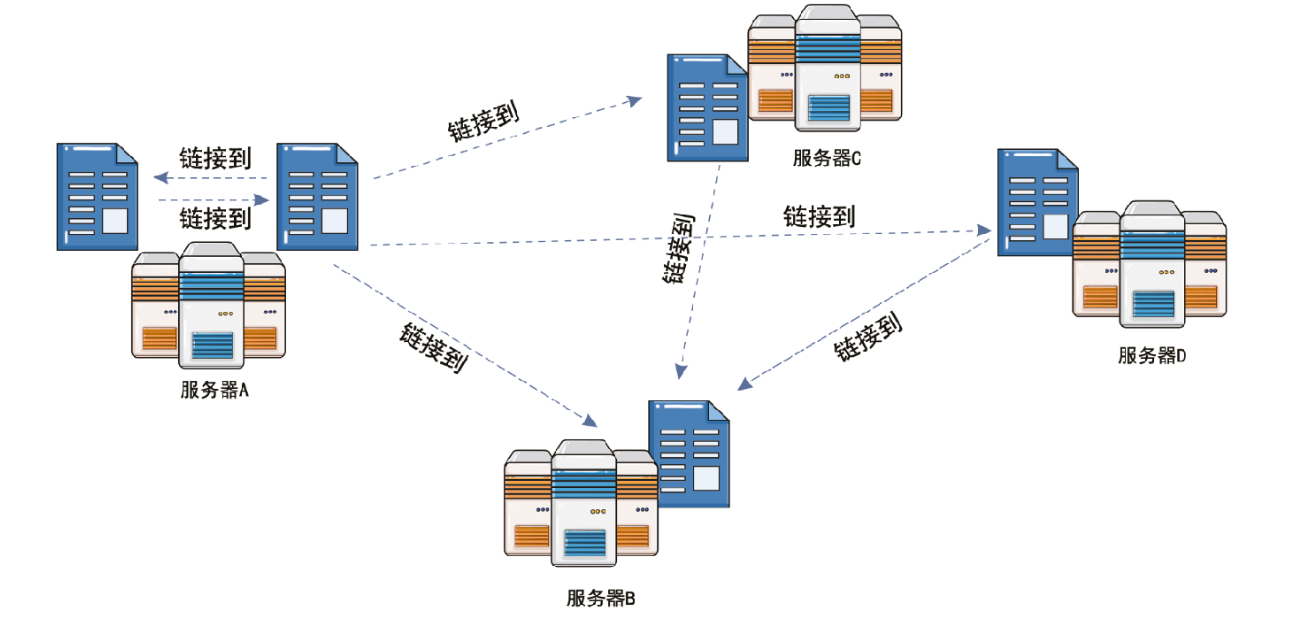
万维网的基本概念
万维网的特点
- 万维网(World Wide Web, 简称 WWW 或 Web)是一个大规模的、 联机式的信息储藏所
- 万维网是一个分布式的超媒体(hypermedia)系统, 它是超文本(hypertext)系统的扩充。
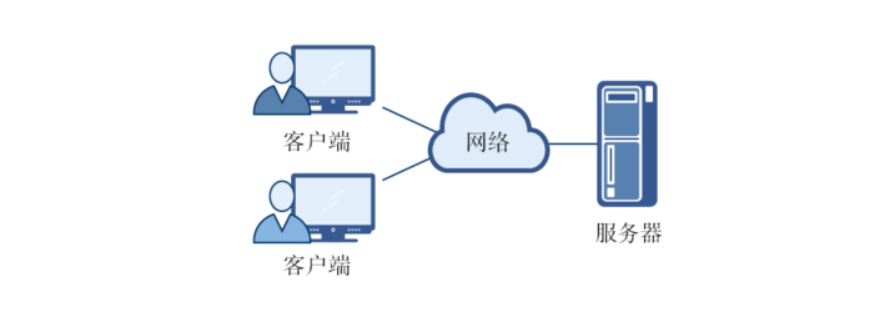
- 万维网以客户-服务器方式工作
什么是URL?
万维网使用统一资源定位符URL(Uniform Resource Locator)来标志万维网上的各种文档, 并使每一个文档在整个互联网的范围内具有唯一的标识符URL。
https://www.baidu.com.cn:443/index.html
语法规则:
scheme://host.domain:port/path/filename
- scheme - 定义因特网服务的类型。最常见的类型是
http - host - 定义域主机(
http的默认主机是www) - domain - 定义因特网域名,比如
makeru.com.cn - :port - 定义主机上的端口号(
http的默认端口号是80) - path - 定义服务器上的路径(如果省略,则文档必须位于网站的根目录中)。
- filename - 定义文档/资源的名称
常见的 URL Scheme:
| Scheme | 访问 | 用于… |
|---|---|---|
| http | 超文本传输协议 | 以 http:// 开头的普通网页。不加密。 |
| https | 安全超文本传输协议 | 安全网页,加密所有信息交换。 |
| ftp | 文件传输协议 | 用于将文件下载或上传至网站。 |
| file | 您计算机上的文件。 |
HTTP与HTTPS
**HTTP(超文本传输协议,Hypertext Transfer Protocol)**是一种用于从网络传输超文本到本地浏览器的传输协议。它定义了客户端与服务器之间请求和响应的格式。HTTP 工作在 TCP/IP 模型之上,通常使用端口 80。
**HTTPS(超文本传输安全协议,Hypertext Transfer Protocol Secure)**是 HTTP 的安全版本,它在 HTTP 下增加了 SSL/TLS 协议,提供了数据加密、完整性校验和身份验证。HTTPS 通常使用端口 443。

超文本标记语言HTML
超文本标记语言HTML (Hyper Text Markup Language)是一种标准化的标记语言,用于创建网页。
它提供了结构性和语义化的标记,使各种浏览器能够渲染不同作者创作的多种风格的文档。
HTML具备一定的灵活性,允许通过CSS(层叠样式表)来实现风格上的差异。
<html>
<body>
<h1 style="text-align:center;">My First Heading</h1>
<p>My first paragraph.</p>
</body>
</html>
万维网的基本工作原理
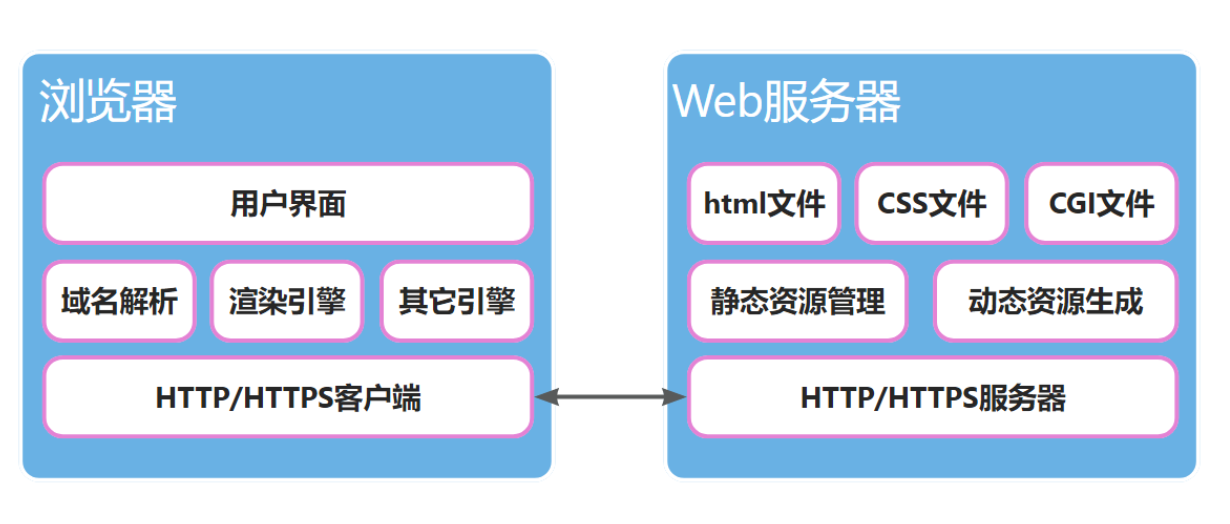
1.2 HTTP协议基本概念
什么是HTTP协议?
- HTTP(超文本传输协议,HyperText Transfer Protocol)是一种用于分布式、协作式、超媒体信息系统的应用层协议。
- HTTP 是万维网(WWW)的数据通信的基础,设计目的是确保客户端与服务器之间的通信,是互联网上最常用的协议之一。
- HTTP 是一个基于 TCP/IP 通信协议来传递数据的(HTML 文件、图片文件、查询结果等)。
- 设计 HTTP 最初的目的是为了提供一种发布和接收 HTML 页面的方法,通过 HTTP 或者 HTTPS 协议请求的资源由统一资源标识符(Uniform Resource Identifiers,URI)来标识。
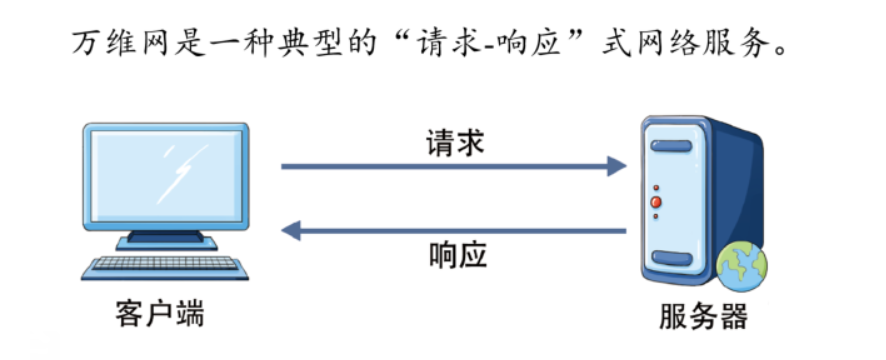
HTTP 的请求-响应
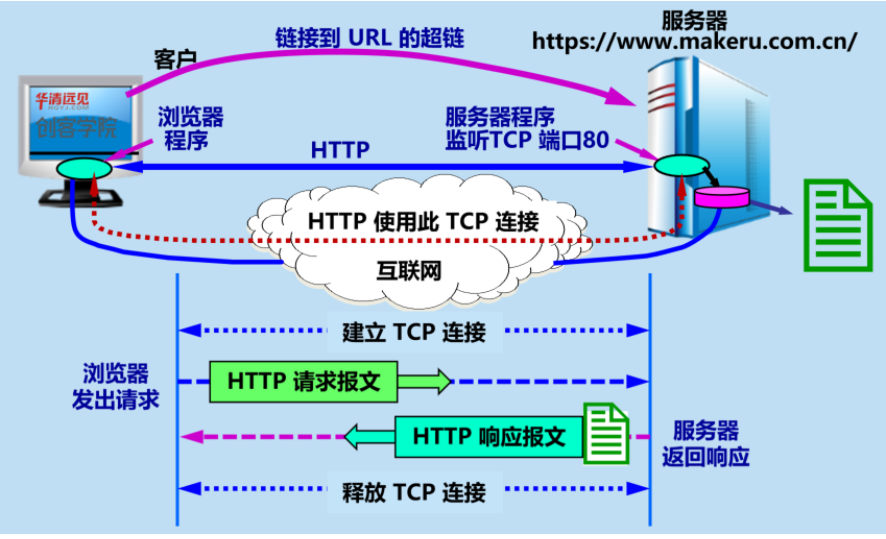
- 建立连接:客户端与服务器之间建立连接。在传统的 HTTP 中,这是基于 TCP/IP 协议的。最近的 HTTP/2 和 HTTP/3 则使用了更先进的传输层协议,例如基于 TCP 的二进制协议(HTTP/2)或基于 UDP 的 QUIC 协议(HTTP/3)。
- 发送请求:客户端向服务器发送请求,请求中包含要访问的资源的 URL、请求方法(GET、POST、PUT、DELETE 等)、请求头(例如,Accept、User-Agent)以及可选的请求体(对于 POST 或 PUT 请求)。
- 处理请求:服务器接收到请求后,根据请求中的信息找到相应的资源,执行相应的处理操作。这可能涉及从数据库中检索数据、生成动态内容或者简单地返回静态文件。
- 发送响应:服务器将处理后的结果封装在响应中,并将其发送回客户端。响应包含状态码(用于指示请求的成功或失败)、响应头(例如,Content-Type、Content-Length)以及可选的响应体(例如,HTML 页面、图像数据)。
- 关闭连接:在完成请求-响应周期后,客户端和服务器之间的连接可以被关闭,除非使用了持久连接(如 HTTP/1.1 中的 keep-alive)。
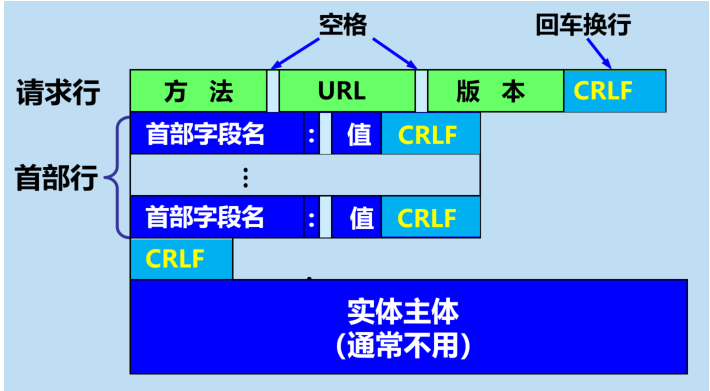
客户端请求消息
客户端发送一个HTTP请求到服务器的请求消息包括以下格式:请求行(request line)、请求头部(header)、空行和请求数据四个部分组成,下图给出了请求报文的一般格式。
示例:
GET / HTTP/1.1
User-Agent: curl/7.16.3 libcurl/7.16.3 OpenSSL/0.9.7l zlib/1.2.3
Host: www.example.com
Accept-Language: en, mi
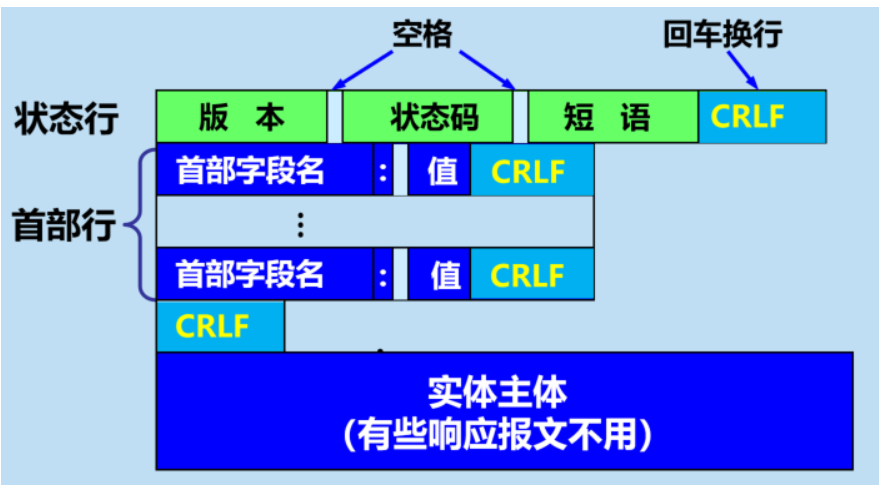
服务器响应消息
HTTP 响应也由四个部分组成,分别是:状态行、消息报头、空行和响应正文。
示例:
HTTP/1.1 200 OK
Date: Mon, 27 Jul 2009 12:28:53 GMT
Server: Apache
Last-Modified: Wed, 22 Jul 2009 19:15:56 GMT
ETag: "34aa387-d-1568eb00"
Accept-Ranges: bytes
Content-Length: 143
Vary: Accept-Encoding
Content-Type: text/plain
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<title>创客学院(makeru.com.cn)</title>
</head>
<body>
<h1>这是一个html</h1>
</body>
</html>
HTTP 请求方法
| 序号 | 方法 | 描述 |
|---|---|---|
| 1 | GET | 从服务器获取资源。用于请求数据而不对数据进行更改。例如,从服务器获取网页、图片等。 |
| 2 | POST | 向服务器发送数据以创建新资源。常用于提交表单数据或上传文件。发送的数据包含在请求体中。 |
| 3 | PUT | 向服务器发送数据以更新现有资源。如果资源不存在,则创建新的资源。与 POST 不同,PUT 通常是幂等的,即多次执行相同的 PUT 请求不会产生不同的结果。 |
| 4 | DELETE | 从服务器删除指定的资源。请求中包含要删除的资源标识符。 |
| 5 | PATCH | 对资源进行部分修改。与 PUT 类似,但 PATCH 只更改部分数据而不是替换整个资源。 |
| 6 | HEAD | 类似于 GET,但服务器只返回响应的头部,不返回实际数据。用于检查资源的元数据(例如,检查资源是否存在,查看响应的头部信息)。 |
| 7 | OPTIONS | 返回服务器支持的 HTTP 方法。用于检查服务器支持哪些请求方法,通常用于跨域资源共享(CORS)的预检请求。 |
| 8 | TRACE | 回显服务器收到的请求,主要用于诊断。客户端可以查看请求在服务器中的处理路径。 |
| 9 | CONNECT | 建立一个到服务器的隧道,通常用于 HTTPS 连接。客户端可以通过该隧道发送加密的数据。 |
HTTP 状态码
状态码分类
HTTP 状态码由三个十进制数字组成,第一个十进制数字定义了状态码的类型。响应分为五类:信息响应(100–199),成功响应(200–299),重定向(300–399),客户端错误(400–499)和服务器错误 (500–599):
| 分类 | 分类描述 |
|---|---|
| 1** | 信息,服务器收到请求,需要请求者继续执行操作 |
| 2** | 成功,操作被成功接收并处理 |
| 3** | 重定向,需要进一步的操作以完成请求 |
| 4** | 客户端错误,请求包含语法错误或无法完成请求 |
| 5** | 服务器错误,服务器在处理请求的过程中发生了错误 |
HTTP状态码列表
| 状态码 | 状态码英文名称 | 中文描述 |
|---|---|---|
| 100 | Continue | 继续。客户端应继续其请求 |
| 101 | Switching Protocols | 切换协议。服务器根据客户端的请求切换协议。只能切换到更高级的协议,例如,切换到HTTP的新版本协议 |
| 200 | OK | 请求成功。一般用于GET与POST请求 |
| 201 | Created | 已创建。成功请求并创建了新的资源 |
| 202 | Accepted | 已接受。已经接受请求,但未处理完成 |
| 203 | Non-Authoritative Information | 非授权信息。请求成功。但返回的meta信息不在原始的服务器,而是一个副本 |
| 204 | No Content | 无内容。服务器成功处理,但未返回内容。在未更新网页的情况下,可确保浏览器继续显示当前文档 |
| 205 | Reset Content | 重置内容。服务器处理成功,用户终端(例如:浏览器)应重置文档视图。可通过此返回码清除浏览器的表单域 |
| 206 | Partial Content | 部分内容。服务器成功处理了部分GET请求 |
| 300 | Multiple Choices | 多种选择。请求的资源可包括多个位置,相应可返回一个资源特征与地址的列表用于用户终端(例如:浏览器)选择 |
| 301 | Moved Permanently | 永久移动。请求的资源已被永久的移动到新URI,返回信息会包括新的URI,浏览器会自动定向到新URI。今后任何新的请求都应使用新的URI代替 |
| 302 | Found | 临时移动。与301类似。但资源只是临时被移动。客户端应继续使用原有URI |
| 303 | See Other | 查看其它地址。与301类似。使用GET和POST请求查看 |
| 304 | Not Modified | 未修改。所请求的资源未修改,服务器返回此状态码时,不会返回任何资源。客户端通常会缓存访问过的资源,通过提供一个头信息指出客户端希望只返回在指定日期之后修改的资源 |
| 305 | Use Proxy | 使用代理。所请求的资源必须通过代理访问 |
| 306 | Unused | 已经被废弃的HTTP状态码 |
| 307 | Temporary Redirect | 临时重定向。与302类似。使用GET请求重定向 |
| 400 | Bad Request | 客户端请求的语法错误,服务器无法理解 |
| 401 | Unauthorized | 请求要求用户的身份认证 |
| 402 | Payment Required | 保留,将来使用 |
| 403 | Forbidden | 服务器理解请求客户端的请求,但是拒绝执行此请求 |
| 404 | Not Found | 服务器无法根据客户端的请求找到资源(网页)。通过此代码,网站设计人员可设置"您所请求的资源无法找到"的个性页面 |
| 405 | Method Not Allowed | 客户端请求中的方法被禁止 |
| 406 | Not Acceptable | 服务器无法根据客户端请求的内容特性完成请求 |
| 407 | Proxy Authentication Required | 请求要求代理的身份认证,与401类似,但请求者应当使用代理进行授权 |
| 408 | Request Time-out | 服务器等待客户端发送的请求时间过长,超时 |
| 409 | Conflict | 服务器完成客户端的 PUT 请求时可能返回此代码,服务器处理请求时发生了冲突 |
| 410 | Gone | 客户端请求的资源已经不存在。410不同于404,如果资源以前有现在被永久删除了可使用410代码,网站设计人员可通过301代码指定资源的新位置 |
| 411 | Length Required | 服务器无法处理客户端发送的不带Content-Length的请求信息 |
| 412 | Precondition Failed | 客户端请求信息的先决条件错误 |
| 413 | Request Entity Too Large | 由于请求的实体过大,服务器无法处理,因此拒绝请求。为防止客户端的连续请求,服务器可能会关闭连接。如果只是服务器暂时无法处理,则会包含一个Retry-After的响应信息 |
| 414 | Request-URI Too Large | 请求的URI过长(URI通常为网址),服务器无法处理 |
| 415 | Unsupported Media Type | 服务器无法处理请求附带的媒体格式 |
| 416 | Requested range not satisfiable | 客户端请求的范围无效 |
| 417 | Expectation Failed(预期失败) | 服务器无法满足请求头中 Expect 字段指定的预期行为。 |
| 418 | I’m a teapot | 状态码 418 实际上是一个愚人节玩笑。它在 RFC 2324 中定义,该 RFC 是一个关于超文本咖啡壶控制协议(HTCPCP)的笑话文件。在这个笑话中,418 状态码是作为一个玩笑加入到 HTTP 协议中的。 |
| 500 | Internal Server Error | 服务器内部错误,无法完成请求 |
| 501 | Not Implemented | 服务器不支持请求的功能,无法完成请求 |
| 502 | Bad Gateway | 作为网关或者代理工作的服务器尝试执行请求时,从远程服务器接收到了一个无效的响应 |
| 503 | Service Unavailable | 由于超载或系统维护,服务器暂时的无法处理客户端的请求。延时的长度可包含在服务器的Retry-After头信息中 |
| 504 | Gateway Time-out | 充当网关或代理的服务器,未及时从远端服务器获取请求 |
| 505 | HTTP Version not supported | 服务器不支持请求的HTTP协议的版本,无法完成处理 |
1.3 问题
HTTP/1.1中支持持久连接的机制是?
A. QUIC协议
B. Keep-Alive
C. 二进制分帧
D. 多路复用
HTTP/1.1:默认长连接 Keep-Alive
A QUIC协议:HTTP/3 使用
C 二进制分帧:HTTP/2 特性
D 多路复用:HTTP/2 的核心特性
2 wireshark分析GET方法
2.1 安装Web服务器
- 更新系统
在安装任何软件之前,先确保系统是最新的:
sudo apt update
sudo apt upgrade
- 安装Apache Web服务器
Apache是一个流行的开源Web服务器。你可以通过以下命令安装它:
sudo apt install apache2
安装完成后,Apache将自动启动。可以通过访问http://localhost查看默认的Apache欢迎页面。
- 检查Apache状态
你可以使用以下命令检查Apache是否正在运行:
sudo systemctl status apache2
- 测试服务器
打开浏览器,输入http://<your-server-ip-address>,如果看到Apache默认页面,说明服务器搭建成功。 - 重启Apache
在更改配置后,需要重启Apache服务器:
sudo systemctl restart apache2
如何使用
配置文件:/etc/apache2
html页面文件:/var/www/html/
3 HTTP协议是怎样实现的
3.1 编写套接字框架
第一步:实现socket通信
系统调用都要处理错误判断
#include <sys/socket.h>//man tcp
#include <netinet/in.h>
#include <netinet/tcp.h>
#include <arpa/inet.h>
#include <stdio.h>
int main(int argc, const char *argv[])
{
// 创建一个套接字
int fd = socket(AF_INET, SOCK_STREAM, 0);
if(fd < 0) {
perror("socket"); // 如果套接字创建失败,输出错误信息
return -1;
}
//man 7 IP
// 定义 sockaddr_in 结构体以指定绑定地址
struct sockaddr_in addr = {
.sin_family = AF_INET, // 使用 IPv4
.sin_port = htons(8080), // 指定端口号 8080
.sin_addr.s_addr = INADDR_ANY // 绑定到所有可用的网络界面
};
// 将套接字绑定到指定地址和端口
if(bind(fd, (struct sockaddr *)&addr, sizeof(addr)) ) {
perror("bind"); // 如果绑定失败,输出错误信息
return -2;
}
// 使套接字进入监听状态,最多接受 5 个未处理的连接请求
if(listen(fd, 5) ) {
perror("listen"); // 如果监听失败,输出错误信息
return -3;
}
// 接受客户端连接请求
int cfd = accept(fd, NULL, NULL); // 接受连接请求
if(cfd < 0) {
perror("accept");
return -4;
}
while(1) {
char buf[BUFSIZ] = {}; // 定义一个缓冲区,用于存放接收到的数据
int r = recv(cfd, buf, BUFSIZ, 0); // 接收来自客户端的数据
if(r < 0) {
perror("recv"); // 如果接收失败,输出错误信息
return -5;
} else if(r == 0) {
break; // 如果接收到的数据长度为 0,则说明客户端已关闭连接,退出循环
} else {
printf("%s\n", buf); // 打印接收到的数据
}
}
// 关闭客户端和服务器套接字写入通道
shutdown(cfd, SHUT_WR); // 关闭客户端套接字的写通道
shutdown(fd, SHUT_WR); // 关闭服务器套接字的写通道
return 0;
}
3.2 模拟实现web服务器GET响应
test.c
#include <sys/socket.h>
#include <netinet/in.h>
#include <netinet/tcp.h>
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <fcntl.h>
#include <sys/stat.h>
#include <unistd.h>
#include <time.h>
//判断文件后缀
char *get_extension(char *filename) {
char *dot = strrchr(filename, '.');
if(!dot || dot == filename) {
return "html";
}
return dot+1;
}
//获取系统时间
char *get_time(char *time_str, int len) {
time_t rawtime;
struct tm *timeinfo;
// 获取当前的 UTC 时间
time(&rawtime);
timeinfo = gmtime(&rawtime);
// 格式化时间字符串
strftime(time_str, len, "Date: %a, %d %b %Y %H:%M:%S GMT", timeinfo);
return time_str;
}
//发送数据
ssize_t send_data(int fd, const void *buf) {
int ret = send(fd, buf, strlen(buf), 0);
if(ret < 0) {
perror("send");
exit(EXIT_FAILURE);
}
return ret;
}
//响应get请求
int do_get(int fd, char *buf, size_t len) {
char type[16] = {};
char resource[16] = {};
char head[1024] = {};
char *pathname = NULL;
int ret = sscanf(buf, "%s%s\n", type, resource);
if(ret != 2) {
char *head = "HTTP/1.1 400 Bad Request\r\n\r\n";
return send_data(fd, head);
}
printf("type = %s resource = %s\n", type, resource);
if(strncasecmp("GET", type, 3) ) {
char *head = "HTTP/1.1 501 Not Implemented\r\n\r\n";
return send_data(fd, head);
}
if( strlen(resource) == 1 && resource[0] == '/') {
pathname = "index.html";
} else {
pathname = &resource[1];
}
FILE *fp = fopen(pathname, "r");
if(fp == NULL ){
char *head = "HTTP/1.1 404 Not Found\r\n\r\n";
return send_data(fd, head);
}
fread(buf, 1, len, fp);
char time[100] = {};
sprintf(head, "HTTP/1.1 200 OK\r\n"
"%s\r\n"
"Content-Length: %ld\r\n"
"Connection: Keep-Alive\r\n"
"Content-Type: text/%s;charset=UTF-8\r\n\r\n",
get_time(time, 100), strlen(buf) , get_extension(pathname) );
printf("send %s %s", head, buf);
send_data(fd, head);
return send_data(fd, buf);
}
int main(int argc, const char *argv[])
{
int fd = socket(AF_INET, SOCK_STREAM, 0);
if(fd == -1){
perror("socket");
exit(0);
}
struct sockaddr_in addr={
.sin_family = AF_INET,
.sin_port = htons(8080),
.sin_addr.s_addr = INADDR_ANY
};
if(bind(fd, (struct sockaddr *)&addr, sizeof(addr))){
perror("bind");
exit(0);
}
if(listen(fd, 5)){
perror("listen");
exit(0);
}
while(1){
int newFd = accept(fd, NULL, NULL);
if(newFd == -1){
perror("accept");
exit(0);
}
while(1){
char buf[BUFSIZ] = {};
int ret = recv(newFd, buf, BUFSIZ,0);
if(ret == -1){
perror("recv");
exit(0);
}else if(ret == 0){
close(newFd);
break;
}else{
printf("%s", buf);
do_get(newFd, buf, BUFSIZ);
}
}
}
close(fd);
return 0;
}
<!DOCTYPE html>
<html lang="zh-CN">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>登录</title>
<link rel="stylesheet" type="text/css" href="styles.css">
</head>
<body>
<div class="container">
<h2>登录页面</h2>
<form action="/cgi-bin/login.cgi" method="get">
<input type="text" name="username" placeholder="请输入用户名"><br>
<input type="password" name="password" placeholder="请输入密码"><br>
<input type="submit" value="Login">
</form>
<a href="/register.html">注册</a>
</div>
</body>
</html>
body {
font-family: Arial, sans-serif;
background-color: #11999e;
display: flex;
justify-content: center;
align-items: center;
height: 100vh;
margin: 0;
}
.container {
background-color: #e4f9f5;
padding: 20px;
border-radius: 8px;
box-shadow: 0 0 10px rgba(0, 0, 0, 0.1);
width: 300px;
}
.container h2 {
text-align: center;
margin-top: 0;
margin-bottom: 20px;
color: #333;
}
.container input[type="text"],
.container input[type="password"] {
width: 100%;
padding: 10px;
margin-bottom: 15px;
border: 1px solid #ddd;
border-radius: 4px;
box-sizing: border-box;
}.container input[type="submit"] {
width: 100%;
padding: 10px;
background-color: #1ab189;
padding: 10px;
margin-top: 10px;
border: none;
border-radius: 4px;
color: #ffffff;
font-size: 16px;
cursor: pointer;
}
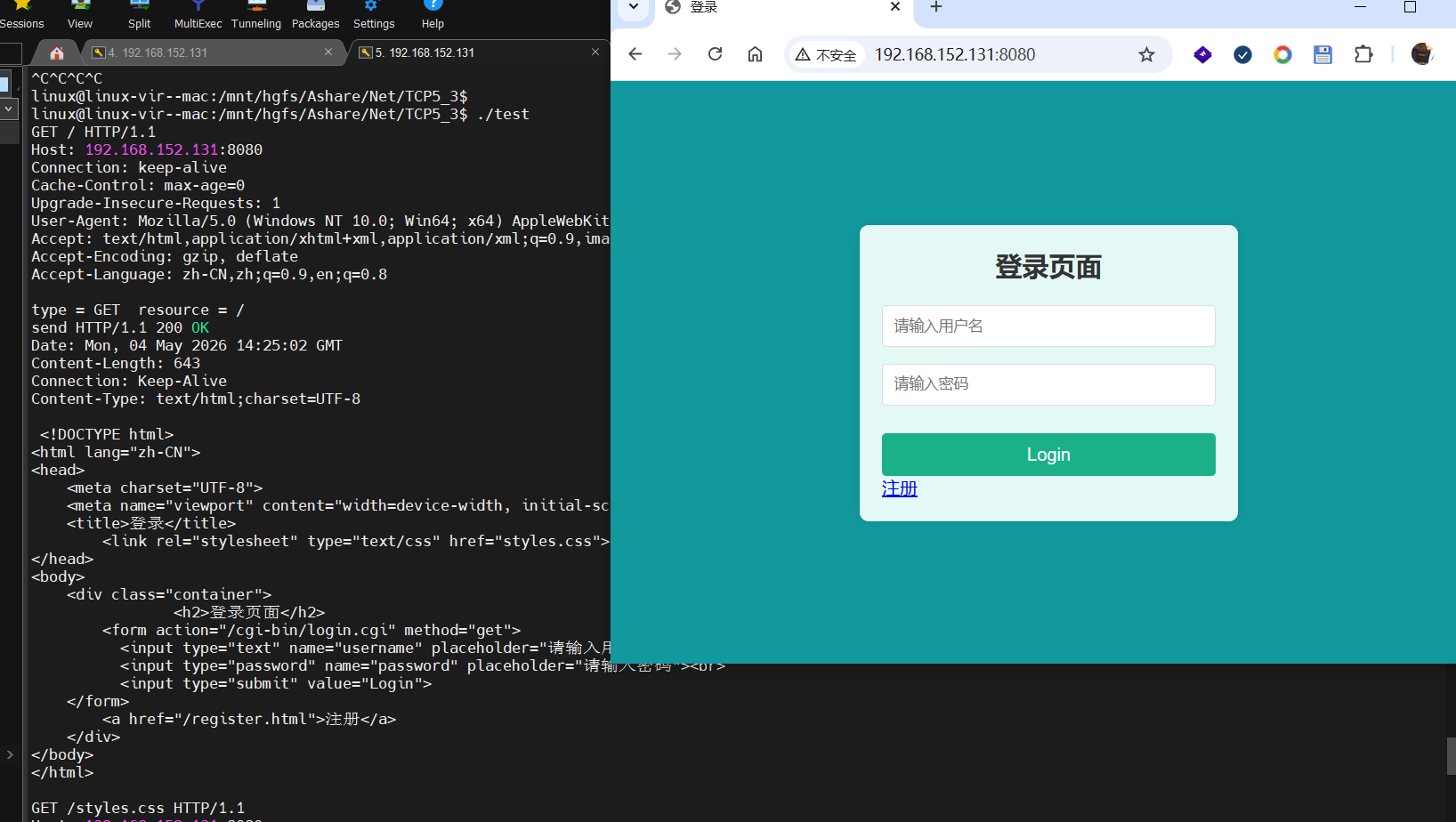
4 静态页面到动态页面
4.1 html的主要概念
从标签到元素
<开头,>结尾,就是一个标签,例:
<H1>
HTML的常见标签,及其含义:
HTML(超文本标记语言)使用各种标签来定义网页的内容结构。以下是一些常见的HTML标签及其含义:
<html>:定义HTML文档的根元素,包含整个页面的内容。<head>:包含元信息(如编码、样式、脚本引用、页面标题等),不会在页面上直接显示。<title>:定义网页的标题,通常显示在浏览器的标签页上。<body>:包含网页的主体内容,所有可见的页面内容都放在这个标签内。<h1>** - **<h6>:定义标题,<h1>是最高级别的标题,<h6>是最低级别的。<p>:定义段落。<a>:定义一个超链接,href属性指定链接的目标URL。<table>:定义表格。<tr>:定义表格中的行,用于<table>中。<td>:定义表格中的单元格,用于<tr>中。<th>:定义表格中的表头单元格。
…
一对标签加上中间的内容就组成了一个元素,例:
<H1>abcde</H1>
但也有一些元素是单个出现的,被称之为空元素。例:
<br>
表示换行
从元素到属性
元素是HTML的基本单位,每个元素都可以指定一些属性,例如<a>表示一个超级链接,就是通过属性指定链接的:
<a href="https://www.baidu.com/">链接文本</a>
很明显,除这种必不可少的属性外,也有一些其它常见的标签属性:
| 属性 | 描述 |
|---|---|
| class | 给元素指定一个或多个类名,方便通过 CSS 或 JavaScript 操作 |
| id | 给元素一个唯一的标识符,可以用于 CSS 选择器或 JavaScript 操作 |
| style | 直接为元素定义 CSS 样式。 |
| title | 提供关于元素的额外信息,通常在鼠标悬停时显示。 |
从属性到样式
- 内联样式
当特殊的样式需要应用到个别元素时,就可以使用内联样式。 使用内联样式的方法是在相关的标签中使用样式属性。样式属性可以包含任何 CSS 属性。以下实例显示出如何改变段落的颜色和左外边距。
<p style="color:blue;margin-left:20px;">这是一个段落。</p>
- 内部样式表
当单个文件需要特别样式时,就可以使用内部样式表。你可以在 部分通过
<head>
<style type="text/css">
body {background-color:yellow;}
p {color:blue;}
</style>
</head>
- 外部样式表
当样式需要被应用到很多页面的时候,外部样式表将是理想的选择。使用外部样式表,你就可以通过更改一个文件来改变整个站点的外观。
<head>
<link rel="stylesheet" type="text/css" href="mystyle.css">
</head>
html相关学习资料
html示例代码:
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<title>我的html页面</title>
</head>
<body>
<h1>我的第一个标题</h1>
<p>我的第一个段落。</p>
</body>
</html>
html语言标准官方文档:
html教程:
使用 HTML 构建 Web - 学习 Web 开发 | MDN (mozilla.org)
国内的优秀网站:
HTML 教程 | 菜鸟教程 (runoob.com)
4.2 从静态页面到动态页面
引入
思考:怎样将传感器数据显示到web页面?
- 读取传感器数据
- 显示到
html页面 - 刷新
html页面
如何读取传感器数据?
以读取鼠标的坐标信息为例,鼠标的设备文件是/dev/input/mouse0:
sudo xxd /dev/input/mouse0
执行以上命令可以看到鼠标这个设备输出的原始数据
怎样把数据显示到html页面?
思路:
- 作为标记语言
html是无法读取硬件信息的,但C语言可以实现一个html页面 - 传感器数据的数据是动态变化的,
html页面是静止的,可以让浏览器每一秒刷新一次页面。
C语言实现一个html页面
#include <stdio.h>
#include <fcntl.h>
#include <unistd.h>
#include <errno.h>
#include <string.h>
#define MOUSE_DEVICE "/dev/input/mouse0"
int main() {
FILE *file;
int fd;
int data = 0;
// 打开鼠标设备文件
fd = open(MOUSE_DEVICE, O_RDONLY);
if (fd == -1) {
perror("open");
return errno;
}
// 确保文件描述符是非阻塞的
int flags = fcntl(fd, F_GETFL, 0);
if (flags == -1) {
perror("fcntl F_GETFL");
close(fd);
return errno;
}
if (fcntl(fd, F_SETFL, flags | O_NONBLOCK) == -1) {
perror("fcntl F_SETFL");
close(fd);
return errno;
}
while(1) {
// 打开文件以写入模式
file = fopen("/var/www/html/index.html", "w");
// 检查文件是否成功打开
if (file == NULL) {
printf("无法创建文件\n");
return 1;
}
// 写入HTML文件的基本结构和内容
fprintf(file, "<!DOCTYPE html>\n");
fprintf(file, "<html>\n");
fprintf(file, "<head>\n");
fprintf(file, " <meta charset=\"utf-8\">\n");
fprintf(file, " <title>鼠标的原始数据</title>\n");
//自动刷新获取数据
fprintf(file, " <meta http-equiv=\"refresh\" content=\"1\">");
fprintf(file, "</head>\n");
fprintf(file, "<body>\n");
read(fd, &data, 4);
printf("%#x\n", data);
fprintf(file, " <p>%#x</p>\n", data);
fprintf(file, "</body>\n");
fprintf(file, "</html>\n");
// 关闭文件
fclose(file);
sleep(1);
}
return 0;
}
可以继续尝试以下实验:
- 用C语言+输出重定向创建一个html文件
36,48s/fprintf(file, /printf(
while(1) {
// 写入HTML文件的基本结构和内容
printf( "<!DOCTYPE html>\n");
printf( "<html>\n");
printf( "<head>\n");
printf( " <meta charset=\"utf-8\">\n");
printf( " <title>鼠标的原始数据</title>\n");
//自动刷新获取数据
printf( " <meta http-equiv=\"refresh\" content=\"1\">");
printf( "</head>\n");
printf( "<body>\n");
read(fd, &data, 4);
printf("%#x\n", data);
printf( " <p>%#x</p>\n", data);
printf( "</body>\n");
printf( "</html>\n");
sleep(1);
}
./test > /var/www/html/index.html
2. 用C语言+管道生成一个html文件,以下面的命令为例:
./test | cat > var/www/html/index.html
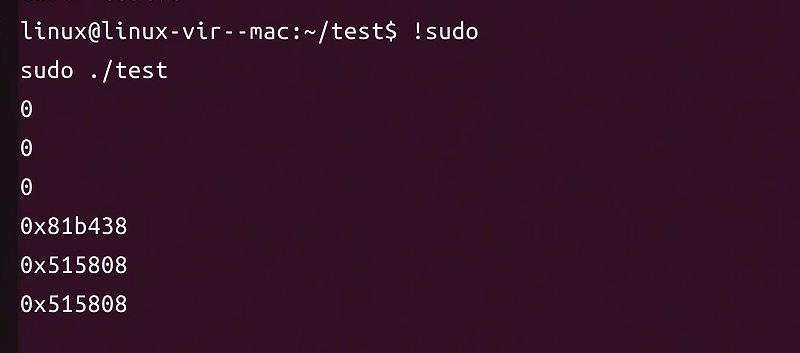
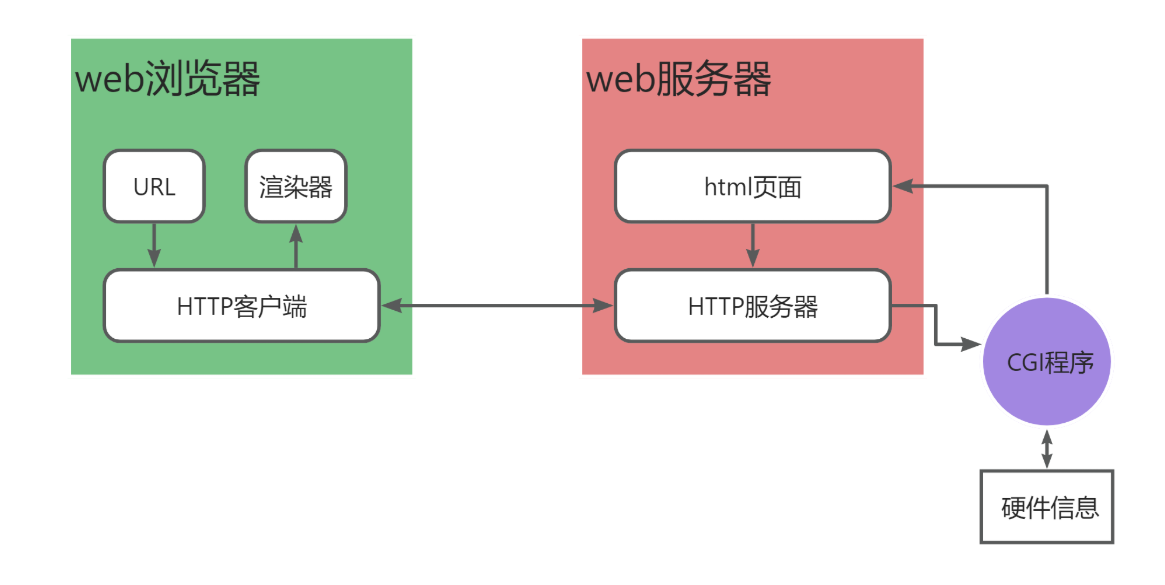
5 CGI
5.1 什么是CGI?
让 Web 服务器 可以调用 外部程序 来处理客户端请求,并把程序的输出结果返回给浏览器。
CGI 全称为 Common Gateway Interface,是一种标准协议,定义了Web服务器与外部应用程序(通常是执行脚本或程序)之间的交互方式。其主要作用是在Web服务器和生成动态内容的应用程序之间传递信息。
当用户在Web浏览器中请求一个CGI程序时,Web服务器会将请求传递给相应的CGI脚本。脚本执行完成后,将结果返回给服务器,服务器再将结果传给用户的浏览器。CGI脚本可以用多种编程语言编写,如Perl、Python、C、或者Shell脚本。
cgi接口的引入
sudo a2enmod cgi
sudo systemctl restart apache2
sudo cp test /usr/lib/cgi-bin/
#include <stdio.h>
int main(int argc, char *argv[]) {
printf("Content-Type: text/html\n\n");
printf("<!DOCTYPE html>\n");
printf("<html> <head> <meta charset=\"utf-8\">\n");
printf("<title>我的html页面</title> </head> <body>\n");
printf("<h1>第一个标题</h1>\n");
printf("<p>我的第一个段落。</p>\n");
printf("</body> </html> \n");
return 0;
}
使用shell脚本实现cgi程序
#!/bin/bash
echo "Content-Type: text/html"
echo ""
echo "<!DOCTYPE html>"
echo "<html> <head> <meta charset=\"utf-8\">"
echo "<title>html页面</title> </head> <body>"
echo "<h1>标题</h1>"
echo "<p>我的第一个段落</p>"
echo "</body> </html>"
CGI的特点:
对http浏览器来说,cgi脚本文件只是一个页面文件。
CGI可以使用任意编程语言编写,只要这个语言能把数据输出到标准输出即可。
CGI是一个标准,它规定了系统所必须具备的环境变量
CGI相关文档
CGI标准官方文档:
RFC 3875 - The Common Gateway Interface (CGI) Version 1.1 (ietf.org)
CGI教程:
C++ Web 编程 | 菜鸟教程 (runoob.com)
Python CGI 编程 | 菜鸟教程 (runoob.com)
Perl CGI编程 | 菜鸟教程 (runoob.com)
CGI环境变量
| 变量名 | 描述 |
|---|---|
| CONTENT_TYPE | 内容的数据类型。当客户端向服务器发送附加内容时使用。例如,文件上传等功能。 |
| CONTENT_LENGTH | 查询的信息长度。只对 POST 请求可用。 |
| HTTP_COOKIE | 以键 & 值对的形式返回设置的 cookies。 |
| HTTP_USER_AGENT | 用户代理请求标头字段,递交用户发起请求的有关信息,包含了浏览器的名称、版本和其他平台性的附加信息。 |
| PATH_INFO | CGI 脚本的路径。 |
| QUERY_STRING | 通过 GET 方法发送请求时的 URL 编码信息,包含 URL 中问号后面的参数。 |
| REMOTE_ADDR | 发出请求的远程主机的 IP 地址。这在日志记录和认证时是非常有用的。 |
| REMOTE_HOST | 发出请求的主机的完全限定名称。如果此信息不可用,则可以用 REMOTE_ADDR 来获取 IP 地址。 |
| REQUEST_METHOD | 用于发出请求的方法。最常见的方法是 GET 和 POST。 |
| SCRIPT_FILENAME | CGI 脚本的完整路径。 |
| SCRIPT_NAME | CGI 脚本的名称。 |
| SERVER_NAME | 服务器的主机名或 IP 地址。 |
| SERVER_SOFTWARE | 服务器上运行的软件的名称和版本。 |
获取鼠标数据打印到网页
#include <stdio.h>
#include <fcntl.h>
#include <unistd.h>
#include <errno.h>
#include <string.h>
#define MOUSE_DEVICE "/dev/input/mouse0"
int main() {
FILE *file;
int fd;
int data = 0;
// 打开鼠标设备文件
fd = open(MOUSE_DEVICE, O_RDONLY);
if (fd == -1) {
perror("open");
return errno;
}
// 确保文件描述符是非阻塞的
int flags = fcntl(fd, F_GETFL, 0);
if (flags == -1) {
perror("fcntl F_GETFL");
close(fd);
return errno;
}
if (fcntl(fd, F_SETFL, flags | O_NONBLOCK) == -1) {
perror("fcntl F_SETFL");
close(fd);
return errno;
}
printf("Content-Type: text/html\n\n");
// 写入HTML文件的基本结构和内容
printf("<!DOCTYPE html>\n");
printf("<html>\n");
printf("<head>\n");
printf(" <meta charset=\"utf-8\">\n");
printf(" <title>鼠标的原始数据</title>\n");
//自动刷新获取数据
printf(" <meta http-equiv=\"refresh\" content=\"1\">");
printf("</head>\n");
printf("<body>\n");
read(fd, &data, 4);
printf("%#x\n", data);
printf(" <p>%#x</p>\n", data);
printf("</body>\n");
printf("</html>\n");
sleep(1);
return 0;
}
5.2 CGI程序处理form表单
思考:怎样完成用户登录的功能?
html只是静态页面,无法动态的处理这种问题。需要依靠其它具备逻辑控制能力的语言来完这项工作- 处理用户登录功能的语言需要获取必要的数据
认识form表单
<form action="/cgi-bin/login.cgi" method="get">
<input type="text" name="username" placeholder="请输入用户名"><br>
<input type="password" name="password" placeholder="请输入密码"><br>
<input type="submit" value="Login">
</form>
-
action="/cgi-bin/login.cgi": 这个属性指定了当用户提交表单时,表单数据将被发送到服务器上的/cgi-bin/login.cgi文件进行处理。 -
method="get": 这个属性指定了表单数据的提交方式。 -
type="submit": 定义了一个提交按钮,当用户点击这个按钮时,表单数据将被发送到服务器。
CGI程序处理form表单
/*cgi 通过环境变量 获取信息 */
#include <stdio.h>
#include <stdlib.h>
/*cgi 通过环境变量 从wen获取信息 */
int main(void) {
char *data = getenv("QUERY_STRING");
char username[50], password[50];
// data :username=lpy&password=1234
//%49[^&]:表示从当前位置读取最多 49 个字符,直到遇到 &
sscanf(data, "username=%49[^&]&password=%49s", username, password);
//由于告诉浏览器,将发送html的文本页面
printf("Content-Type: text/html\n\n");
//登录成功以后的显示内容
printf("<h1>Login successful! Welcome, %s!</h1>", username);
return 0;
}
运行前需要让http服务器支持CGI功能:
sudo a2enmod cgi
sudo systemctl restart apache2
编译
gcc login.c -o login.cgi -Wall
把编写好的应用程序复制到/usr/lib/cgi-bin/目录下:
sudo cp login.cgi /usr/lib/cgi-bin/
打开浏览器进行测试
思考:如果把login.cgi改成login程序还能正常运行吗?
.cgi是为了表示这是个CGI程序,和其它可执行程序是一样的,没有特殊的属性。
去掉.cgi的后缀不影响其功能,但文件名需要和form表单当中的文件名一致。例如:
- 把
form表单当中的/cgi-bin/login.cgi改为/cgi-bin/login, - 把
/usr/lib/cgi-bin/下的login.cgi改为login,
再次进行测试…
5.3 从GET到POST
GET的缺点
get的请求信息会直接展示在URL当中
POST如何获取表单数据?
#include <stdio.h>
#include <stdlib.h>
int main(int argc, char *argv[]) {
printf("Content-Type: text/html\n\n");
printf("<!DOCTYPE html>\n");
printf("<html> <head> <meta charset=\"utf-8\">\n");
printf("<title>我的html页面</title> </head> <body>\n");
printf("<h1>请求方式:REQUEST_METHOD:%s</h1>\n", getenv("REQUEST_METHOD"));
printf("<p>CONTENT_LENGTH:%s</p>\n", getenv("CONTENT_LENGTH"));
printf("<p>CONTENT_TYPE:%s</p>\n", getenv("CONTENT_TYPE"));
char buf[1024] = {};
scanf("%s", buf);
printf("<p>but:%s</p>\n", buf);
printf("</body> </html> \n");
return 0;
}
关于HTTP当中的内容类型
常见的媒体格式类型如下:
- text/html : HTML格式
- text/plain :纯文本格式
- text/xml : XML格式
- image/gif :gif图片格式
- image/jpeg :jpg图片格式
- image/png:png图片格式
以application开头的媒体格式类型:
- application/xhtml+xml :XHTML格式
- application/xml: XML数据格式
- application/atom+xml :Atom XML聚合格式
- application/json: JSON数据格式
- application/pdf:pdf格式
- application/msword : Word文档格式
- application/octet-stream : 二进制流数据(如常见的文件下载)
- application/x-www-form-urlencoded : 中默认的encType,form表单数据被编码为key/value格式发送到服务器(表单默认的提交数据的格式)
另外一种常见的媒体格式是上传文件之时使用的:
- multipart/form-data : 需要在表单中进行文件上传时,就需要使用该格式
最终代码:
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
int main(int argc, char *argv[]) {
printf("Content-Type: text/html\n\n");
printf("<!DOCTYPE html>\n");
printf("<html> <head> <meta charset=\"utf-8\">\n");
printf("<title>我的html页面</title> </head> <body>\n");
if(strncasecmp("POST", getenv("REQUEST_METHOD"), 4) == 0 &&
atoi(getenv("CONTENT_LENGTH") ) > 0) {
printf("<h1>请求方式是POST类型</h1>\n");
printf("<p>%s</p>\n", getenv("CONTENT_LENGTH"));
} else {
printf("<h1>请求方式为空</h1>\n");
return -1;
}
char *content_type = "application/x-www-form-urlencoded";
if(strncasecmp(content_type, getenv("CONTENT_TYPE"), strlen(content_type) ) == 0) {
char username[50], password[50];
if( scanf("username=%49[^&]&password=%49s", username, password) != 2) {
printf("<h3>\"账号或密码错误!\"</h3>\n");
}
printf("<h1>欢迎【%s】登录本网站!</h1>", username);
}
printf("</body> </html> \n");
return 0;
}
6 CGI的下载和使用
6.1 复习总结
CGI与Web服务器
CGI与Web服务器的关系
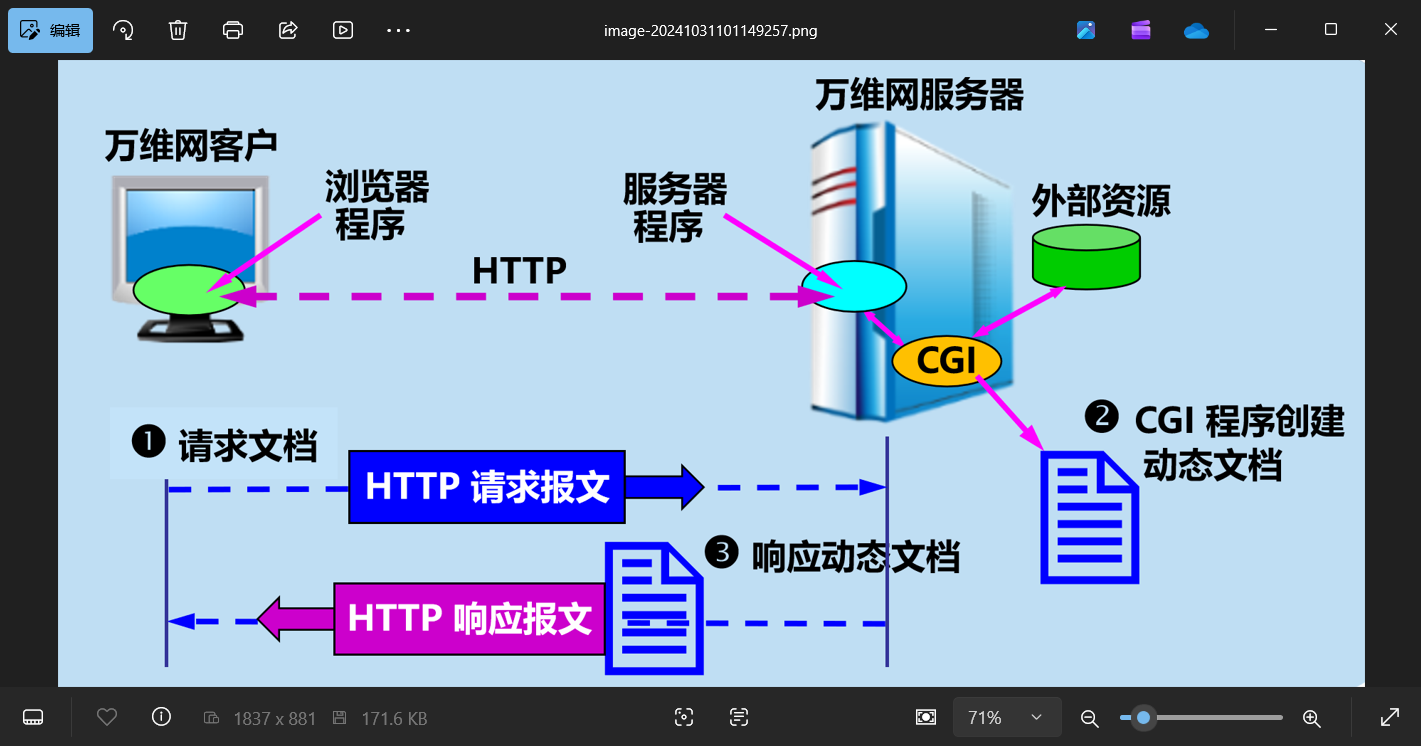
在HTTP请求与CGI脚本的交互中,CGI充当了Web服务器和外部应用程序之间的桥梁,使服务器能够生成动态内容并将其发送回客户端。以下是交互的详细过程:
HTTP请求与CGI脚本的交互过程
-
客户端发起请求
- 用户在浏览器中请求一个URL,这个URL指向一个CGI脚本。
- 该请求可以是GET请求或POST请求。
-
服务器接收到请求
- Web服务器(如Apache或Nginx)接收到HTTP请求后会检查请求的URL。
- 如果URL对应于CGI脚本的路径,服务器将识别需要启动CGI处理。
-
调度CGI脚本
- 服务器根据请求启动相应的CGI脚本作为新进程运行。
- 在启动脚本前,服务器设定环境变量,这些变量包含了请求的各种信息。
-
传递请求数据
- 环境变量: 服务器通过环境变量传递请求的元数据,如请求方法、查询字符串、内容类型等。例如:
REQUEST_METHOD: 请求方式(如GET、POST)QUERY_STRING: URL中的查询字符串CONTENT_TYPE: 请求体的数据类型(针对POST请求)
- 标准输入(stdin): 对于POST请求,请求体的数据通过标准输入传递给CGI脚本。
- 环境变量: 服务器通过环境变量传递请求的元数据,如请求方法、查询字符串、内容类型等。例如:
-
CGI脚本处理请求
- CGI脚本读取请求数据和环境变量,并进行相应的数据处理和逻辑操作。
- 脚本生成输出,包括HTTP头部和内容。常见的首个输出头是
Content-Type,告知响应数据的类型,例如Content-Type: text/html。
-
返回响应给服务器
- 脚本执行完成后,将输出发送回Web服务器。
- Web服务器将这一输出作为HTTP响应发送回客户端浏览器。
-
浏览器显示内容
- 客户端浏览器接收到响应后,解析并渲染网页内容供用户查看。
总结:
CGI的交互过程依赖于环境变量和标准输入输出,允许服务器动态生成内容处理复杂的用户请求。
CGI编程
C语言实现的CGI脚本的基本结构
使用C语言编写CGI脚本与其他语言有些不同,因为C语言通常需要手动处理输入、输出以及内存管理等。以下是一个简单的C语言CGI脚本的基本结构:
-
环境设置:
- CGI脚本通常位于
/cgi-bin/目录中,确保你的Web服务器能够执行它。 - 脚本的文件权限需正确设置,通常需要对执行者可执行(例如,
chmod 755 script.cgi)。
- CGI脚本通常位于
-
编写C代码:
- 开头包括必要的头文件:
#include <stdio.h> #include <stdlib.h>
- 开头包括必要的头文件:
-
输出HTTP头部:
- CGI脚本必须首先输出HTTP头部,并以一个空行结束。
printf("Content-Type: text/html\n\n"); -
处理输入数据:
- 一般使用
GET或POST方法传递数据。 - 使用环境变量如
QUERY_STRING来获取GET方法传递的参数,或者从标准输入读取POST方法的内容。
例子中处理
GET请求的查询字符串:char *query = getenv("QUERY_STRING"); if (query != NULL) { printf("<p>Query string: %s</p>\n", query); } - 一般使用
-
生成HTML内容:
- 输出HTML内容即可,例如:
printf("<html>\n"); printf("<head><title>CGI Script in C</title></head>\n"); printf("<body>\n"); printf("<h1>Hello, CGI in C!</h1>\n"); printf("</body>\n"); printf("</html>\n"); -
处理
POST方法输入:- 读取
CONTENT_LENGTH环境变量确定输入数据的长度,然后使用fgets或fread从标准输入读取数据。
char *content_length = getenv("CONTENT_LENGTH"); int len = content_length ? atoi(content_length) : 0; if (len > 0) { char *post_data = malloc(len+1); // +1 for null-terminator fread(post_data, 1, len, stdin); post_data[len] = '\0'; printf("<p>Post data: %s</p>\n", post_data); free(post_data); } - 读取
完整简单的CGI脚本可能如下:
#include <stdio.h>
#include <stdlib.h>
int main(void) {
// 输出HTTP头部
printf("Content-Type: text/html\n\n");
// 输出HTML页面开始
printf("<html>\n");
printf("<head><title>CGI Script in C</title></head>\n");
printf("<body>\n");
// 示例欢迎信息
printf("<h1>Welcome to CGI with C</h1>\n");
// 处理GET请求参数
char *query = getenv("QUERY_STRING");
if (query != NULL) {
printf("<p>Query string: %s</p>\n", query);
}
// 处理POST请求数据
char *content_length = getenv("CONTENT_LENGTH");
int len = content_length ? atoi(content_length) : 0;
if (len > 0) {
char *post_data = malloc(len + 1);
fread(post_data, 1, len, stdin);
post_data[len] = '\0';
printf("<p>Post data: %s</p>\n", post_data);
free(post_data);
}
// 输出HTML页面结束
printf("</body>\n");
printf("</html>\n");
return 0;
}
CGI编程当中的常见错误的处理与调试
在CGI编程中,处理和调试常见错误是开发过程中非常重要的环节。以下是一些关键技术和步骤,可以帮助你更有效地处理和调试CGI程序中的错误:
- 检查服务器日志:
- 查看Web服务器的错误日志(如Apache的
error.log),可以找到详细的错误信息。日志文件通常能提供具体的错误描述和发生错误的行号。
- 查看Web服务器的错误日志(如Apache的
- 正确设置HTTP头:
- 确保输出正确的HTTP头。例如,输出内容为HTML时,应该以
Content-type: text/html\r\n\r\n开头。如果头信息错误,浏览器可能无法正确解析响应内容。
- 确保输出正确的HTTP头。例如,输出内容为HTML时,应该以
- 使用标准错误输出:
- 将调试信息输出到标准错误(stderr),这样它会被记录到服务器的错误日志中,而不干扰程序的正常输出。
- 权限问题:
- 检查CGI脚本的文件和目录权限。确保Web服务器有足够的权限运行CGI脚本。
- 本地测试:
- 在部署到生产环境之前,先在本地环境中运行和测试CGI脚本,确保其在独立条件下正常运行。
6.2 cgi库的下载与使用
关于CGIC库
CGIC 是一个用于开发 CGI(Common Gateway Interface)程序的 C 库,CGIC 库简化了 CGI 程序的开发,处理诸如表单数据解析和环境变量管理等常见任务。
以下是一些 CGIC 库的功能和特点:
-
GET 和 POST 解析:CGIC 可以自动解析从客户端发送的 GET 和 POST 请求数据,并将数据存储为键值对,方便开发者获取和使用。
-
文件上传:支持处理多部分表单数据(multipart/form-data),使处理文件上传更为轻松。
-
错误处理:提供了一些机制来处理输入数据可能引起的错误,比如数据缺失或格式错误。
-
简化环境变量管理:CGIC 提供了一些函数来获取常用的 CGI 环境变量,如
CONTENT_TYPE、REQUEST_METHOD、QUERY_STRING等。 -
跨平台支持:CGIC 是用标准 C 语言编写的,能够在多种操作系统上使用,如 Unix/Linux 和 Windows。
CGIC库的下载:
https://github.com/boutell/cgic
阅读cgic库的帮助文档:cgic.html
构建cgic应用程序
- 准备好源码:
#include <stdio.h>
#include <string.h>
#include <stdlib.h>
#include "cgic.h"
int cgiMain() {
// 输出 HTTP 响应头
cgiHeaderContentType("text/html");
// 输出 HTML 头部
fprintf(cgiOut, "<!DOCTYPE html>\n");
fprintf(cgiOut, "<html>\n<head>\n<meta charset=\"utf-8\">\n");
fprintf(cgiOut, "<title>我的html页面</title>\n</head>\n<body>\n");
// 检查请求方法是否为 POST
char username[50];
char password[50];
// 获取表单数据
if (cgiFormString("username", username, sizeof(username)) != cgiFormSuccess) {
strcpy(username, "未知用户");
}
if (cgiFormString("password", password, sizeof(password)) != cgiFormSuccess) {
strcpy(password, "未知密码");
}
fprintf(cgiOut, "<h1>登录成功,欢迎 %s!</h1>\n", username);
// 输出 HTML 结束标签
fprintf(cgiOut, "</body>\n</html>\n");
return 0;
}
- 修改cgic库的Makefile或替换cgitest.c文件。以下是添加了注释的Makefile文件内容:
# 编译选项,使用 -g 进行调试信息生成,-Wall 打开所有警告信息
CFLAGS=-g -Wall
# 指定 C 编译器
CC=gcc
# 指定创建静态库的工具
AR=ar
# 指定静态库索引工具
RANLIB=ranlib
# 指定链接器选项,这里找到当前目录下的库,链接 cgic 库
LIBS=-L./ -lcgic
# 默认目标。生成 libcgic.a 静态库、cgictest.cgi 可执行文件和 capture 可执行文件
all: libcgic.a cgictest.cgi capture
# 安装目标。将 libcgic.a 复制到 /usr/local/lib,将 cgic.h 复制到 /usr/local/include
install: libcgic.a
cp libcgic.a /usr/local/lib
cp cgic.h /usr/local/include
@echo libcgic.a is in /usr/local/lib. cgic.h is in /usr/local/include.
# 静态库目标。生成 cgic.o 对象文件并创建 libcgic.a 静态库
libcgic.a: cgic.o cgic.h
rm -f libcgic.a
$(AR) rc libcgic.a cgic.o
$(RANLIB) libcgic.a
# 适用于 mingw32 和 cygwin 用户,将生成的可执行文件更改为 .exe 扩展名
# 可执行文件目标 cgictest.cgi,确保链接 libcgic.a 静态库
cgictest.cgi: cgictest.o libcgic.a
gcc cgictest.o -o cgictest.cgi ${LIBS}
# 可执行文件目标 capture,确保链接 libcgic.a 静态库
capture: capture.o libcgic.a
gcc capture.o -o capture ${LIBS}
# 清理目标。删除所有生成的对象文件、静态库和可执行文件
clean:
rm -f *.o *.a cgictest.cgi capture cgicunittest
# 测试目标。编译并运行单元测试程序
test:
gcc -D UNIT_TEST=1 cgic.c -o cgicunittest
./cgicunittest
CGI存在的问题与解决方案
CGI(Common Gateway Interface)在Web开发中曾经是一种常用的技术,但随着现代Web开发技术的进步,它的一些问题也逐渐显露出来。以下是CGI存在的一些主要问题及其解决方案:
-
性能问题:
- 问题:CGI每次处理请求时都会启动一个新的进程,这对于服务器来说开销非常大,尤其是在高并发环境下,容易导致性能下降。
- 解决方案:使用持久连接技术,如FastCGI或SCGI,这些技术通过重用进程来处理多个请求,从而提高性能。
-
安全问题:
- 问题:不安全的CGI脚本可能导致安全漏洞,比如缓冲区溢出和代码注入。
- 解决方案:编写安全的脚本,进行输入验证和参数化查询;使用现代Web框架,这些框架通常提供了更多内置的安全功能。
-
可扩展性问题:
- 问题:由于CGI的性能限制,在大规模应用中难以扩展。
- 解决方案:使用更现代的Web应用架构,如采用反向代理、负载均衡,并结合使用Web应用服务器如Node.js、Django、Flask等。
-
维护性和开发效率问题:
- 问题:CGI脚本通常直接用C或者Perl编写,代码复杂且不易维护。
- 解决方案:采用现代编程语言和框架,如Python的Flask、Java的Spring等,它们提供了更高的开发效率和可维护性。

openEuler 是由开放原子开源基金会孵化的全场景开源操作系统项目,面向数字基础设施四大核心场景(服务器、云计算、边缘计算、嵌入式),全面支持 ARM、x86、RISC-V、loongArch、PowerPC、SW-64 等多样性计算架构
更多推荐



 6
6 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)