操作系统 第六章 文件系统的实现


前面讲了存储系统的软件实现(算法)那么底层的物理是如何实现的?
第一页:外存与内存——本质区别
核心逻辑:
- 物理层面的区别:
- 速度:内存极快(纳秒级),外存很慢(毫秒级,相差百万倍)。
- 连接方式:内存走高速总线,CPU可以直接寻址;外存走低速I/O总线(如SATA, NVMe)。
- 最本质的区别(关键点):
- 访问方式:内存可以通过“访存指令”(如
mov)直接访问;而外存无法通过访存指令直接访问,必须通过“系统调用”(如read/write)和驱动程序来操作。 - 结论:能否被CPU直接寻址,是区分内存和外存的金标准。
- 访问方式:内存可以通过“访存指令”(如
第二页 & 第三页:外存的“性格”刻画
核心逻辑:
既然外存不能直接访问,那它有什么特性?这几页PPT深入剖析了外存的物理特性,解释了为什么文件系统那么难写。
- 非易失性:掉电数据还在,适合永久存储。
- 可靠性与寿命:外存(特别是SSD/Flash)是有寿命的,写入次数有限(P/E cycles)。
- 访问粒度的不对称性:
- 读取可以很细(字节级)。
- 写入通常需要按块(Page)。
- 擦除必须按大块(Block)。
- 随机访问性能差:机械硬盘寻道慢,SSD随机写也慢。所以外存喜欢“顺序读写”。
第四页:打破界限——内存外存化与外存内存化
核心逻辑:
随着技术发展,界限开始模糊。
- 外存的内存化:像 Intel Optane (PMEM) 这样的技术,插在内存插槽上,CPU可以直接访问,但掉电不丢数据。这打破了“外存必须通过I/O访问”的铁律。
- 内存的外存化:给内存加上电池(NVDIMM),让它变成一种超高速的“硬盘”。
数据与文件系统
文件是对外存的关系映射,简化对外存的增删改查。文件管理系统是对外存的实际操作系统。
第五页 & 第六页:文件的抽象
核心逻辑:
外存太复杂了(有扇区、柱面、块、寿命限制等),程序员不想面对这些。于是操作系统引入了“文件”这个抽象概念。
- 文件是什么?
- 它是对“字节流”的抽象。
- 文件是对外存的关系映射
- —个具备—些属性的数据记录。我们可以根据其属性对相对应的数据记录进行增 (Create )删 (Delete)改 (Update)查 (Read;合称CRUD)
- 它屏蔽了底层外存的物理细节(比如数据存在哪个磁道、哪个块)。
- 逻辑结构:程序员看到的是连续的字节流(Byte Stream)或记录。
- 字节流结构
提供—个连续的存储空间,可存放任意的数据。
记录结构
提供—系列固定大小的存储空间,可以存放多 个大小固定的数据块。
索引结构
提供—系列的键值对,可以根据键来查询值
- 字节流结构
- 物理结构:操作系统负责把逻辑上的连续,映射到物理上的离散块。
第七页:层层映射——从文件到物理介质
核心逻辑:
这张图(图7)是文件系统的核心架构图,展示了数据是如何一步步落盘的。
- 文件层:用户看到的
a.txt。 - 文件系统层:负责把文件切分成块,管理元数据(FCB)。
- 卷管理层:可能把多个物理硬盘合成一个大硬盘(RAID),或者把一个硬盘切成多个分区。
- 物理设备层:具体的硬盘硬件。
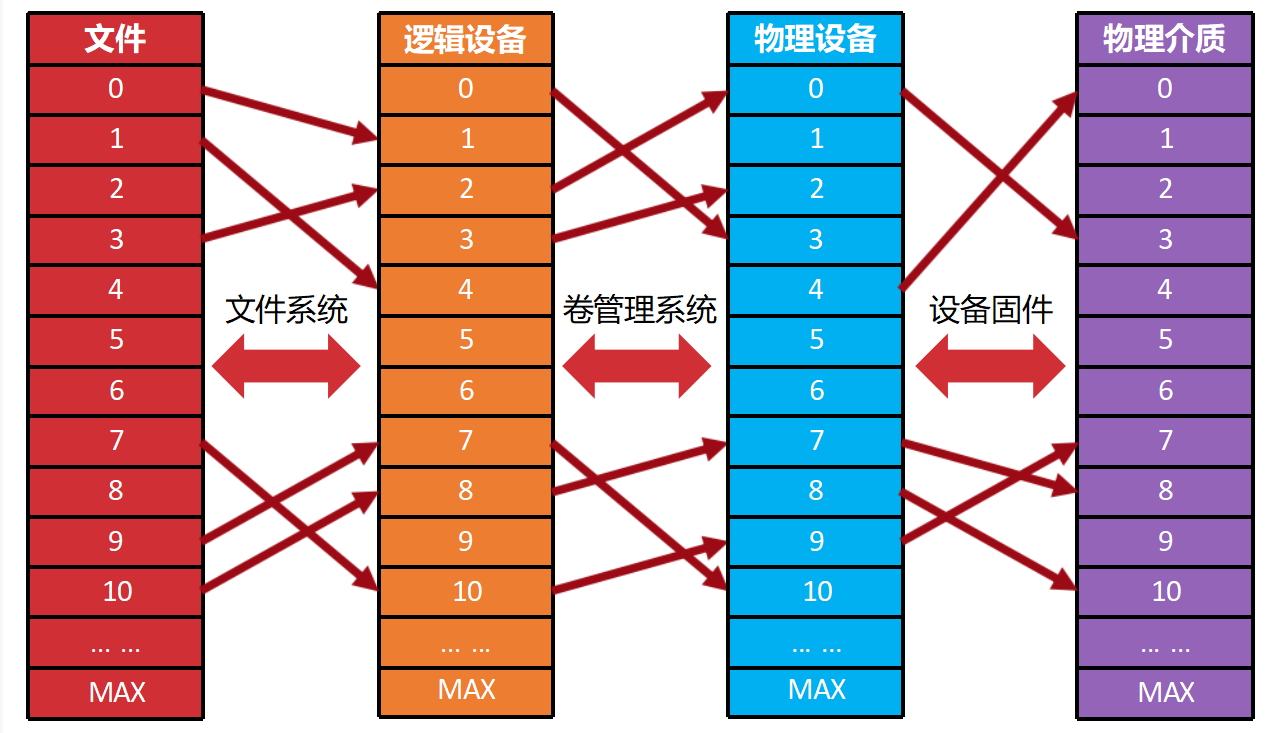
用户视角:用户程序通常只能看到最上层的“文件”抽象,或者最多看到“逻辑设备”(如 /dev/sda1),底层的物理映射对用户是透明的。
文件管理系统
第八页 & 第九页:文件系统——外存的管理者
核心逻辑:
最后,我们定义了什么是“文件系统”。
- 文件系统的作用:
- 它是操作系统中负责管理外存的软件栈。
- 它负责将“文件”映射到“物理块”。
- 它提供了按名存取的能力(不用记扇区号了)。
- 文件系统 vs 数据库:
- 文件系统更底层,功能更少,更偏重于信息的 存储而非查询, 可以看做是最基本的键值存储 (Key-Value Store) 型非关系型数据库
- 逻辑设备:
- 分区: 将—个物理存储器按照块号分成数个连续的逻辑存储器
- 阵列:将数个物理存储器按照—定规则整合成—个逻辑存储器
一、从“物理设备”到“物理介质”:硬件层的拆解
明确硬件层级:
- 物理设备:用户能看到的存储硬件,它对外呈现为“设备块”(操作系统能识别的最小存储单位)。
- 物理介质:设备内部的存储单元(如SSD的闪存芯片),它包含“物理块”(实际读写的最小单元)。
为什么区分这两层? 因为设备块是操作系统和硬件的“接口”,而物理块是硬件内部的“实际存储单元”。比如SSD的闪存芯片有坏块,设备会通过“闪存翻译层(FTL)”把坏块屏蔽,让操作系统看到的设备块是“连续且完美”的——这就是“设备块到物理块的转换”,目的是屏蔽硬件缺陷,提供稳定的存储接口。
二、从“物理块”到“逻辑块”:管理层的抽象
随着存储容量增大(如从早期磁盘到现代SSD),单个设备需要存储多个文件,且要应对“坏块”“容量扩展”等问题,操作系统引入了逻辑设备和逻辑块:
- 逻辑设备:可以是一块硬盘的分区(如C盘、D盘),也可以是多块硬盘组成的存储池(如RAID)。它和物理设备的关系是“多对多”(比如多块硬盘合成一个逻辑存储池,或一块硬盘分成多个分区)。
- 逻辑块:逻辑设备上的存储单位,是操作系统管理文件的“中间层”。
1. 为什么文件块到逻辑块之间需要转换?
- 核心目的:实现文件的逻辑组织与物理存储的解耦。
- 通俗解释:因为文件的逻辑结构(如连续存储、链式存储)和逻辑块的物理分布可能不一致。比如一个大文件可能被分成多个不连续的文件块,需要将离散的物理空间映射到连续的逻辑空间上。
- 支持文件动态增长:文件变大时,只需分配新的逻辑块,无需移动整个文件。
- 提高存储利用率:可以填充逻辑设备上的空闲块,避免“碎片化”导致的空间浪费。
- 隐藏物理细节:用户无需关心文件到底存在硬盘的哪个位置,只需通过文件名访问。
2. 为什么逻辑块到设备块之间需要转换?
- 核心目的:屏蔽物理设备的差异,提供统一的存储接口。
- 支持存储虚拟化
- 实现坏块管理
3. 为什么设备块到物理块之间需要转换?
- 核心目的:解决物理介质的缺陷,优化硬件性能。
- 屏蔽坏块
- 磨损均衡
- 性能优化
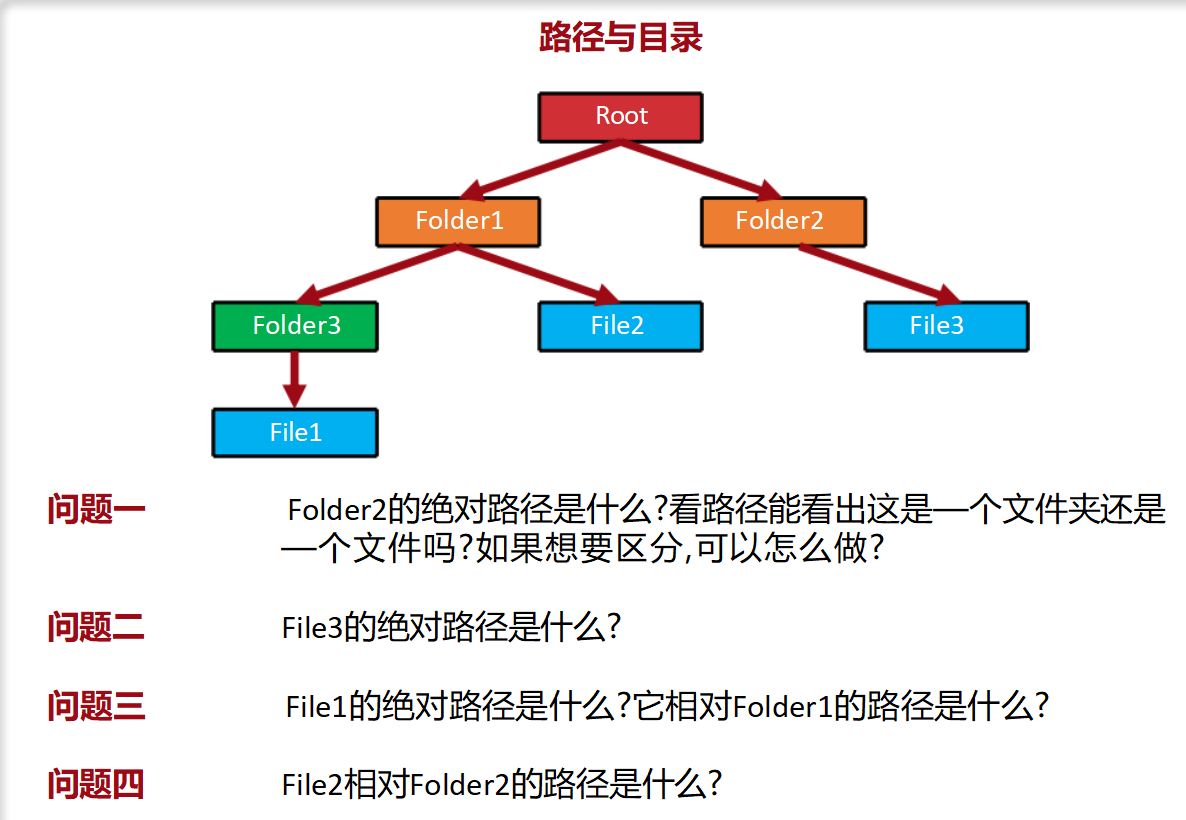
四、从“块映射”到“路径访问”:用户的最终体验
前面三层映射(文件块→逻辑块→设备块→物理块)是“幕后工作”,用户直接接触的是路径和目录:
- 绝对路径:从根目录(如
/)开始的完整路径(如/home/user/文档/笔记.txt),唯一确定一个文件。 - 相对路径:从当前工作目录(如
/home/user)开始的路径(如文档/笔记.txt),简化操作。 - 目录:树状结构的“节点”,用来分类文件(如“文档”目录放文本,“图片”目录放照片)。
为什么用树状结构? 因为人类习惯“分类管理”(如文件夹分层),树状结构能清晰表达文件的层级关系,让用户轻松找到目标文件——这就是“用户层的友好性”,把复杂的块映射变成直观的“文件夹+路径”。
总结:层层抽象,化繁为简
这几页PPT的核心逻辑是“分层映射”:
- 硬件层(物理设备→物理介质):屏蔽硬件缺陷,提供稳定接口;
- 管理层(物理块→逻辑块):灵活管理存储,应对容量、坏块等问题;
- 用户层(逻辑块→文件块→路径):把“块”变成“文件”,用树状结构和路径让用户轻松访问。
数据与文件系统
算法演进逻辑(通俗串联)
- 连续分配:最直观的方法,把文件存在连续的磁盘块里。但文件一旦需要扩容,就得找新的连续空间,容易“卡壳”;而且磁盘会留下很多零碎的小空隙(外部碎片),利用率低。
- 链接分配:为了解决连续分配的扩容问题,把文件拆成一个个块,用指针串起来。这样文件可以随便长,但读文件时得顺着指针一个个找,速度很慢;而且指针本身占空间,一旦指针坏了,整个文件就丢了。
- 扩展分配:结合前两者的优点,把文件分成“扩展块”(连续的小段),再用指针连起来。这样既减少了碎片,又比纯链接快一点,但还是没解决随机读写慢和指针损坏的问题。
- 链表备份(FAT):为了解决链接分配的可靠性问题,把所有指针集中存到一张表(FAT表)里,单独备份。这样即使数据块坏了,只要FAT表还在,文件结构就不会崩;而且FAT表可以加载到内存,随机读写速度变快。
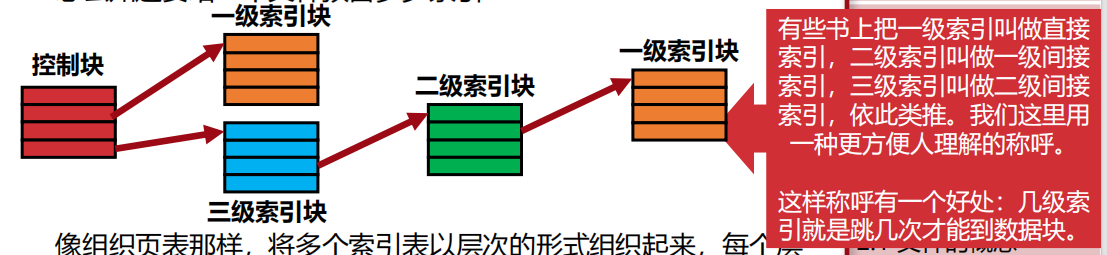
- 索引分配:为了彻底解决随机读写慢的问题,给每个文件建一个“目录”(索引表),直接记录每个数据块的位置。这样找数据就像查字典,速度飞快;但索引表本身占空间,大文件需要多级索引,结构复杂。
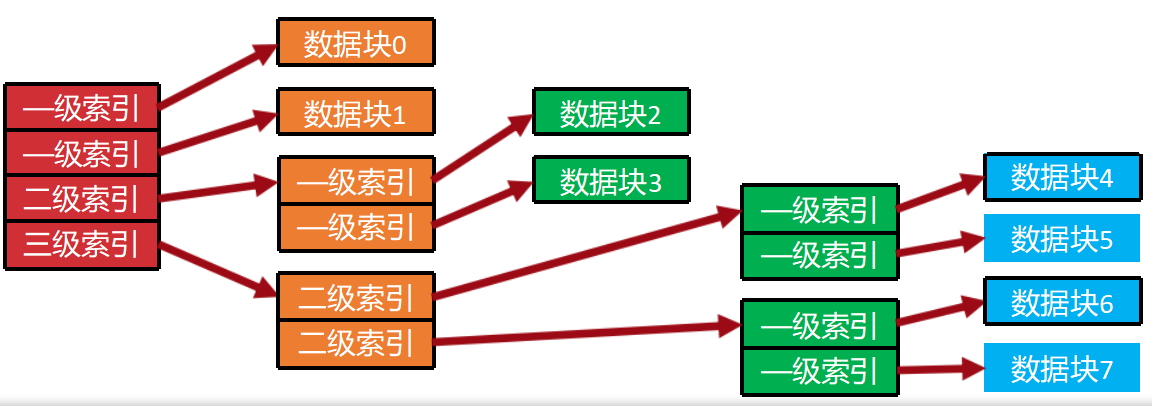
- 混合索引:现代文件系统的主流方案,结合直接、一级、二级、三级索引,小文件用直接索引(快),大文件用多级索引(支持大空间)。既保证了小文件的高效,又支持大文件的存储。
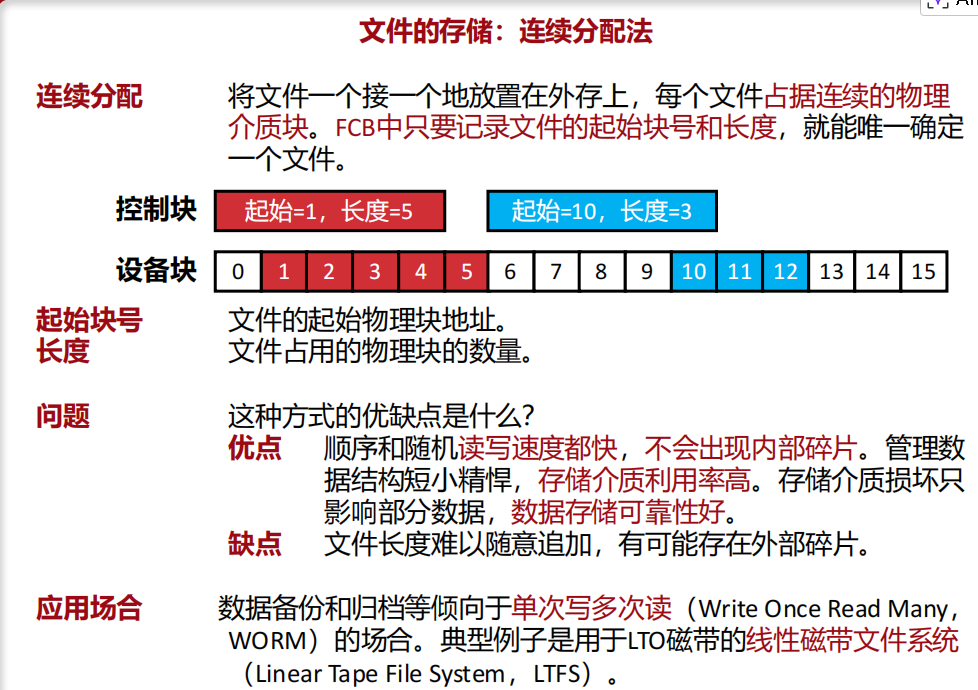
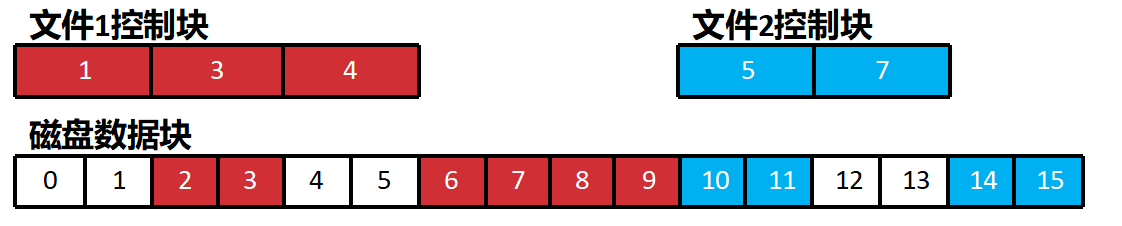
文件的存储:连续分配法
将文件放置在外存上, 占据连续的物理空间。 FCB中只要记录文件的起始块号和长度,就能唯—确定 —个文件。
优点:顺序和随机读写速度都快 , 不会出现内部碎片。
管理数据结构短小精悍, 存储介质利用率高。
存储介质损坏只影响部分数据, 数据存储可靠性好。
缺点:扩容难, 有外部碎片。
文件的存储:链接分配法(解决可扩展)
为了解决连续分配的扩容问题,把文件拆成一个个块,用指针串起来。这样文件可以随便长,但读文件时得顺着指针一个个找,速度很慢;而且指针本身占空间,一旦指针坏了,整个文件就丢了。
优点:文件长度可以随意增减, 不会产生外部碎片。
缺点:顺序读写慢, 随机读写更慢。
管理数据结构包含指针。
存储介质损坏可能会导致指针丢失,因此, 数据存储可靠性差。
分配块的大小怎么选择? 选择物理块的大小, 还是更大的单位?
文件的存储:拓展分配(综合连续和链式)
连续分配和链式分配的折中。使用链表来避免外部碎片,使用 可变长度的块来避免内部碎片。这种可变长度的连续块称为扩展 (Extent) ,其内部包含指向下—个扩展的指针,以及本扩展的长度。
结合前两者的优点,把文件分成“扩展块”(连续的小段),再用指针连起来。这样既减少了碎片,又比纯链接快一点,但还是没解决随机读写慢和指针损坏的问题。

优点:文件长度可以随意增减, 不会产生外部碎片; 同时扩展 大小灵活,也不会产生内部碎片。
缺点:顺序读写有—定提升,随机读写还是慢。
管理数据结构包含指针和扩展长度。
存储介质损坏可能会导致指针或扩展长度丢失,因此, 数据存储可靠性仍然差。
文件的存储:链表备份法(解决可靠性差)
为了解决链接分配的可靠性问题,把所有指针集中存到一张表(FAT表)里,单独备份。这样即使数据块坏了,只要FAT表还在,文件结构就不会崩;而且FAT表可以加载到内存,随机读写速度变快。
管理结构就和数据本身完成了解耦
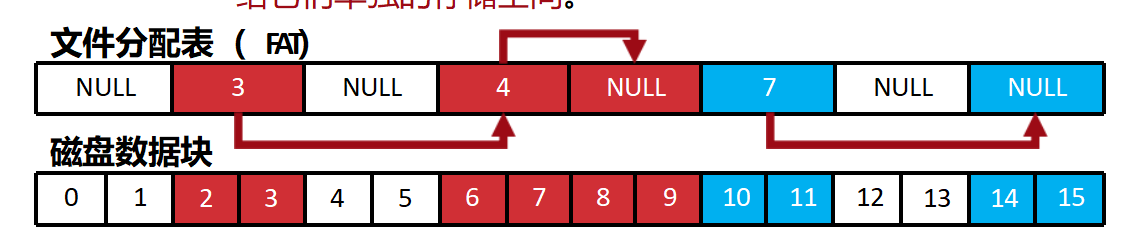
数据区受损只会引起数据损坏, 不会引起文件系统崩溃
文件的存储:索引分配法(解决随机读写慢)
为了彻底解决随机读写慢的问题,给每个文件建一个“目录”(索引表),直接记录每个数据块的位置。这样找数据就像查字典,速度飞快;但索引表本身占空间,大文件需要多级索引,结构复杂。
优点:
连续和随机访问都快,抗损性能也强。
缺点:不好分配
索引预留多了, 浪费;索引预留少了,文件大小受限。
但是指针分配大了浪费 少了不够,怎么办?
文件的存储:按需分配法
像组织页表那样,将多个索引表以层次结构组织起来,每个层 次负责翻译逻辑块号的—部分, 最终得到物理块号。不使用的索 引块不创建、不填充就可以了。虽然随机访问仍然引起指针追逐, 但是追逐的次数是有限的,也即索引的层数
文件的存储:混合索引法
操作系统启动时会加载很多小文件,对小文件多级索引不核算。
文件的索引采取多级方法进行, 但索引的级数随着文件块号的增加 而增加。文件越靠前的部分, 索引的级别越少。这样, 小文件的存储效率就提高了。
混合索引法就是“把最常用的数据放在手边(直接索引),不常用的数据放在抽屉里(一级索引),极少用的庞大数据放在仓库里(二级索引)
索引分配法存储小文件浪费,比如索引2MB,数据1MB
文件的存储:直接内容法
当文件很小的时候,可以直接放进FCB中,不需要额外的数据块


管理结构占用空间 可靠性 连续/随机访问 拓展性 内外部碎片
空闲块的组织
暂未被占用的物理块称为空闲块
连续存储 将所有的空闲块的地址和长度记录在表格中, 好像连续分配法那样。
链表存储 将所有的空闲块放在—个链表里面, 好像链接分配法那样
索引存储 将所有的空闲块放在—个多级索引里面,好像索引分配法那样

索引法的问题:—次分配多个块变得较高效了。但是,每次分配单个块都需要查 询多级索引才能启动分配,启动成本太高。怎么解决这个问题?
空闲块的组织: 分组索引法
空闲块可以先按照预定的数量分组, 每组使用自己的索引; 每个 索引表都包含指向下—个索引表的—个指针; 除了这个指针之外, 每组空闲块的地址直接登记在该索引表内。即先索引,再链接

整个车厢满了,直接把索引头挂到下一节车厢上。
车厢空了还要删,就再引入一节车厢,把索引头挂过来。
- 解决了“多级索引”太慢的问题:
多级索引像剥洋葱,找一块地要读好几次硬盘。分组索引法就像“栈”一样,永远只操作最上面那一层(火车头挂着的那一节),绝大多数时候只需要读/写一次磁盘。 - 解决了“链表”太散的问题:
虽然它本质上还是个链,但它把地址打包了。一个索引表里能存几十个地址,相当于一次操作就处理了一批,效率比一个连一个的纯链表高得多。
空闲块的组织: 位图法
用—系列二进制位对应每个块。如果该块被分配出去,那么位图 的对应位置就置1,否则置0。

可将位图直接加载进内存。分配单个空 闲块只要找到第—个0所在的位置,分配连续的区间则是寻找足够长的连续的0。释放空间就更简单,只要将那些1变成0就好了
但是找到第—个0,以及找到连续的足够长的0,看上去也不简单
位图可以按照不同粒度分级
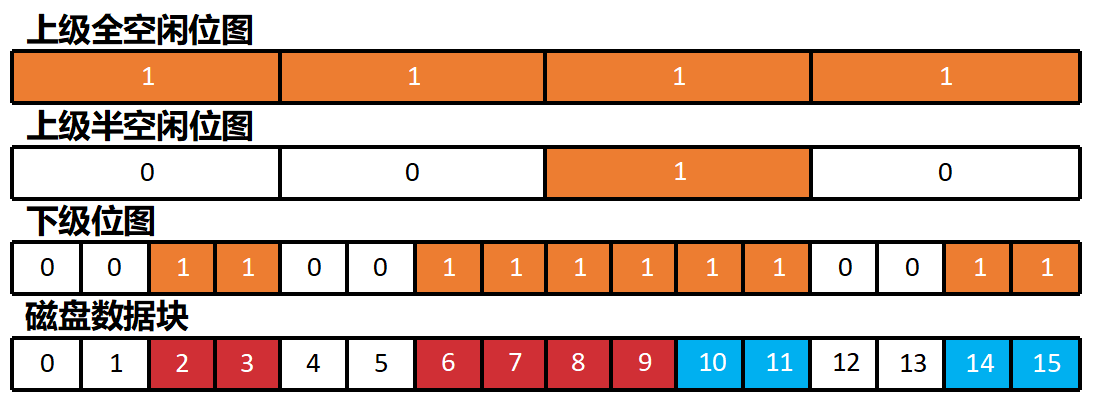
空闲块的组织: 多级位图法
在位图法的基础上,使用多个不同粒度的位图。更高粒度的上级 位图可以有全空闲和半空闲两种: 对于全空闲上级位图,若它的 某—位是0,代表其对应的整个下级位图区间的空间都是空闲的; 对于半空闲上级位图, 若它的某—位是0,则代表其对应的下级位 图区间中至少有—个空闲块。
FCB目录的存储
文件内部的组织已经实现了,但文件之间还需要组织起来才能形 成—个文件系统
目录文件:包含目录信息的特殊文件。它们储存的是其下属各文件的属性 , 也即其FCB内容。
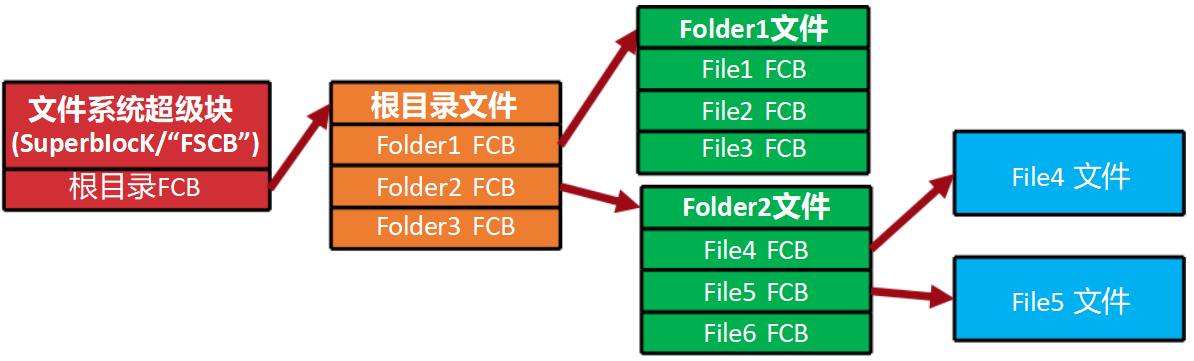
文件的查找:目录的改进
如果是子目录文件不在了,那意味着它下属的—切都找不到了, 文件系统发生了结构性损坏。怎么避免这个问题? 将每个目录文件在磁盘上保存几个备份
考虑文件移动的情况
文件系统层面的操作中, 最常见的是文件移动。在常规的文件移动中, 每次都需要在源目录文件中删除该文件的FCB,并将FCB写入目标目录文件。 FCB是有—定数据量的,移动需要花—些时间,在—次移动大量小文件(如代码库、图片库)时尤其如此。
文件的查找:索引节点
把FCB里面不常变动的部分单独保存在—个表里面 ,然后让目录文件去引用这个表就可以
- 目录文件: 存的是索引项,格式为
<文件名, 索引节点号>。 - 索引节点表: 存的是索引节点(下标是节点号),格式为
<文件属性, 物理地址指针>。 - 查找过程: 拿着文件名去目录里查 -> 得到节点号 -> 拿着节点号去索引节点表里查 -> 得到 FCB 和数据地址。
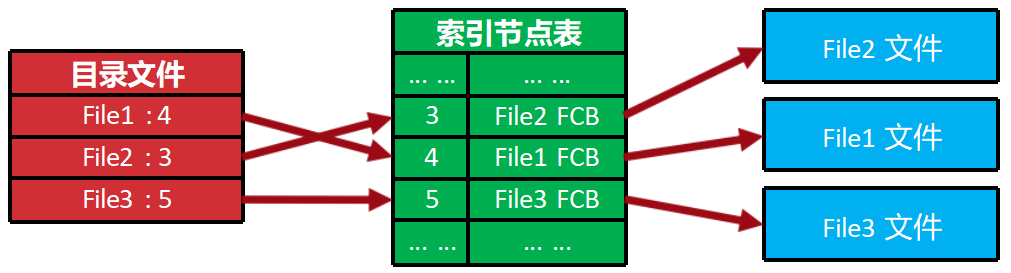
文件的引用:硬链接
一个文件取很多个名字,删了其他的不会影响其他文件名的引用
这种通过某个名称可以访问另—个名称所属内容的形式叫做“链接”,在文件系统数据结构层面实现的链接称为硬链接
文件的引用:软链接
硬链接虽然好,但只能在同一个硬盘分区里用(因为它们共用一个inode表)。能不能跨分区,甚至像Windows快捷方式那样?
在打开—个 软链接文件时, 内核将提取软链接文件中的实际路径,并据此 来打开真实的文件。这种软链接又叫符号链接 (Symbolic Link; Symlink) 。
在部分操作系统中,应用程序需要自己识别打开的文件是否是 软链接,如果是则需要自行解析软链接并转去打开真实的文件。这种软链接又叫做快捷方式 (Shortcut; Launcher ) 。
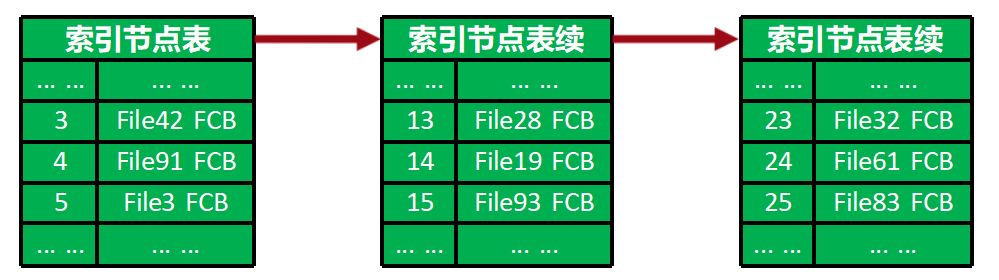
文件的查找:索引节点表的改进
索引节点耗尽了,需要扩充怎么办?
解决方案:将索引节点表视为“特殊文件”(分组索引法)
PPT提出一个巧妙的思路:把“索引节点的集合”本身也看作一个“特殊文件”。既然它是一个文件,就可以像管理普通文件一样,用更灵活的方法来存储和管理它,比如链表法或索引法。
图中展示的正是链表法的存储方式:
- 索引节点表是主表,它指向一个索引节点表续。
- 索引节点表续又可以指向下一个索引节点表续。
- 这样,当主表空间不足时,系统可以动态地“追加”新的表续,从而实现索引节点的动态扩充,解决了“耗尽”的问题。
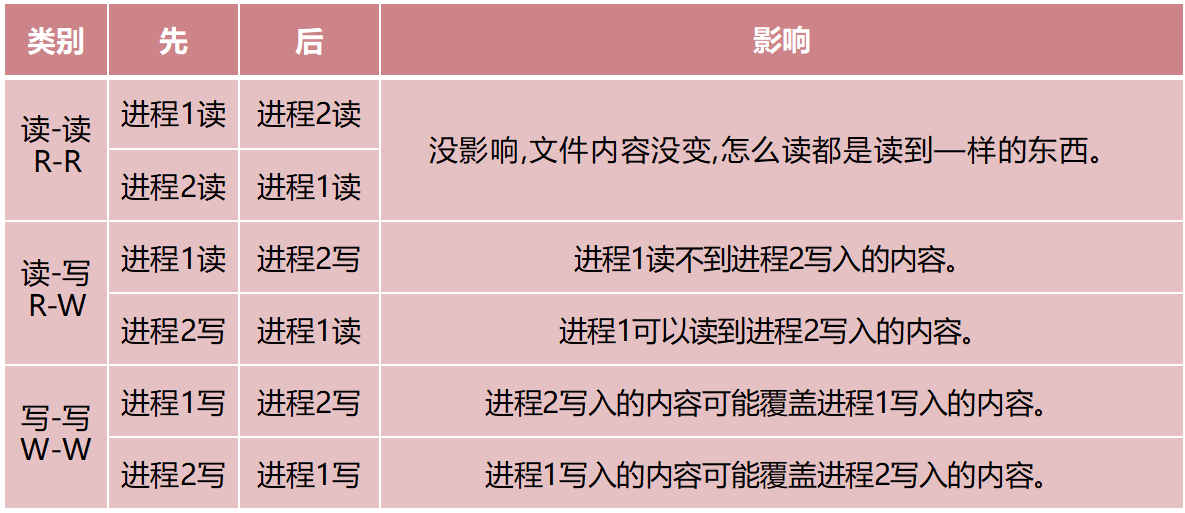
文件的共享:多个进程打开同一个文件
元文件系统
从宏观的“多文件系统如何统一”讲起,深入到了微观的“文件权限如何精细化管理”,最后讨论了“谁来掌握生杀大权”。
问题:操作系统中不仅只有一种文件系统,但是要查询所有文件系统下的文件怎么办?
解决方案:虚拟文件系统(VFS)
- 角色: VFS 就是那个“全能翻译官”。它在应用程序和具体的文件系统之间加了一层抽象。
- 作用: 应用程序只需要对 VFS 说:“我要打开这个文件”,VFS 就会自动去指挥底下的 NTFS 或 ext4 干活。它不是真正的文件系统,而是一个统筹管理的抽象层。
盘符法
仅允许将代表具体文件系统的子目录挂载在虚拟文件系统的根 目录下,并且赋予不同文件系统独立的标志。这就是Windows的 盘符机制。
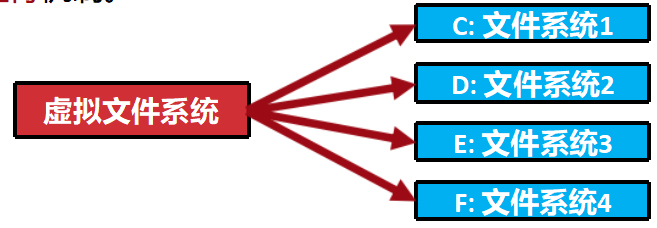
路径法
允许将任何—个文件系统的任何子目录挂载到任何文件系统的 任何子目录下,并且—个文件系统及其子目录可以挂载多次

挂载与硬链接和软链接有何不同? 它们都可以递归吗?
挂在可以递归
文件权限管理
访问控制矩阵
Access Control Matrix , ACM 记录不同保护域(进程) 对文件操作的权限的矩阵。它—般情况下是—个稀疏矩阵。
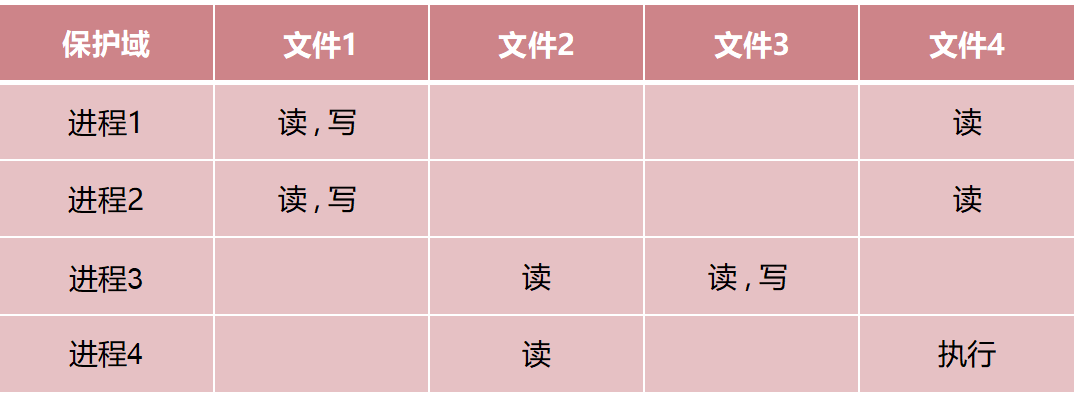
如何存储呢?
基于文件的访问控制ACL(不行,因为你不知道有哪些进程) 访问控制列表
Access Control List , ACL 按照每个文件记录不同保护域(进程) 对文件操作的权限的列表, 它储 存在文件的FCB中。进程访问该文件时,就从FCB中取出该文件的ACL,对比查看进程是否有访问它的权限。
- 做法: 既然矩阵很空,我们就不存矩阵了,直接把权限表贴在文件身上(存在FCB里)。
- 逻辑: 文件1说:“进程1能读写,进程2能读”。
- 缺陷: 进程是动态生成的,今天有进程1,明天可能就没了。基于“进程ID”做权限管理太麻烦,不现实。
它可以看做ACM的按列压缩。

在实际系统中, 能直接按照进程存储ACL吗?
不能,系统中的进程是启动应用程序时生成的,不是固定的。
既然进程不可以作为权限表主题,就看看创建进程的用户。
进程是用户启动的,那么给每个用户—个权限表就可以了;不 同用户的进程直接继承这个用户的权限
RBAC基于角色的访问控制
Role-Based Access Control , RBAC 按照角色记录对文件操作的权限,并同时记录每个用户属于哪些角色。
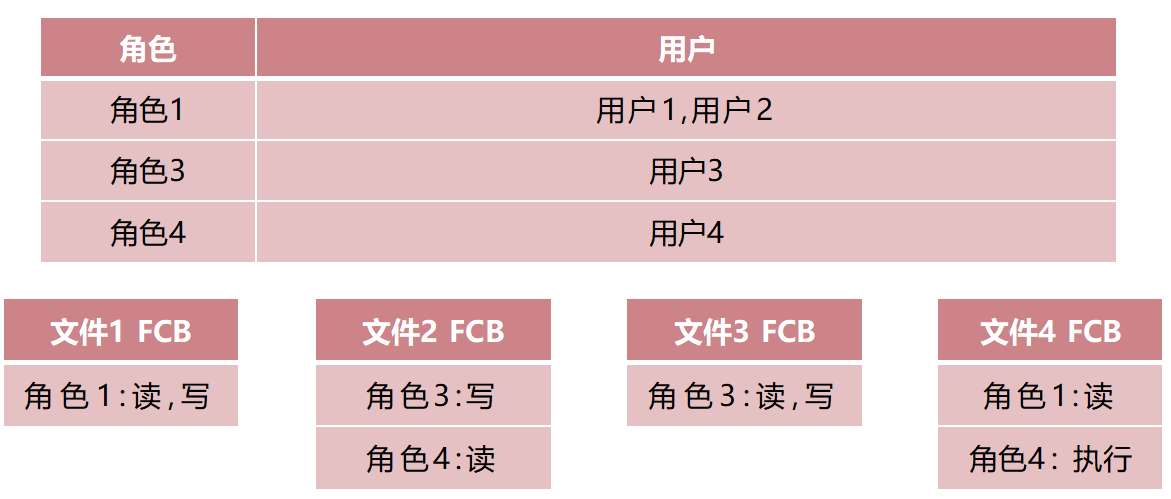
按照用户角色对其启动的全部进程—刀切有什么优缺点?
管理简单。
不同的用户可能会在不同的情况下执行不同的进程。
ABAC基于属性的访问控制 一事一议
Attribute-Based Access Control , ABAC RBAC的升级版,按照角色、活动、操作、环境等的—系列属性决定对文件操作的权限, 可以—事—议。描述语言 (XACML)来描述这种权限控制, 而且为了修改方便必须将其集 中存储 (RBAC也可以集中存储) 。

PBAC基于策略的访问控制 (ABAC的另一种称呼)
Policy-Based Access Control , PBAC ABAC的另—种称呼, 强调使用脚本而非描述列表来控制权限。每个访问请求都被送入含有策略的脚本程序, 并由程序来输出判别结果。比XML 更直观、更符合人类习惯 ,且可不受格式限制加入任意判断逻辑。

要在运行中动态撤销和设置权限,需频繁编辑XML或脚本。怎么规避?
CBAC基于权能的访问控制
Capability-Based Access Control , CBAC 不将访问权限和文件结合,而是将其和具体的进程结合。每个进程都保存自己的权能表 (Capability Table , CT), 其中每个权能都记载它可以对某个文件做某些访问操作。它可以看做是ACM的按行压缩。 在进程启动时, 其权能表为空, 必须等待上级下发权能;权能可以在进 程运行的过程中由其管理者授予和撤销,这就解决了动态性的问题

不论是RBAC、ABAC、 PBAC或CBAC,谁来编辑ACL或CT?
DAC自主访问控制
Discretionary Access Control , DAC 每个文件有—个“所有者”,该文件的权限可以由其“所有者”负责编辑。对于RBAC、ABAC和PBAC,所有者负责编辑它拥有的文件的ACL、XML或 权限控制脚本; 对于CBAC,所有者负责将其文件的访问权能添加到进程的CT中。
MAC强制访问控制
Mandatory Access Control , MAC 由系统中的—个或—组管理员统—编辑全部或分别编辑部分文件的权限。无论是ACL、XML还是CT都由系统管理员集中操作,对文件的访问控制权更集中。
系统中除了文件之外,还有其他设备等等。这些成分的权限管理能否也参照文件进行?
可以,一切皆文件
☆ 考点

外存储器分配机制与实现
按来源划分
- 系统文件:操作系统的“心脏”,如内核文件。普通用户不能动,只有系统更新时才会变。
- 中间件文件:程序的“工具箱”,如驱动程序、运行库。用户只能读和执行,不能随便删。
- 用户文件:用户的“私人物品”,如文档、照片、自己写的代码。
- 临时文件:用完即弃的“草稿纸”,如缓存、日志。需要定期清理,否则会撑爆硬盘。
按性质划分
- 普通文件:就是我们平时理解的“文件”,存数据。
- 索引文件:文件的“目录”或“索引卡”,记录其他文件的信息,如目录文件。
- 设备文件:这是Linux/Unix系统的精髓——“一切皆文件”。打印机、键盘、硬盘都被抽象成文件。这样做的好处是,对设备的操作(如读写)可以复用文件的操作接口,大大简化了系统设计。
( 1)引入设备文件有什么好处?
统一IO接口,无需编写驱动调用,统一使用openread
(2)硬链接属于索引文件吗?
不属于,指向目标文件的节点,共享文件,是入口,不是FPC
按权限划分
不可访问文件
只读/写文件
可执行文件
含有进程的描述(Specification),可以用以启动进程的文件。
隐藏文件
一般不展示给用户的文件,可能用于保存配置信息。
(3)只读文件我们都见过,但什么应用场景需要只写文件?
日志文件 审计文件
GPT分区
分区的主要目的是为了更好地组织和管理硬盘上的数据。一个未经分区的硬盘就像一个大通间,所有文件都混在一起,既混乱又危险。通过分区,你可以:
- 逻辑分离: 将操作系统、应用程序和个人文件(如照片、视频)存放在不同的分区中。这样,在需要重装系统时,只需格式化系统分区,而不会影响其他分区里的个人数据。
- 多系统共存: 可以在同一块硬盘上创建多个分区,分别安装不同的操作系统(如 Windows 和 Linux),实现多系统启动。
- 提升性能与安全: 将频繁读写的数据和静态数据分开,有助于减少磁盘碎片,可能在一定程度上提升性能。同时,一个分区的数据损坏通常不会直接影响其他分区,提高了数据的安全性。
要实现分区,就需要一套规则来记录每个分区的位置、大小等信息,这套规则就是分区表。目前主流的分区表有两种:MBR 和 GPT。你提到的 GPT 就是其中一种更现代的方案。
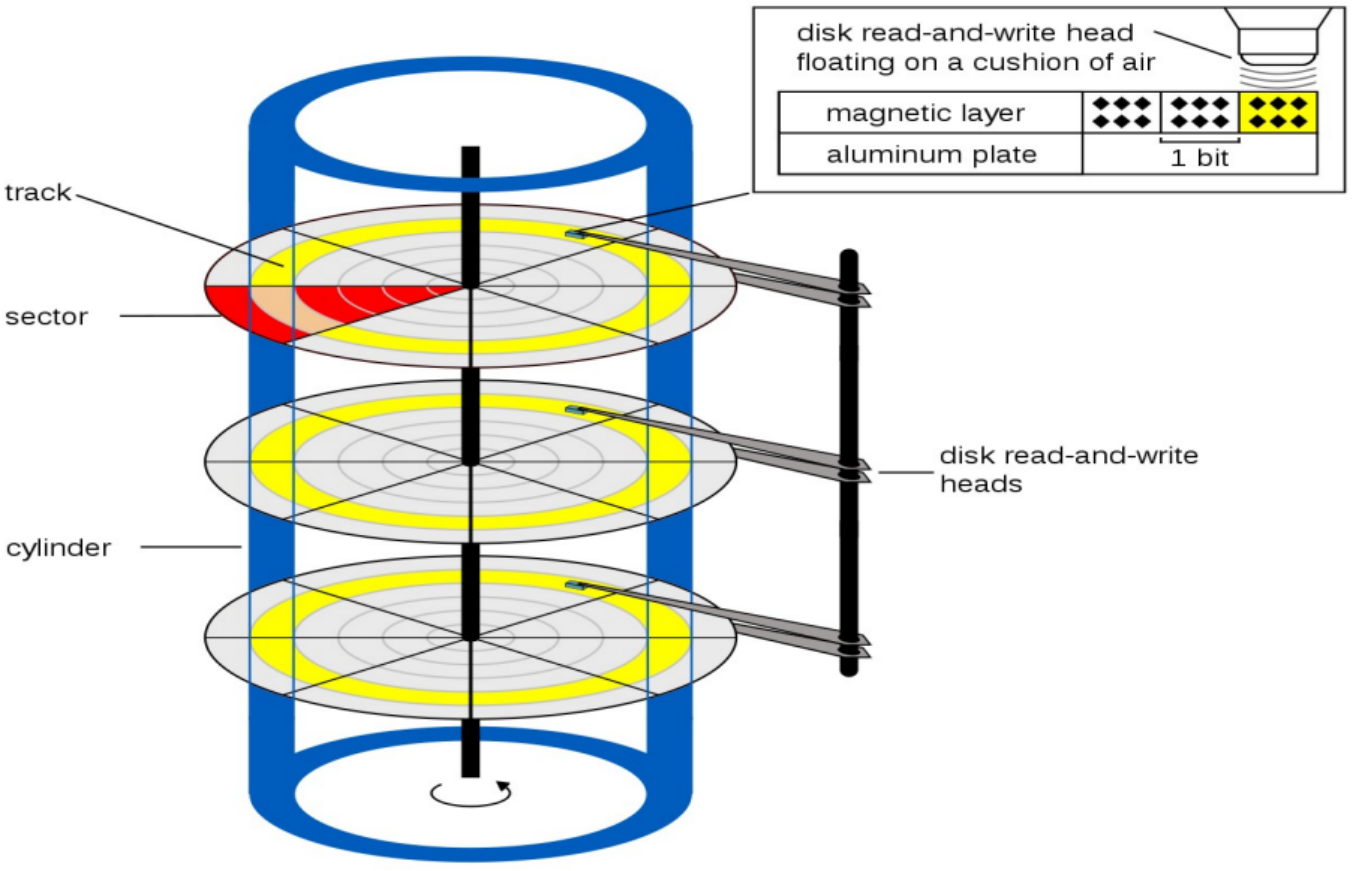
如何找到分区中的数据?[有计算]
CHS地址 CHS是柱面(Cylinder)-磁头( Head)-扇区(Sector)格式的缩 写。在CHS中,S从1开始 ,C和H从0开始。
LBA地址 LBA是Logical Block Address的缩写,不再包含毫无意义的CHS参 数,更适合扁平化和复杂化的现代外存介质。 LBA从0开始。
☆ 考点:
( 1)若先数S ,再进位H ,最后进位C,则CHS转换为LBA的公式是什么?
没经过一个扇区LBA++,设每个磁道的扇区数SM,每个柱面的磁头数为HM(=盘面数)
公式=LBA=(CXHM+H)【当前柱面磁盘的扇区总数】*SM+(S-1)【当前磁道内的扇区偏移】(S从1开始)H是层 C是柱体
(2)某磁盘CM=1024, HM=4 ,SM=16,其CHS地址10 2 5对应的LBA是多少?
(10X4+2)*16+(5-1)=42*16+4=676
磁带: LTFS
一种数据磁带,容量大、价格便宜 ,适合备份大量数据使用。
-
磁带的特性:
- 顺序读写:磁带就像一盘老式录音带,想听后面的歌必须快进,无法像硬盘一样“随机跳转”。因此,LTFS的设计核心就是最大化顺序读写性能。
- 价格便宜:单位容量成本极低,适合存储海量不常访问的数据(冷数据)。
-
LTFS的设计:
- 分区结构:每个LTFS分区包含一个标签区(Label Construct)和一个内容区(Content Area)。标签区存放卷标,内容区存放数据和索引。
- 数据与索引:内容区里,数据文件(A, B, C...)和索引区(Index)是交错存放的。索引区是一个XML文件,记录了“文件名 -> 数据位置”的映射。
- 如何处理修改? 这是LTFS最巧妙也最“无奈”的地方。因为磁带无法“原地修改”,所以当文件被更新时,新版本会被追加到磁带的末尾。老版本并不会被立即删除。
- 代数(Generation):为了区分新旧版本,LTFS引入了“代数”的概念。新版本的索引块会有一个更高的代数,系统通过它来判断哪个是最新版本。
- 优点与缺点:
- 缺点:浪费空间,因为旧版本会一直占用磁带,直到磁带被重新格式化。
- 优点:天然的历史版本备份!你可以找回任何一个文件在任何时间点的历史版本,这对于数据安全至关重要。
磁带介质的特点是什么?
顺序读写
磁带先天是顺序读写的 ,不可能指望随机读写性能。
价格便宜
磁带的单位容量价格如果不便宜 ,就不能吸引客户,否 则他们会用硬盘代替。
问题二 如何针对这点,设计适合磁带的文件系统?
顺序读写性能好,空间利用率高。
问题三 假设文件系统本身的管理数据结构已经最小化,还有什么方法可以继续节约存储器?
线性磁带文件系统
Linear Tape FileSystem , LTFS 一种适合于磁带的文件系统。顺序读写快、空间利用率高 ,并自带压缩
功能:文件存储到介质上之前会被自动无损压缩,读取时则自动解压缩 , 最大限度节省介质容量。
LTFS分区 每个LTFS分区都具有一个标签区(Label Construct)和一个内容 区(Content Area),如下所示

标签区 标签区保存LTFS的卷标。它的内容非常简单,如下所示。
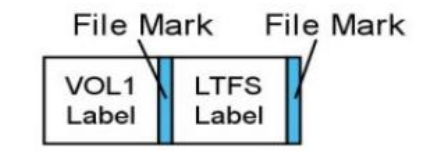
内容区 内容区中首先包含一个索引区,该区域是一个XML文件,描述了 从文件名到文件内容位置的映射。 当然,索引也可以指向新的索 引和老的索引(后面详述)。每个文件的数据则是完全连续的。
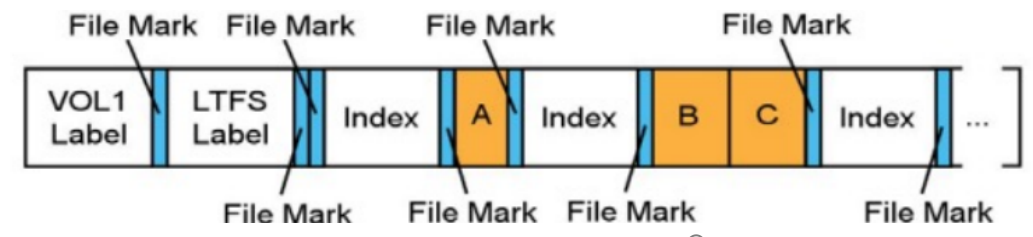
问题一
给文件追加修改怎么办?
磁带是顺序存储,没办法直接追加,只好写在磁带的后面。这样一来, 一个文件在磁带上就等于出现两次,一次是老版本 ,一次是新版本。因此,我们需要标记哪个版本是新版本。
代数
LTFS引入了“代数” 的概念。 当文件被修改时,老版本不会被删除,新版本和新的索引块则被追加到磁带的末尾。
新版本的索引块中会标明一个比老版本更高的代数,这样就可以判断哪个索引是最新的。 新版本索引中有一个指针指回老版本的索引。这样就可以从新版本找到老版本。
当磁带已满时, 唯一释放所有空间的方法就是重新初始化文件系统。
问题二
除了浪费空间的缺点,在备份场合这有什么优点?
磁带上具备所有的备份,这意味着任何时候都能把任何文件的任何深度 的历史记录找回来。最大限度地确保了数据安全性。
硬盘: EXT4
与磁带不同,硬盘(HDD/SSD)支持快速的随机读写。因此,EXT4的设计目标是高效地管理海量小文件和大文件,并保证数据的一致性和性能。
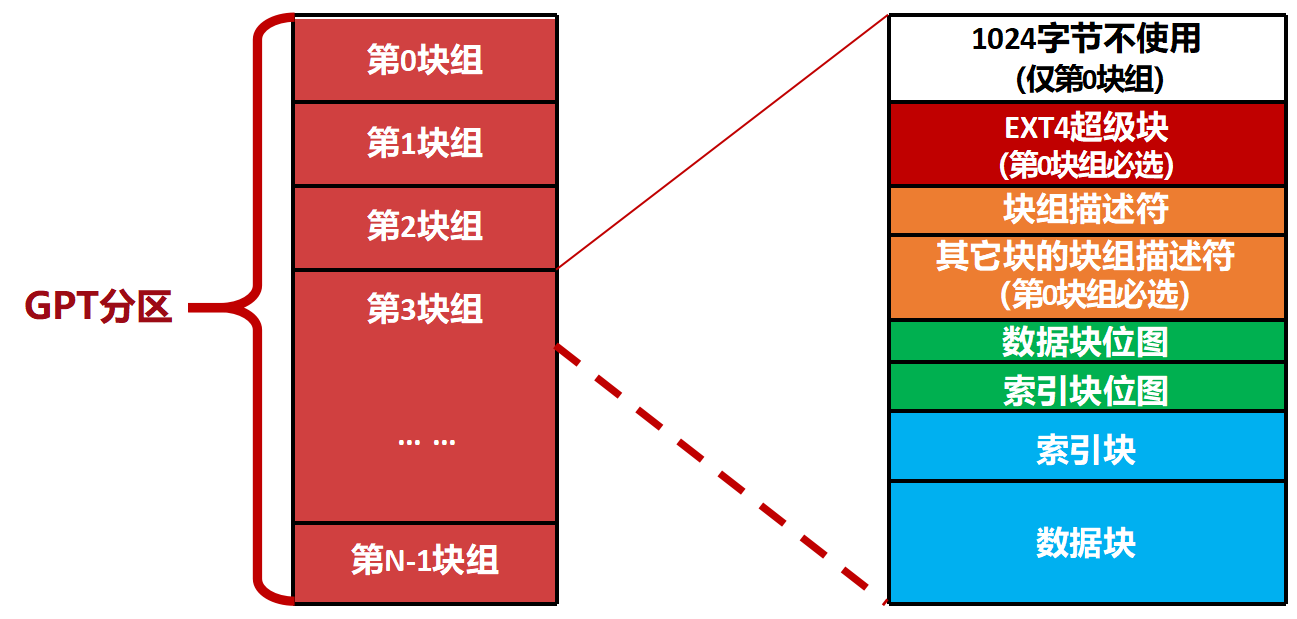
-
块组(Block Group):
- 为什么分块组? 为了提高性能和简化管理。EXT4将整个分区划分为多个“块组”,每个块组都包含自己的一套管理数据结构(位图、inode表等)。
- 好处:
- 局部性原理:文件的inode和其数据块尽量放在同一个块组内,减少磁头移动或寻址开销。
- 并行性:多个块组可以并行操作,提高并发性能。
- 容错性:关键数据结构(如超级块)在多个块组中有备份,一个坏了可以从另一个恢复。
- 为什么分块组? 为了提高性能和简化管理。EXT4将整个分区划分为多个“块组”,每个块组都包含自己的一套管理数据结构(位图、inode表等)。
-
超级块(Super Block):
- 作用:它是整个文件系统的“总指挥部”,记录了文件系统的全局信息,如总块数、空闲块数、inode总数、块大小等。
- 为什么需要备份? 因为超级块至关重要,一旦损坏,整个文件系统将无法挂载。因此,EXT4在多个块组中都保存了超级块的副本。
-
索引节点(inode):
- 核心概念:在EXT4中,文件名和文件数据是分离的。inode存储了文件的所有元数据(属性),如权限、所有者、大小、时间戳,以及指向实际数据块的指针。
- 文件模式(i_mode):这个字段非常关键,它不仅记录了文件的权限(读、写、执行),还记录了文件的类型(普通文件、目录、设备文件等)。
- 权限控制:EXT4采用的是自主访问控制(DAC)模型。文件所有者可以自主决定谁(拥有者、同组用户、其他用户)可以读、写、执行该文件。
- 特殊文件:Linux中“一切皆文件”,设备文件(如
/dev/sda)、管道(FIFO)、套接字(Socket)等,都是通过i_mode中的特定标志位来标识的。 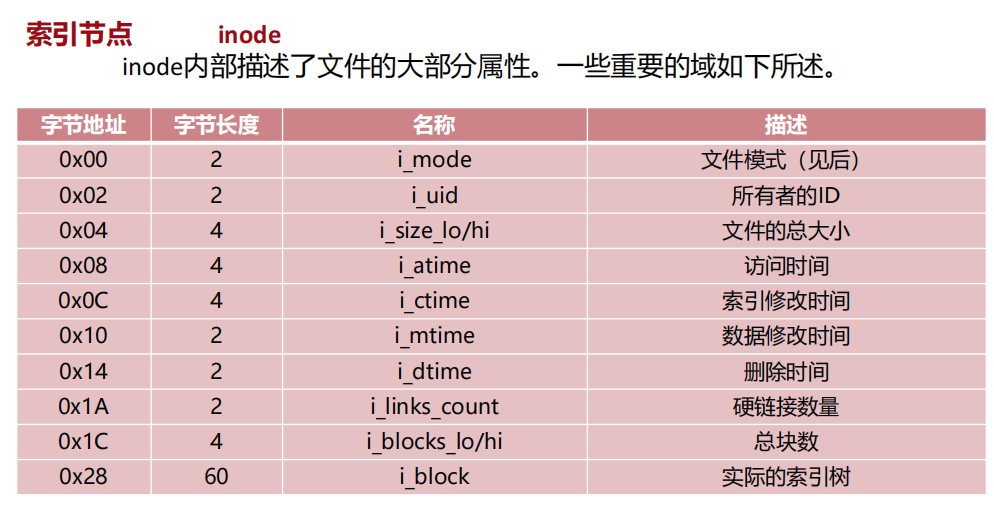
( 1)块位图我们都知道是什么, inode位图呢?
看谁是空闲的?
inode也是看哪个indos是空闲的
(2)为什么每个块组要有自己的块位图和inode位图?整个文件系统用一个不可以吗?
跨块组引用怎么办?
可靠性:一个快组坏了还有其他的备份块是好的,并发现 局部性 可靠性
查询加速:indoes本身存物理块号,通过块指针指向存储的物理地址。
inode位图是为了在创建文件时查找空闲的inode方便。
inode 是全局编号的: 虽然 inode 物理上分散在各个块组的 inode 表里,但它们的编号是全局连续的
间接块指针:如果一个文件特别大,本块组的数据块不够用了,inode 里的指针完全可以直接指向其他块组里的数据块地址。文件系统并不限制数据块必须在同一个组,只是为了性能尽量让它们在一起。
3. 为什么超级块在每个块组都有一份可选的拷贝?
冗余可靠性,每3幂次块备份了
4.其它块的块组描述符为什么在第0块都有一个拷贝?
可靠性 如果损坏就不可用了,0块保存了所有块组描述符的所有备份
( 1)文件模式是什么东西?
- 定义: 它定义了“这是什么类型的文件”以及“它的权限是什么”。
(2)从上表可知, EXT4的一个文件最多有多少硬链接?
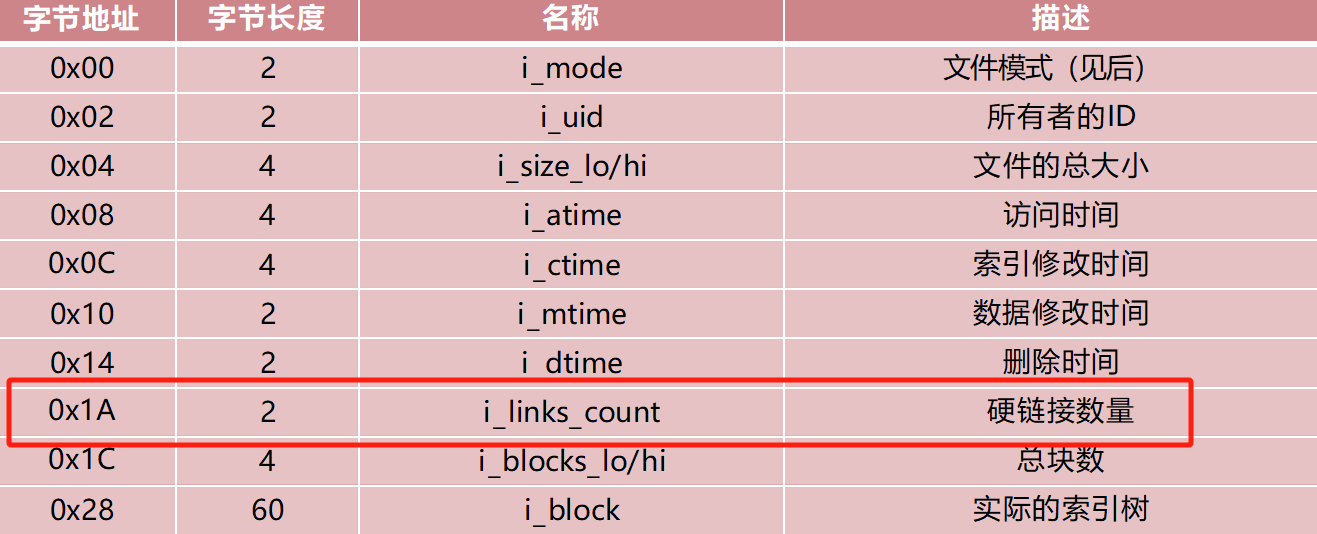
2^(2*8)=2^16
文件模式
i_mode 在传统Unix/Linux中,权限是记录在文件的FCB中的,且具备读、写、执行三个独立的权限。
对于每个文件,用户被分为三类,分别是拥有者( Owner)、和拥有者同一个用户组的用户(Group)以及其它用户 (Other ),其中每类用户的权限由拥有者设置。
问题 这个访问控制方法是DAC还是MAC?是RBAC、ABAC、 PBAC,还是CBAC?
DAC.
特殊文件的 i_mode
i_mode中还有一些位,用来标记文件的性质。 和前面的各个位不同,这些选项不可互相组合,仅能有一个被选中。
问题
( 1) Ubuntu等系统中的.desktop快捷方式文件的S_IFLNK为何不选中?
是普通文件,不是符号连接
(2)为什么硬链接不需要一个类别?
硬链接不是独立类型,是目录文件中新增目录项,indoe中已经指向了文件.硬链接在文件系统眼里,根本就不是一个特殊的“东西”,它就是原文件本身。
i_block的内部结构

看上去相当畸形。二级以上的索引仅各保留一个。为什么这么做?
有限空间内兼顾大小文件,小文件很多,因此需要给小文件高校访问。大文件的四级间接块已经能满足了
大文件的存储之道——从“多级索引”到“扩展树”
之前都是用多级/混合索引存储,效率低下,哪怕连着也要多级索引
-
随机访问性能差
多级索引寻址在机械硬盘上尤其耗时 -
元数据开销大
管理间接块占用磁盘空间,降低了存储效率。
为了解决上述问题,ext4 等现代文件系统引入了扩展记录(Extent)机制,并用 B+ 树来组织这些扩展记录。
- 扩展记录(Extent):核心思想: 不再记录“每一个块在哪里”,而是记录“从第 X 块开始,连续 Y 块都是我的”
寻址方式的根本区别
假设你要在一个大仓库里存放 1000 箱货物。
-
旧模式(EXT2/3 的多级索引):记“流水账”
- 做法: 你拿一个小本本,一行一行地记:第 1 箱在 A 区 1 号架,第 2 箱在 A 区 2 号架……第 1000 箱在 B 区 5 号架。
- 问题: 如果这 1000 箱是连在一起的,你也要写 1000 行字。这非常浪费纸(磁盘空间),而且翻本子找第 900 箱在哪也很慢。如果货物太多,本子记不下了,还得再拿一个新本子记“本子放在哪”(这就是二级、三级索引的开销)。
-
新模式(EXT4 的扩展记录树):记“区间段”
- 做法: 你发现这 1000 箱货物其实是连着放的。于是你只记一行字:“从 A 区 1 号架开始,往后数 1000 个架子都是我的。”
- 优势: 你只需要极少的笔墨(数据)就能描述巨大的文件
这种设计带来了显著的优势:
-
大幅提升寻址效率
- 减少元数据数量:一个扩展记录可以替代成百上千个单独的数据块指针。
- 优化顺序读写:连续
-
改善随机访问性能
所有的扩展记录被组织成一棵 B+ 树(即扩展记录树)。- O(log n) 查找
- 减少I/O次数
| 特性 | 间接块系统 (ext2/ext3) | 扩展记录树 (ext4) |
|---|---|---|
| 寻址单元 | 单个数据块指针 | 连续的块范围 (Extent) |
| 数据结构 | 多级指针链 | B+ 树 |
| 元数据开销 | 大文件时开销巨大 | 显著减少 |
| 大文件性能 | 随机访问慢,顺序读写一般 | 随机访问快,顺序读写极快 |
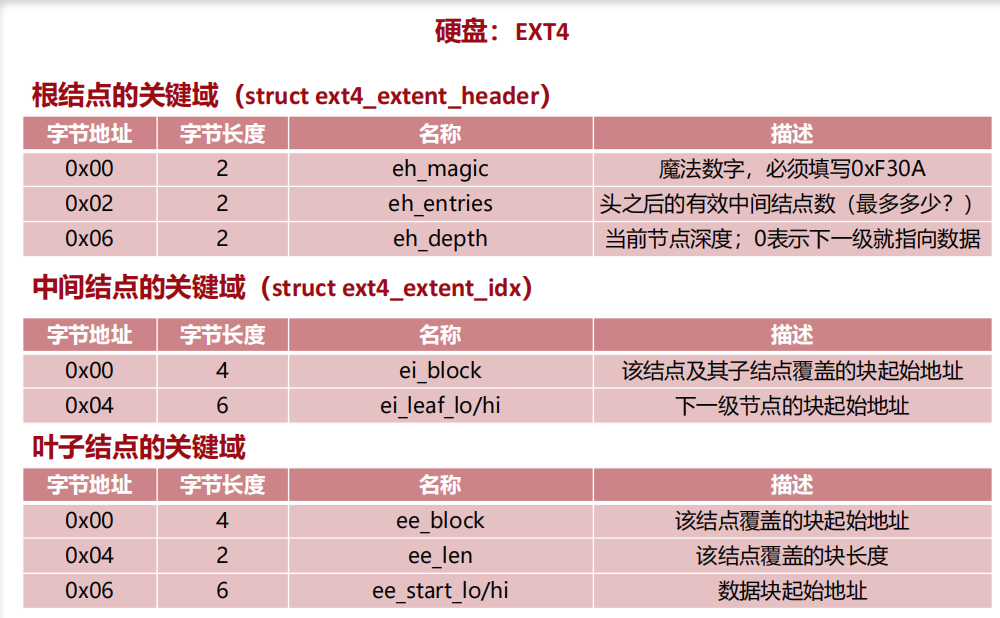
根节点 记录头之后最多多少个中间节点 当前节点深度
中间节点 当前节点的映射范围 逻辑块号映射到下一节点的起始地址
叶子节点 真正的扩展记录 指向能见数据的范围和起始地址
(1)为什么12字节?
iblock只有64字节 减少元数据块
空间对齐与紧凑,与kB整除对齐
长度可以通过子节点的范围计算得到。中间节点只需要描述结构
目录的查找之道——从“线性扫描”到“哈希 B 树”
( 1)文件类型在inode里面不是有吗?在这里重复一遍有什么用呢?
安全性
(2)这种目录的搜索性能怎么样?如何改进?
线性查找 很慢 用哈希树B树
哈希树
根据文件名称得到哈希值,然后再查找哈希树得到具体的目录项。
2. EXT4的解决方案:哈希树(Hash Tree / HTree)
- 核心逻辑:
- 计算哈希值: 拿到文件名(比如
book.txt),通过哈希算法算出一个数字(hash value)。 - 构建B树: 利用这个哈希值构建一棵B树。
- 快速查找: 查找时,先算哈希值,然后像查字典一样,根据哈希值的大小,迅速定位到所在的目录块,而不需要遍历所有文件。
- 计算哈希值: 拿到文件名(比如
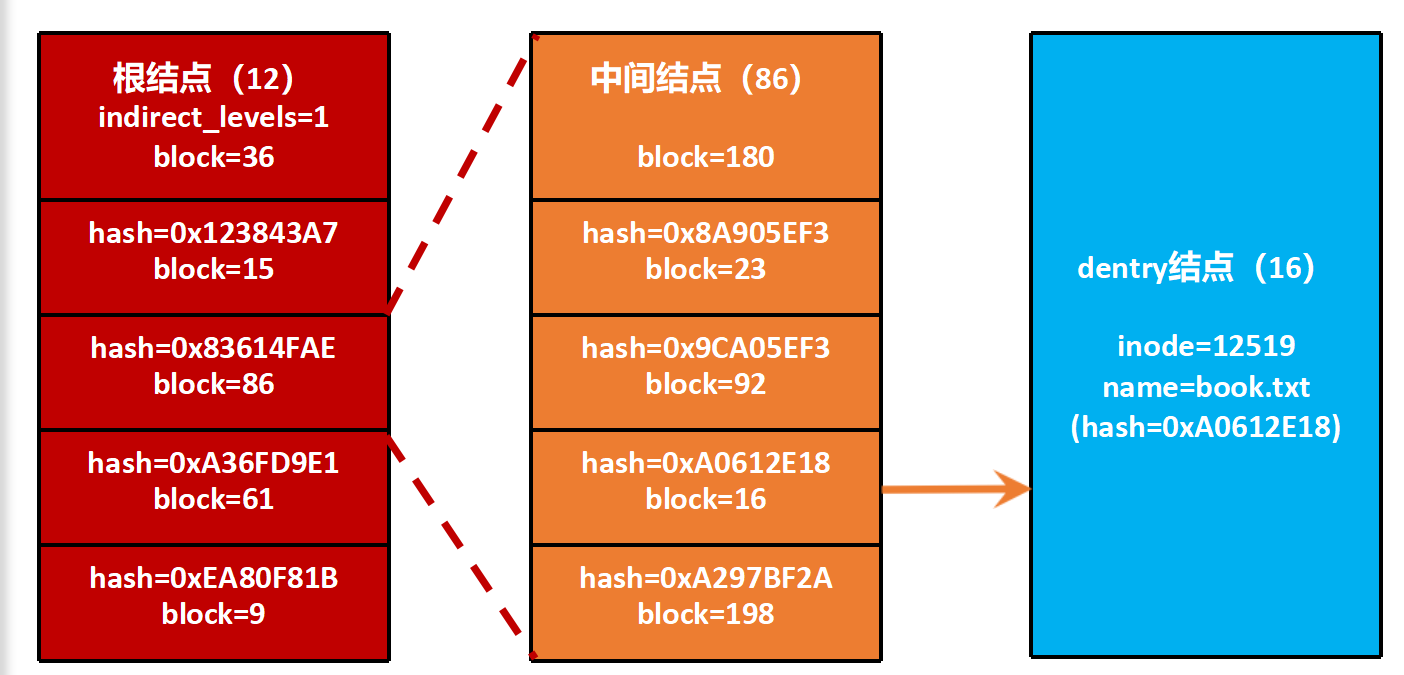
3. 节点结构解析(图4 & 图5)
- 根结点(dx_root): 目录索引的入口,记录树深、哈希版本等。
- 中间结点(dx_node): 存储哈希值的区间范围,指向下一级。
- 叶子结点(dx_entry): 指向实际存储目录项(dentry)的数据块。
4. 查找流程演示
假设我们要找 book.txt:
- 计算
book.txt的哈希值,假设是0xA0612E18。 - 第一步(查根): 在根结点中对比哈希值,发现它落在
0x83614FAE和0xA36FD9E1之间,于是跳转到对应的block=86。 - 第二步(查中间): 在
block=86(中间结点)中继续比对,发现它落在0x9CA05EF3和0xA297BF2A之间,于是跳转到block=16。 - 第三步(找数据):
block=16是叶子结点,它指向了真正存放book.txt目录信息的物理块。 - 根据inode号读取inode表获取文件属性

日志
从“数据怎么存”转向了“系统怎么保命”
流程:
1。将操作写入日志
2。按日志条目操作文件系统
3。消除日志目录
问题
日志文件系统中, 日志与文件系统掉电时的状态关系可能有哪些?
情况一 日志条目写入未完成。
下次上电时直接删掉不完整的日志条目,相当于最后的 操作从未发生。(装作无事发生;本次操作丢失)
情况二 日志条目写入完成,但操作未执行完毕。
继续执行剩余操作
情况三 操作已经执行完毕,但日志条目未被消除。
检查日志条目描述的操作是否完成,若完成 则不再重复操作,若未完成则继续操作直到完成,完成后消除掉日志条目。
情况二与情况三怎么区分?怎么知道操作是否完成?
直到操作是否完成 幂等性,重新执行操作也不会影响结果
幂等性(Idempotence) 对某对象执行任意多次相同操作得到的结果不变。
日志的存储
EXT4的日志也是以文件格式存储的,称为日志文件
日志只存管理结构操作 ,并不储存实际数据,因此在掉电时只能保证文件系统结构的完整性 , 正在操作的文件数据的完整性则无法保证
1)为何要将日志文件放在连续存储空间上?
高校读写: 日志是顺序写入的。
(2)为何这个连续存储空间要靠近分区的中间位置?
平衡寻道时间
(3)为何日志不能连实际数据一起存储?这里有什么考虑?
增加写入量 降低写入速度 空间不够
(4)将日志创建在其它存储设备上有什么好处?对这种设备的
隔离 安全
彻底解耦。日志写入极快(SSD随机写快),且不影响主硬盘的读写磁头
坏了可以恢复
NAND闪存与其匹配的文件系统YAFFS
芯片越小,良率越高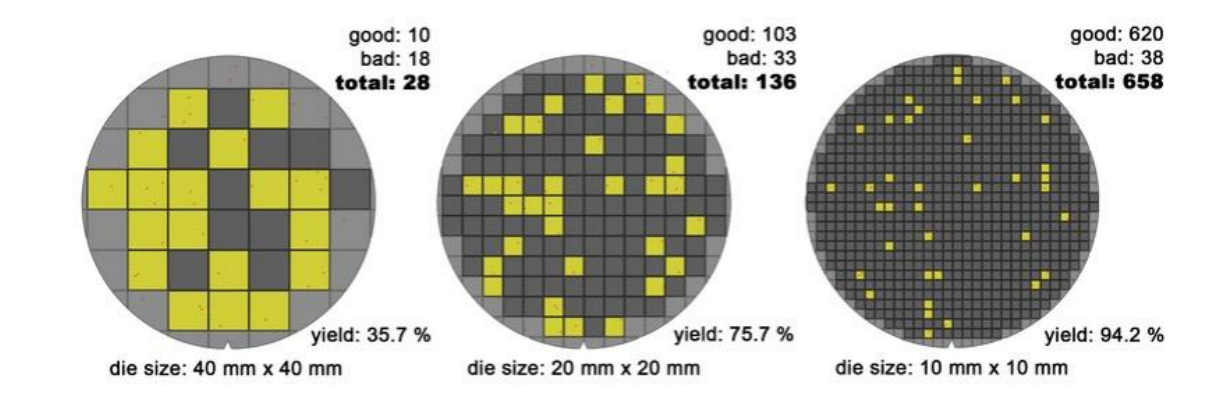
嵌入式系统
它们对功耗、价格、体积非常敏感
介质特性:NAND Flash的“脾气”
- 只能写0不能写1:Flash写入只能把1变成0。如果想把0变回1,必须进行擦除。
- 擦除粒度大:写入是按“页”(比如512字节),但擦除必须按“块”(比如2KB,包含多个页)。这意味着修改一点点数据,可能需要搬运并擦除整个块,效率极低。
- 天生有坏块:Flash制造工艺不完美,出厂就有坏块,用久了还会产生新坏块。
日志结构文件系统
为了解决上述问题,YAFFS采用了日志结构文件系统的设计理念。
- 核心思想:“只追加,不修改”。
- 就像写日记一样,如果要修改数据,不是去覆盖原来的地方(因为覆盖需要先擦除,太麻烦),而是把新数据写到后面空闲的地方,然后把旧数据标记为“无效”。
- 位于同一个闪存块的四个页都包含无效数据,因此可以将它擦除
YAFFS系统
坏块管理
- ECC纠错:Flash数据不可靠,YAFFS使用ECC算法来纠正少量的位翻转。
- 策略:如果一个块读了三次都纠错失败,YAFFS就认定它是“坏块”,以后再也不碰它。
垃圾回收
- 随着修改增多,Flash里会有很多“无效数据”占着茅坑不拉屎。YAFFS会主动进行垃圾回收,把有效的页搬运到一起,腾出整块的空闲空间。
巧妙利用Spare区(点睛之笔)
这是YAFFS最精妙的设计之一。
- 物理特性:NAND Flash的每个页(如2KB)后面,都会附带一个很小的备用区,通常用来存ECC校验码。
- YAFFS的做法:它把文件的元数据(对象头、块编号、有效性标记)直接塞进这个备用区里,而不是占用主数据区。
- 好处:
- 省空间:不占用宝贵的主存储区。
- 原子性:写入数据和写入元数据是在同一个物理操作里完成的,要么都成功,要么都失败,保证了数据一致性。
用来存放每个页的ECC值以及坏块或坏页标记

海量存储的文件系统 池化ZFS 128位
FAT32 块号32位
一、为什么要诞生ZFS?
1. 传统架构的痛点
传统的存储架构是割裂的:文件系统(FS)管逻辑,卷管理器(Volume Manager)管物理
在ZFS之前,传统的存储架构是割裂的(如第二张图左侧所示):
- 物理层:硬盘。
- 卷管理层:用逻辑卷管理器把硬盘拼起来(做RAID)。
- 文件系统层:在卷管理器之上再建文件系统(如EXT4)。
痛点:
- 层级太多:文件系统和卷管理器互不通信,一旦断电或出错,容易导致数据不一致。
- 扩容麻烦:想给硬盘扩容,往往需要下线、重新分区、格式化,风险极大。
二、ZFS的核心革命:存储池化
ZFS做了一件颠覆性的事:它消灭了“卷管理器”,直接把文件系统建在物理硬盘之上。
- 存储池:ZFS把所有硬盘扔进一个大池子里,统一管理。
- 动态扩展:就像往游泳池里加水一样,存储空间不够了,直接扔一块新硬盘进去,池子自动变大,文件系统自动扩容,在线操作,无需停机。
- 无限容量:ZFS是128位文件系统。PPT里提到,这个容量大到几乎不可能用完(理论容量是地球上海水总重量的64倍那么多),所以被称为“无限存储”。
三、ZFS的两大“护身符”
ZFS之所以被称为“终极文件系统”,是因为它有两个核心机制来保证数据绝对安全。
1. 写时复制——对抗“突然掉电”
ZFS采用写时复制策略(如第四张图所示):
- 不覆盖:要修改数据时,ZFS不碰原来的数据块,而是去空闲的地方申请一块新空间写入新数据。
- 链式更新:新数据写好后,ZFS会更新指向它的指针块(也申请新空间写入),一级一级向上更新,直到更新最顶层的“根节点”。
- 原子切换:最后一步,ZFS只需要把那个指向整个文件系统最顶层的Uberblock指针,指向新的根节点。
好处:这个指针切换是瞬间完成的。如果中间断电了,Uberblock还是指向旧的根节点,数据依然是完整且未修改的状态。要么全改完,要么完全没改,绝无中间状态。
2. 独立校验和——对抗“静默损坏”
这是ZFS最厉害的地方。传统文件系统的校验和(Checksum)是和数据存在一起的(如第五张图上半部分)。如果磁盘发生“位翻转”(由于宇宙射线或磁盘老化,0变成了1),数据和校验和可能同时被读错,系统根本发现不了数据坏了。
ZFS的做法(如第五张图下半部分):
- 校验和分离:ZFS把校验和存在父节点里,而不是和数据存在一起。
- 自下而上验证:读取数据时,ZFS先读数据,算出校验和,然后去父节点对比。
- 自动修复:如果发现数据坏了(校验和不匹配),且你配置了冗余(如RAID-Z),ZFS会自动从其他副本读取正确数据,并悄悄把坏掉的地方修好。
系统启动: INITRAMFS
一、起步:如何挂载根文件系统?(INITRAMFS)
- 内核要读取外存,需要硬盘驱动。
- 但硬盘驱动通常是以模块形式存在于根文件系统里的。
- 死循环:没有驱动读不出文件系统,读不出文件系统就没有驱动。
解决方案:INITRAMFS
它是一个临时的、基于内存的根文件系统。
- 启动流程:
- 启动器(GRUB)把内核和INITRAMFS一起加载到内存。
- 内核先挂载这个内存里的INITRAMFS作为临时根目录。
- 因为INITRAMFS里包含了最基本的驱动,内核就能驱动硬盘了。
- 加载完硬盘驱动后,内核再去读取真正的硬盘根文件系统,把它挂载上来,覆盖掉INITRAMFS(这就叫
pivot_root)。
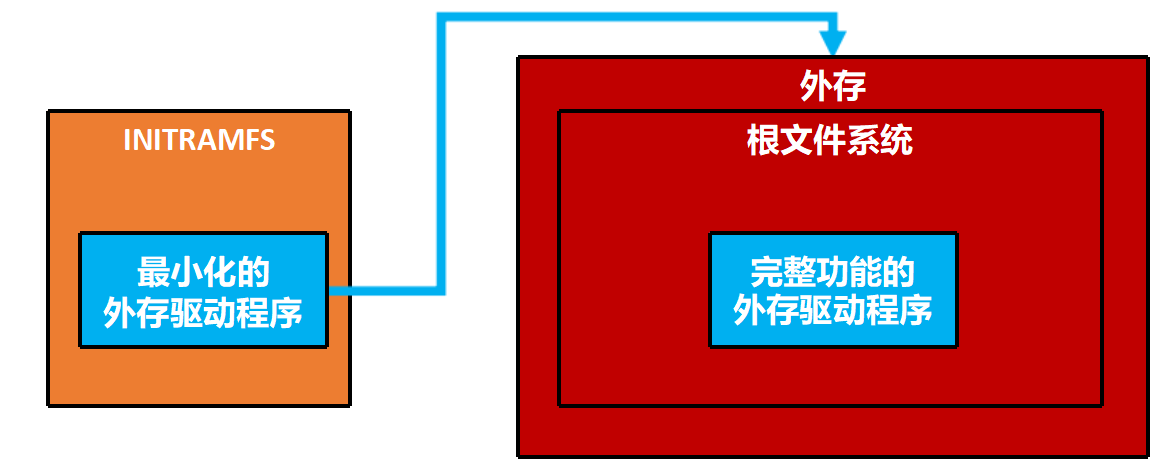
( 1)内核与INITRAMFS的映像也在外存上。启动器如何将它们读入内存?
启动器(GRUB)通过 BIOS/UEFI 提供的底层磁盘访问协议直接读取硬盘扇区。它不需要操作系统驱动,它自己就是一段能读懂简单文件系统的程序。
(2)在什么情况下,不需要使用INITRAMFS?
嵌入式 本身就包含在内核中了
二、进阶:如何管理运行中的系统?(PROC)
系统启动后,我们不仅要读写硬盘上的文件,还要查看内存里正在运行的状态(如CPU温度、内存使用率、进程状态)。
Linux的设计哲学是“一切皆文件”。为了不让程序员专门学一套新指令来查状态,Linux搞了个虚拟文件系统——PROC。
- 本质:它不占硬盘空间,完全存在于内存中。
- 功能:它把内核的数据结构伪装成文件。
文件打开了,能不能读、能不能写、能不能删?这就需要访问控制
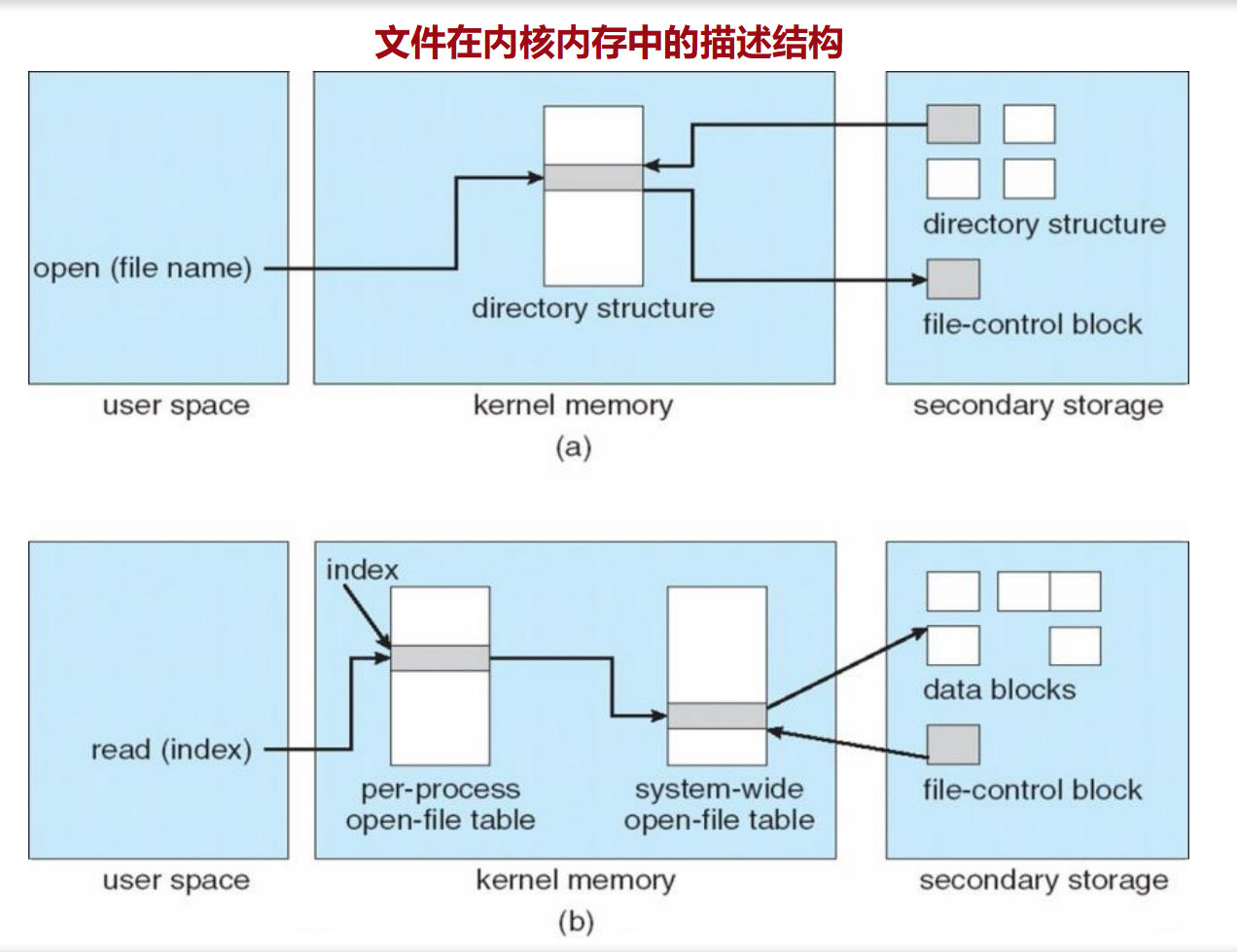
调度 同步互斥
分段分页 计算
优缺点比较
地址转换计算题

openEuler 是由开放原子开源基金会孵化的全场景开源操作系统项目,面向数字基础设施四大核心场景(服务器、云计算、边缘计算、嵌入式),全面支持 ARM、x86、RISC-V、loongArch、PowerPC、SW-64 等多样性计算架构
更多推荐
 0
0 0
0- 0



 已为社区贡献15条内容
已为社区贡献15条内容

所有评论(0)