数据库知识点总结
数据库基础
什么是数据库?
数据库(Database)就是专门存储数据的仓库。
例如学生信息:
| id | name | age |
|---|---|---|
| 1 | 张三 | 20 |
| 2 | 李四 | 21 |
常见的数据库
- MySQL(最常见)
-
SQL Server
什么是 C/S 和 B/S?
C/S(Client/Server)客户端/服务器模式
用户需要安装客户端才能访问。
例如:
- 王者荣耀
结构:
客户端
↓
服务器
↓
数据库B/S(Browser/Server)浏览器/服务器模式
用户直接通过浏览器访问
例如:
- 淘宝网页版
- 学校教务系统
结构:
浏览器
↓
Web服务器
↓
数据库数据库操作
创建数据库
create database school;
查看数据库
show databases;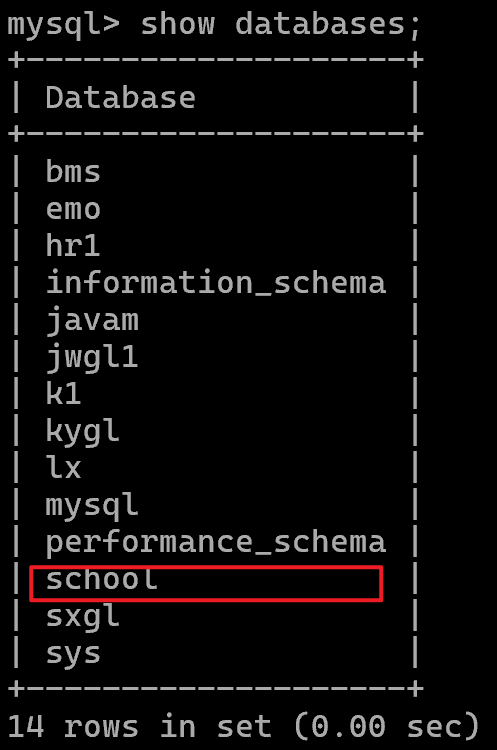
进入数据库
use school;
删除数据库
drop database school;
常用数据类型
数字类型
整数类型:int
age int定点小数类型
- decimal:钱、金额、账单、工资必须用decimal
salary decimal(10,2)
10:金钱的总位数
2:小数部分其他小数类型
- 普通小数:温度、重量、单价(非钱款)→ float(4 字节,7 位有效)
- 超大数值、高精度实验统计 → double(8 字节,15 位有效)
字符串类型
varchar(50):表示最多存放50个字符
name VARCHAR(50)日期类型
date
例如:
birthday date;
结果:
2004-01-01
表的基本操作
创建表
create table student(,,,);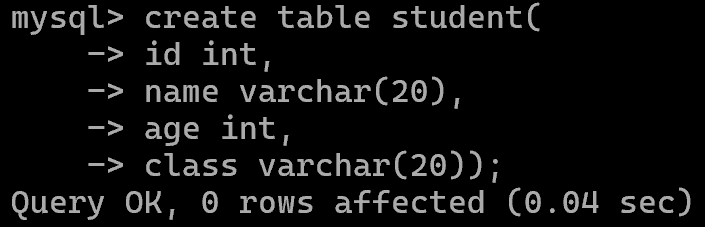
查看表
show tables;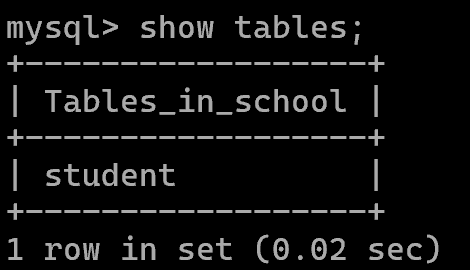
查看表结构
describe student;
或者desc student;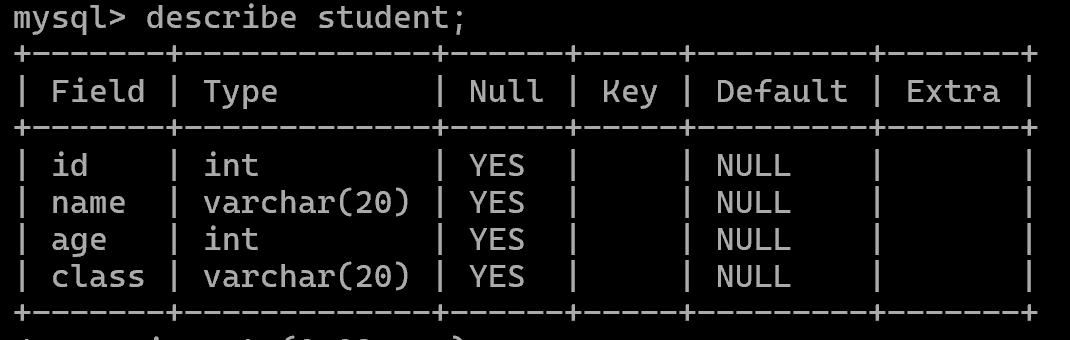
删除表
drop table stu;
增删改查(重点)
增(Insert)
增加一条数据:

增加多条数据:
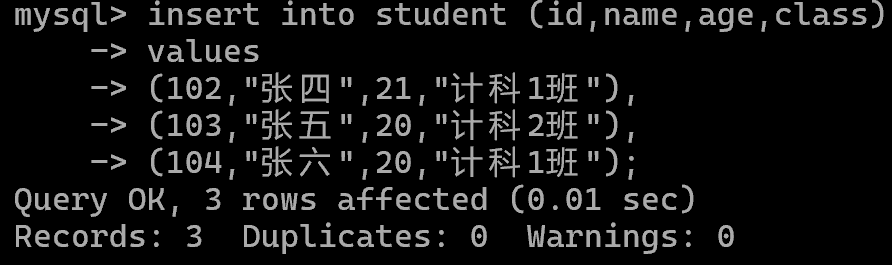
查(Select)
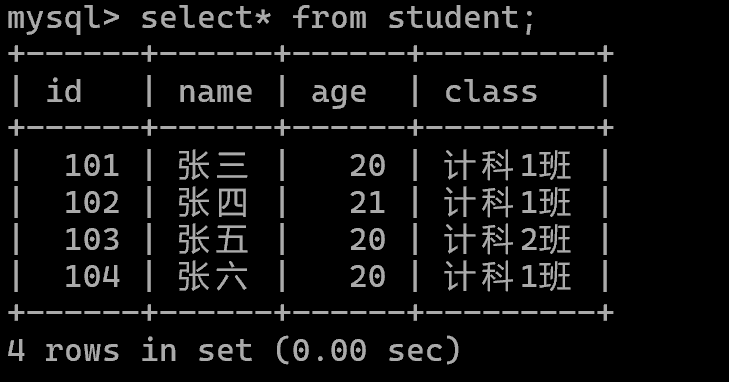
查询全部:
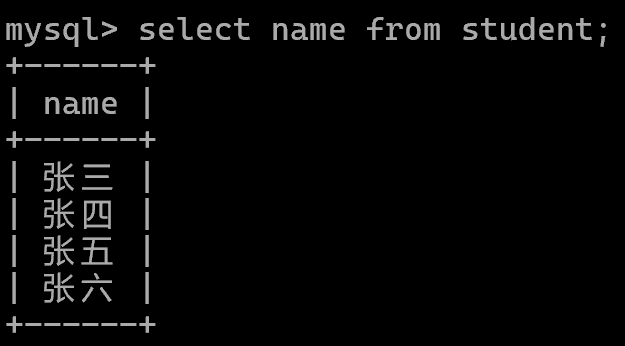
查询部分:
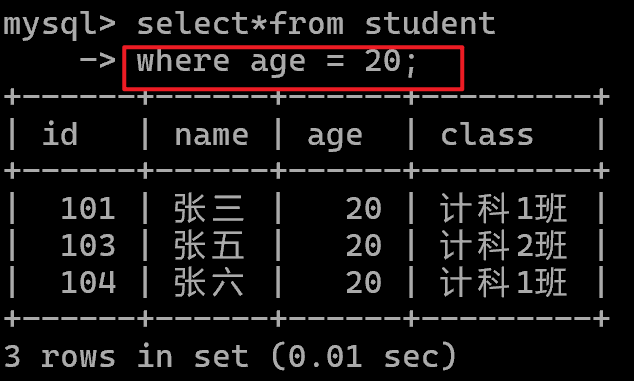
按条件查询where
例如:在student表中查询年龄=20的所有数据。
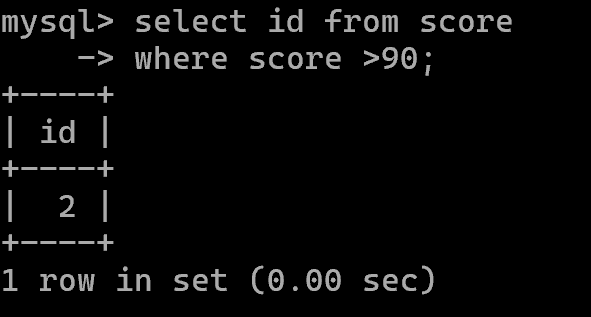
例如:在score表中查分数>90的id。
模糊查询:like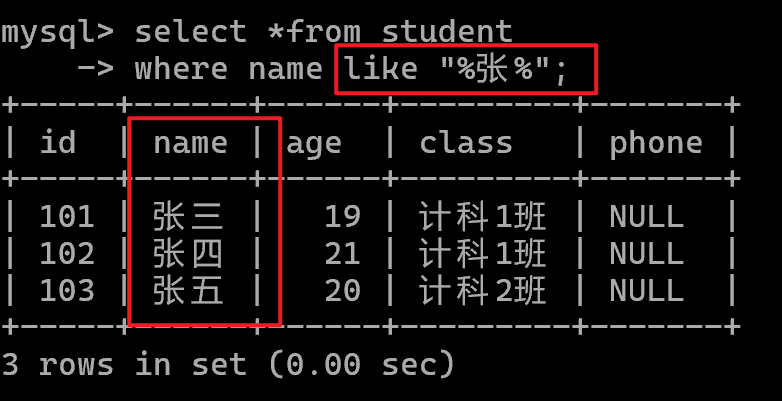
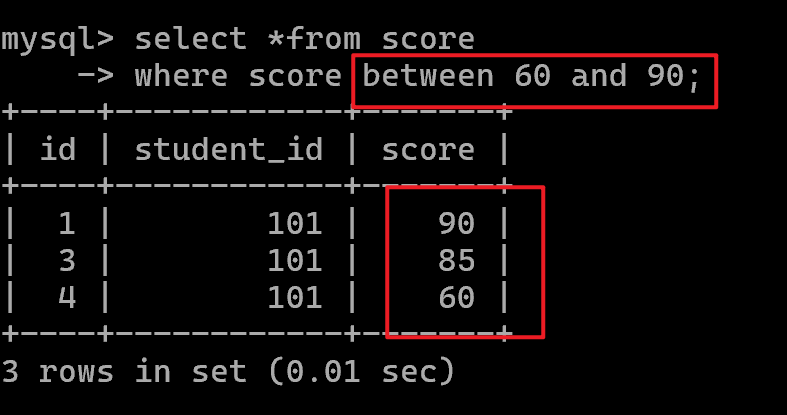
区间查询:between and
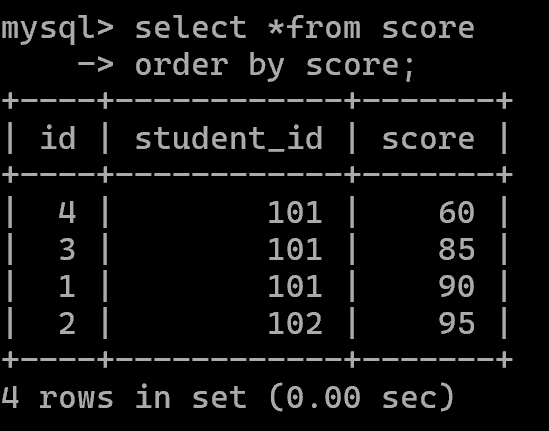
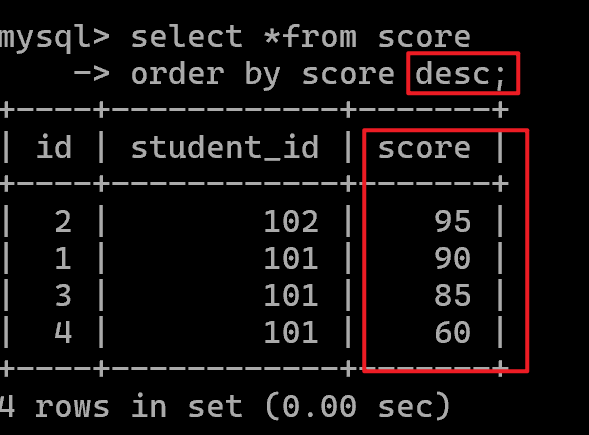
排序查询order by
升序:
降序:加上desc
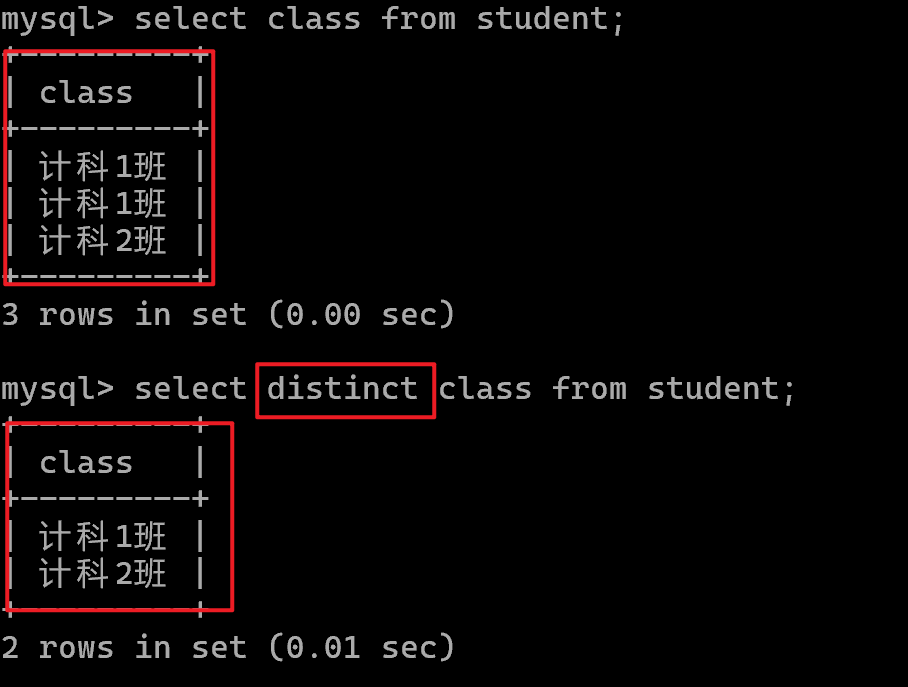
去重查询(distinct)
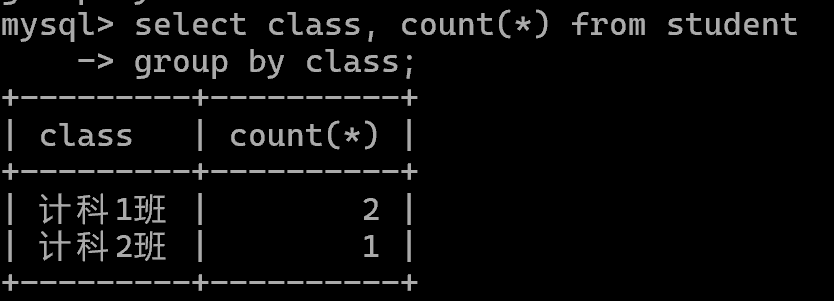
分组查询group by
按照某个字段分类统计。
例如:按照每个班级统计·班级人数
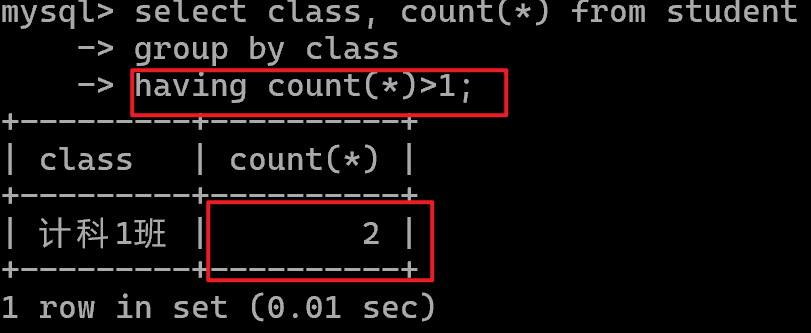
分组后筛选having
WHERE 是分组前过滤。
HAVING 是分组后过滤。
例如:先按班级分组,再查询班级人数大于1的班级。
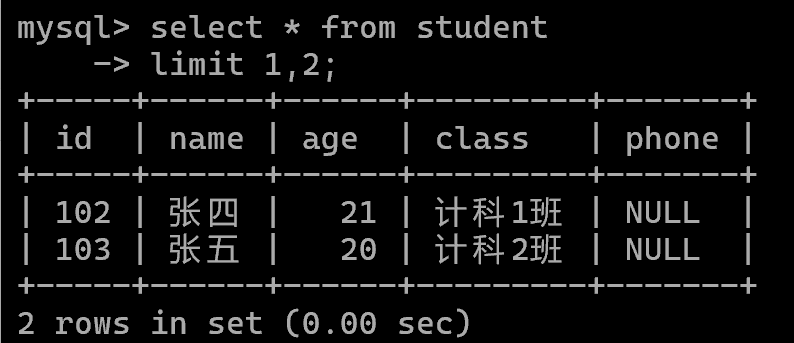
分页查询limit
limit 起始位置,每页条数
注意:第一个位置为0
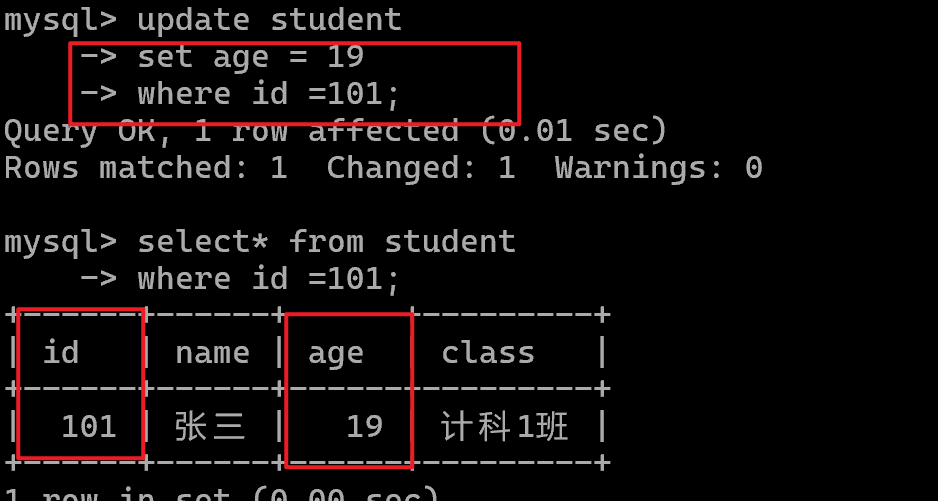
改(Update)
例如:更改id为101的学生,age改为19
删(Delete)
删除表中所有数据
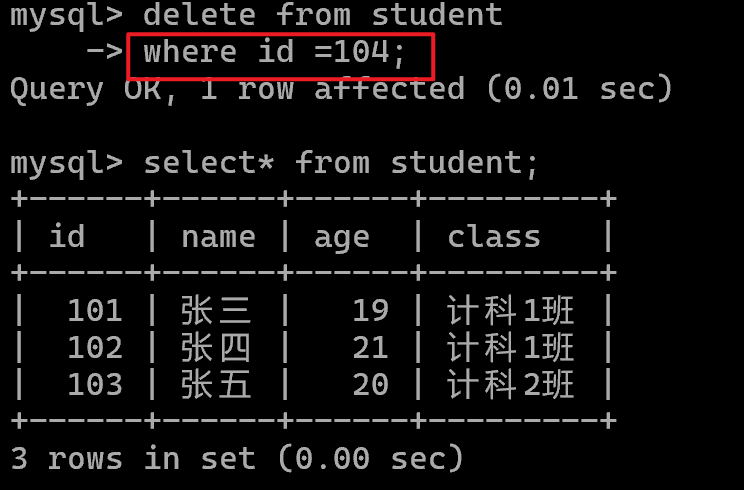
delete from student;删除表中部分数据
例如:删除id=104的学生数据
修改表结构
alter table student查询进阶
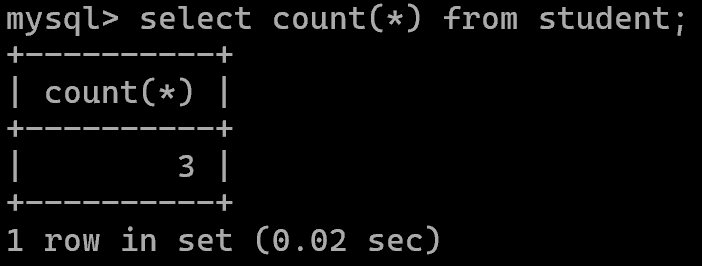
聚合函数
统计数量:count()
最大值:max()
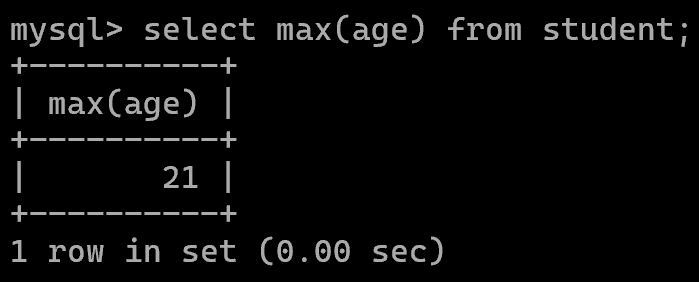
最小值:min()
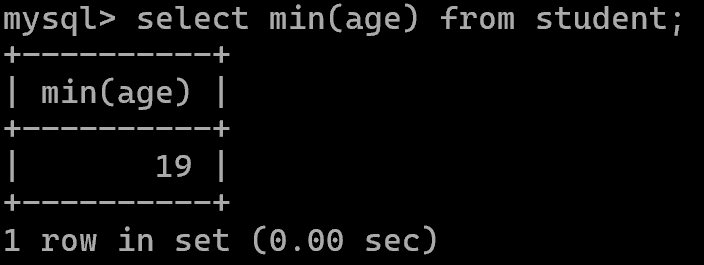
平均值:avg()
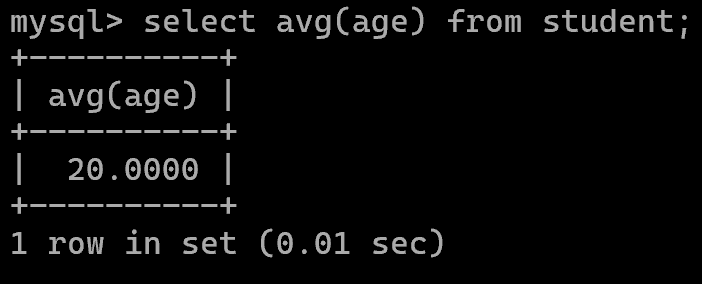
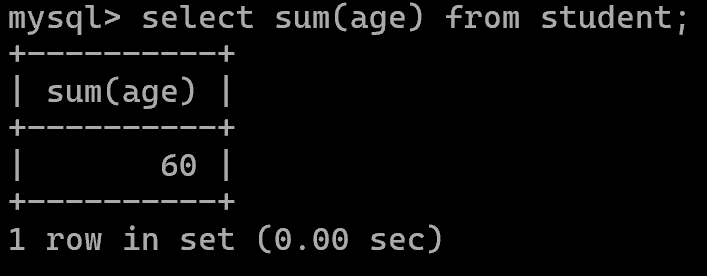
求和:sum()
数据库约束
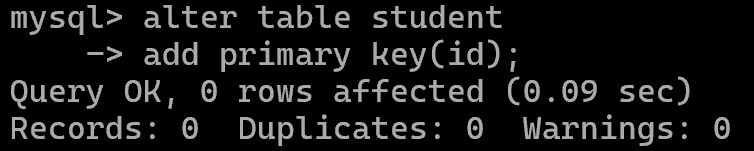
主键Primary key
修改表结构:添加主键
外键:foreign key
用于建立两张表之间的关系(不会出现score表存在在student表中找不到id的情况)
例如:新建一张score成绩表
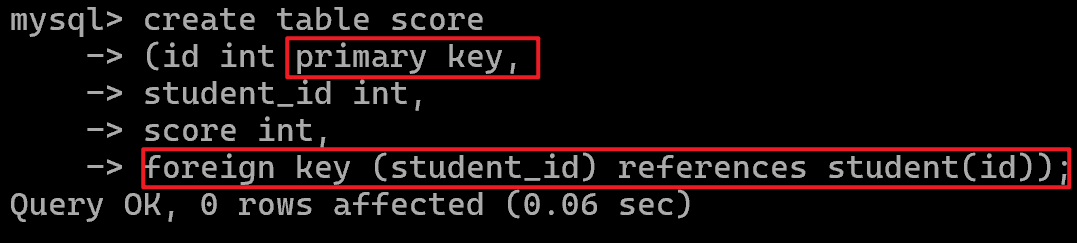
这里score.student_id 就引用了 student.id。
非空not null
modify用来修改已有字段的数据类型 / 约束

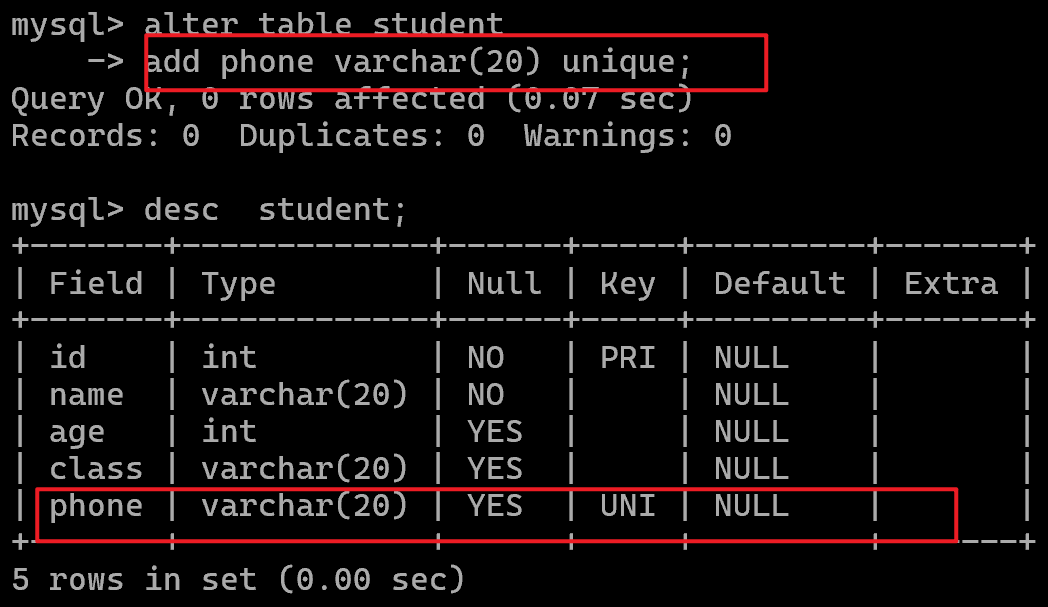
唯一unique
联合查询(三种连接)
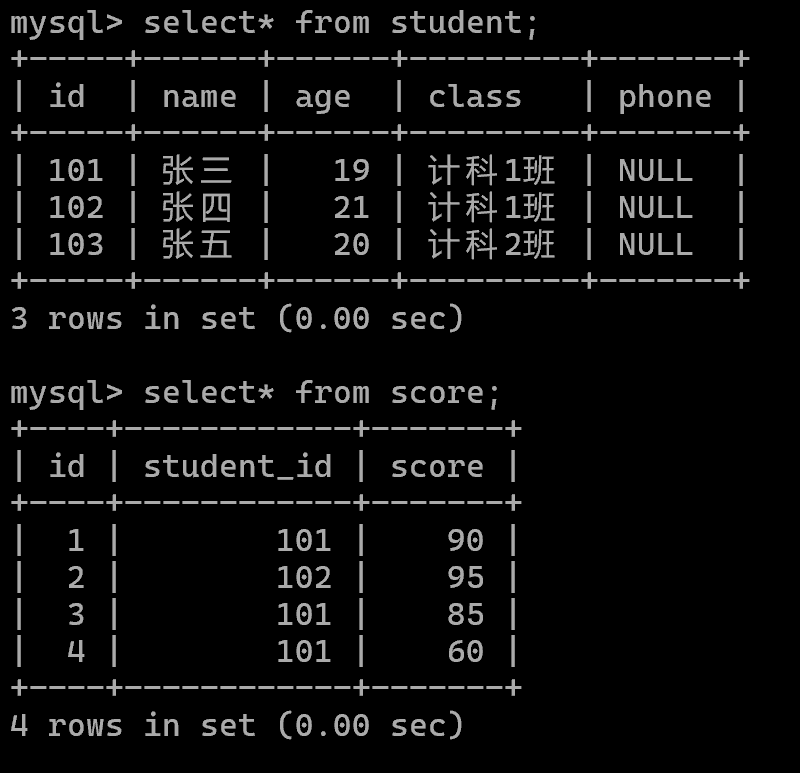
现在school数据库中有两张表:
内连接(最常用)inner join(取表之间的交集)
书写时inner可直接省略,JOIN 连表,ON 写主键 = 外键
student表主键:id
score表外键:student_id
例如: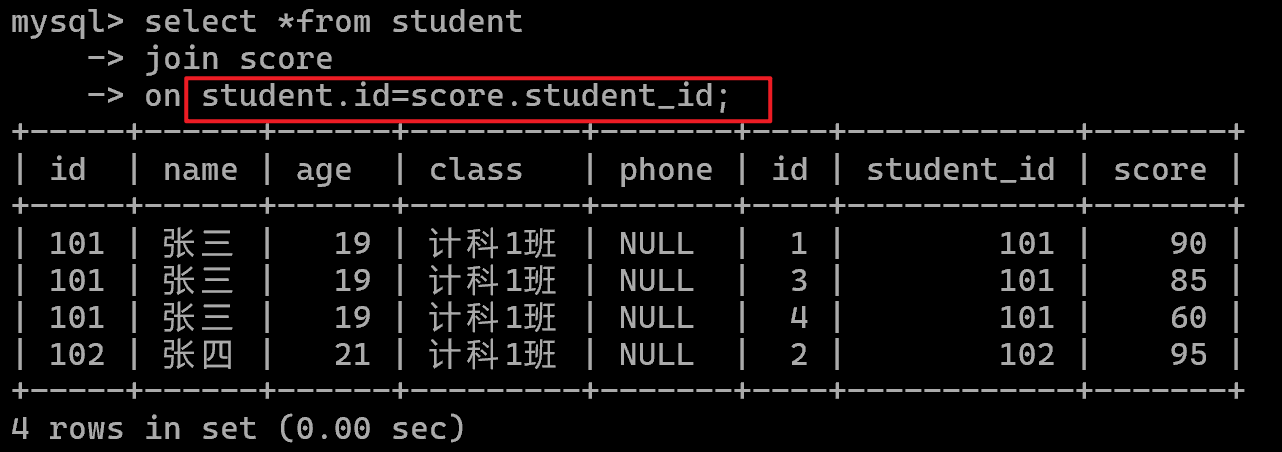
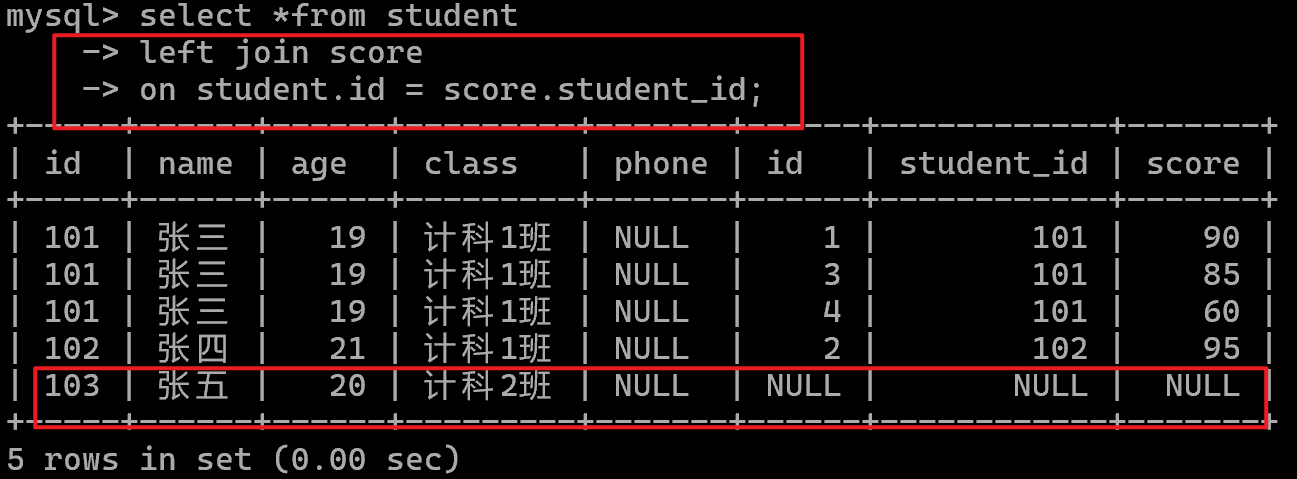
左连接(left join)
左表全部保留:
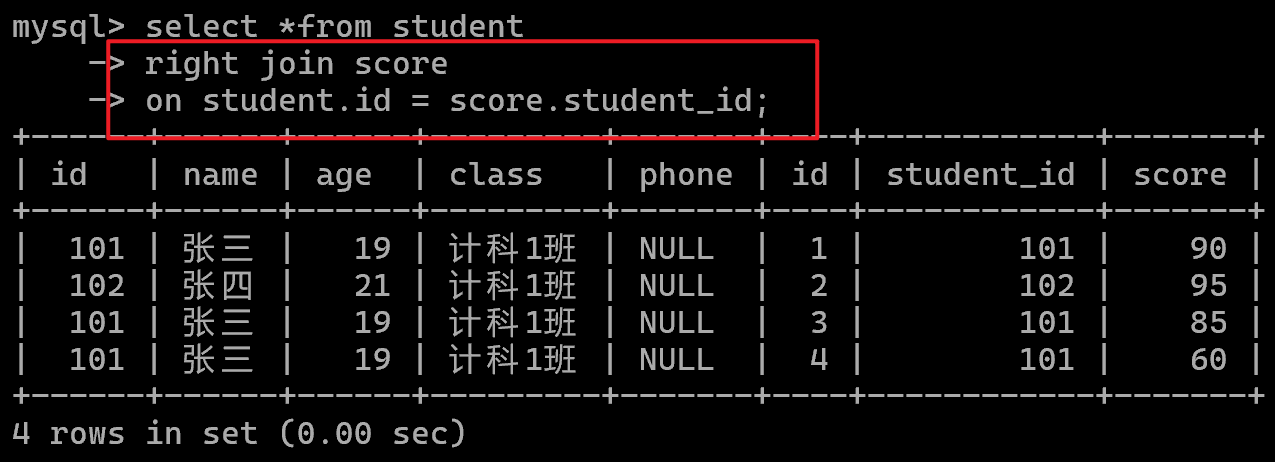
右连接(right join)
右表全部保留:

openEuler 是由开放原子开源基金会孵化的全场景开源操作系统项目,面向数字基础设施四大核心场景(服务器、云计算、边缘计算、嵌入式),全面支持 ARM、x86、RISC-V、loongArch、PowerPC、SW-64 等多样性计算架构
更多推荐



 1
1 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)